python爬虫:爬取动态网页并将信息存入MySQL数据库
目标网站
http://www.neeq.com.cn/disclosure/supervise.html
爬取网页该部分内容

网页分析
查看网页源代码发现没有表格部分内容,对网页请求进行分析 F12–>network---->xhr
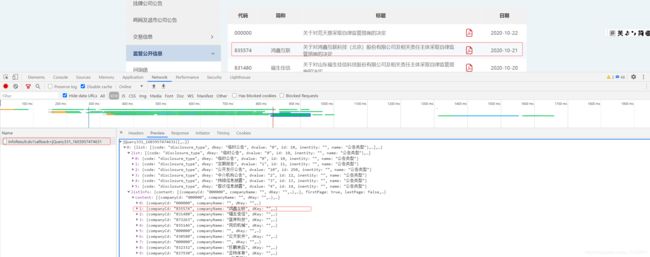
接下来分析数据来源,切换到Headers可以查看到 url,请求方法为 POST以及 Form Data
Request URL: http://www.neeq.com.cn/disclosureInfoController/infoResult.do?callback=jQuery331_1603957757976
Request Method: POST
Form Data
page: 0
companyCd:
disclosureType: 8
startTime: 2019-10-30
endTime: 2020-10-29
keyword:
sortfield: xxssdq
sorttype: asc
切换页数多分析几条请求发现 post请求 Form Data 上传了两个关键的数据:disclosureType和page
代码编写
接下来开始撸代码,代码运行环境为 python3 ,结合返回数据格式编写代码

新建 neeq.py 抓取清洗数据
import requests
import json
import py_mysql
import os
def get_data():
urls = "http://www.neeq.com.cn/disclosureInfoController/infoResult.do?callback=jQuery331_1603846097415"
headers = {
'Accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content-Length': '113',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie': 'Hm_lvt_b58fe8237d8d72ce286e1dbd2fc8308c=1603788530; AlteonP=Aa0sI4GSf3sCGftZEvcaAw$$; Hm_lpvt_b58fe8237d8d72ce286e1dbd2fc8308c=1603846029',
'Host': 'www.neeq.com.cn',
'Origin': 'http://www.neeq.com.cn',
'Pragma': 'no-cache',
'Referer': 'http://www.neeq.com.cn/disclosure/supervise.html',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
# 爬取第四页数据
for index in range(4, 5):
# post请求获取数据
str_data = requests.post(url=urls, headers=headers, data={
'page': index, 'disclosureType': 8}).text
# 截取字符串有用数据部分并反序列化为字典对象
tar_data = json.loads(str_data[str_data.index('[') + 1:str_data.rindex(']')])
# 获取需要保存的数据
content_data = tar_data['listInfo']
for da in content_data['content']:
# 保存 pdf,根据返回 pdf 路径下载保存 pdf 到本地
urls_pdf = """http://www.neeq.com.cn/""" + da['destFilePath']
data_pdf = requests.get(url=urls_pdf).content
path_pdf = da['destFilePath'][1:]
path_dir = path_pdf[: path_pdf.rindex('/') + 1]
file_name = path_pdf[path_pdf.rindex('/') + 1:]
# 如果pdf文件路径不存在,则新建
if not os.path.exists(path_dir):
os.makedirs(path_dir)
with open(path_dir + file_name, 'wb') as f:
f.write(data_pdf)
# 将爬取到的数据存入MySQL数据库
py_mysql.insert(da['companyCd'], da['companyName'], da['disclosureTitle'], path_pdf,
da['publishDate'])
# 关闭数据库连接
py_mysql.close_()
get_data()
新建 py_mysql.py 将数据存入数据库
import pymysql
conn = pymysql.connect(host="127.0.0.1", user="root", password="123456", database="python_test", charset="utf8")
cursor = conn.cursor()
def insert(code, alias, title, file, date):
sql = """insert into neeq(code,alias,title,file,date_) values("%s","%s","%s","%s",'%s')""" % (
code, alias, title, file, date)
print(sql)
try:
cursor.execute(sql)
conn.commit()
except:
print("插入错误")
conn.rollback()
def close_():
cursor.close()
conn.close()
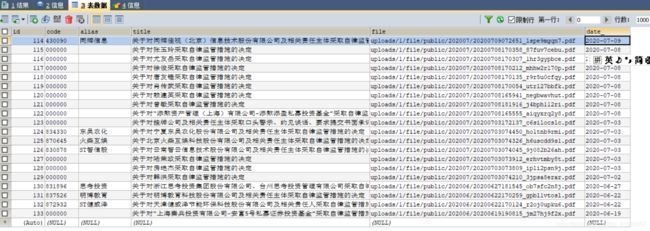
查看数据
mysql 保存数据
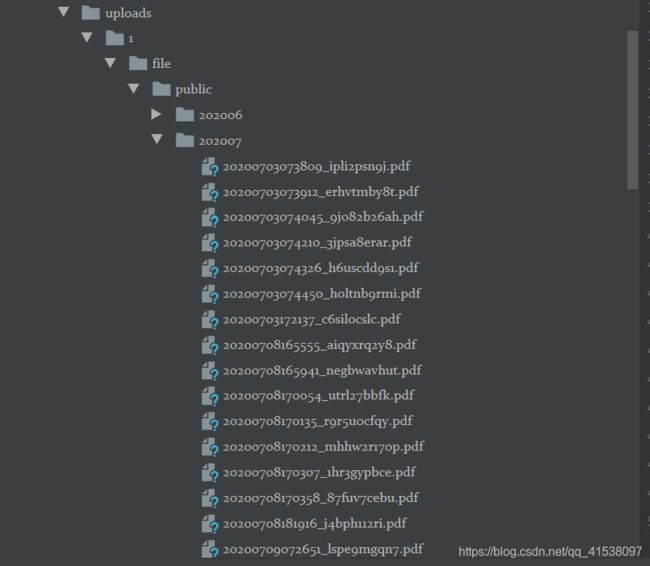
保存的 pdf
以上就是简单的爬虫入门