pytorch 三维点分类_基于深度学习的三维重建——MVSNet系列论文解读

MVSNet:香港科技大学的权龙教授团队的MVSNet(2018年ECCV)开启了用深度做多视图三维重建的先河。
2019年,2020年又有多篇改进:RMVSNet(CVPR2019),PointMVSNet(ICCV2019),P-MVSNet(ICCV2019),MVSCRF(ICCV2019),Cascade(CVPR2020),CVP-MVSNet(CVPR2020),Fast-MVSNet(CVPR2020),UCSNet(CVPR2020),CIDER(AAAI2020),PVAMVSNet(ECCV2020),D2HC-RMVSNet(ECCV2020),Vis-MVSNet(BMVC 2020)。
一 MVSNet:目标是预测图片上每个像素的深度信息
MVSNet: Depth Inference for Unstructured Multi-view Stereo
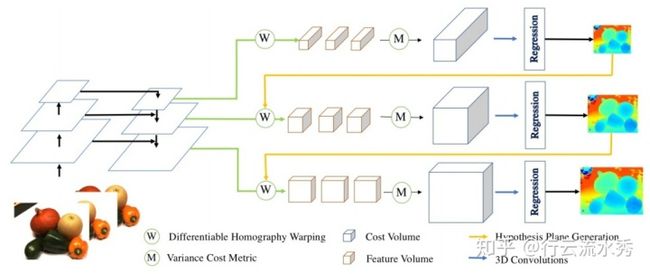
MVSNet本质是借鉴基于两张图片cost volume的双目立体匹配的深度估计方法,扩展到多张图片的深度估计,而基于cost volume的双目立体匹配已经较为成熟,所以MVSNet本质上也是借鉴一个较为成熟的领域,然后提出基于可微分的单应性变换的cost volume用于多视图深度估计。
论文实现了权龙教授多年的深度三维重建想法。
过程:
(1)输入一张reference image(为主) 和几张source images(辅助);
(2)分别用网络提取出下采样四分之一的32通道的特征图;
(3)采用立体匹配(即双目深度估计)里提出的cost volume的概念,将几张source images的特征利用单应性变换( homography warping)转换到reference image,在转换的过程中,类似极线搜索,引入了深度信息。构建cost volume可以说是MVSNet的关键。
具体costvolume上一个点是所有图片在这个点和深度值上特征的方差,方差越小,说明在该深度上置信度越高。
(4)利用3D卷积操作cost volume,先输出每个深度的概率,然后求深度的加权平均得到预测的深度信息,用L1或smoothL1回归深度信息,是一个回归模型。
(5)利用多张图片之间的重建约束(photometric and geometric consistencies)来选择预测正确的深度信息,重建成三维点云。
该论文最重要的单应性变换( homography warping)的公式写错了,误导了好几篇后续改进的顶会论文,不过神奇地是提供的代码没有错:


二 MVSNet的后续改进论文
1.RMVSNet(CVPR2019)
Recurrent MVSNet for High-resolution Multi-view Stereo Depth Inference
RMVSNet是香港科技大学权龙教授团队对自己的MVSNet(ECCV2018)论文的改进,主要是把3D卷积换成GRU的时序网络来降低模型大小,然后loss也改成了多分类的交叉熵损失,其他都一样,还是在四分之一的图上预测深度。模型变小了,但是其实精度也小有降低。
代码是用tensorflow写的,和MVSNet代码合到一起了,github链接:
https://github.com/YoYo000/MVSNetgithub.com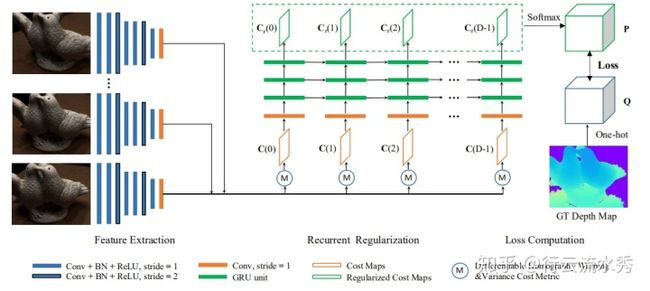
2. MVSNet(pytorch版本)
这里需要特别强调一下,Xiaoyang Guo 同学把原来MVSNet的tensorflow代码改成了pytorch,这为几乎后续所有改进MVSNet的论文提供了极大的帮助,后续的论文几乎都是在Xiaoyang Guo同学的MVSNet_pytorch上改的。而且Xiaoyang Guo同学的MVSNet_pytorch已经比原来的MVSNet的效果好了不少,而后续的改进都是对比MVSNet论文里的结果,所以真正的提升其实并不大,后续改进应该对比Xiaoyang Guo同学的MVSNet_pytorch。
MVSNet论文里的结果和Xiaoyang Guo同学的MVSNet_pytorch在DTU数据集上的对比结果,可以看出Xiaoyang Guo已经提升了不少MVSNet的效果。

Xiaoyang Guo同学的MVSNet_pytorch 链接:
https://github.com/xy-guo/MVSNet_pytorchgithub.com3 PointMVSNet(ICCV2019)
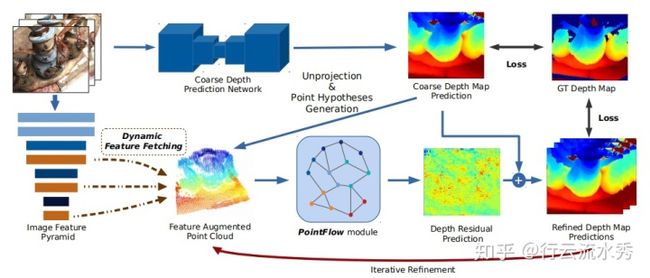
Point-Based Multi-View Stereo Network ,清华大学
PointMVSNet(ICCV2019)也是2019年的改进MVSNet论文,想法是预测出深度depth信息然后和图片构成三维点云,再用3D点云的算法去优化depth的回归。后续复现其代码发现无法得到PointMVSNet论文里的精度,不知道是不是因为3D点云的算法问题。
改的MVSNet_pytorch的代码,PointMVSNet github链接:https://github.com/callmeray/PointMVSNet
4 P-MVSNet(ICCV2019)
P-MVSNet: Learning Patch-wise Matching Confifidence Aggregation for Multi-View Stereo 华中科技大学
P-MVSNet对MVSNet的改进主要在于采用传统三维重建算法中Patch-wise。还没有找到其代码。

5 MVSCRF(ICCV2019)
MVSCRF: Learning Multi-view Stereo with Conditional Random Fields
改进点:接入了一个CRF模块
清华大学。没有找到其代码。

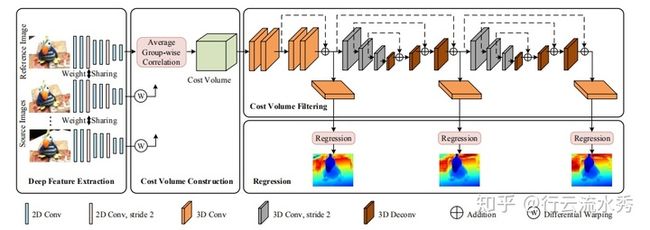
6 cascade MVSNet(CVPR2020)
Cascade Cost Volume for High-Resolution Multi-View Stereo and Stereo Matching
阿里,GitHub链接:https://github.com/alibaba/cascade-stereo
改的MVSNet_pytorch的代码,主要是把MVSNet的模型改成了层级的,先预测下采样四分之一的深度,然后用来缩小下采样二分之一的深度,再用其缩小原始图片大小的深度,这样层级的方式,可以采用大的深度间隔和少的深度区间,从而可以一次训练更多数据。
另外由于双目立体匹配和MVSNet的MVS都是用了cost volume,双目立体匹配是用两张图片估计’深度‘,MVS的MVSNet是用三张及以上图片预测深度,所以其实模型差不多,都是相同的,cascade MVSNet也把改进思想用到了双目立体匹配上,一篇论文做了两份工作。
7 CVP-MVSNet(CVPR2020)
Cost Volume Pyramid Based Depth Inference for Multi-View Stereo
澳大利亚国立和英伟达,github链接:https://github.com/JiayuYANG/CVP-MVSNet
也是改的MVSNet_pytorch的代码,和上一个cascade MVSNet比较类似,也是先预测出深度信息然后用来缩小更大的图片的深度,CVP-MVSNet相比cascade MVSNet也缩小了cost volume的范围。

8 Fast-MVSNet(CVPR2020)
Fast-MVSNet: Sparse-to-Dense Multi-View Stereo With Learned Propagation
and Gauss-Newton Refifinement,上海科技大学
也是改的MVSNet_pytorch的代码,github链接:https://github.com/svip-lab/FastMVSNet
Fast-MVSNet采用稀疏的cost volume以及Gauss-Newton layer,目的是提高MVSNet的速度。

9 CIDER(AAAI 2020)
Learning Inverse Depth Regression for Multi-View Stereo with Correlation Cost Volume , 华科的
GitHub链接:https://github.com/GhiXu/CIDER
CIDER主要采用采用group的方式提出了一个小的cost volume
10 PVA-MVSNet(ECCV2020)
Pyramid Multi-view Stereo Net with Self-adaptive View Aggregation
北大,GitHub链接:https://github.com/yhw-yhw/PVAMVSNet
主要采用attention机制来自适应学习一些权重,比如不同view的权重。

11 UCSNet(CVPR2020)
Deep Stereo using Adaptive Thin Volume Representation with Uncertainty Awareness
github链接:
https://github.com/touristCheng/UCSNetgithub.comUCSNet和上面两个差不多,不过更好一点,depth interval 可以自动调,最大层度的进行网络层级,通过下采样四分之一的深度结果来缩小cost volume和深度的范围,从而让模型尽可能小。

12 D2HC-RMVSNet(ECCV2020 Spotlight)
Dense Hybrid Recurrent Multi-view Stereo Net with Dynamic Consistency Checking
github链接(还未提供):
yhw-yhw/D2HC-RMVSNet
还没细看,大概和RMVSNet差不多,用LSTM来处理cost volume,同时提出一种Dynamic Consistency Checking来后融合。
可能因为在Tanks榜单上排名较高(目前滑落到第二,论文提交时第一),所以拿了ECCV2020的Spotlight。
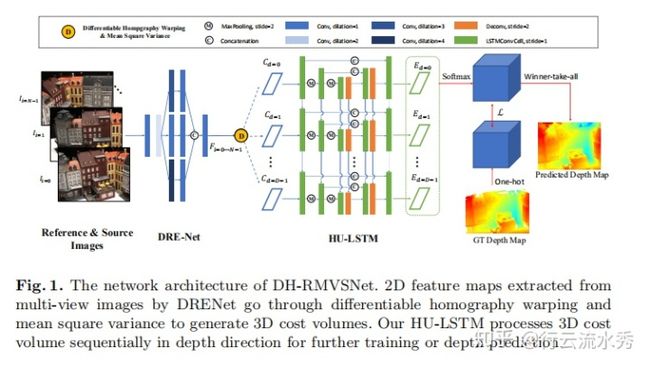
13 Visibility-aware Multi-view Stereo Network(BMVC2020 oral)

github:https://github.com/jzhangbs/Vis-MVSNet
香港科技大学的权龙教授团队的最新的一篇论文,发表在BMVC2020上,主要是考虑了别的基于深度学习的论文都没考虑的一个问题:多视图构建cost volume的可见性问题。代码融合多阶段和group Cost Volume等技巧。
目前在tanks榜单的intermediate上排名第一。
总结:
香港科技大学的权龙教授团队的Yao Yao把双目立体匹配的cost volume,引入了基于深度学习的三维重建领域,提出了MVSNet,并整理了DTU数据集,开创了通过深度模型预测深度进行三维重建的一个新领域。
后续Xiaoyang Guo 同学把原来MVSNet的tensorflow代码改成了pytorch框架,极大地增加了代码的可读性,方便了后续一系列对MVSNet的改进。也提高了改进的基点。
得特别感谢香港科技大学的权龙教授团队和Xiaoyang Guo 同学。
由于tanks and temples榜单评价的是点云,阻碍tanks and temples榜单上排名的可能并不是深度值预测的不好,而是其他的问题。三维重建涉及的东西很多。榜单上排名高的模型可能是因为在模型以外的地方做了东西。。