大数据实操篇 No.16-记一次完整的Flink流计算案例(DataStream API)
第1章 简介
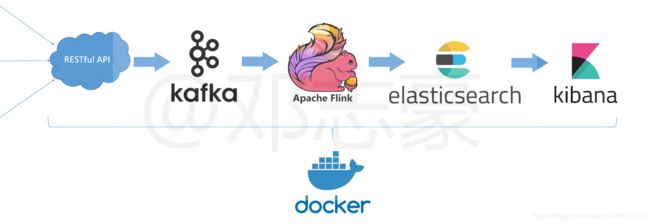
本篇文章采用Flink DataStream API完成一次端到端的完成流计算案例,将数据从Kafka抽取,写入Elasticsearch中,并且用kibana动态的展示出来。(客户端=>Web API服务=>Kafka=>Flink=>Elasticsearch=>Kibana)。
第2章 案例设计
先定一个简单的需求(就根据当下的疫情情况来做吧):统计各地区新冠疫情风险等级。
我们假定每个地区确诊病例(0-10]例为低风险地区,(10-50]例为中风险地区,大于50例为高风险地区。
概要设计:
- 模拟一个数据源,发送各地区疫情确诊病例;
- 通过Flink进行窗口计算,每10秒钟一个窗口,滑动窗口5秒,统计出窗口内出现的确诊病例;
- 将统计出的实时结果写入Elasticsearch中,并通过Kibana可视化的展示出一个排行榜。
第3章 docker-compose构建环境
3.1 创建docker-compose.yml文件
这里不详细展示了,详见后续上传的github。
3.2 启动容器
docker-compose启动容器,包含(zookeeper,flink,kafka,elasticsearch,kibana)
docker-compose up -d
停止
docker-compose down
第4章 创建Restful API接口项目
4.1建立API接口项目
这里不详细展示了,详见后续上传的github。
4.2打包项目
mvn clean package -DskipTests
4.3创建docker镜像
api项目我们单独创建一个容器
docker build -t lotemall-webapi-es .
4.4 运行容器
docker run --link kafka:kafka --net flink-kafka2es_default -e TZ=Asia/Shanghai -d -p 8090:8080 lotemall-webapi-es
flink-kafka2es_default 通过docker network ls查询,如下图:

第5章 创建Flink作业
5.1 编写Flink作业代码
Kafka2ESByEnd2End 主函数类:
/**
* 疫情低、中、高风险地区 (假定疫情时刻在变化)
* 1-10 低风险 0
* 11-50 中风险 1
* >=51 高风险 2
* 数据源:kafka {"city_code":"SZ","count":"6","timestamp":"1612847156743"}
* 数据汇:ES {"city_code":"SZ","level":"0"}
*/
public class Kafka2ESByEnd2End {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 并行度设置
env.setParallelism(4);
// 设置Checkpoint 每个60*1000ms一次cp
env.enableCheckpointing(60 * 1000, CheckpointingMode.EXACTLY_ONCE);
// 10分钟内 重启三次 每次间隔10秒 超过则job失败
env.setRestartStrategy(RestartStrategies.failureRateRestart(3, org.apache.flink.api.common.time.Time.of(10,TimeUnit.MINUTES), org.apache.flink.api.common.time.Time.of(10,TimeUnit.SECONDS)));
//设置statebackend 暂用Memory
env.setStateBackend(new MemoryStateBackend(true));
// 设置EventTime为事件时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// source
Properties properties = new Properties();
// 集群配置多个kafka地址properties.setProperty("bootstrap.servers", "kafka120:9092,kafka121:9092");
properties.setProperty("bootstrap.servers", "kafka:9092");
properties.setProperty("group.id", "grouplevel");
DataStream<Covid19Event> dataStream = env
.addSource(new FlinkKafkaConsumer011<Covid19Event>("covid19count-log", new Covid19DesSchema(), properties));
// sink
List<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("elasticsearch", 9200, "http"));
// 集群add多个地址
//httpHosts.add(new HttpHost("127.0.0.1", 9200, "http"));
ElasticsearchSink.Builder<Tuple3<String,Integer,Long>> esSinkBuilder = new ElasticsearchSink.Builder<>(
httpHosts,
new Covid19ESSink()
);
// 算子计算
dataStream.assignTimestampsAndWatermarks(new Covid19Watermark())
.map(new Covid19MapFunc())
.keyBy(0)//可以访问keyedstate
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))//10秒钟的窗口,滑动间隔是5秒 滑动窗口可能触发两次计算
.aggregate(new Covid19AggFunc())
.addSink(esSinkBuilder.build());
env.execute("Covid19StaticLevel");
}
}
注意:SlidingEventTimeWindows窗口会触发多次,因为每条数据可能处于多个窗口中,会被触发计算多次。
**Covid19Watermark **自定义watermark类:
public class Covid19Watermark implements WatermarkStrategy<Covid19Event>{
@Override
public WatermarkGenerator<Covid19Event> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) {
return new Covid19WatermarkGenerator();
}
class Covid19WatermarkGenerator implements WatermarkGenerator<Covid19Event> {
private final long delayTime = 3000;// 毫秒
private long currentMaxTimestamp ;
@Override
public void onEvent(Covid19Event covid19Event, long eventTimestamp, WatermarkOutput watermarkOutput) {
currentMaxTimestamp = Math.max(currentMaxTimestamp, covid19Event.getTimestamp());
}
@Override
public void onPeriodicEmit(WatermarkOutput watermarkOutput) {
watermarkOutput.emitWatermark(new Watermark(System.currentTimeMillis() - delayTime));
}
}
}
Covid19MapFunc Map方法类:
public class Covid19MapFunc implements MapFunction<Covid19Event, Tuple3<String, Integer, Long>> {
/**
* Covid19Event -> Tuple3
* @param event
* @return
* @throws Exception
*/
@Override
public Tuple3<String, Integer, Long> map(Covid19Event event) throws Exception {
String cityCode = event.getCityCode();
Integer count = event.getCount();
Long timestamp = event.getTimestamp();
return new Tuple3<>(cityCode, count, timestamp);
}
}
Covid19AggFunc Window方法类:
public class Covid19AggFunc implements AggregateFunction<Tuple3<String, Integer, Long>, Tuple3<String, Integer, Long>, Tuple3<String, Integer, Long>> {
// 城市code -> 确诊数量
// private MapState mapState;
/**
* 初始化列累加器 .创建一个新的累加器,启动一个新的聚合,负责迭代状态的初始化
*
* @return
*/
@Override
public Tuple3<String, Integer, Long> createAccumulator() {
return new Tuple3<>("", 0, 0L);
}
/**
* 累加器的累加方法 来一条数据执行一次 对于数据的每条数据,和迭代数据的聚合的具体实现
*
* @param tpInput
* @param tpAcc
* @return 返回新的累加器
*/
@Override
public Tuple3<String, Integer, Long> add(Tuple3<String, Integer, Long> tpInput, Tuple3<String, Integer, Long> tpAcc) {
if (tpAcc.f0.equals(tpInput.f0)) {
return new Tuple3<>(tpInput.f0, tpInput.f1 + tpAcc.f1, tpInput.f2);
} else {
return tpInput;
}
}
/**
* 返回值 在窗口内满足2个,计算结束的时候执行一次,从累加器获取聚合的结果
*
* @param tpAcc
* @return
*/
@Override
public Tuple3<String, Integer, Long> getResult(Tuple3<String, Integer, Long> tpAcc) {
String city_code = tpAcc.f0;
Integer nowCount = tpAcc.f1;
Integer level;
if (nowCount.compareTo(50) > 0) {
//高风险
level = 2;
} else if (nowCount.compareTo(10) > 0 && nowCount.compareTo(50) <= 0) {
//中风险
level = 1;
} else {
//低风险
level = 0;
}
return new Tuple3<>(tpAcc.f0, level, tpAcc.f2);
}
/**
* 累加器合并 merge方法仅SessionWindow会调用
*
* @param stringIntegerTuple2
* @param acc1
* @return
*/
@Override
public Tuple3<String, Integer, Long> merge(Tuple3<String, Integer, Long> stringIntegerTuple2, Tuple3<String, Integer, Long> acc1) {
return null;
//return new Tuple2<>(stringIntegerTuple2.f0, stringIntegerTuple2.f1 + acc1.f1);
}
}
Covid19ESSink Elasticsearch Sink方法类:
public class Covid19ESSink implements ElasticsearchSinkFunction<Tuple3<String,Integer,Long>>, Serializable {
@Override
public void process(Tuple3<String, Integer, Long> element, RuntimeContext runtimeContext, RequestIndexer requestIndexer) {
requestIndexer.add(updateIndexRequest(element));
}
/* insert
public IndexRequest createIndexRequest(Tuple3 element) {
Map json = new HashMap<>();
//json.put("data", String.format("{\"city_code\":\"%s\",\"level\":%d,\"timestamp\":%s}",element.f0,element.f1,element.f2));
json.put("city_code", element.f0);
json.put("level", element.f1);
json.put("timestamp", element.f2);
return Requests.indexRequest()
.index("covid19-index")
.type("covid19-type")
.id(element.f0)
.source(json);
}
*/
// upsert
public UpdateRequest updateIndexRequest(Tuple3<String,Integer,Long> element) {
Map<String, Object> map = new HashMap<>();
//json.put("data", String.format("{\"city_code\":\"%s\",\"level\":%d,\"timestamp\":%s}",element.f0,element.f1,element.f2));
map.put("city_code", element.f0);
map.put("level", element.f1);
map.put("timestamp", element.f2);
UpdateRequest updateRequest=new UpdateRequest();
updateRequest.docAsUpsert(true).retryOnConflict();
return updateRequest
.index("covid19-index")
.type("covid19-type")
.id(element.f0)
.doc(map);
}
}
5.2 打包Flink任务
mvn clean package -DskipTests
5.3 提交Flink作业
通过Flink Dashboard提交job。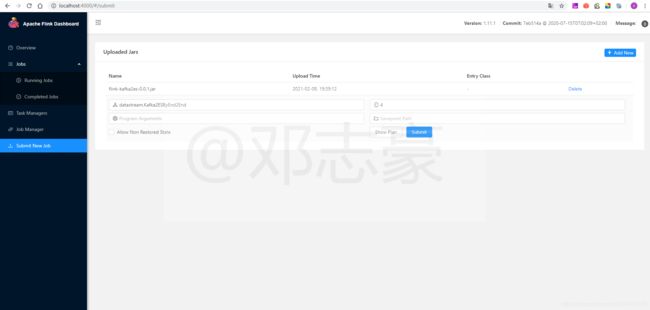
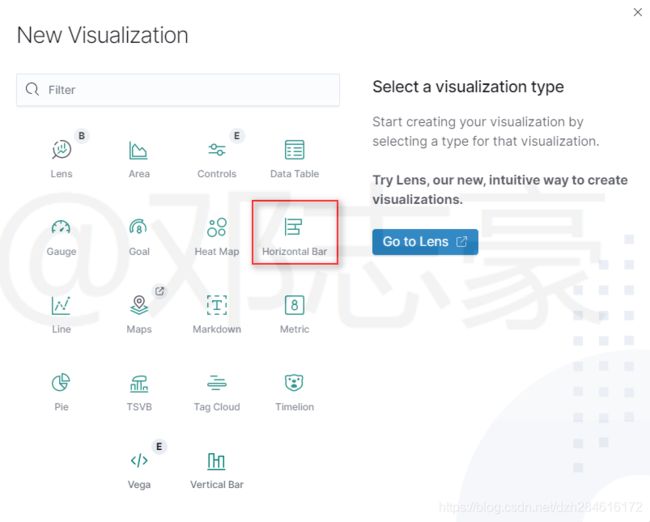
第6章 创建Kibana图表
咱们简单的创建一个水平的柱状图,用来显示地区风险排行榜。
图表效果见后面的验证。
到这里左右准备工作就完成了。下面我们检查一下运行的容器
第7章 检查运行中的容器
docker ps

可以看到所有我们需要的容器都已经运行起来:api项目,flink-jobmanager,flink-taskmanager,kafka,elasticsearch,kibana,zookeeper。
下面我们开始验证。
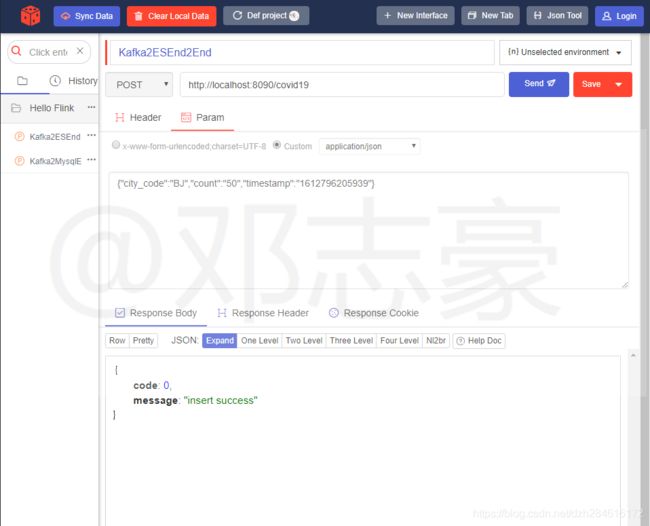
第8章 发起请求
通过接口测试工具,模拟应用产生数据,这里笔者直接发送json数据,包含城市code,新确诊的数量和时间戳。
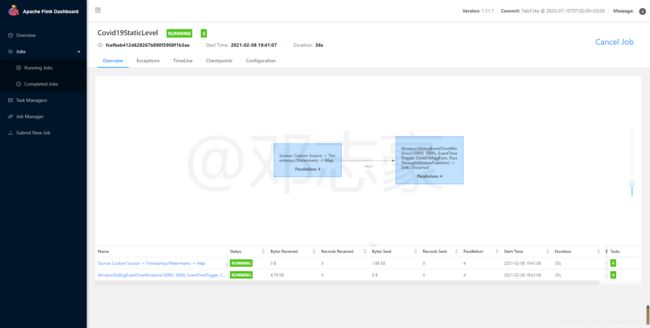
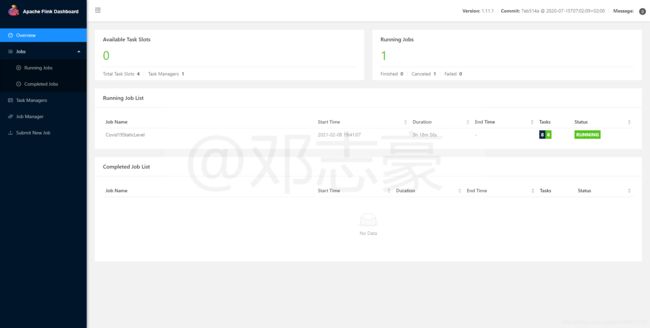
第9章 查看Flink作业运行情况
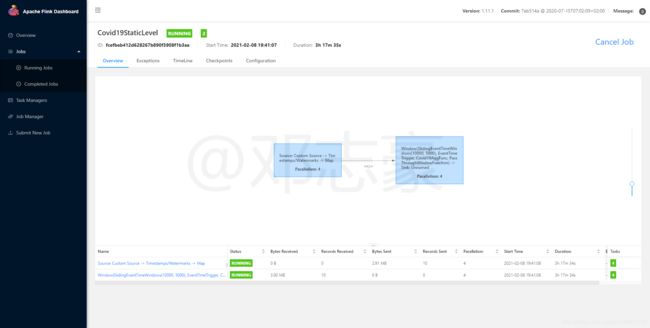
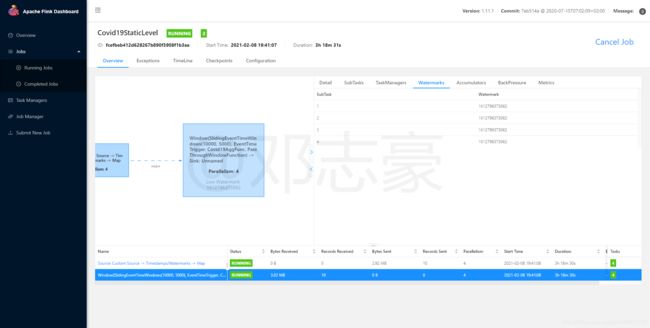
第10章 查看Kibana实时图表
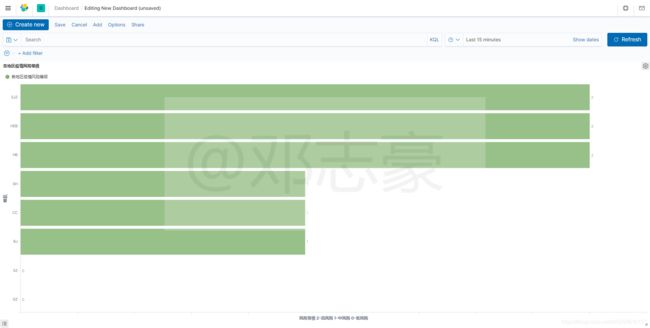
最终分析结果通过一个简单的图表展示(图表有些粗糙,见谅),数据以高风险=>中风险=>低风险地区降序排列,实时的展示出各地区风险等级。
到这里,我们就通过Flink DataStream API完成了一次完整的端到端的流计算案例。
最后,祝愿大家都健健康康,今年春节顺利返乡,与亲人团聚!希望疫情早日消散,2021牛气冲天!!!