【paddle深度学习高层API七日打卡营】三岁水课第四天——年夜饭的故事
paddle深度学习高层API第四天
-
-
- 课程回看
- 任务目标
- 基本概念
- 什么是情感分析
- 文本分类通用步骤
- 原理介绍
- 词向量到句子向量
-
- 循环神经网络RNN
- 循环神经网络—长短时记忆网络LSTM
- 全连接层、线性分类分类器
- 实践
-
- PaddleNLP和Paddle框架是什么关系?
- 通用流程
- 数据集处理
-
- 自定义数据集
- 查看数据
- 数据处理
-
- 词转换成ID
- 构造函数(dataloder)
- 模型搭建
-
- 模型的配置和训练
-
- 模型配置
- 模型训练
- 预测
- 修改3分类
- 总结
-
大家好,这里是三岁,别的不会,擅长白话,今天就是我们的白话系列,内容是paddle2.0新出的高程API,在这里的七日打卡营0基础学习,emmm我这个负基础的也来凑凑热闹,那么就开始吧~~~~
注:以下白话内容为个人理解,如有不同看法和观点及不对的地方欢迎大家批评指正!
课程传送门
注:由于播放器的进度条遮挡,小姐姐的全貌比较难截全,希望各位见谅,特别是小姐姐见谅[戳戳手]
- 老师提到的要点都已经拿 粗体加斜体 标注了!!!(尽职课代表系列)

课程回看
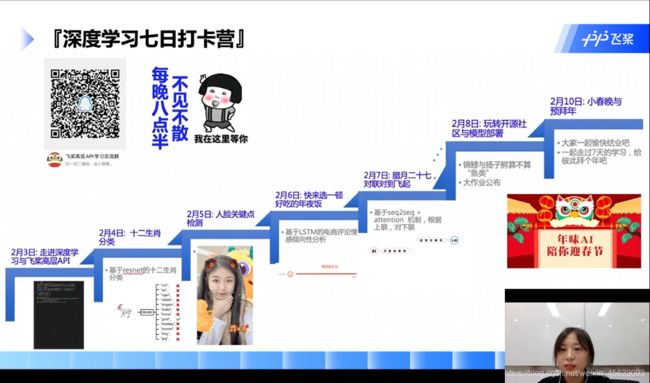
任务目标

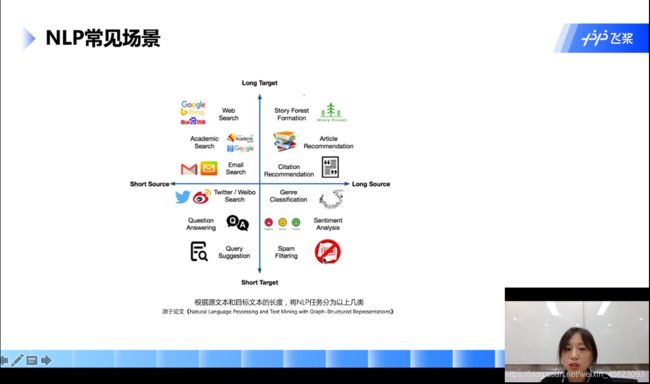
基本概念

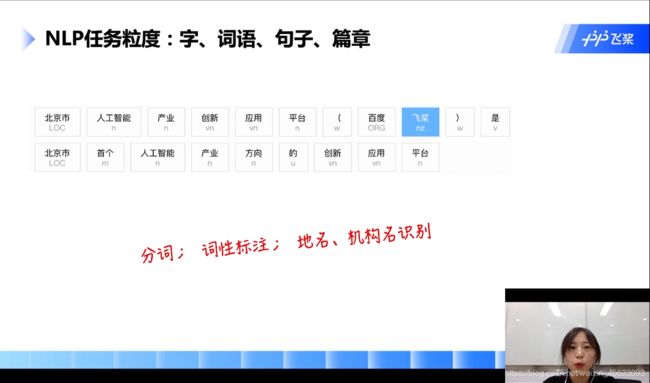
主要的有:分词、词性标注、地名、机构名、快递单信息抽签、搜索、视频文章推荐、智能客服、对话、低质量文章识别……
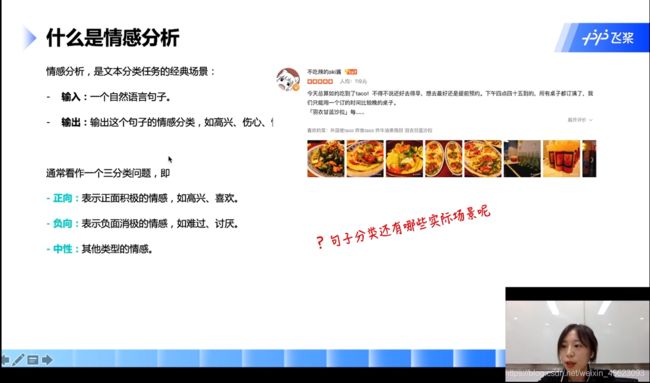
什么是情感分析
通过一个自然语句的输入分析,这一句话的情感,可以分为正向、负向、中性
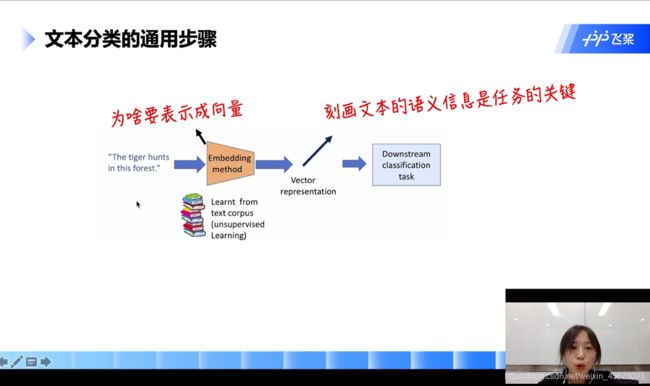
文本分类通用步骤
输入:一个自然语言的句子
通过:分词阶段
生成:词向量
接入:一个任务网络(分类器)
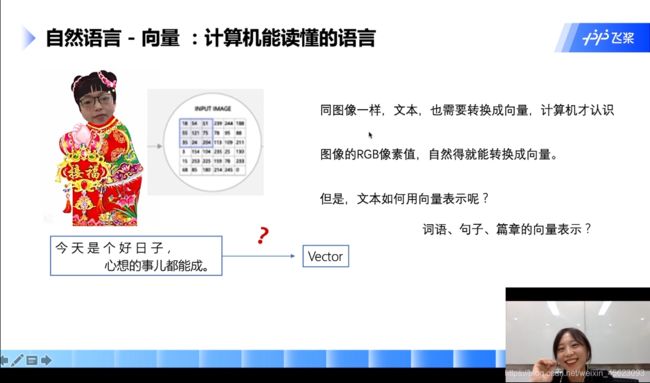
- 为什么词语要以向量的方式来表示?
计算机处理的二进制的数据,只有用向量(张量)表示才能够跟好的处理
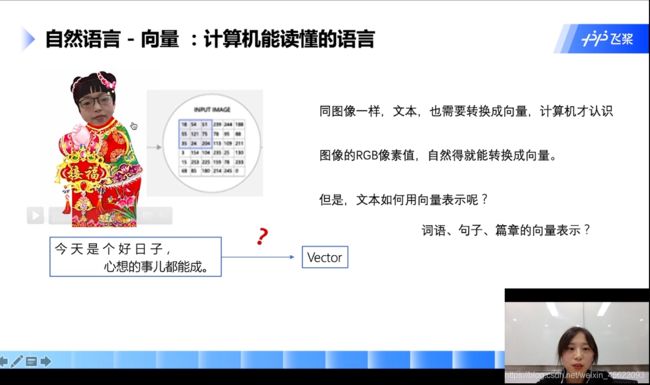
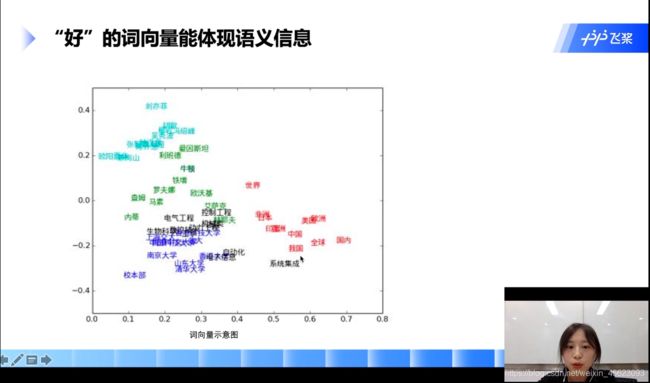
原理介绍

第一步:输入一个自然语言
第二步:切词(或者切字)
第三步:转换成ID(根据词语在词汇表的位置也就是id)
第四步:生成数组(在id位置是1其他位置是0)
注:按照图中的情况进行假设词汇表的长度是5w,那么3个词生成的数组就是(3,5w)
第五步:上面的数组乘以数组(数组的维度是词汇表长度*5的矩阵)
第六步:生成一个新的矩阵(句子长度 * 词向量的长度)
以图为例子: 3个词每一个词用5维的向量表示
第六步:批量处理
如下图:128个数据进行统一的处理就生成了一个3 * 5* 128的三维Tensor,Tensor的大小就是(128, 5, 3)[在里面句子的长度要相等长的要截断,短的要补齐]
第七步:通过黑盒得到一个句子向量(句子的长度这个维度被抹除了)

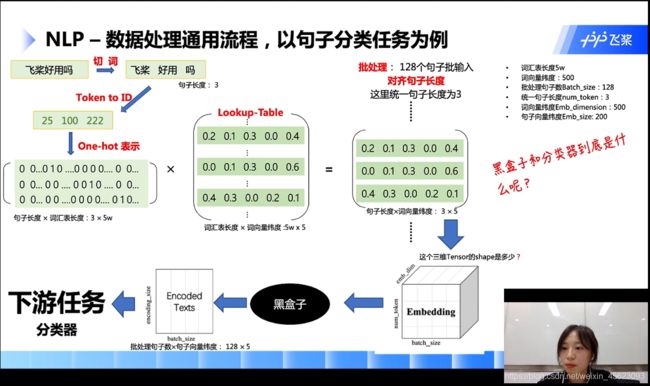
词向量到句子向量
- 加权平均法:
把单个的词向量加起来就是句子向量
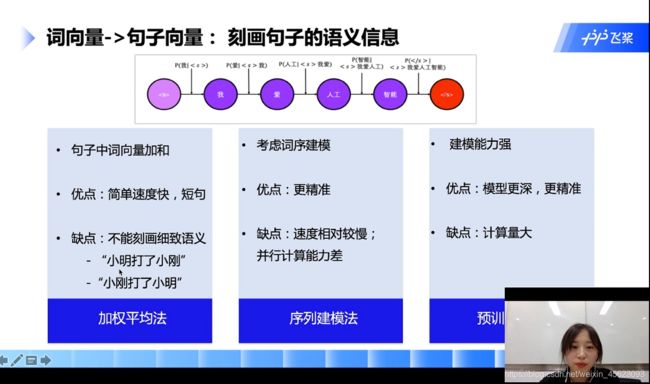
- 序列建模法:
针对加权法的缺点改进的建模方法
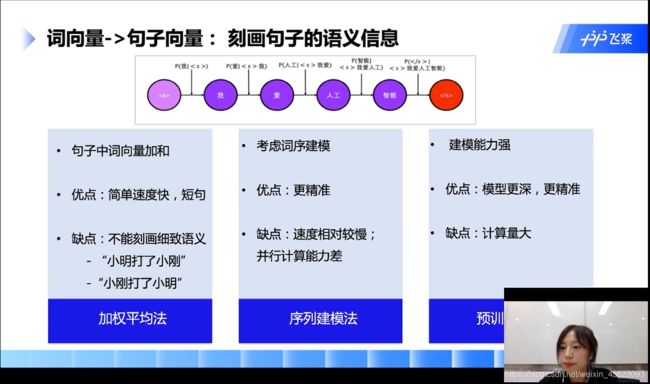
- 预训练模型法
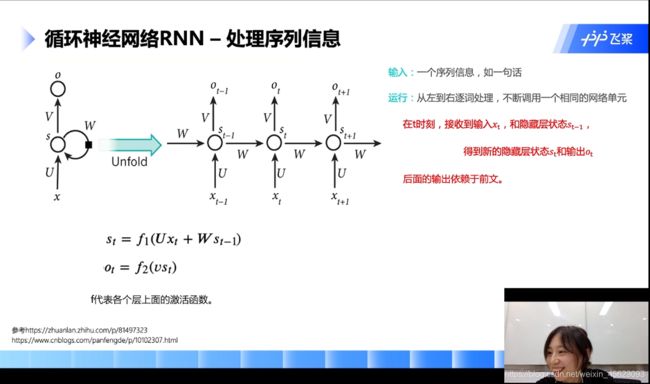
循环神经网络RNN
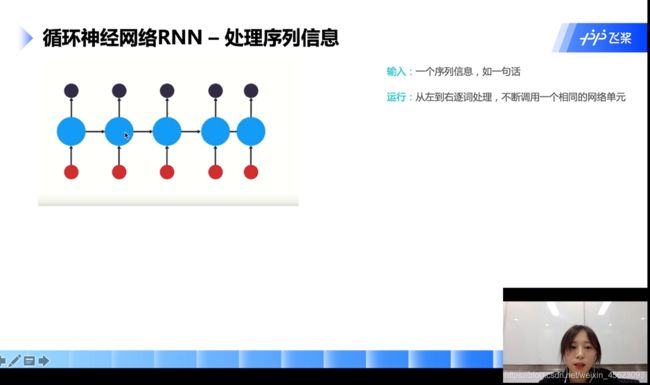

RNN的关键点:词向量从左往右逐词处理,不断的挑整网络。
每个时刻调用的是同一个网络

循环神经网络—长短时记忆网络LSTM
里面也是依次逐词处理的网络
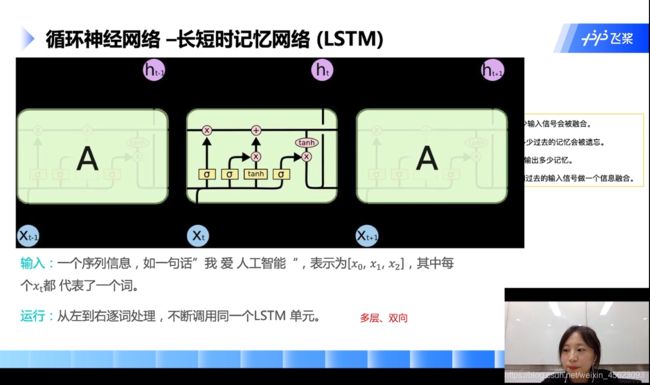
里面涉及了历史记忆和历史的遗忘值,有就计算,没有就不管

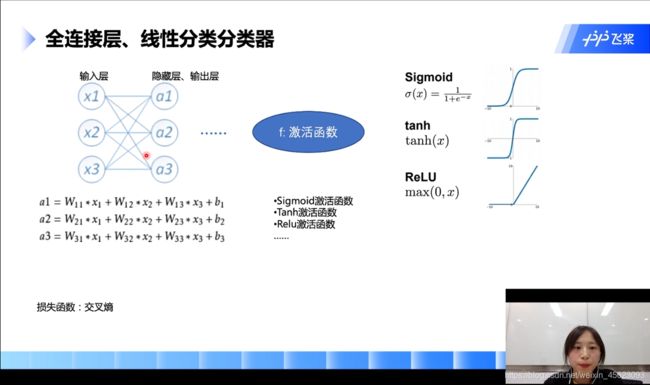
全连接层、线性分类分类器
全连接层顾名思义:输入层和隐藏层逐个连接
实践



-
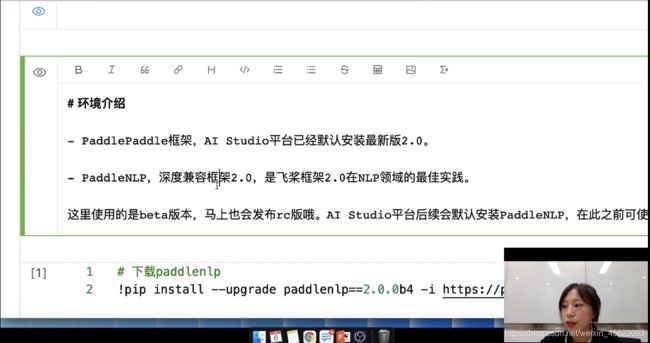
PaddlePaddle框架,AI Studio平台已经默认安装最新版2.0。
-
PaddleNLP,深度兼容框架2.0,是飞桨框架2.0在NLP领域的最佳实践。
这里使用的是beta版本,马上也会发布rc版哦。AI Studio平台后续会默认安装PaddleNLP,在此之前可使用如下命令安装。
# 下载paddlenlp
# !pip install --upgrade paddlenlp==2.0.0b4 -i https://pypi.org/simple
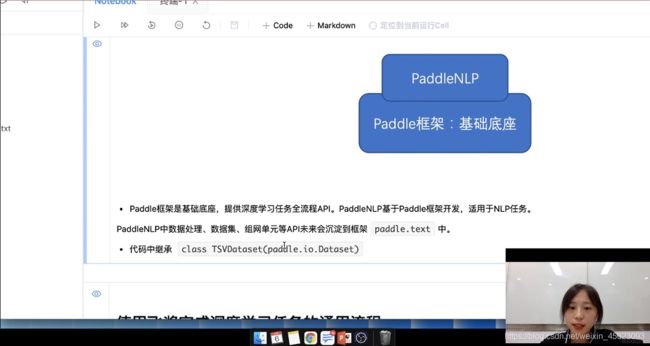
PaddleNLP和Paddle框架是什么关系?

- Paddle框架是基础底座,提供深度学习任务全流程API。PaddleNLP基于Paddle框架开发,适用于NLP任务。
PaddleNLP中数据处理、数据集、组网单元等API未来会沉淀到框架
paddle.text中。
通用流程

数据集处理
自定义数据集
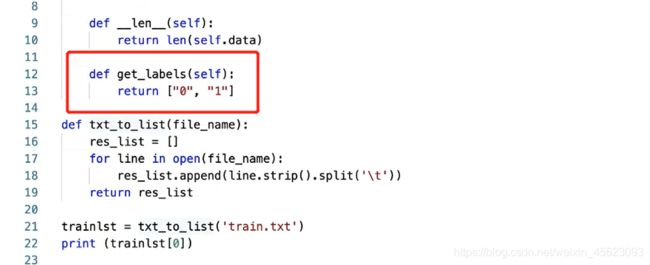
映射式(map-style)数据集需要继承
paddle.io.Dataset
__getitem__: 根据给定索引获取数据集中指定样本,在 paddle.io.DataLoader 中需要使用此函数通过下标获取样本。__len__: 返回数据集样本个数, paddle.io.BatchSampler 中需要样本个数生成下标序列。
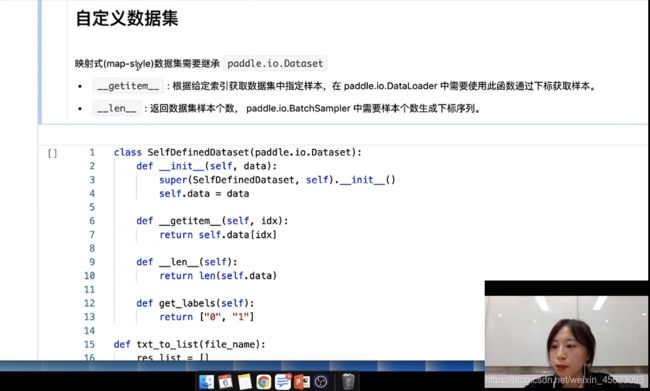
先继承paddle.io.Dataset然后对函数进行初始化,接着定义我们的__getitem__和__len__
定义get_labels是一个文本标签,这里是二分类所以结果是[‘0’, ‘1’]
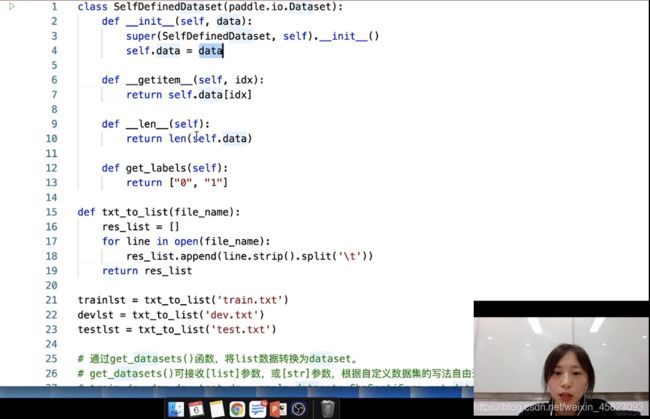
紧接着定义一个txt_to_list函数,把读取的文本转换成列表
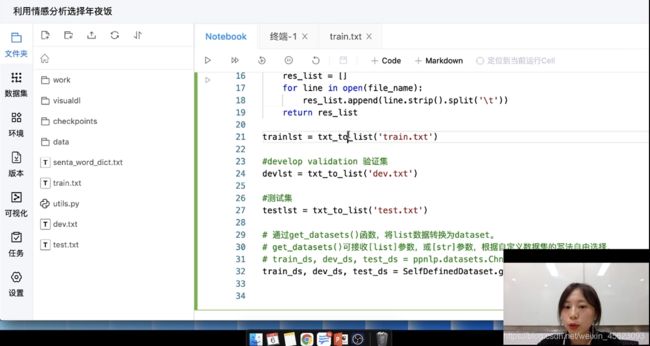
验证集:验证模型在训练过程中的表现,通过负反馈调整模型
测试集:看模型最后的表现。
个人理解:训练集:上课;验证集:周考,月考;测试集:期末考
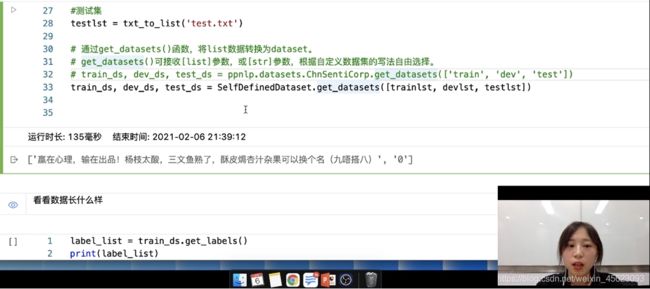
通过SelfDefinedDataset.get_datasets对数据集进行处理得到paddle.io.Dataset类型的结果
查看数据
调用接口和函数直接查看处理以后的数据

数据处理
使用paddle.io.DataLoader接口多线程异步加载数据。
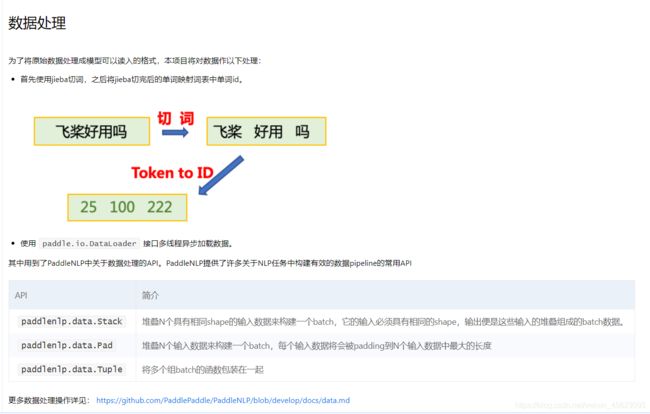
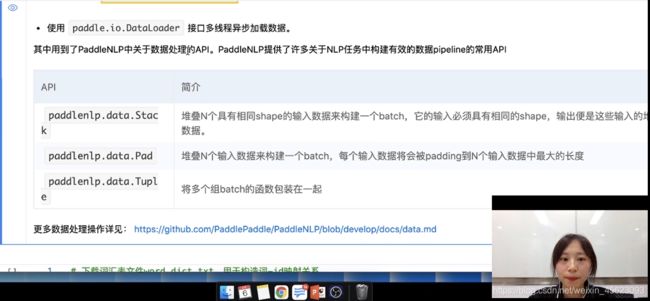
词转换成ID
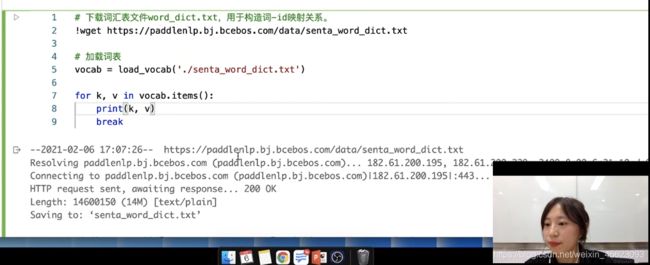
# 下载词汇表文件word_dict.txt,用于构造词-id映射关系。
# !wget https://paddlenlp.bj.bcebos.com/data/senta_word_dict.txt
# 加载词表
vocab = load_vocab('./senta_word_dict.txt')
for k, v in vocab.items():
print(k, v)
break
构造函数(dataloder)
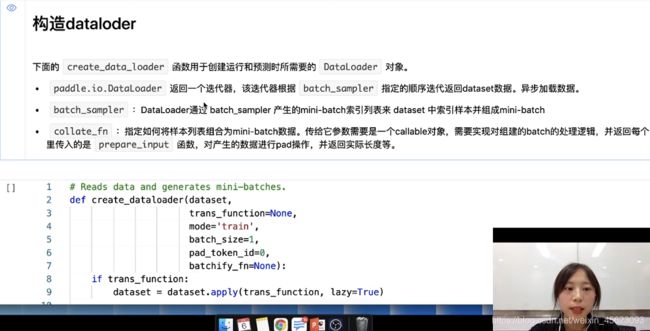
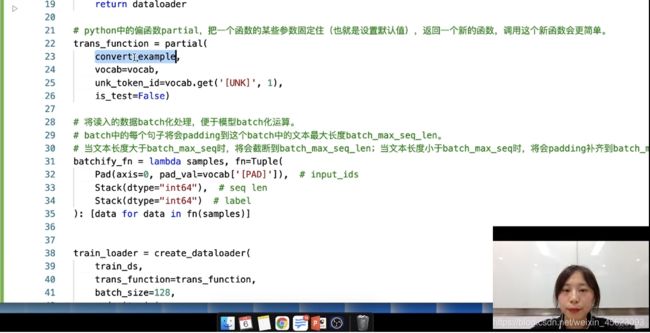
把刚刚的句子(词)通过词典转换成一个ID序列
# python中的偏函数partial,把一个函数的某些参数固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单。
trans_function = partial(
convert_example,
vocab=vocab,
unk_token_id=vocab.get('[UNK]', 1),
is_test=False)
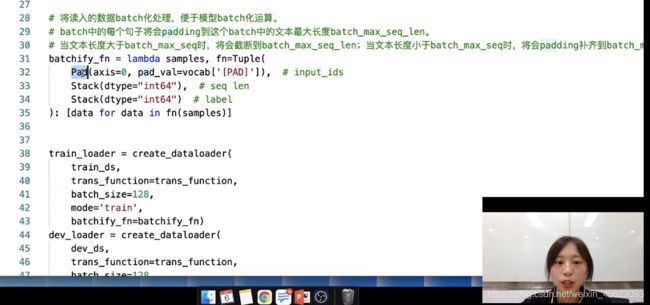
把读入的数据统一到一定的长度(使用的是paddlenlp中专门处理的api)
# 将读入的数据batch化处理,便于模型batch化运算。
# batch中的每个句子将会padding到这个batch中的文本最大长度batch_max_seq_len。
# 当文本长度大于batch_max_seq时,将会截断到batch_max_seq_len;当文本长度小于batch_max_seq时,将会padding补齐到batch_max_seq_len.
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=vocab['[PAD]']), # input_ids
Stack(dtype="int64"), # seq len
Stack(dtype="int64") # label
): [data for data in fn(samples)]

指定数字的返回形式是否是list,指定组合数据的方式等
# return_list 数据是否以list形式返回
# collate_fn 指定如何将样本列表组合为mini-batch数据。传给它参数需要是一个callable对象,需要实现对组建的batch的处理逻辑,并返回每个batch的数据。在这里传入的是`prepare_input`函数,对产生的数据进行pad操作,并返回实际长度等。
dataloader = paddle.io.DataLoader(
dataset,
return_list=True,
batch_size=batch_size,
collate_fn=batchify_fn)
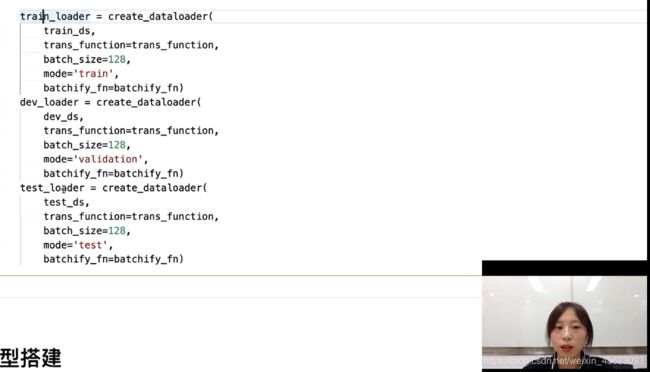
对以上函数的调用就把:训练集,验证集,测试集都处理好了
模型搭建
调用paddle.nn.Embedding把句子中的向量进行提取
生成三维数据通过黑盒(seq2vec)得到词向量

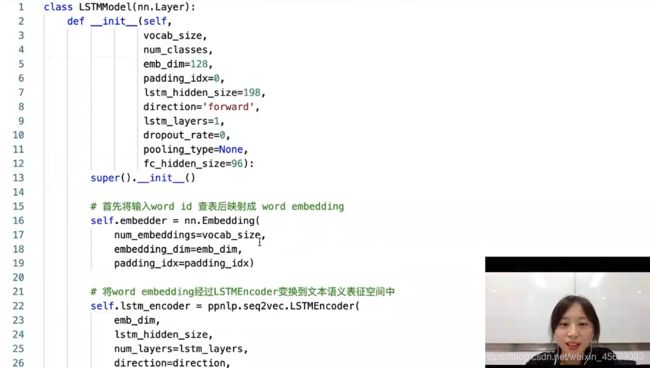
def __init__(self,
vocab_size,
num_classes,
emb_dim=128, # 词向量的维度
padding_idx=0,
lstm_hidden_size=198, # 隐藏层的维度
direction='forward',
lstm_layers=1,
dropout_rate=0,
pooling_type=None,
fc_hidden_size=96):
super().__init__()
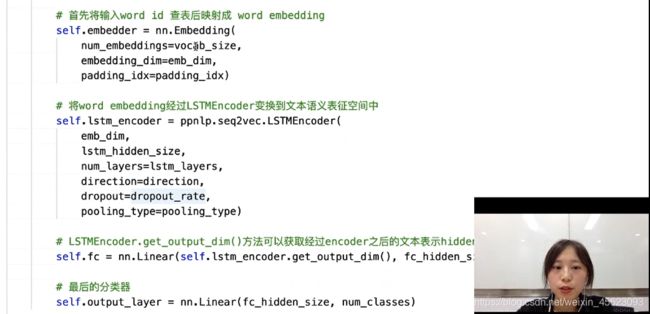
构造向量表(三维数据)
# 首先将输入word id 查表后映射成 word embedding
self.embedder = nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=emb_dim,
padding_idx=padding_idx)
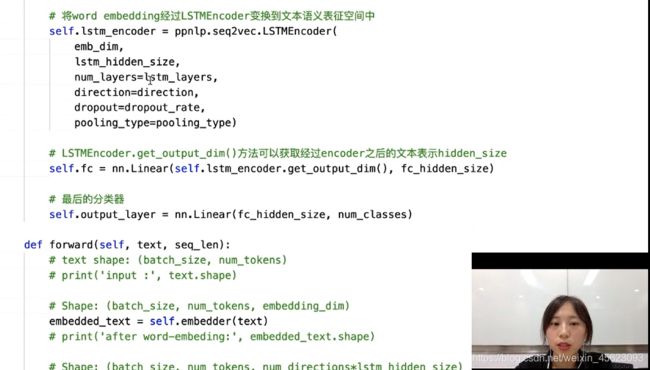
把词向量喂给网络得到句子的输出
# 将word embedding经过LSTMEncoder变换到文本语义表征空间中
self.lstm_encoder = ppnlp.seq2vec.LSTMEncoder(
emb_dim,
lstm_hidden_size,
num_layers=lstm_layers,
direction=direction,
dropout=dropout_rate,
pooling_type=pooling_type)
接入全连接层和分类器得到最后的结果正负样本(0, 1)
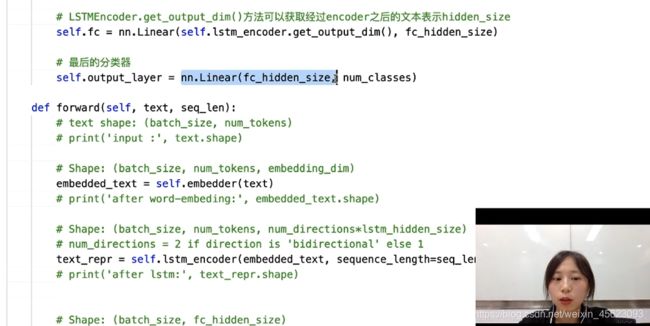
# LSTMEncoder.get_output_dim()方法可以获取经过encoder之后的文本表示hidden_size
self.fc = nn.Linear(self.lstm_encoder.get_output_dim(), fc_hidden_size)
# 最后的分类器
self.output_layer = nn.Linear(fc_hidden_size, num_classes)
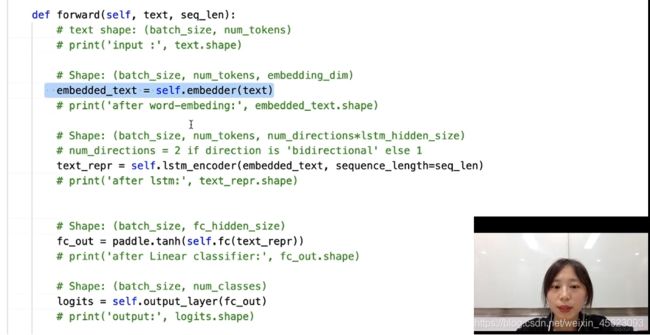
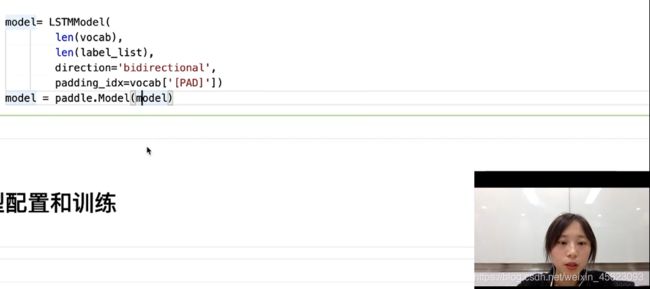
定义并封装网络
model= LSTMModel(
len(vocab),
len(label_list),
direction='bidirectional',
padding_idx=vocab['[PAD]'])
model = paddle.Model(model)
模型的配置和训练
模型配置
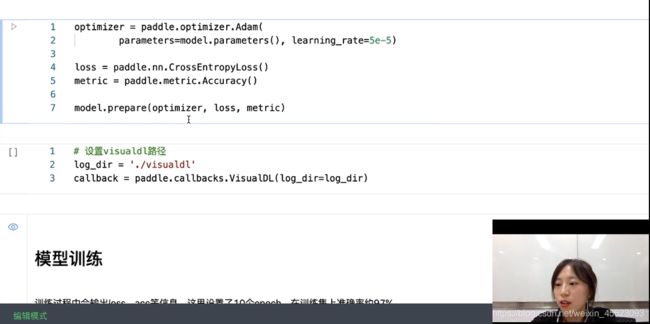
使用优化器指定学习率
生成评价指标然后用model.prepare进行封装
optimizer = paddle.optimizer.Adam(
parameters=model.parameters(), learning_rate=5e-5)
loss = paddle.nn.CrossEntropyLoss()
metric = paddle.metric.Accuracy()
model.prepare(optimizer, loss, metric)
模型训练
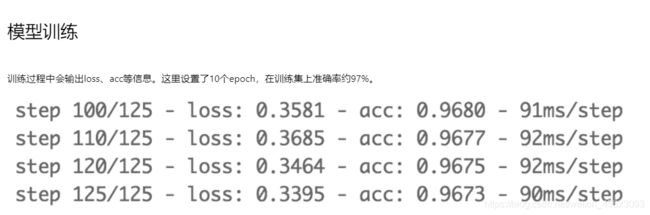
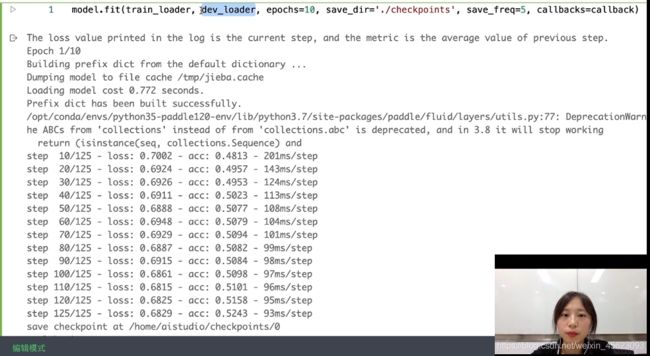
调用model.fit进行训练
model.fit(train_loader, dev_loader, epochs=10, save_dir='./checkpoints', save_freq=5, callbacks=callback)
在验证集对数据进行测试
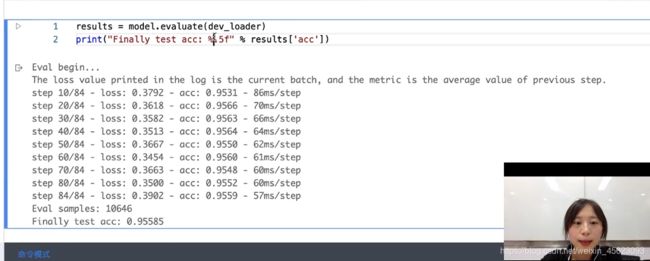
预测
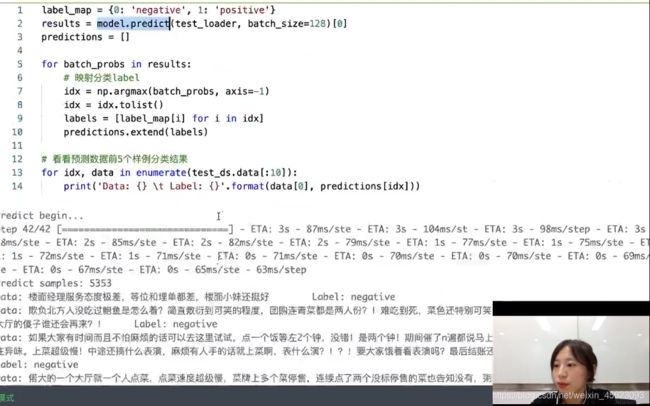
调用model.predict进行预测
label_map = {
0: 'negative', 1: 'positive'}
results = model.predict(test_loader, batch_size=128)[0]
predictions = []
for batch_probs in results:
# 映射分类label
idx = np.argmax(batch_probs, axis=-1)
idx = idx.tolist()
labels = [label_map[i] for i in idx]
predictions.extend(labels)
# 看看预测数据前5个样例分类结果
for idx, data in enumerate(test_ds.data[:10]):
print('Data: {} \t Label: {}'.format(data[0], predictions[idx]))
修改3分类
总结
- 重点

经过一节课的学习,对nlp这个一直以来认为冰山的可怕的东西进行了理解,知道了什么是词向量,什么是句向量,对于训练子类的有了一定的理解,虽然还是远远不够的。接下来继续努力!
这里是三岁,飞桨社区最菜的小白
我在AI Studio上获得黄金等级,点亮7个徽章,来互关呀~
CSDN首页
如果喜欢记得关注呦!!!
三岁出品虽水必精!