NLP 基础--word2vec + text-cnn Demo
文章目录
-
-
-
-
- 1.数据处理
-
- 1.1 数据集
- 1.2 数据预处理
- 2. 文本卷积神经网络
- 3. 模型训练
- 4. 总结
-
-
-
本文是在 文本分类实战(二)—— textCNN 模型这个博客的基础上进行的。提供原始代码以及数据 github链接,以供下载。
1.数据处理
1.1 数据集
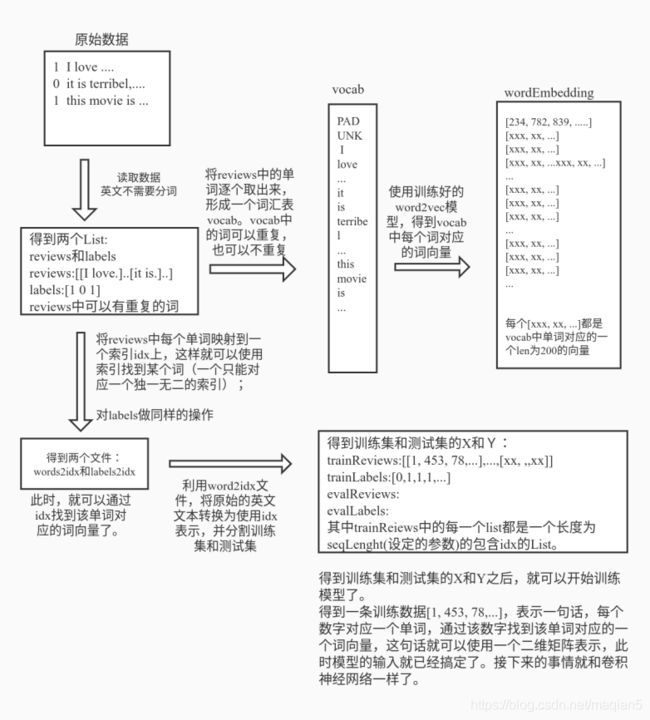
首先,数据集是采用的IMDB 电影影评,总共有三个数据文件,包括unlabeledTrainData.tsv,labeledTrainData.tsv,testData.tsv。在进行文本分类时需要有标签的数据(labeledTrainData),但是在训练word2vec词向量模型(无监督学习)时可以将无标签的数据一起用上。
labeledTrainData.tsv文件有三列,第一列是id,id由下划线分割为两部分,前一部分没有意义,下划线后面的一个数字表示该条评论的感情程度从1-10;第二列是评论的分类:1表示正面情绪,0表示负面情绪,从图中可以看出,1-10的感情程度是从负面向正面过渡;第三列是评论的文本数据。
unlabeledTrainData.tsv和test.tsv文件有两列,id和评价文本数据,id项中的下划线后面的数字均为0,表示没有标签。在这个小Demo中没有用到test.tsv文件。
1.2 数据预处理
一. 形成数据文件
下面的代码可以分为3步:
- step1: 将labeled和unlabeled两个文件中的数据读取出来
- step2: 分别清洗labeled和unlabeled中的review字段,即清洗文本数据。并将所有文本数据保存在一个单独的文件中,以备后面训练word2vec模型使用。
- step3: 将清洗之后的labeled数据保存为新的csv文件,该文件包含三列元素,分别为review, sentiment, rate,即分别为评论文本数据、感情色彩分类(1/0)、感情程度(1-10)。
# data_preprocess.py
# coding=utf-8
import pandas as pd
from bs4 import BeautifulSoup
import sys
reload(sys)
sys.setdefaultencoding('utf8')
# step1: 将labeled和unlabeled两个文件中的数据读取出来
with open("./data/unlabeledTrainData.tsv", "r") as f:
unlabeledTrain = [line.strip().split("\t") for line in f.readlines() if len(line.strip().split("\t")) == 2]
with open("./data/labeledTrainData.tsv", "r") as f:
labeledTrain = [line.strip().split("\t") for line in f.readlines() if len(line.strip().split("\t")) == 3]
# unlabeledTrain[1] 表示第一条数据
unlabel = pd.DataFrame(unlabeledTrain[1:], columns=unlabeledTrain[0])
label = pd.DataFrame(labeledTrain[1:], columns=labeledTrain[0])
# print 'unlabel:', unlabel
# print 'label:', label
# 得到感情程度
def getRate(subject):
splitList = subject[1:-1].split("_")
return int(splitList[1])
# 清洗数据
def cleanReview(subject):
# 数据处理函数
beau = BeautifulSoup(subject)
newSubject = beau.get_text()
newSubject = newSubject.replace("\\", "").replace("\'", "").replace('/', '').replace('"', '').replace(',', '').replace(
'.', '').replace('?', '').replace('(', '').replace(')', '')
newSubject = newSubject.strip().split(" ")
newSubject = [word.lower() for word in newSubject]
newSubject = " ".join(newSubject)
return newSubject
# step2:
unlabel["review"] = unlabel["review"].apply(cleanReview)
label["review"] = label["review"].apply(cleanReview)
# 将有标签的数据和无标签的数据合并
newDf = pd.concat([unlabel["review"], label["review"]], axis=0)
# 保存成txt文件
newDf.to_csv("./data/preProcess/wordEmbdiing.txt", index=False)
# step3:
label["rate"] = label["id"].apply(getRate)
newLabel = label[["review", "sentiment", "rate"]]
newLabel.to_csv("./data/preProcess/labeledTrain.csv", index=False)
二. 训练word2vec模型
通常情况下,可以采用开源的数据集进行word2vec模型的训练,例如采用维基语料库、百度语料、搜狗实验室中的各个语料。当然,你也可以像这个Demo中一样,采用自己的数据集进行word2vec模型训练。
在上面的代码中,将所有文本数据保存在一个单独的文件中(wordEmbdiing.txt),就是要训练word2vec模型使用。
在我的另一个博客《NLP基础–word2vec的使用Demo》中已经介绍了如何训练word2vec模型,这里就不再赘述。代码如下。执行代码之后,会出现一个word2Vec.bin文件,这就是训练好的word2Vec模型,在接下来的步骤中,将会使用到。
# train_word2vc_model.py
# coding=utf-8
import logging
import gensim
from gensim.models import word2vec
# 设置输出日志
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
# 直接用gemsim提供的API去读取txt文件,读取文件的API有LineSentence 和 Text8Corpus, PathLineSentences等。
sentences = word2vec.LineSentence("./data/preProcess/wordEmbdiing.txt")
# 训练模型,词向量的长度设置为200, 迭代次数为8,采用skip-gram模型,模型保存为bin格式
model = gensim.models.Word2Vec(sentences, size=200, sg=1, iter=5)
model.wv.save_word2vec_format("./word2Vec" + ".bin", binary=True)
# 加载bin格式的模型
# wordVec = gensim.models.KeyedVectors.load_word2vec_format("word2Vec.bin", binary=True)
三. 数据处理
下面的代码是数据处理的一个类,包含有以下几个方法(介绍这几个方法的顺序是按照dataGen()函数的顺序进行介绍的,也是实际运行代码时的顺序):
-
def _readStopWord(self, stopWordPath): 读取停用词
-
def _readData(self, filePath): 从csv文件中读取数据集,返回list类型的review和label
-
def _getWordEmbedding(self, words): 按照我们的数据集中的单词取出预训练好的word2vec中的词向量。接收多个words,然后返回’PAD’+‘UNK’+words组成的列表vocab,以及对应的词向量。
-
def _genVocabulary(self, reviews, labels): 生成词向量和词汇-索引映射字典,可以用全数据集。接收_readData返回的review和label作为参数,因为是英文文本,所以不需要分词,接着去除停用词,去除低频词;然后使用_getWordEmbedding函数得到vocab和对应的词向量,并将词汇与索引进行映射得到word2idx,将标签与索引进行映射得到label2idx,并分别将word2idx和label2idx保存为json文件。
-
def _labelToIndex(self, labels, label2idx): 将标签转换成索引表示, 得到返回值labelIds
-
def _wordToIndex(self, reviews, word2idx): 将词转换成索引,得到返回值reviewIds
-
def _genTrainEvalData(self, x, y, word2idx, rate): 生成训练集和验证集。参数介绍:x就是reviewIds,y就是labelIds,rate是分割训练集和验证集的比例。
# data_create.py
# -*- coding: utf-8 -*-
import json
from collections import Counter
import gensim
import pandas as pd
import numpy as np
# 数据预处理的类,生成训练集和测试集
class Dataset(object):
def __init__(self, config):
self.config = config
self._dataSource = config.dataSource
self._stopWordSource = config.stopWordSource
self._sequenceLength = config.sequenceLength # 每条输入的序列处理为定长
self._embeddingSize = config.model.embeddingSize
self._batchSize = config.batchSize
self._rate = config.rate
self._stopWordDict = {
}
self.trainReviews = []
self.trainLabels = []
self.evalReviews = []
self.evalLabels = []
self.wordEmbedding = None
self.labelList = []
def _readData(self, filePath):
"""
从csv文件中读取数据集
"""
df = pd.read_csv(filePath)
if self.config.numClasses == 1:
labels = df["sentiment"].tolist()
elif self.config.numClasses > 1:
labels = df["rate"].tolist()
review = df["review"].tolist()
reviews = [line.strip().split() for line in review]
return reviews, labels
def _labelToIndex(self, labels, label2idx):
"""
将标签转换成索引表示
"""
labelIds = [label2idx[label] for label in labels]
return labelIds
def _wordToIndex(self, reviews, word2idx):
"""
将词转换成索引
"""
reviewIds = [[word2idx.get(item, word2idx["UNK"]) for item in review] for review in reviews]
return reviewIds
def _genTrainEvalData(self, x, y, word2idx, rate):
"""
生成训练集和验证集
"""
reviews = []
for review in x:
if len(review) >= self._sequenceLength:
reviews.append(review[:self._sequenceLength])
else:
reviews.append(review + [word2idx["PAD"]] * (self._sequenceLength - len(review)))
trainIndex = int(len(x) * rate)
trainReviews = np.asarray(reviews[:trainIndex], dtype="int64")
trainLabels = np.array(y[:trainIndex], dtype="float32")
evalReviews = np.asarray(reviews[trainIndex:], dtype="int64")
evalLabels = np.array(y[trainIndex:], dtype="float32")
return trainReviews, trainLabels, evalReviews, evalLabels
def _genVocabulary(self, reviews, labels):
"""
生成词向量和词汇-索引映射字典,可以用全数据集
"""
allWords = [word for review in reviews for word in review]
# 去掉停用词
subWords = [word for word in allWords if word not in self.stopWordDict]
wordCount = Counter(subWords) # 统计词频
sortWordCount = sorted(wordCount.items(), key=lambda x: x[1], reverse=True)
# 去除低频词
words = [item[0] for item in sortWordCount if item[1] >= 5]
vocab, wordEmbedding = self._getWordEmbedding(words)
self.wordEmbedding = wordEmbedding
word2idx = dict(zip(vocab, list(range(len(vocab)))))
uniqueLabel = list(set(labels))
label2idx = dict(zip(uniqueLabel, list(range(len(uniqueLabel)))))
self.labelList = list(range(len(uniqueLabel)))
# 将词汇-索引映射表保存为json数据,之后做inference时直接加载来处理数据
# with open("../data/wordJson/word2idx.json", "w", encoding="utf-8") as f:
with open("./data/wordJson/word2idx.json", "w") as f:
json.dump(word2idx, f)
# with open("../data/wordJson/label2idx.json", "w", encoding="utf-8") as f:
with open("./data/wordJson/label2idx.json", "w") as f:
json.dump(label2idx, f)
return word2idx, label2idx
def _getWordEmbedding(self, words):
"""
按照我们的数据集中的单词取出预训练好的word2vec中的词向量
"""
wordVec = gensim.models.KeyedVectors.load_word2vec_format("./word2Vec.bin", binary=True)
vocab = []
wordEmbedding = []
# 添加 "pad" 和 "UNK",
vocab.append("PAD")
vocab.append("UNK")
wordEmbedding.append(np.zeros(self._embeddingSize))
wordEmbedding.append(np.random.randn(self._embeddingSize))
for word in words:
try:
vector = wordVec.wv[word]
vocab.append(word)
wordEmbedding.append(vector)
except:
print(word + "不存在于词向量中")
return vocab, np.array(wordEmbedding)
def _readStopWord(self, stopWordPath):
"""
读取停用词
"""
with open(stopWordPath, "r") as f:
stopWords = f.read()
stopWordList = stopWords.splitlines()
# 将停用词用列表的形式生成,之后查找停用词时会比较快
self.stopWordDict = dict(zip(stopWordList, list(range(len(stopWordList)))))
def dataGen(self):
"""
初始化训练集和验证集
"""
# 初始化停用词
self._readStopWord(self._stopWordSource)
# 初始化数据集
reviews, labels = self._readData(self._dataSource)
# 初始化词汇-索引映射表和词向量矩阵
word2idx, label2idx = self._genVocabulary(reviews, labels)
# 将标签和句子数值化
labelIds = self._labelToIndex(labels, label2idx)
reviewIds = self._wordToIndex(reviews, word2idx)
# 初始化训练集和测试集
trainReviews, trainLabels, evalReviews, evalLabels = self._genTrainEvalData(reviewIds, labelIds, word2idx,
self._rate)
self.trainReviews = trainReviews
self.trainLabels = trainLabels
self.evalReviews = evalReviews
self.evalLabels = evalLabels
2. 文本卷积神经网络
一. text_cnn
下面是一个文本卷积神经网络的类,创建实例时,需要将DataSet类中生成的WordEmbeding作为参数传递进来。
该文本卷积神经网络首先需要构建输入文本对应的词向量矩阵;然后再进行卷积操作,这里是采用了3个不同shape的卷积核:3200,4200,5*200的卷积核各有128个,这些超参数的设定会在另外一个单独的配置文件中;经过卷积之后,需要进行最大池化,池化之后进行展开,然后进行全连接层的输出即可。
# text_cnn.py
# -*- coding: utf-8 -*-
import tensorflow as tf
# 构建模型
class TextCNN(object):
"""
Text CNN 用于文本分类
"""
def __init__(self, config, wordEmbedding):
# 定义模型的输入
self.inputX = tf.placeholder(tf.int32, [None, config.sequenceLength], name="inputX")
self.inputY = tf.placeholder(tf.int32, [None], name="inputY")
self.dropoutKeepProb = tf.placeholder(tf.float32, name="dropoutKeepProb")
# 定义l2损失
l2Loss = tf.constant(0.0)
# 词嵌入层
with tf.name_scope("embedding"):
# 利用预训练的词向量初始化词嵌入矩阵
self.W = tf.Variable(tf.cast(wordEmbedding, dtype=tf.float32, name="word2vec"), name="W")
# 利用词嵌入矩阵将输入的数据中的词转换成词向量,维度[batch_size, sequence_length, embedding_size]
# tf.nn.embedding_lookup函数的用法主要是选取一个张量里面索引对应的元素。
# tf.nn.embedding_lookup(params, ids):params可以是张量也可以是数组等,id就是对应的索引
self.embeddedWords = tf.nn.embedding_lookup(self.W, self.inputX)
# 卷积的输入是思维[batch_size, width, height, channel],因此需要增加维度,用tf.expand_dims来增大维度
self.embeddedWordsExpanded = tf.expand_dims(self.embeddedWords, -1)
# 创建卷积和池化层
pooledOutputs = []
# 有三种size的filter,3, 4, 5,textCNN是个多通道单层卷积的模型,可以看作三个单层的卷积模型的融合
for i, filterSize in enumerate(config.model.filterSizes):
with tf.name_scope("conv-maxpool-%s" % filterSize):
# 卷积层,卷积核尺寸为filterSize * embeddingSize,卷积核的个数为numFilters
# 初始化权重矩阵和偏置
filterShape = [filterSize, config.model.embeddingSize, 1, config.model.numFilters]
W = tf.Variable(tf.truncated_normal(filterShape, stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[config.model.numFilters]), name="b")
conv = tf.nn.conv2d(
self.embeddedWordsExpanded,
W,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")
# relu函数的非线性映射
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
# 池化层,最大池化,池化是对卷积后的序列取一个最大值
pooled = tf.nn.max_pool(
h,
ksize=[1, config.sequenceLength - filterSize + 1, 1, 1],
# ksize shape: [batch, height, width, channels]
strides=[1, 1, 1, 1],
padding='VALID',
name="pool")
pooledOutputs.append(pooled) # 将三种size的filter的输出一起加入到列表中
# 得到CNN网络的输出长度
numFiltersTotal = config.model.numFilters * len(config.model.filterSizes)
# 池化后的维度不变,按照最后的维度channel来concat
self.hPool = tf.concat(pooledOutputs, 3)
# 摊平成二维的数据输入到全连接层
self.hPoolFlat = tf.reshape(self.hPool, [-1, numFiltersTotal])
# dropout
with tf.name_scope("dropout"):
self.hDrop = tf.nn.dropout(self.hPoolFlat, self.dropoutKeepProb)
# 全连接层的输出
with tf.name_scope("output"):
outputW = tf.get_variable(
"outputW",
shape=[numFiltersTotal, config.numClasses],
initializer=tf.contrib.layers.xavier_initializer())
outputB = tf.Variable(tf.constant(0.1, shape=[config.numClasses]), name="outputB")
l2Loss += tf.nn.l2_loss(outputW)
l2Loss += tf.nn.l2_loss(outputB)
self.logits = tf.nn.xw_plus_b(self.hDrop, outputW, outputB, name="logits")
if config.numClasses == 1:
self.predictions = tf.cast(tf.greater_equal(self.logits, 0.0), tf.int32, name="predictions")
elif config.numClasses > 1:
self.predictions = tf.argmax(self.logits, axis=-1, name="predictions")
print(self.predictions)
# 计算二元交叉熵损失
with tf.name_scope("loss"):
if config.numClasses == 1:
losses = tf.nn.sigmoid_cross_entropy_with_logits(logits=self.logits,
labels=tf.cast(tf.reshape(self.inputY, [-1, 1]),
dtype=tf.float32))
elif config.numClasses > 1:
losses = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=self.logits, labels=self.inputY)
self.loss = tf.reduce_mean(losses) + config.model.l2RegLambda * l2Loss
二. 配置文件
配置文件中包含有训练阶段参数、模型参数等。
# Config.py
# -*- coding: utf-8 -*-
# 配置参数
class TrainingConfig(object):
epoches = 5
evaluateEvery = 100
checkpointEvery = 100
learningRate = 0.001
class ModelConfig(object):
embeddingSize = 200
numFilters = 128
filterSizes = [2, 3, 4, 5]
dropoutKeepProb = 0.5
l2RegLambda = 0.0
class Config(object):
sequenceLength = 200 # 取了所有序列长度的均值
batchSize = 128
dataSource = "./data/preProcess/labeledTrain.csv"
stopWordSource = "./data/english"
numClasses = 1 # 二分类设置为1,多分类设置为类别的数目
rate = 0.8 # 训练集的比例
training = TrainingConfig()
model = ModelConfig()
3. 模型训练
# main.py
# -*- coding: utf-8 -*-
import os
import datetime
import numpy as np
import tensorflow as tf
from Config import Config
from data_create import Dataset
from text_cnn import TextCNN
config = Config()
data = Dataset(config)
data.dataGen()
print("train data shape: {}".format(data.trainReviews.shape))
print("train label shape: {}".format(data.trainLabels.shape))
print("eval data shape: {}".format(data.evalReviews.shape))
# 输出batch数据集
def nextBatch(x, y, batchSize):
"""
生成batch数据集,用生成器的方式输出
"""
perm = np.arange(len(x))
np.random.shuffle(perm)
x = x[perm]
y = y[perm]
numBatches = len(x) // batchSize
for i in range(numBatches):
start = i * batchSize
end = start + batchSize
batchX = np.array(x[start: end], dtype="int64")
batchY = np.array(y[start: end], dtype="float32")
yield batchX, batchY
"""
定义各类性能指标
"""
# def mean(item: list) -> float:
def mean(item):
"""
计算列表中元素的平均值
:param item: 列表对象
:return:
"""
res = sum(item)*1.0 / len(item) if len(item) > 0 else 0
return res
def accuracy(pred_y, true_y):
"""
计算二类和多类的准确率
:param pred_y: 预测结果
:param true_y: 真实结果
:return:
"""
# if isinstance(pred_y[0], list):
if isinstance(pred_y[0], np.ndarray):
pred_y = [item[0] for item in pred_y]
# print 'in acc, pred_y:', pred_y
# print 'in acc, pred_y:', type(pred_y), type(pred_y[0])
corr = 0
for i in range(len(pred_y)):
# print 'in acc, for, pred_y:', pred_y[i], 'true_y:', true_y[i]
if pred_y[i] == true_y[i]:
# print '========='
corr += 1
# print 'in acc, corr:', corr, 'len(pred_y):', len(pred_y)
acc = corr*1.0 / len(pred_y) if len(pred_y) > 0 else 0
return acc
def binary_precision(pred_y, true_y, positive=1):
"""
二类的精确率计算
:param pred_y: 预测结果
:param true_y: 真实结果
:param positive: 正例的索引表示
:return:
"""
corr = 0
pred_corr = 0
for i in range(len(pred_y)):
if pred_y[i] == positive:
pred_corr += 1
if pred_y[i] == true_y[i]:
corr += 1
prec = corr*1.0 / pred_corr if pred_corr > 0 else 0
return prec
def binary_recall(pred_y, true_y, positive=1):
"""
二类的召回率
:param pred_y: 预测结果
:param true_y: 真实结果
:param positive: 正例的索引表示
:return:
"""
corr = 0
true_corr = 0
for i in range(len(pred_y)):
if true_y[i] == positive:
true_corr += 1
if pred_y[i] == true_y[i]:
corr += 1
rec = corr*1.0 / true_corr if true_corr > 0 else 0
return rec
def binary_f_beta(pred_y, true_y, beta=1.0, positive=1):
"""
二类的f beta值
:param pred_y: 预测结果
:param true_y: 真实结果
:param beta: beta值
:param positive: 正例的索引表示
:return:
"""
precision = binary_precision(pred_y, true_y, positive)
recall = binary_recall(pred_y, true_y, positive)
try:
f_b = (1 + beta * beta) * precision * recall*1.0 / (beta * beta * precision + recall)
except:
f_b = 0
return f_b
def multi_precision(pred_y, true_y, labels):
"""
多类的精确率
:param pred_y: 预测结果
:param true_y: 真实结果
:param labels: 标签列表
:return:
"""
if isinstance(pred_y[0], np.ndarray):
pred_y = [item[0] for item in pred_y]
precisions = [binary_precision(pred_y, true_y, label) for label in labels]
prec = mean(precisions)
return prec
def multi_recall(pred_y, true_y, labels):
"""
多类的召回率
:param pred_y: 预测结果
:param true_y: 真实结果
:param labels: 标签列表
:return:
"""
if isinstance(pred_y[0], np.ndarray):
pred_y = [item[0] for item in pred_y]
recalls = [binary_recall(pred_y, true_y, label) for label in labels]
rec = mean(recalls)
return rec
def multi_f_beta(pred_y, true_y, labels, beta=1.0):
"""
多类的f beta值
:param pred_y: 预测结果
:param true_y: 真实结果
:param labels: 标签列表
:param beta: beta值
:return:
"""
if isinstance(pred_y[0], np.ndarray):
pred_y = [item[0] for item in pred_y]
f_betas = [binary_f_beta(pred_y, true_y, beta, label) for label in labels]
f_beta = mean(f_betas)
return f_beta
def get_binary_metrics(pred_y, true_y, f_beta=1.0):
"""
得到二分类的性能指标
:param pred_y:
:param true_y:
:param f_beta:
:return:
"""
acc = accuracy(pred_y, true_y)
recall = binary_recall(pred_y, true_y)
precision = binary_precision(pred_y, true_y)
f_beta = binary_f_beta(pred_y, true_y, f_beta)
return acc, recall, precision, f_beta
def get_multi_metrics(pred_y, true_y, labels, f_beta=1.0):
"""
得到多分类的性能指标
:param pred_y:
:param true_y:
:param labels:
:param f_beta:
:return:
"""
acc = accuracy(pred_y, true_y)
recall = multi_recall(pred_y, true_y, labels)
precision = multi_precision(pred_y, true_y, labels)
f_beta = multi_f_beta(pred_y, true_y, labels, f_beta)
return acc, recall, precision, f_beta
# 训练模型
# 训练模型
# 生成训练集和验证集
trainReviews = data.trainReviews
trainLabels = data.trainLabels
evalReviews = data.evalReviews
evalLabels = data.evalLabels
wordEmbedding = data.wordEmbedding
labelList = data.labelList
# print 'trainreview:', trainReviews[0], len(trainReviews[0])
# trainreview 是一个二维矩阵,二维矩阵的每一项是一个长度为200的list,该List中是每个词对应的idx。
# 定义计算图
with tf.Graph().as_default():
session_conf = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)
session_conf.gpu_options.allow_growth = True
session_conf.gpu_options.per_process_gpu_memory_fraction = 0.9 # 配置gpu占用率
sess = tf.Session(config=session_conf)
# 定义会话
with sess.as_default():
cnn = TextCNN(config, wordEmbedding)
globalStep = tf.Variable(0, name="globalStep", trainable=False)
# 定义优化函数,传入学习速率参数
optimizer = tf.train.AdamOptimizer(config.training.learningRate)
# 计算梯度,得到梯度和变量
gradsAndVars = optimizer.compute_gradients(cnn.loss)
# 将梯度应用到变量下,生成训练器
trainOp = optimizer.apply_gradients(gradsAndVars, global_step=globalStep)
# 用summary绘制tensorBoard
gradSummaries = []
for g, v in gradsAndVars:
if g is not None:
tf.summary.histogram("{}/grad/hist".format(v.name), g)
tf.summary.scalar("{}/grad/sparsity".format(v.name), tf.nn.zero_fraction(g))
outDir = os.path.abspath(os.path.join(os.path.curdir, "summarys"))
print("Writing to {}\n".format(outDir))
lossSummary = tf.summary.scalar("loss", cnn.loss)
summaryOp = tf.summary.merge_all()
trainSummaryDir = os.path.join(outDir, "train")
trainSummaryWriter = tf.summary.FileWriter(trainSummaryDir, sess.graph)
evalSummaryDir = os.path.join(outDir, "eval")
evalSummaryWriter = tf.summary.FileWriter(evalSummaryDir, sess.graph)
# 初始化所有变量
saver = tf.train.Saver(tf.global_variables(), max_to_keep=5)
# 保存模型的一种方式,保存为pb文件
savedModelPath = "./model/textCNN/savedModel"
if os.path.exists(savedModelPath):
os.rmdir(savedModelPath)
builder = tf.saved_model.builder.SavedModelBuilder(savedModelPath)
sess.run(tf.global_variables_initializer())
def trainStep(batchX, batchY):
"""
训练函数
"""
feed_dict = {
cnn.inputX: batchX,
cnn.inputY: batchY,
cnn.dropoutKeepProb: config.model.dropoutKeepProb
}
_, summary, step, loss, predictions = sess.run(
[trainOp, summaryOp, globalStep, cnn.loss, cnn.predictions],
feed_dict)
# print 'predictions:', predictions
# print 'prediction[0]:', predictions[0], type(predictions[0])
# print 'batchY:', type(batchY), type(batchY[0])
# print 'batchY:', batchY
timeStr = datetime.datetime.now().isoformat()
if config.numClasses == 1:
acc, recall, prec, f_beta = get_binary_metrics(pred_y=predictions, true_y=batchY)
elif config.numClasses > 1:
acc, recall, prec, f_beta = get_multi_metrics(pred_y=predictions, true_y=batchY,
labels=labelList)
trainSummaryWriter.add_summary(summary, step)
return loss, acc, prec, recall, f_beta
def devStep(batchX, batchY):
"""
验证函数
"""
feed_dict = {
cnn.inputX: batchX,
cnn.inputY: batchY,
cnn.dropoutKeepProb: 1.0
}
summary, step, loss, predictions = sess.run(
[summaryOp, globalStep, cnn.loss, cnn.predictions],
feed_dict)
if config.numClasses == 1:
acc, precision, recall, f_beta = get_binary_metrics(pred_y=predictions, true_y=batchY)
elif config.numClasses > 1:
acc, precision, recall, f_beta = get_multi_metrics(pred_y=predictions, true_y=batchY, labels=labelList)
evalSummaryWriter.add_summary(summary, step)
return loss, acc, precision, recall, f_beta
for i in range(config.training.epoches):
# 训练模型
print("start training model")
for batchTrain in nextBatch(trainReviews, trainLabels, config.batchSize):
loss, acc, prec, recall, f_beta = trainStep(batchTrain[0], batchTrain[1])
currentStep = tf.train.global_step(sess, globalStep)
print("train: step: {}, loss: {}, acc: {}, recall: {}, precision: {}, f_beta: {}".format(
currentStep, loss, acc, recall, prec, f_beta))
if currentStep % config.training.evaluateEvery == 0:
print("\nEvaluation:")
losses = []
accs = []
f_betas = []
precisions = []
recalls = []
for batchEval in nextBatch(evalReviews, evalLabels, config.batchSize):
loss, acc, precision, recall, f_beta = devStep(batchEval[0], batchEval[1])
losses.append(loss)
accs.append(acc)
f_betas.append(f_beta)
precisions.append(precision)
recalls.append(recall)
time_str = datetime.datetime.now().isoformat()
print("{}, step: {}, loss: {}, acc: {},precision: {}, recall: {}, f_beta: {}".format(time_str,currentStep, mean(losses), mean(accs), mean(precisions),mean(recalls), mean(f_betas)))
if currentStep % config.training.checkpointEvery == 0:
# 保存模型的另一种方法,保存checkpoint文件
path = saver.save(sess, "./model/textCNN/model/my-model", global_step=currentStep)
print("Saved model checkpoint to {}\n".format(path))
inputs = {
"inputX": tf.saved_model.utils.build_tensor_info(cnn.inputX),
"keepProb": tf.saved_model.utils.build_tensor_info(cnn.dropoutKeepProb)}
outputs = {
"predictions": tf.saved_model.utils.build_tensor_info(cnn.predictions)}
prediction_signature = tf.saved_model.signature_def_utils.build_signature_def(inputs=inputs, outputs=outputs,
method_name=tf.saved_model.signature_constants.PREDICT_METHOD_NAME)
legacy_init_op = tf.group(tf.tables_initializer(), name="legacy_init_op")
builder.add_meta_graph_and_variables(sess, [tf.saved_model.tag_constants.SERVING],
signature_def_map={
"predict": prediction_signature},
legacy_init_op=legacy_init_op)
builder.save()
结果:
/usr/bin/python /home/maqian/PycharmProjects/word2vec-use/nlp-p/main.py
–不存在于词向量中
cliché不存在于词向量中
clichés不存在于词向量中
…
débutante不存在于词向量中
gérald不存在于词向量中
train data shape: (20000, 200)
train label shape: (20000,)
eval data shape: (5000, 200)
…
start training model
train: step: 1, loss: 1.84601175785, acc: 0.4921875, recall: 0.403225806452, precision: 0.471698113208, f_beta: 0.434782608696
train: step: 2, loss: 2.84315872192, acc: 0.4921875, recall: 0.861538461538, precision: 0.5, f_beta: 0.632768361582
train: step: 3, loss: 1.50959098339, acc: 0.5703125, recall: 0.515151515152, precision: 0.59649122807, f_beta: 0.552845528455
train: step: 4, loss: 1.75978684425, acc: 0.546875, recall: 0.3125, precision: 0.588235294118, f_beta: 0.408163265306
train: step: 5, loss: 2.03314805031, acc: 0.4921875, recall: 0.115384615385, precision: 0.24, f_beta: 0.155844155844
train: step: 6, loss: 1.67574131489, acc: 0.4921875, recall: 0.480519480519, precision: 0.596774193548, f_beta: 0.532374100719
…
4. 总结