Python爬虫——下载文件以及tqdm进度条的使用
Python爬虫——下载文件以及tqdm进度条的使用
本篇内容知识点:
1.使用tqdm库对可迭代对象进行进度可视化操作
2.使用requests进行简单爬取并下载文件
可迭代对象什么意思:
以Python为例,可迭代对象的意思是指存储了元素的一个容器对象,且容器中的元素可以通过iter( )方法或getitem( )方法访问。并不是指某种具体的数据类型。常见的可迭代对象包括:集合数据类型,如list、tuple、dict、set、str等…
安装:
pip install tqdm
pip install requests
库安装问题在此不过多解释,出现问题自行查找其他资料
最常见的一套“下载模板”
import requests
url='某某文件路径'
response=requests.get(url) # 向地址发送一个get请求以获取响应对象
with open('文件名.后缀名','wb') as f:
f.write(date)
# wb:以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,
# 即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。
#更多文件打开的模式:https://www.runoob.com/python/python-files-io.html
tqdm库比较简单易懂的使用方法
使用tqdm必须知道的几个常见参数:
iterable:可迭代的对象 默认None
total:进度条总长度大小(int or float)默认None
desc:进度条的前缀内容(str)默认None
unit:进度条的单位(str)默认 it ,实际表带为 it/s
一、迭代对象的处理
from tqdm import tqdm
import time
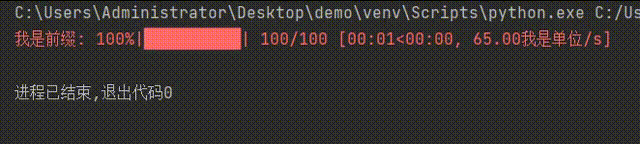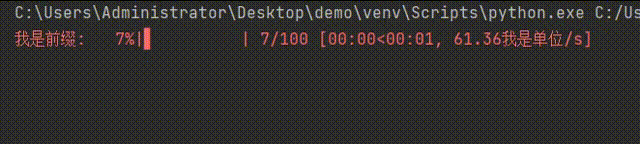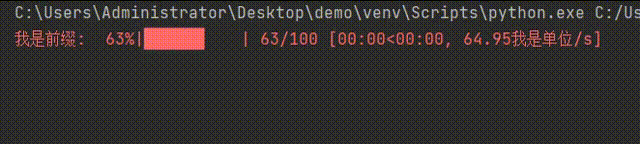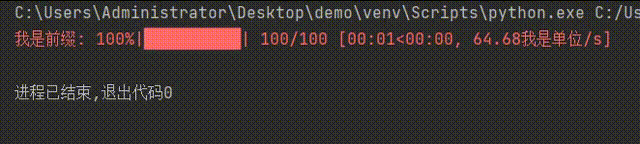
for i in tqdm(iterable=range(100),desc='我是前缀',unit='我是单位'):
time.sleep(0.1) #延时0.1秒
pass
效果如下
二、需要自定义进度条的增长间隔
from tqdm import tqdm
import time
lt=["a","b","c","d","e","f","g","h","i","j","k","l","m","n","o","p","q","r","s","t","u","v","w","x","y"]
with tqdm(iterable=lt,desc='遍历字母',unit='个',total=len(lt)) as pgbr:
for index,l in enumerate(lt):
if index%5==0:
time.sleep(1) # 延时1秒
pgbr.update(5) # 进度条一次增长5个单位
print(l)
效果如下

下载文件结合tqdm用法
from tqdm import tqdm
import requests
url='https://dldir1.qq.com/qqtv/TencentVideo11.14.4043.0.exe'
response=requests.get(url,stream=True) # 设stream流传输方式为真
print(response.headers) # 打印查看基本头信息
data_size=int(response.headers['Content-Length'])/1024/1024 # 字节/1024/1024=MB
with open('测试.exe','wb') as f:
for data in tqdm(iterable=response.iter_content(1024*1024),total=data_size,desc='正在下载',unit='MB'):
f.write(data)
效果如下


要点解释:
1.response.get(stream=True) 这一点必须为True,其详细解释请查iter_content函数的说明,或者找其他资料理解
2.iter_content(chunk_size) chunk_size参数的理解见下图
3.TqdmWarning: clamping frac to range [0, 1]full_bar = Bar(frac, … 这个警告我也未找到原因,网络上也未找到相同的问题,有大佬知道的也请告知一声 。(个人猜测与iter_content(chunk_size)的size有关)
理解chunk_size

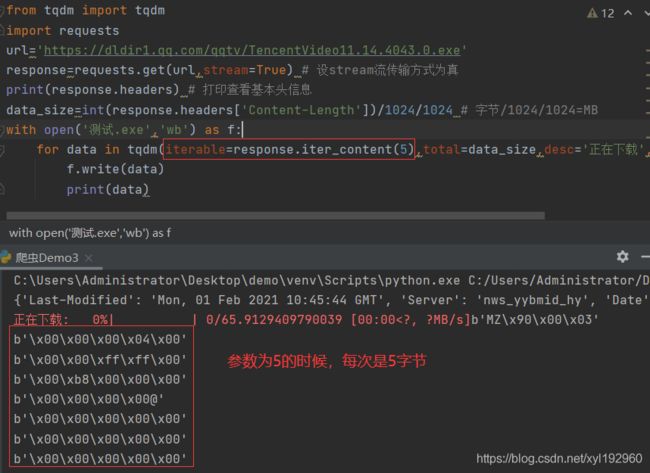
因此我将iter_content(chunk_size)->chunk_size理解为一个列表的容量,
而iterable=response.iter_content(1024*1024)理解为分割字符串的函数,
将response.content分割为每个元素的长度是1024*1024大小的列表,在对每个部分进行下载。
这只是助于理解chunk_size的一个方法
而response.iter_content 是流传输(简单说就是边下载边写入磁盘),如果将chunk_size设置的很小,意味着每次
下载和存在很小的一部分,下载的速度也会很慢,如果设置的很大,则进度条的进度会错乱,因此我们在确定chunk_size
大小的时候应该对应文件大小,data_size除以多少,chunk_size就乘以多少,才能使进度条对应。
本篇内容仅供学习参考交流,有错误的地方请大家指正