Scrapy框架爬虫实战——从入门到放弃03
Scropy框架爬虫的其他文件格式下载——以zcool精选图片为例
本次实战中,我们以图片为例,演示使用Scrapy框架爬取非文本内容的方法。
在前面两次的Scrapy框架爬虫实战中,已经对基础操作有了较为详细的解释说明,因此本次教程中的基础操作将不再过多赘述,有疑惑的同学可以查看前面两期的从入门到放弃系列博客:
Scrapy框架爬虫实战——从入门到放弃 01 :传送门
Scrapy框架爬虫实战——从入门到放弃02 :传送门
文章目录
- Scropy框架爬虫的其他文件格式下载——以zcool精选图片为例
-
- 爬虫编写
-
- 创建CrawlSpider爬虫
- 基础设置
-
- 创建`start.py`
- 关闭协议、设置ua
- 设置初始页面
- 编写灵魂——rules规则
-
- 页码对应url
- 详情页
- 数据解析与存储
-
- 编写回调函数`parse_details`
-
- 获取标题
- 获取图片url
- 编写`items.py`
- 在`zcoolSpider.py`中调用`items.py`
- 在`setting.py`中打开`piplines`,并编写文件存储路径
- 编写`piplines.py`
- 最终代码参考:
-
- `zcoolSpider.py`
- `items.py`
- `piplines.py`
- `settings.py`
目标网站: 传送门
爬虫编写
我们以CrawlSpider为工具进行爬取。
创建CrawlSpider爬虫
在命令行中创建爬虫:
cd zcool
scrapy startproject zcool
cd zcool
scrapy genspider -t zcoolSpider https://www.zcool.com.cn/
基础设置
进行一些常规化的基础设置,后续使用Scrapy框架时可以按照这样的思路直接往下进行。
创建start.py
创建start.py以实现在pycharm内运行Scrapy爬虫
from scrapy import cmdline
cmdline.execute("scrapy crawl zcoolSpider".split(" "))
关闭协议、设置ua
在settings.py中关闭那个君子协议,然后设置好自己的user-agent
BOT_NAME = 'zcool'
SPIDER_MODULES = ['zcool.spiders']
NEWSPIDER_MODULE = 'zcool.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent' : '我的user-agent'
}
设置初始页面
设置一下zcoolSpider.py(就是爬虫文件)里的start_urls,本次实战中我们爬取的是“精选部分”,页面链接在这:传送门
name = 'zcoolSpider'
allowed_domains = ['zcool.com.cn']
start_urls = ['https://www.zcool.com.cn/discover/0!3!0!0!0!!!!1!1!1']
编写灵魂——rules规则
页码对应url
不难找到不同页码对应链接的规律:
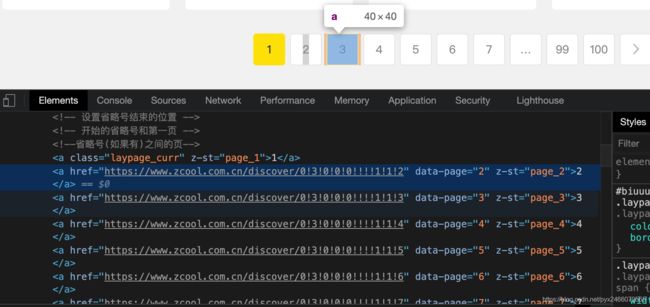
均为https://www.zcool.com.cn/discover/0!3!0!0!0!!!!1!1!+页码的形式
规则(正则表达式)应该这样写:
Rule(LinkExtractor(allow=r'.+0!3!0!0!0!!!!1!1!\d+'),follow=True)
详情页

详情页的规则也很明显,均为https://www.zcool.com.cn/work/+一串字母+=.html
规则(正则表达式)应该这样写:
Rule(LinkExtractor(allow=r'.+work/.+html'),follow=False,callback="parse_detail")
数据解析与存储
上面已经写好了rules,使crawlSpider有了自己找到每一个详情页的能力,接下来我们就处理这些详情页。
编写回调函数parse_details
由于每个详情页里都有很多张图,所以我们期望把每一页里的图放在同一个文件夹里,然后以那一页的标题为文件名,这样便于我们以后查看。因此,在回调函数中,我们需要获取的内容主要有两个:标题和图片链接
获取标题

title = response.xpath("//div[@class='details-contitle-box']/h2/text()").getall() # getall返回列表
title = "".join(title).strip() # 用于将列表拼接并删掉首尾的空格
获取图片url

利用div标签的class属性,定位图片的链接
image_urls = response.xpath("//div[@class='photo-information-content']/img/@src").getall()
ps. 我们可以在插件XPath Helper中验证自己找的xpath路径是否正确,如图:

的确是可以成功获取url
编写items.py
import scrapy
class ZcoolItem(scrapy.Item):
title = scrapy.Field() # 标题
image_urls = scrapy.Field() # 图片链接
images = scrapy.Field() # 图片本身
在zcoolSpider.py中调用items.py
from ..items import ZcoolItem
...
class ZcoolspiderSpider(CrawlSpider):
...
def parse_detail(self, response):
...
item = ZcoolItem(title=title,image_urls=image_urls)
return item
在setting.py中打开piplines,并编写文件存储路径
import os
IMAGES_STORE = os.path.join(os.path.dirname(os.path.dirname(__file__)),'images')
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'zcool.pipelines.ZcoolPipeline': 300,
}
其中os.path.dirname的作用是获取上层文件夹路径,__file__就是只这个文件本身,os.path.join则实现了将路径拼接的作用。
编写piplines.py
from scrapy.pipelines.images import ImagesPipeline
from zcool import settings # 这是想调用settings.py里写的IMAGE_STORE
import os
import re # 正则表达式库
class ZcoolPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
media_requests = super(ZcoolPipeline, self).get_media_requests(item,info)
for media_request in media_requests:
media_request.item = item
return media_requests
def file_path(self, request, response=None, info=None, *, item=None):
origin_path = super(ZcoolPipeline, self).file_path(request, response, info) # 先执行一遍原函数
title = request.item['title']
title = re.sub(r'[\\/:\*\?"<>\|]',"",title) # 删除非法字符
save_path = os.path.join(settings.IMAGES_STORE,title)
image_name = origin_path.replace("full/","")
return os.path.join(save_path,image_name)
注意到上面的title = re.sub(r'[\\/:\*\?"<>\|]',"",title)一句中,因为我们想用详情页的标题作为文件夹名,但文件夹名中不可以出现这些字符:\ / : * ? " < > |,因此我们要用正则表达式的方法,把标题中的这些字符删除。
至此,我们编写完了本次实战的爬虫,运行可得结果如下:

最终代码参考:
zcoolSpider.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ..items import ZcoolItem
class ZcoolspiderSpider(CrawlSpider):
name = 'zcoolSpider'
allowed_domains = ['zcool.com.cn']
start_urls = ['https://www.zcool.com.cn/discover/0!3!0!0!0!!!!1!1!1']
rules = (
Rule(LinkExtractor(allow=r'.+0!3!0!0!0!!!!1!1!\d+'),follow=True),
Rule(LinkExtractor(allow=r'.+work/.+html'),follow=False,callback="parse_detail")
)
def parse_detail(self, response):
image_urls = response.xpath("//div[@class='photo-information-content']/img/@src").getall()
title = response.xpath("//div[@class='details-contitle-box']/h2/text()").getall()
title = "".join(title).strip()
item = ZcoolItem(title=title,image_urls=image_urls)
return item
items.py
import scrapy
class ZcoolItem(scrapy.Item):
title = scrapy.Field()
image_urls = scrapy.Field()
images = scrapy.Field()
piplines.py
from scrapy.pipelines.images import ImagesPipeline
from zcool import settings
import os
import re
class ZcoolPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
media_requests = super(ZcoolPipeline, self).get_media_requests(item,info)
for media_request in media_requests:
media_request.item = item
return media_requests
def file_path(self, request, response=None, info=None, *, item=None):
origin_path = super(ZcoolPipeline, self).file_path(request, response, info) # 先执行一遍原函数
title = request.item['title']
title = re.sub(r'[\\/:\*\?"<>\|]',"",title)
save_path = os.path.join(settings.IMAGES_STORE,title)
image_name = origin_path.replace("full/","")
return os.path.join(save_path,image_name)
settings.py
BOT_NAME = 'zcool'
SPIDER_MODULES = ['zcool.spiders']
NEWSPIDER_MODULE = 'zcool.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent' : '我的user-agent'
}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'zcool.pipelines.ZcoolPipeline': 300,
}
import os
IMAGES_STORE = os.path.join(os.path.dirname(os.path.dirname(__file__)),'images')