Python爬虫实例——爬取LOL皮肤图片and保存英雄四维属性雷达图
Python爬虫实例——爬取LOL皮肤图片and保存英雄四维属性雷达图
前言:
本篇内容不会过多解释爬虫基本操作,都是一些小知识点结合起来使用,主要介绍如何分析页面以及数据,达到想要的效果
如若还未入门爬虫,请往这走 简单粗暴入门法——Python爬虫入门篇
如若不理解进度条以及下载文件的用法,请往这走 Python爬虫——下载文件以及tqdm进度条的使用
matplotlib详解后续补
本篇内容知识点:
import requests # 爬虫
import json # 转换json格式
import os # 访问目录
from tqdm import tqdm # 进度条
import matplotlib.pyplot as plt #绘图
import numpy as np # 科学计算库
使用审查分析页面
安装:
pip install pyttsx3
pip install matplotlib
pip install requests
pip install numpy
分析单个英雄皮肤页面
既然要爬取皮肤,我们就首先进入可以查看英雄皮肤的页面进行分析,图例链接:https://lol.qq.com/data/info-defail.shtml?id=40
刷新页面,查看XHR和IMG类型会加载哪些数据。

可以看到在XHR中有一个40.js里面就存放了json格式的一些关于英雄皮肤的数据,将其展开就可以找到对应皮肤图片的链接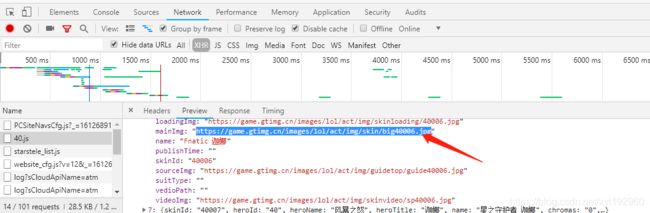
而我们发现这个40.js与页面路径中的40相对应,猜测40应该是一个id,在点开其他英雄皮肤页面进行对比,发现我们的猜测是正确的。可以得到每个英雄的预览皮肤的链接为:
url='https://game.gtimg.cn/images/lol/act/img/js/hero/'+hero_id+'.js'
得到单个英雄皮肤链接
我们在对单个英雄进行爬取分析;
1.从上图中看到从40.js获取到的内容是json类型数据,所以我们要对内容进行json转换
2.从上图中可以发现是用{} 进行存放的,在Pyhon {}是字典,所以我们可以用dict[‘key’]在获取里面的内容
3.逐层拨开找到我们需要的内容
import requests
import json
url='https://game.gtimg.cn/images/lol/act/img/js/hero/40.js'
with requests.get(url) as response:
content=json.loads(response.text)
infos=content['skins']
for info in infos:
print(info['mainImg'])
运行得到图片路径
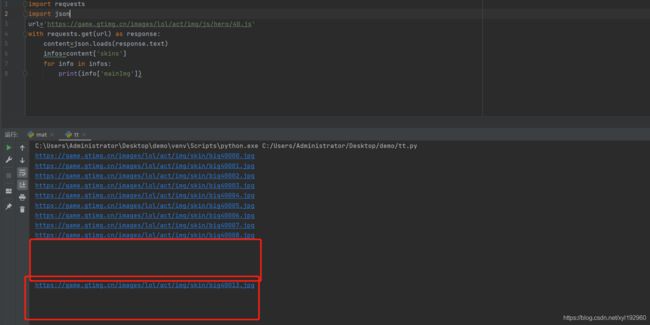 但是发现其中断开了,而且得到的地址也不一定是连续的,因此我们在对得到的数据进行分析,发现有些地方的mainImg为空字符,并且在单个英雄下面的skins皮肤列表中也并不都有这个皮肤,所以我们在正式爬取的时候应该对 mainImg 进行非空判断
但是发现其中断开了,而且得到的地址也不一定是连续的,因此我们在对得到的数据进行分析,发现有些地方的mainImg为空字符,并且在单个英雄下面的skins皮肤列表中也并不都有这个皮肤,所以我们在正式爬取的时候应该对 mainImg 进行非空判断
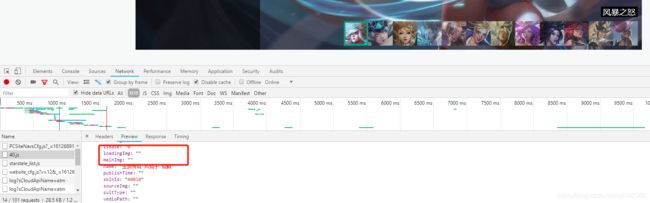
找到所有英雄列表
进入官网https://lol.qq.com/main.shtml刷新,查看可以获取到什么内容。

从上图我们可以看到英雄列表是存放在
https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?v=06 这个链接中的,并且从Json中可以得到一些信息:name、attack、magic、 defense、 difficulty等信息,所以我们在爬取皮肤的时候还能使用一个雷达图进行一个小小的数据分析。
程序实现
MyPyClass类
MyPyClass类
def GetRadarChart(values,features,bottom,top,title='多维雷达图',issave=False,savepath='./RadarChart.jpg',isshow=True):
'''获得一个多维雷达图
Parameters:
----------
values:list列表
用于存放int类型的多维雷达图数据
features:list列表
用于存放str类型对应每个数据的特征说明
bottom:float浮点
雷达图圆心位置的起始值即数据下限
top:float浮点
雷达图半径长度即数据上限
title:str字符串 可选
雷达图标题 默认为 '多维雷达图'
issave:bool布尔类型
是否需要保存 默认为 False
savapath:str字符串类型
保存路径 默认为 ./RadarChart.jpg
isshow:bool布尔类型
是否需要显示雷达图 默认为 True
'''
# 中文和负号的正常显示
plt.rcParams['font.sans-serif'] = 'Microsoft YaHei'
plt.rcParams['axes.unicode_minus'] = False
# 使用ggplot的风格绘图
plt.style.use('ggplot')
# N=数据个数
N = len((values))
# 设置雷达图的角度,将一个圆平分为N块
angles = np.linspace(0, 2 * np.pi, N, endpoint=False)
# 封闭雷达图
angles = np.concatenate((angles, [angles[0]]))
attribute = np.concatenate((values, [values[0]]))
# np.concatenate相当于
# angles.append(angles[0])
# angles=np.array(angles)
# 绘图
fig = plt.figure()
# 设置为极坐标格式
ax = fig.add_subplot(111, polar=True)
# 添加每个特质的标签
ax.set_thetagrids(angles[0:N] * 180 / np.pi, features)
# 绘制折线图
ax.plot(angles, attribute, 'o-', linewidth=2, label=title)
# 填充颜色
ax.fill(angles, attribute, 'b', alpha=0.5)
# 设置极轴范围 半径长度
ax.set_ylim(bottom, top)
# 标题
plt.title(title)
# 增加网格纸
ax.grid(True)
# 是否需要保存图片
if issave:
plt.savefig(savepath)
# 是否需要显示雷达图
if isshow:
plt.show()
主程序
import MyPyClass
import requests
import json
import os
from tqdm import tqdm
hero_list=[] # 定义一个列表,英雄信息列表
hero_infos=[] # 定义一个列表,用于存放英雄名称和对应ID的字典
# requests爬虫基本程序
# 英雄列表信息url
url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?v=06'
ua = MyPyClass.GetUserAgent()
with requests.get(url, headers={
'User-agent': ua}) as response:
content = response.text
hero_list = json.loads(content)['hero'] # 将Json字符串转换为列表
# 遍历英雄数据
for hero in hero_list:
# 将英雄名称和id以及四维数据的字典放如外部列表
hero_dict={
'name':hero['name'],
'id':hero['heroId'],
'attack':hero['attack'],
'magic':hero['magic'],
'defense':hero['defense'],
'difficulty':hero['difficulty']}
hero_infos.append(hero_dict)
for hero_info in hero_infos:
hero_name=hero_info['name'] # 英雄名字
hero_id=hero_info['id'] # 英雄ID
path='D:/LOL皮肤/' # 路径
# 判断是否存在路径,不存在则创建
if not os.path.exists(path):
os.mkdir(path)
if not os.path.exists(path+hero_name):
os.mkdir(path+hero_name)
os.chdir(path+ hero_name) # 设置此路径为工作目录
# 生成雷达图并保存到路径
attribute = [int(hero_info['attack']), int(hero_info['magic']), int(hero_info['defense']), int(hero_info['difficulty'])]
attribute_name = ['物理攻击力', '魔法攻击力', '防御力', '操作难度']
MyPyClass.GetRadarChart(values=attribute, features=attribute_name, bottom=0, top=10, title=hero_name + '四维数据图', issave=True, isshow=False,savepath=path+hero_name+'/'+hero_name+'四维数据图.jpg')
# 英雄信息url
hero_info_url='https://game.gtimg.cn/images/lol/act/img/js/hero/'+hero_id+'.js'
#将Json转换
content=requests.get(hero_info_url).text
skin_infos=json.loads(content)['skins']
for skin_info in skin_infos:
# 获取皮肤路径
if skin_info['mainImg']!="":
skin_name=skin_info['name']
skin_url=skin_info['mainImg']
img=requests.get(skin_url,stream=True)
# 判断访问状态
if img.status_code==200:
# 判断图片名称中是否带有不可用于命名的字符串
if '/' in skin_name or ':' in skin_name or '\\' in skin_name or '\"' in skin_name:
skin_name=skin_name.replace('/','')
skin_name=skin_name.replace('\\','')
skin_name=skin_name.replace('\"','“')
skin_name = skin_name.replace(':', ':')
# 将图片下载保存到工作路径
content_size = int(img.headers['Content-Length']) / 1024 # 获取文件大小
with open(skin_name+'.jpg','wb') as f:
for data in tqdm(iterable=img.iter_content(1024),total=content_size,unit='b',desc='正在爬取 '+hero_name+'的皮肤 '+skin_name):
f.write(data)
print('Next')
效果如下
本篇内容仅供学习参考交流,有错误的地方请大家指正