YOLOv2模型自记
目录
改进之处
训练框架部分
损失函数
YOLOv2的网络模型光看原理不难的,但看代码就非常的痛苦,一是没有合适版本的,而是不同于以前看的Fast rcnn系列的网络架构,很清晰的全都有,YOLO一部分是放在了darknet的框架里面的,有一部分是独有的改进,这就很费劲,我并没有完全消化这个网络,这里先存个档,把已经看懂的部分整理出来。
改进之处
1.使用Batch normalization。YOLOv2网络通过在每一个卷积层后添加batch normalization,极大的改善了收敛速度同时减少了对其它regularization方法的依赖(舍弃了dropout(一种常用的过拟合处理方法)优化后依然没有过拟合),使得mAP获得了2%的提升。
2.高分辨率。YOLO(v2)先以分辨率224*224训练分类网络,然后需要增加分辨率到448*448,这样做不仅切换为检测算法也改变了分辨率。所以作者想能不能在预训练的时候就把分辨率提高了,训练的时候只是由分类算法切换为检测算法。这个过程让网络有足够的时间调整filter去适应高分辨率的输入。然后fine tune为检测网络。mAP获得了4%的提升。
3.引入anchor Box。YOLOv2借鉴了Faster R-CNN中的anchor思想: 简单理解为卷积特征图上进行滑窗采样,每个中心预测9种不同大小和比例的建议框。由于都是卷积不需要reshape,很好的保留的空间信息,最终特征图的每个特征点和原图的每个cell一一对应。而且用预测相对偏移(offset)取代直接预测坐标简化了问题,方便网络学习。
4.提出了一种联合训练的机制:使用识别数据集训练模型识别相关部分,使用分类数据集训练模型分类相关部分。
5.细粒度特征。YOLOv2使用了一种不同的方法,简单添加一个 passthrough layer,把浅层特征图(分辨率为26 * 26)连接到深层特征图。
6.多尺度训练。每经过10批训练(10 batches)就会随机选择新的图片尺寸。
训练框架部分
首先,在找到的YOLOv2的版本中,并没有非常清晰的训练过程,唯一清晰的就是:根据官方记载,训练过程分三个阶段:
第一个阶段,输入为224*224,在ImageNet数据集上finetune分类模型,共训练160epochs。
作者使用Darknet-19在标准1000类的ImageNet上训练了160次,用随机梯度下降法,starting learning rate 为0.1,polynomial rate decay 为4,weight decay为0.0005 ,momentum 为0.9。训练的时候仍然使用了很多常见的数据扩充方法(data augmentation)
第二个阶段,将网络输入调整为448*448,继续在ImageNet数据集上finetune分类模型,训练10个epochs,(书中暗表:此时分类模型的top-1准确度为76.5%,而top-5准确度为93.3%)。
第三个阶段,就是修改上面的分类网络为检测网络,并在检测数据集(COCO)上继续finetune模型,网络修改包括:移除最后一个卷积层、global avgpooling层以及softmax层,并且新增了三个3*3*1024卷积层,同时,增加一个passthrough层,最后,使用1*1卷积层输出预测结果,输出的channnels数为:num_anchors*(5+num_classes),当然,这个跟训练采用的训练集有关,训练集有几个分类,num_classes就设置成多少。
举个例子:
由于anchors数为5(这个是针对训练集的框值分布通过kmeans++聚类出来的),对于VOC数据集输出的channels数就是125,而对于COCO数据集则为425。这里以VOC数据集为例,最终的预测矩阵为T,([batch_size, 13, 13, 125]),可以先将其reshape为[batch_size, 13, 13, 5, 25],其中,T[:, :, :, :, 0:4]为边界框的位置和大小(tx, ty, tw, th),T[:, :, :, :, 4]为边界框的置信度, 而T[:, :, :, :, 5:]为类别预测值。一共26个(从零开始计),分别是一个置信度,四个位置大小,和21个分类信息。
从代码角度讲,网络训练是分着好几个阶段的,先是训练分类网络,然后,用训练好的分类网络的权重,作为初始值,训练检测网络,从代码角度上看,有几点值得注意的地方:
1.每层卷积之后,都跟着一个BN层,将结果做归一化:
if batch_normalize: #卷积层的输出,先经过batch_normalization
out = tf.layers.batch_normalization(out,axis=-1,momentum=0.9,training=False,name=name+'_bn')
if activation: #经过batch_normalization处理之后的网络输出输入到激活函数
out = activation(out)然后,再输入到下一层的卷积当中。
2.在检测网络时候,会将前面的层数结果,串联到后面,并组成新的一层网络,这样来使粗细粒度重合。如下,在第5层卷积的时候,将net信息存储,然后,接到第七层卷积后面。利用1*1卷积核拼成一共新的网络层。
net = conv2d(net, 512, 3, 1, name='conv5_5') #卷积层,卷积核数量为512,大小为1*1,padding=1,默认步长为1
# 存储这一层特征图,以便后面passthrough层
shortcut = net #大小为14*14
net = maxpool(net, 2, 2, name='pool5') #maxpooling,变成7*7
net = conv2d(net, 1024, 3, 1, name='conv6_1') #卷积层,卷积核数量为1024,大小为3*3,padding=1,默认步长为1
net = conv2d(net, 512, 1, 0, name='conv6_2') #卷积层,卷积核数量为512,大小为1*1,padding=0,默认步长为1
net = conv2d(net, 1024, 3, 1, name='conv6_3') #卷积层,卷积核数量为1024,大小为3*3,padding=1,默认步长为1
net = conv2d(net, 512, 1, 0, name='conv6_4') #卷积层,卷积核数量为512,大小为1*1,padding=0,默认步长为1
net = conv2d(net, 1024, 3, 1, name='conv6_5') #卷积层,卷积核数量为1024,大小为3*3,padding=1,默认步长为1
#具体这个可以参考: https://blog.csdn.net/hrsstudy/article/details/70767950 Training for classification 和 Training for detection
# 训练检测网络时去掉了分类网络的网络最后一个卷积层,在后面增加了三个卷积核尺寸为3 * 3,卷积核数量为1024的卷积层,并在这三个卷积层的最后一层后面跟一个卷积核尺寸为1 * 1
# 的卷积层,卷积核数量是(B * (5 + C))。
# 对于VOC数据集,卷积层输入图像尺寸为416 * 416
# 时最终输出是13 * 13
# 个栅格,每个栅格预测5种boxes大小,每个box包含5个坐标值和20个条件类别概率,所以输出维度是13 * 13 * 5 * (5 + 20)= 13 * 13 * 125。
#
# 检测网络加入了passthrough
# layer,从最后一个输出为26 * 26 * 512
# 的卷积层连接到新加入的三个卷积核尺寸为3 * 3
# 的卷积层的第二层,使模型有了细粒度特征。
#下面这部分主要是training for detection
net = conv2d(net, 1024, 3, 1, name='conv7_1') #卷积层,卷积核数量为1024,大小为3*3,padding=1,默认步长为1
net = conv2d(net, 1024, 3, 1, name='conv7_2') #卷积层,卷积核数量为1024,大小为3*3,padding=1,默认步长为1,大小为1024*7*7
#关于这部分细粒度的特征的解释,可以参考:https://blog.csdn.net/hai_xiao_tian/article/details/80472419
# shortcut增加了一个中间卷积层,先采用64个1*1卷积核进行卷积,然后再进行passthrough处理
# 这样26*26*512 -> 26*26*64 -> 13*13*256的特征图,可能是输入图片刚开始不是224,而是448,知道就好了,YOLOv2的输入图片大小为 416*416
shortcut = conv2d(shortcut, 64, 1, 0, name='conv_shortcut') #卷积层,卷积核数量为64,大小为1*1,padding=0,默认步长为1,变成26*26*64
shortcut = reorg(shortcut, 2) # passthrough, 进行Fine-Grained Features,得到13*13*256
#连接之后,变成13*13*(1024+256)
net = tf.concat([shortcut, net], axis=-1) #channel整合到一起,concatenated with the original features,passthrough层与ResNet网络的shortcut类似,以前面更高分辨率的特征图为输入,然后将其连接到后面的低分辨率特征图上,
net = conv2d(net, 1024, 3, 1, name='conv8') #卷积层,卷积核数量为1024,大小为3*3,padding=1, 在连接的特征图的基础上做卷积进行预测。变成13*13*10243. yolov2最后的输出的是卷积层,不是全连接层,这样就可以保证处理多尺度图片的输入,另外,在训练过程中,每隔几个批次,就更改一下输入图片的尺度,也是为了让网络适用于多尺度的处理。
# 激活函数
def leaky_relu(x): #leaky relu激活函数,leaky_relu激活函数一般用在比较深层次神经网络中
return tf.maximum(0.1*x,x)
#return tf.nn.leaky_relu(x,alpha=0.1,name='leaky_relu') # 或者tf.maximum(0.1*x,x)
# Conv+BN:yolo2中每个卷积层后面都有一个BN层, batch normalization正是yolov2比yolov1多的一个东西,可以提升mAP大约2%
def conv2d(x,filters_num,filters_size,pad_size=0,stride=1,batch_normalize=True,activation=leaky_relu,use_bias=False,name='conv2d'):
# padding,注意: 不用padding="SAME",否则可能会导致坐标计算错误,用自己定义的填充方式
if pad_size > 0:
x = tf.pad(x,[[0,0],[pad_size,pad_size],[pad_size,pad_size],[0,0]]) #这里使用tensorflow中的pad进行填充,主要填充第2和第3维度,填充的目的是使得经过卷积运算之后,特征图的大小不会发生变化
out = tf.layers.conv2d(x,filters=filters_num,kernel_size=filters_size,strides=stride,padding='VALID',activation=None,use_bias=use_bias,name=name)
# BN应该在卷积层conv和激活函数activation之间,(后面有BN层的conv就不用偏置bias,并激活函数activation在后)
if batch_normalize: #卷积层的输出,先经过batch_normalization
out = tf.layers.batch_normalization(out,axis=-1,momentum=0.9,training=False,name=name+'_bn')
if activation: #经过batch_normalization处理之后的网络输出输入到激活函数
out = activation(out)
return out #返回网络的输出
# max_pool
def maxpool(x,size=2,stride=2,name='maxpool'): #maxpool,最大池化层
return tf.layers.max_pooling2d(x,pool_size=size,strides=stride)
# reorg layer(带passthrough的重组层),主要是利用到Fine-Grained Feature(细粒度特征用于检测微小物体)
def reorg(x,stride):
return tf.space_to_depth(x,block_size=stride) #返回一个与input具有相同的类型的Tensor
# return tf.extract_image_patches(x,ksizes=[1,stride,stride,1],strides=[1,stride,stride,1],rates=[1,1,1,1],padding='VALID')
# Darknet19
# 默认是coco数据集,最后一层维度是anchor_num*(class_num+5)=5*(80+5)=425,注意与voc数据集的区别
def darknet(images,n_last_channels=425): #Darknet19网络,假设这里图片的输入大小为224*224,下面的所有注释都是基于这个宽度和高度的假设,主要是为了和论文对应
net = conv2d(images, filters_num=32, filters_size=3, pad_size=1, name='conv1') #卷积层,卷积核数量32,大小为3*3,padding=1, 默认步长为1
net = maxpool(net, size=2, stride=2, name='pool1') #maxpooling, 减少特征图的维度一半,为112*112,因为siez=2*2,步长为2
net = conv2d(net, 64, 3, 1, name='conv2') #卷积层,卷积核数量为64,大小为3*3,padding=1,默认步长为1
net = maxpool(net, 2, 2, name='pool2') #maxpooling,变成56*56
net = conv2d(net, 128, 3, 1, name='conv3_1') #卷积层,卷积核数量为128,大小为3*3,padding=1,默认步长为1
net = conv2d(net, 64, 1, 0, name='conv3_2') #卷积层,卷积核数量为64,大小为1*1,padding=0,默认步长为1
net = conv2d(net, 128, 3, 1, name='conv3_3') #卷积层,卷积核数量为128,大小为3*3,padding为1,默认步长为1
net = maxpool(net, 2, 2, name='pool3') #maxpooling,变成28*28
net = conv2d(net, 256, 3, 1, name='conv4_1') #卷积层,卷积核数量为256,大小为3*3,padding=1,默认步长为1
net = conv2d(net, 128, 1, 0, name='conv4_2') #卷积层,卷积核数量为128,大小为1*1,padding=0,默认步长为1
net = conv2d(net, 256, 3, 1, name='conv4_3') #卷积层,卷积核数量为256,大小为3*3,padding=1,默认步长为1
net = maxpool(net, 2, 2, name='pool4') #maxpooling,变成14*14
net = conv2d(net, 512, 3, 1, name='conv5_1') #卷积层,卷积核数量为512,大小为3*3,padding=1,默认步长为1
net = conv2d(net, 256, 1, 0,name='conv5_2') #卷积层,卷积核数量为256,大小为1*1,padding=0,默认步长为1
net = conv2d(net,512, 3, 1, name='conv5_3') #卷积层,卷积核数量为512,大小为3*3,padding=1,默认步长为1
net = conv2d(net, 256, 1, 0, name='conv5_4') #卷积层,卷积核数量为256,大小为1*1,padding=0,默认步长为1
net = conv2d(net, 512, 3, 1, name='conv5_5') #卷积层,卷积核数量为512,大小为1*1,padding=1,默认步长为1
# 存储这一层特征图,以便后面passthrough层
shortcut = net #大小为14*14
net = maxpool(net, 2, 2, name='pool5') #maxpooling,变成7*7
net = conv2d(net, 1024, 3, 1, name='conv6_1') #卷积层,卷积核数量为1024,大小为3*3,padding=1,默认步长为1
net = conv2d(net, 512, 1, 0, name='conv6_2') #卷积层,卷积核数量为512,大小为1*1,padding=0,默认步长为1
net = conv2d(net, 1024, 3, 1, name='conv6_3') #卷积层,卷积核数量为1024,大小为3*3,padding=1,默认步长为1
net = conv2d(net, 512, 1, 0, name='conv6_4') #卷积层,卷积核数量为512,大小为1*1,padding=0,默认步长为1
net = conv2d(net, 1024, 3, 1, name='conv6_5') #卷积层,卷积核数量为1024,大小为3*3,padding=1,默认步长为1
#具体这个可以参考: https://blog.csdn.net/hrsstudy/article/details/70767950 Training for classification 和 Training for detection
# 训练检测网络时去掉了分类网络的网络最后一个卷积层,在后面增加了三个卷积核尺寸为3 * 3,卷积核数量为1024的卷积层,并在这三个卷积层的最后一层后面跟一个卷积核尺寸为1 * 1
# 的卷积层,卷积核数量是(B * (5 + C))。
# 对于VOC数据集,卷积层输入图像尺寸为416 * 416
# 时最终输出是13 * 13
# 个栅格,每个栅格预测5种boxes大小,每个box包含5个坐标值和20个条件类别概率,所以输出维度是13 * 13 * 5 * (5 + 20)= 13 * 13 * 125。
#
# 检测网络加入了passthrough
# layer,从最后一个输出为26 * 26 * 512
# 的卷积层连接到新加入的三个卷积核尺寸为3 * 3
# 的卷积层的第二层,使模型有了细粒度特征。
#下面这部分主要是training for detection
net = conv2d(net, 1024, 3, 1, name='conv7_1') #卷积层,卷积核数量为1024,大小为3*3,padding=1,默认步长为1
net = conv2d(net, 1024, 3, 1, name='conv7_2') #卷积层,卷积核数量为1024,大小为3*3,padding=1,默认步长为1,大小为1024*7*7
#关于这部分细粒度的特征的解释,可以参考:https://blog.csdn.net/hai_xiao_tian/article/details/80472419
# shortcut增加了一个中间卷积层,先采用64个1*1卷积核进行卷积,然后再进行passthrough处理
# 这样26*26*512 -> 26*26*64 -> 13*13*256的特征图,可能是输入图片刚开始不是224,而是448,知道就好了,YOLOv2的输入图片大小为 416*416
shortcut = conv2d(shortcut, 64, 1, 0, name='conv_shortcut') #卷积层,卷积核数量为64,大小为1*1,padding=0,默认步长为1,变成26*26*64
shortcut = reorg(shortcut, 2) # passthrough, 进行Fine-Grained Features,得到13*13*256
#连接之后,变成13*13*(1024+256)
net = tf.concat([shortcut, net], axis=-1) #channel整合到一起,concatenated with the original features,passthrough层与ResNet网络的shortcut类似,以前面更高分辨率的特征图为输入,然后将其连接到后面的低分辨率特征图上,
net = conv2d(net, 1024, 3, 1, name='conv8') #卷积层,卷积核数量为1024,大小为3*3,padding=1, 在连接的特征图的基础上做卷积进行预测。变成13*13*1024
#detection layer: 最后用一个1*1卷积去调整channel,该层没有BN层和激活函数,变成: S*S*(B*(5+C)),在这里为:13*13*425
output = conv2d(net, filters_num=n_last_channels, filters_size=1, batch_normalize=False, activation=None, use_bias=True, name='conv_dec')
return output #返回网络的输出损失函数
接下来看损失函数,这个看了好长时间,才隐隐约约觉得可能理解了,但还是欠点火候,先记下来些:
首先,yolov2的损失函数的数学描述如下:
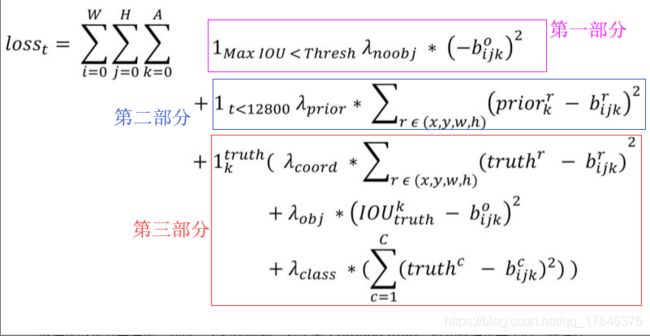
损失总体还是一个加和的形式,分成三部分,第一个部分,描述的是背景置信度的误差;第二部分,描述的是先验框与预测框的坐标误差,第三部分描述的是真值框和预测框的误差。下面一个一个说。
先说第一个部分,这个部分描述的是背景置信度的误差,那么首先,就要判断背景,规定当一个真值对应的所有预测框与其的IOU都小于0.6的时候,就判顶这个预测框为背景(因为和真值框的重合度太低,认为没包含目标物,那不就是背景了嘛),这里有个点,就是,真值是一个,对应产生的预测框并不唯一,在所有筛选出来的背景预测框中,选择一个IOU最大的(其他的背景预测框舍弃),将它的置信度bijk来作为求背景置信度误差的一个参数:
![]()
其中:1maxIOU < Thresh 代表如果最大的IOU都小于阈值(0.6)那么此值就置为1,否则就为0,后面的![]() 代表权重。再后面(-bijk)^2,代表置信度的差,应知,当检测结果越接近真值时,置信度就越高,规定置信度最高为1,同意,当越不接近真值时,置信度越低,规定置信度越低,最低为0,那么好了,这里的-bijk,其实的意思是(0-bijk),置信度最低的时候和当前背景的置信度的值的差,这样,根据损失函数的意义,损失函数越小越好,那么当他们的差越小的时候,意味着背景的置信度越来越接近背景应该的置信度(0),符合这个变化规律。
代表权重。再后面(-bijk)^2,代表置信度的差,应知,当检测结果越接近真值时,置信度就越高,规定置信度最高为1,同意,当越不接近真值时,置信度越低,规定置信度越低,最低为0,那么好了,这里的-bijk,其实的意思是(0-bijk),置信度最低的时候和当前背景的置信度的值的差,这样,根据损失函数的意义,损失函数越小越好,那么当他们的差越小的时候,意味着背景的置信度越来越接近背景应该的置信度(0),符合这个变化规律。
第二部分,描述的是预测框和所有先验框的损失。先注意这里,![]() 这个权重代表,在前12800批次的时候,这项才起作用,在这个批次之后,标记值记为0,那么这部分的损失就不起作用了, 为啥要这样做呢?那就要讲到这个先验框了,我们知道yolov2是通过kmeans++通过聚类来得到5个anchor值,那这五个anchor值表达的是什么意思?表达的是五种当前数据集里出现的框的概率最大的长宽比,就是说,这个训练集里面的框,大部分都符合这五种长宽比,在前期训练的时候,预测框预测出来的形状是随机的,我们通过先验框来对预测框的形状进行修正,让它尽可能的向先验框的五种比例靠近,这样提高检测框的准确性了就,而且,只需要在训练的前面部分批次进行就行了,其实也不需要一直进行,所以,才有了1280这个批次作为一个阈值。
这个权重代表,在前12800批次的时候,这项才起作用,在这个批次之后,标记值记为0,那么这部分的损失就不起作用了, 为啥要这样做呢?那就要讲到这个先验框了,我们知道yolov2是通过kmeans++通过聚类来得到5个anchor值,那这五个anchor值表达的是什么意思?表达的是五种当前数据集里出现的框的概率最大的长宽比,就是说,这个训练集里面的框,大部分都符合这五种长宽比,在前期训练的时候,预测框预测出来的形状是随机的,我们通过先验框来对预测框的形状进行修正,让它尽可能的向先验框的五种比例靠近,这样提高检测框的准确性了就,而且,只需要在训练的前面部分批次进行就行了,其实也不需要一直进行,所以,才有了1280这个批次作为一个阈值。
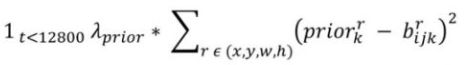
prior是先验框的w,h,bijk是预测框的w,h,x,y值是不参与的。这一步的目的,就是将预测框“塑形”。
第三部分,这个部分是最复杂的计算预测框和真值框的误差,这里面又包含了 三部分,分别是,坐标误差,置信度误差(准确的说是前景置信度误差),分类误差。需要点明的一个是在计算置信度误差的时候,首先,真值框先与其对应的5个先验框来求IOU,找出一个最大的IOU值,我称之为A,那么到置信度误差的时候,(A-前景区域的实际IOU)^2这个就作为了置信度的误差了,其他的,坐标误差和分类误差,很普遍,就不细讲了。