【NLP】文献翻译3——基于卷积神经网络和词嵌入的一种新型句子相似性模型
A novel sentence similarity model with word embedding based on convolutional neural network
- 摘要
- 1. 简介
- 2. 相关工作
-
- 2.1 基于CNN的句子相似性的计算方法
- 2.2 基于RNN的句子相似性的计算方法
- 2.3 基于DNN的句子相似性的计算方法
- 3. 提出的模型WSV-SCNN-SV
- 3.1 模型总体架构
-
- 3.2 句子预处理
- 3.3 基于 "二元组(binary-gram)词组向量 "的输入模型
- 3.4 我们的浅层卷积神经网络
- 3.5 相似性计算
- 4. 实验结果与分析
-
- 4.1 实验设置
- 4.2 训练
- 4.3 实验分析
- 5. 结论
文献信息:
标题:基于卷积神经网络和词嵌入的一种新型句子相似性模型
作者:Haipeng Yao1 Huiwen Liu1 Peiying Zhang1,2
时间:18 January 2018
机构:1北京邮电大学网络与交换技术国家重点实验室,北京,中国 2中国石油大学计算机与通信工程学院,青岛,中国
出版社:wiley online library
摘要
在本文中,我们提出了一种有效的英语句子相似度度量模型。在该模型中,我们首先利用词嵌入和卷积神经网络(CNN)生成句子向量,然后利用句子向量对的信息来计算句子相似度得分。考虑到词与词之间存在长程(long-range)语义依赖关系的情况,我们提出了一种新型的词嵌入转化方法来构建三维句子特征张量。此外,我们将k-max池化融入卷积神经网络中,以适应输入句子的可变长度。所提出的模型不需要WordNet和解析树(parse tree)等外部资源,同时,它消耗的时间非常少。同时,它的训练时间消耗非常少。最后,我们进行了大量的模拟,以评估我们的模型与其他最先进的(state-of-the-art)作品相比的性能。在SemEval 2014任务(SICK测试语料)上的实验结果表明,我们的模型在Pearson相关系数、Spearman相关系数和均方误差方面都能取得良好的性能。此外,在Microsoft research paraphrase identification(MSRP)的实验结果表明,我们的模型在F1和Accuracy方面表现良好。
关键词:卷积神经网络,句子相似性,词嵌入
1. 简介
句子相似度测量是自然语言处理(NLP)研究中的一个基本问题,在许多语言处理任务中,如查询排名、问题回答、释义(paraphrase)识别和释义生成等,都会用到它。对于机器来说,理解句子之间的相似性并不是一个简单的任务,因为既要考虑语义(semantic)信息又要考虑句法(syntactic)信息。在Mikolov等人的作品中,分布式词嵌入已经被明确编码了许多语言规律和模式,它已经被广泛利用来提取句子的语义特征。句法解析由于其复杂性,是一项具有挑战性的任务,因此,使机器从语料库中隐藏地学习语法规则是一个很好的想法。最近,随着人们对神经网络兴趣的增加,通过神经网络的模型可以实现这一想法。
2008年,Collobert和Wetson提出了一种基于卷积神经网络的架构,用于对句子进行建模,并将其用于命名实体标签、语义角色和语义相似词等多个学习任务中。在他们的研究中,单词被嵌入到多维空间中。受他们的工作启发,其他研究者在释义识别、句子分类和语义相似度测量中利用了词嵌入和卷积神经网络,循环神经网络是一种具有可变长度输入的时间序列神经网络,对于序列建模任务如句子建模是很好的选择。Socher等人将RNN应用于寻找和描述带有句子的图像的任务中。RNN的缺点是其梯度在长序列上消失。为了避免梯度消失问题,提出了长短期记忆网络(LSTM),它在学习长程依赖性方面效果较好。Tai等人和Mueller和Thyagarajan采用LSTM进行句子相似度测量。
然而,长短期记忆网络和深度卷积神经网络在利用它们进行语义相似性测量时,都有一个耗时的缺点。另外,深度卷积神经网络在测量句子相似度时需要进行修改。它们的结构普遍比较复杂。由于句子相似度的测量是NLP中的一个基本任务,而且更多的是作为辅助解决其他更大任务的一个子任务,这些结构复杂、训练时间长的模型会消耗分配给其他子任务的额外资源,减缓整个任务的进行。
在本文中,我们提出了一种采用词嵌入和卷积神经网络进行句子相似度测量的新型模型。本文的主要贡献如下:
- 为了减少训练时间,简化体系结构,我们提出了一种不同于传统长短期记忆网络和深度卷积神经网络的新型句子相似度模型。我们的模型主体是一个不需要全连接层的浅层卷积神经网络,同时针对句子相似度测量的任务对其结构进行了修改。
- 我们将长度可变的句子嵌入到一个多维空间中。我们将词嵌入的方法从词级扩展到句子级,目的是将词相似度计算方法放到句子相似度测量中去。此外,我们的模型可以处理任何长度的句子,而不需要进行剪裁(clipping)和填充(padding)操作。
- 我们使用不同的评价指标对我们的模型进行评价,有两类不同的任务,即语义相关度任务(SemEval 2014,Task1)和微软研究释义识别任务。得到的结果在这两个任务上都取得了良好的表现。
我们论文的其余部分组织如下。首先,我们在第2节介绍了将神经网络应用于语义相似度测量的相关研究。第二,我们在第3节描述了我们的句子相似度计算模型的细节。第三,我们在第4节中介绍了我们的实验。最后,我们在第5节中得出结论。
2. 相关工作
在自然语言处理领域,有很多句子相似性计算方法。这些句子相似性的计算方法按照应用神经网络的类型可以大致分为三个方面,包括CNN、RNN和DNN。本节从这三个方面对相关工作进行回顾。
2.1 基于CNN的句子相似性的计算方法
Kalchbrenner等提出了一种动态卷积神经网络(DCNN)模型来对句子进行建模,并进行了4次实验来验证所提出的模型。所提出的句子表示模型具有动态k-max池化、不需要外部资源和语言独立等三个方面的特点。He等提出了一种基于卷积神经网络的句子模型,目的是从不同角度提取特征,并通过不同粒度(granularities)的相似度量对句子表示进行比较。为了缩短训练时间,He和Lin利用卷积神经网络和双向长短期记忆网络的结合来测量文本相似度,在3个SemEval任务和2个答案选择任务上取得了满意的结果。
He et al和He and Lin采用深度神经网络来计算句子相似度测量。特别的,He和Lin应用了19个子层的CNN和双向LSTM的深度架构。然而,我们的模型与他们的模型在架构上有所不同。首先,我们提出了一种新的网络输入映射的构造方法。第二,我们应用浅卷积神经网络,并对网络进行了一些修改。第三,我们的神经网络的输出是一个向量,用来计算句子相似度的得分。在其他工作中,句子相似度的得分是由神经网络直接计算出来的。
2.2 基于RNN的句子相似性的计算方法
Socher等人提出了一种用于释义检测的无监督递归自动编码器(recursive auto encoder, RAE),它基于展开目标,学习获取句法树中短语的特征向量。这些提取的特征被应用于计算句子对的词与词组的相似度。Hermann和Blunsom介绍了一种基于组合分类自动编码器的模型,该模型引导了句子内意义的非线性转换,并学习了句子的高维嵌入,并证明了从该模型中学习到的句子表征在一系列任务中既有效又通用。Tai等提出了树状结构的长短期记忆网络(Tree-LSTMs)formodeling句子,它由一个输入向量和任意多子单元的隐藏状态组成其状态。在语义关联性预测和情感分类的任务上对树状结构长短期记忆网络进行了评估,在这两个任务上都有良好的表现。
2.3 基于DNN的句子相似性的计算方法
Lu和Li开发了一种深度神经网络来匹配短文,它可以有效地捕捉他们匹配文本中的非线性和层次性。首先,作者考虑了两个文本中组件之间的交互作用,构建了一个交互空间。然后,他们将空间中的局部决策输入到深度神经网络的相应神经元中。最后,他们利用深度神经网络输出层的逻辑回归来计算最终的匹配得分。他们的工作优于各种基于内产品(inner-product)的匹配模型。
3. 提出的模型WSV-SCNN-SV
在本节中,我们提出了基于神经网络的模型,即 “词组向量-浅卷积神经网络-句子向量”(the word set vectors-the shallow convolutional neural network-the sentence vector, WSV-SCNN-SV)。该模型的主体是浅卷积神经网络,它将一组 "词集向量"作为输入特征图,输出句子表示为句子向量。"词组向量"是在词嵌入的基础上改进的新思路。与词嵌入相比,它包含了更多的句子语义信息,我们基于卷积神经网络学习到的句子向量来计算相似度,而不是采用卷积神经网络。
本节的组织结构总结如下。首先,我们介绍了我们模型的整体架构,然后,我们详细阐述了我们模型的每个部分。
3.1 模型总体架构
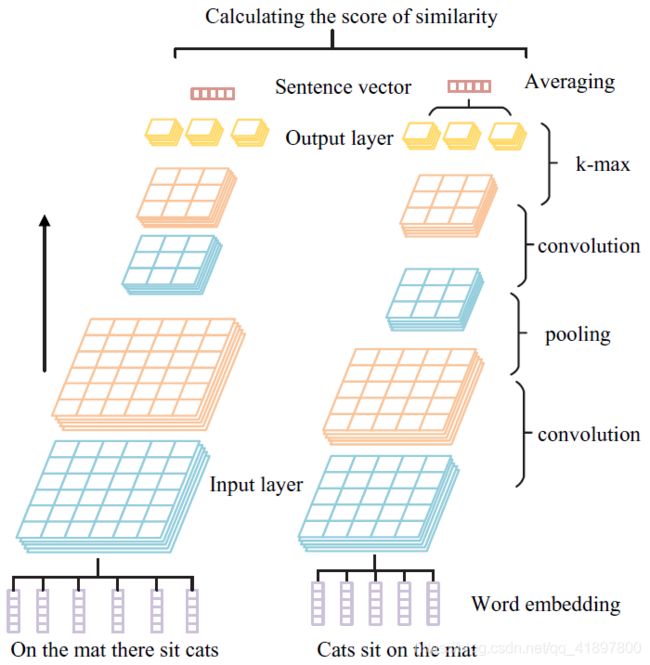
WSV-SCNN-SV的混合架构如图1所示。在该架构中,有四个部分。
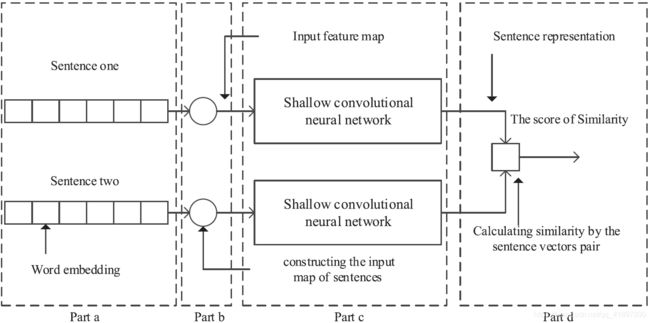
a. 句子的预处理:由于原始句子不为机器所接受,因此在输入机器之前应进行处理和编码。句子的预处理包括词的分割(word segmentation)、去掉停顿词(removal of stop words)、词干(stemming)等。
如"workers"这个词,worker是词干,work是词根,-er 是词缀,-s就是词尾
在我们的工作中,我们采用词嵌入的方式对句子进行编码,每个句子中的词经过预处理后由其对应的词向量来表示。
b. 输入模型:我们提出了一种新颖的方法,将词向量序列转化为三维张量。该张量包含句子丰富的语义和语法信息,是下一个卷积神经网络的输入特征图。
c.我们的浅层卷积神经网络:我们的卷积神经网络的工作是从输入张量中学习语义和语法特征,并产生句子的表示,我们对卷积神经网络做了一些修改。首先,我们从模型中删除了全连接层。在流过(flowing over)几个卷积层和池化层后,将张量转换成一个矢量,从输入张量中提取丰富的特征。第二,我们在模型中同时应用k-max池化和max池化操作。第三,我们通过k-max池化操作,使我们的卷积神经网络支持输入特征图的不固定大小。
d. 相似性计算部分:句子向量对被用来计算相似度得分。有许多方法可以用于两个向量之间的相似度测量。在我们的工作中,我们分别使用余弦距离、欧氏距离和曼哈顿距离。
综上所述,模型前三部分的目标是:完成将句子嵌入到高维空间的任务。我们模型最后一部分的目标是计算与句子向量对的相似度得分。
3.2 句子预处理
由于每个词都是一个句子的最小语义单元(atomic semantic unit),所以对于机器从句子中捕捉细粒度(fine-grained)的特征具有重要意义。不同的句子可能会用不同的词来表达高相似度的信息,比如 "He studies computer science in college "和 “His major is CS”.在分布式词嵌入等建模词方面已经做了很多了不起的研究,其明确地编码了很多语言规律性和词的相似性。
其中关于分布式词嵌入的著名工作是word2vec模型,在word2vec模型中,向量计算的结果向量(“Madrid”)-向量(“Spain”)+向量(“France”)与向量(“Paris”)相比,这比其他词向量更接近。在相关论文中,基于word2vec来建立衡量相似度的句子模型是通用的。同样,在本文中,我们应用预训练的词嵌入来为词建立模型。
有很多利用词嵌入产生句子简单的表示的方法。假设 w i = ( w i 1 , w i 2 , … , w i d ) \mathbf{w}_{i}=\left(w_{i}^{1}, w_{i}^{2}, \ldots, w_{i}^{d}\right) wi=(wi1,wi2,…,wid)是一个d维词向量,对应句子中的第i个词。一个包含n个词的句子可以用如下方式表示:
S = 1 n ∑ i = 1 n w i (1) S=\frac{1}{n} \sum_{i=1}^{n} w_{i} \tag{1} S=n1i=1∑nwi(1)
S = ( w 1 ⊤ , w 2 ⊤ , … , w n T ) (2) S=\left(\mathbf{w}_{1}^{\top}, \mathbf{w}_{2}^{\top}, \ldots, \mathbf{w}_{n}^{T}\right) \tag{2} S=(w1⊤,w2⊤,…,wnT)(2)
在之前的研究中,这些句子的表示被输入到神经网络中完成最终任务。公式1使用这些词向量的平均值来表达句子,尽管这个过程非常简单,但其在实践中的表现并不差。公式2将词向量连缀起来,生成一个二维矩阵来表达句子,这是一种常用的句子表示方法。与公式1不同,公式2的方法保留了词的顺序信息。Kim使用了该方法,Hu等对公式2进行了一些改进。
然而,我们的想法与之前的工作不同。我们的动机是,句子表示应该像单词嵌入一样从神经网络中学习。在句子中的单词由其对应的单词向量表示后,我们构建一个三维张量,然后将张量放入卷积神经网络中学习句子表示。
3.3 基于 "二元组(binary-gram)词组向量 "的输入模型
词不是句子表述中唯一需要考虑的因素。词与词组(phrase)之间、词组与词组之间的依赖关系也不能忽视。公式2中句子的表示可以看作是一个宽度为1,高度为n,通道为d的特征图。但是,该表示法的缺点是忽略了词与词之间的长程语义依赖关系(long-range semantic dependencies)。
为了在我们的模型中考虑长程语义依赖性,我们提出了一个新的向量,称为 “词集向量(word set vector)”。由式2,句子可以由词向量的平均值来表示,我们将这一思想从句子扩展到短语和相互之间有语义依赖关系的词集,这就是词集向量的思想,词集向量 w ‾ \overline{\mathbf{w}} w由j个词向量 w l 1 w_{l_1} wl1 , w l 2 w_{l_2} wl2 ,…, w l j w_{l_j} wlj组成,定义如下:
w ‾ = ∑ i = 1 j λ i w l i (3) \overline{\mathbf{w}}=\sum_{i=1}^{j} \lambda_{i} \mathbf{w}_{l_{i}} \tag{3} w=i=1∑jλiwli(3)
其中,序列{ l 1 l_1 l1, l 2 l_2 l2,…, l j l_j lj}表示序列{1,2,…,n}的子序列,表示词向量的权重( ∑ i = 1 j λ i = 1 , λ i > 0 \sum_{i=1}^{j} \lambda_{i}=1, \lambda_{i}>0 ∑i=1jλi=1,λi>0)
由词向量 w l 1 w_{l_1} wl1 , w l 2 w_{l_2} wl2 ,…, w l j w_{l_j} wlj组成的词集向量是顺序敏感的。由j个词向量(允许重复的词向量)组成的词集向量w定义为j-gram词集向量。我们认为参数应该由机器来训练,它可以计算如下:
λ i = exp ( α i ) ∑ j exp ( α j ) , α j ϵ R (4) \lambda_{i}=\frac{\exp \left(\alpha_{i}\right)}{\sum_{j} \exp \left(\alpha_{j}\right)}, \alpha_{j} \epsilon \mathbb{R} \tag{4} λi=∑jexp(αj)exp(αi),αjϵR(4)
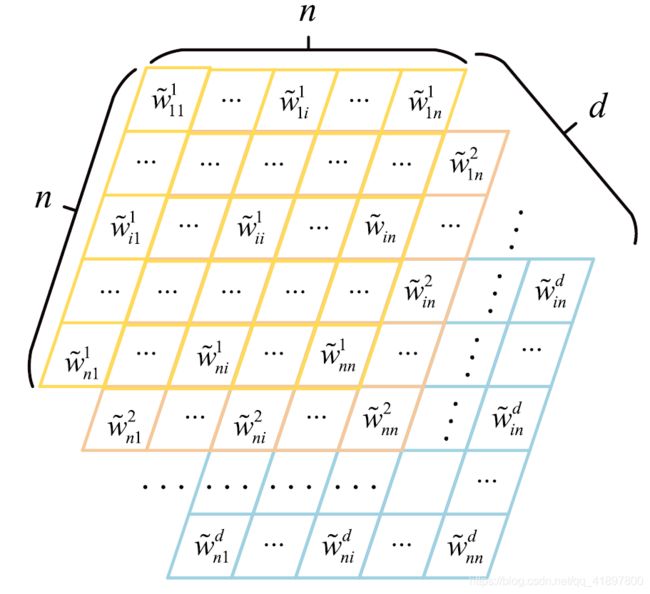
词集向量采用权重来惩罚紊乱词向量。有n个词的句子有nj个j-gram词集向量。有n个词的句子有n2个d维的binary-gram词集向量,可以转化为n个宽度、n个高度、d个通道的特征图。binary-gram词集向量的计算方法为:
w ~ l 1 l 2 = λ 1 w l 1 + λ 2 w l 2 (5) \tilde{\mathbf{w}}_{l_{1} l_{2}}=\lambda_{1} \mathbf{w}_{l_{1}}+\lambda_{2} \mathbf{w}_{l_{2}} \tag{5} w~l1l2=λ1wl1+λ2wl2(5)
其中 l 1 , l 2 ϵ { 1 , 2 , … , n } , λ 1 + λ 2 = 1 , λ 1 , λ 2 > 0 l_1,l_2\epsilon\{1,2,…,n\},\lambda_1+\lambda_2=1,\lambda_1,\lambda_2>0 l1,l2ϵ{ 1,2,…,n},λ1+λ2=1,λ1,λ2>0。如果 l 1 = l 2 l_1=l_2 l1=l2, w ~ l 1 l 2 \tilde{\mathbf{w}}_{l_{1} l_{2}} w~l1l2表示一个binary-gram词集向量。权重 λ 1 \lambda_1 λ1和 λ 2 \lambda_2 λ2通过梯度下降法计算得到。
算法1显示了输入特征图的构成方式。图谱的单元是句子中的这些binary-gram词集向量。
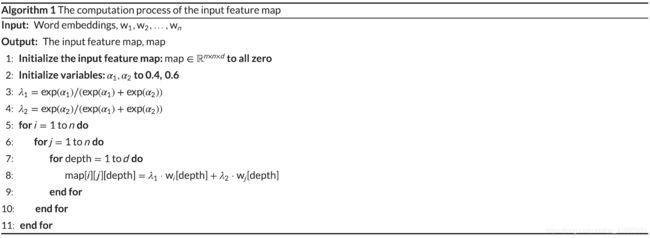
由以上代码可见,实际上只是很简单的把二维向量转化扩充到了三维空间,这个维度方便以后使用图像处理吧
图2展示了由n2个词集向量组成的特征图。这是本文的一个创造性工作,将句子的特征图从二维矩阵扩展到三维张量。由于特征图在形式上与图像数据相同,我们希望接下来的卷积神经网络能够像在图像上一样,完全从输入的特征图中提取句子特征。
![]()
3.4 我们的浅层卷积神经网络
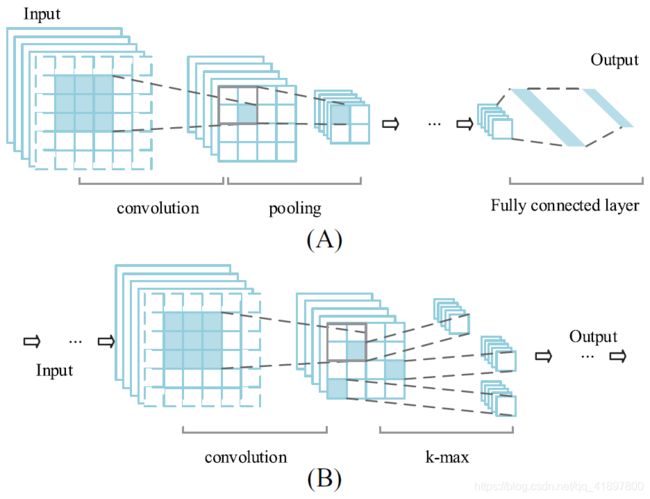
完整的多层卷积神经网络应该包含全连接层,就像图3A一样。在我们的卷积神经网络中,我们将全连接层从网络中移除,因为它对于学习句子向量来说并不是必不可少的,并且会消耗训练的时间。我们提出的卷积神经网络只包含由卷积子层和池化子层组成的层。此外,在最后一层的输出端应用了一个计算句子向量的和函数。
卷积子层:卷积的公式如下:
X j l = ϕ ( ∑ i ∈ M j X i l − 1 ∗ K i j l + b j l ) (6) X_{j}^{l}=\phi\left(\sum_{i \in M_{j}} X_{i}^{l-1} * K_{i j}^{l}+b_{j}^{l}\right) \tag{6} Xjl=ϕ⎝⎛i∈Mj∑Xil−1∗Kijl+bjl⎠⎞(6)
其中 X j l X_{j}^{l} Xjl表示第l-th子层上的第j个图,(x)表示激活函数, M j M_j Mj表示第(l-1)-th子层上的图数,Kl表示第l-th子层的滤波器, b j l b^l_j bjl表示偏差。
我们不对卷积子层做任何修改。从图3A中可以看出,卷积运算中采用零填充(虚线块为零填充),这样卷积层输入特征图的大小与卷积层输出特征图的大小相同。
卷积子层的激活函数是ReLU函数
ϕ ( x ) = { x if x ≥ 0 0 if x < 0 (7) \phi(x)=\left\{\begin{array}{l} x \text { if } x \geq 0 \\ 0 \text { if } x<0 \end{array}\right. \tag{7} ϕ(x)={ x if x≥00 if x<0(7)
虽然,ReLU函数的性能比sigmoid函数的性能差,但它简单,并且需要较少的训练时间来实现收敛。
最大池化子层:池化子层是在卷积子层之后进行的。池化操作也称为向下采样(down sampling)。在池化操作中,特征图的宽度维度和高度维度都会减小,但特征图的深度维度不变。以2×2的池化窗口为例(如图3A所示),经过池化操作后,特征图的宽度和高度将减少一半。如果多层网络的输入特征图的大小是确定的,经过多次池化操作后,输出特征图的大小也是确定的。
卷积的公式如下:
X j l = β j l down ( X j l − 1 ) + bias j l (8) X_{j}^{l}=\beta_{j}^{l} \text { down }\left(X_{j}^{l-1}\right)+\operatorname{bias}_{j}^{l} \tag{8} Xjl=βjl down (Xjl−1)+biasjl(8)
其中, β j l \beta_{j}^{l} βjl代表权重,down(X)表示向下采样, bias j l \operatorname{bias}_{j}^{l} biasjl表示偏差。
k-max池子层:句子的长度是可变的。为了支持不同长度的句子,卷积神经网络的输入层的大小必须是可以改变的。为了在输入特征图可变的情况下保持卷积神经网络输出层的大小不变,在最后一个池化层上采用k-max池化来代替max池化操作。图3B显示了输入特征图上的k-max池化操作(k=3)。k-max池化的伪代码如下:

AscendingSort:从正常的低到高顺序排列数据;例如,从A到Z或从0到9。与降序排序相反。
我们的模型中使用的k-max池化与Kalchbrenner等人的工作中使用的k-max池化不同。在其工作中,经过k-max池化后,数据在原始特征图中的相对位置被保留。相反,我们丢弃了数据的相对位置,因为我们随后将数据相加来计算句子向量。在图3B中,对任意n×n×d(n≥2)的输入特征图进行k-max操作,会产生三个d维向量。
和函数功能:以 "The cat sits on the mat "这个句子为例,它的主语、谓语、宾语所传达的意义足以暗示整个句子。同理,我们希望通过k-max池化操作,从句子中 "提取 "出传达句子意义的单词或短语。通过k-max池化输出的k个向量称为句子的向量组。我们的网络中没有全连接层。句子向量是句子的向量组的平均值,计算方法是:
v S = 1 k ∑ i = 1 k u i (9) v_{S}=\frac{1}{k} \sum_{i=1}^{k} u_{i} \tag{9} vS=k1i=1∑kui(9)
其中 v s v_s vs代表了句子向量, u 1 , … , u i , … , u k u_1, …,u_i,…,u_k u1,…,ui,…,uk表示句子的向量组。
算法3给出了浅卷积神经网络的伪码:

由以上代码可见,k-max的思想就是:不管输入的句子长度是多少,最后一层总是有一个width×height,显然这两个值不可能总是n×n,或者多少,此时应该很小,不会是word2vec产生的300维那么大,然后对每一个depth排序,最后例如想产生主谓宾的话,k=3,这样毫无疑问会影响其他的例如定状补的分类,但这就相当于提取特征了吧,以及depth对应于图像处理里面颜色的深度,这里对应于一开始word2vec的维度,所以经过k-max池化之后,会产生维度相同的k个向量,最后求平均即为句子向量
在我们的应用中,我们网络中的层数不超过三层。全连接层的工作由下一个计算单元代替。结构简单、训练速度快是我们模型的优点。两层网络的模型如图4所示。
3.5 相似性计算
句子的相似度是由句子向量对计算的。计算向量相似度的方法有很多,我们选择余弦距离、欧几里得距离和曼哈顿距离来评价相似度的得分。但欧氏距离和曼哈顿距离的取值范围不是[0,1],我们需要对它们进行修改。欧氏距离和曼哈顿距离计算的得分如下:
score = f ( ∥ v s 1 − v s 2 ∥ ) , score ∈ [ 0 , 1 ] (10) \text { score }=f\left(\left\|v_{s 1}-v_{s 2}\right\|\right), \text { score } \in[0,1] \tag{10} score =f(∥vs1−vs2∥), score ∈[0,1](10)
其中 f f f表示单调递减函数, f f f的值域为[0,1]。我们的模型中使用三种不同的 f f f: f 1 ( x ) = e − x , f 2 ( x ) = 1 1 + e − x , f 3 ( x ) = 1 1 + x f_{1}(x)=e^{-x}, f_{2}(x)=\frac{1}{1+e^{-x}}, f_3(x)=\frac{1}{1+x} f1(x)=e−x,f2(x)=1+e−x1,f3(x)=1+x1,由于ReLu函数的输出不是负值,所以不需要关注余弦距离的负值。句子向量对的余弦距离可以直接作为相似度的得分。
4. 实验结果与分析
在本节中,我们介绍了详细的实验设置和我们训练过程中的损失函数,之后详细分析和说明每一个实验。两个不同的数据集SICK和MSRP被用来评估我们的模型。
4.1 实验设置
我们在一台内存为8GB的个人电脑和英特尔i7四核CPU上做了所有的实验。在实验中,我们使用GloVe单词嵌入(在维基百科2014+Gigaword 5上训练),并在训练中对词嵌入进行微调,GloVe中不存在的单词被随机初始化。
Pennington J, Socher R, Manning C. GloVe: Global vectors for word representation. Paper presented at: Conference on Empirical Methods in Natural Language Processing; 2014; Doha,Qatar.
如果在池化子层和k-max池化子层中不允许填充(padding),则语句长度必须满足下限。句子的长度满足
Length s ≥ ( f w ) L − 1 k (11) \text { Length }_{s} \geq\left(f_{w}\right)^{L-1} k \tag{11} Length s≥(fw)L−1k(11)
其中, f w f_w fw表示池化窗口的宽度(本文中,池化窗口的宽度等于其高度),k表示k-max的参数,L表示隐藏层数。
在模型中,输入层的通道数与词嵌入的维度相同(通常超过50维),如果在网络中增加一个新的隐藏层,将大大增加模型中的训练参数数量,为了限制参数的数量,层数L不超过3个。
在训练任务中,为了保持同一批次的输入图大小相同,我们必须在输入层中使用零填充,但在测试任务中,模型支持不同大小的输入图。
该模型包含许多超参数(hyper parameters)。这是该模型的一个缺点。有层数L、参数k、卷积滤波器的宽度、池化窗口的宽度以及隐藏特征图的数量要人为规定。但非完全连接层和更少的隐藏层的模型在参数总量上比大多数深度神经网络要少。
4.2 训练
我们实验的数据集是SemEval-2014涉及成分知识的句子(Sentences Involving Compositional Knowledge, SICK)数据和微软研究释义识别(Microsoft research paraphrase identificationM, SRP)。
Das D, Smith NA. Paraphrase identification as probabilistic quasi-synchronous recognition. Paper presented at: Joint Conference of the Meeting of the ACL and the International Joint Conference on Natural Language Processing of the AFNLP: Volume 1; 2009; Suntec, Singapore.
Dolan B, Quirk C, Brockett C. Unsupervised construction of large paraphrase corpora: Exploiting massively parallel news sources. Paper presented at: International Conference on Computational Linguistics; 2004; Geneva, Switzerland.
SemEval(Semantic Evaluation)是由计算语言学协会词汇特别兴趣小组组织的计算语义分析系统。SICK是SemEval-2014任务1竞赛的数据集。
Nakov P, Zesch T. Proceedings of the 8th InternationalWorkshop on Semantic Evaluation (SemEval 2014): Association for Computational Linguistics and Dublin City University; 2014; Dublin, Ireland. http://www.aclweb.org/anthology/S14-2
其目的是通过语义关联性和包含性评价全句上的组成分布式语义模型。许多参赛者就该任务提交了他们的作品,他们的结果可以在Marelli等人的工作中获得。SICK包含训练数据(4500个句子对)、试验数据(500个句子对)和测试数据(4927个句子对)。句子对的相关度得分可以从1(完全不相关)到5(非常相关)。MSRP包含训练数据(4076句对)和测试数据(1725句对)。句子对的相关度得分为1或0。
模型的超参数设置如下:k-max池化的参数k为3;卷积滤波器的大小为3×3;单次训练批次大小设置为50。我们对这两个任务的词嵌入进行微调。这两个任务的损失函数是不同的。
在SICK数据集上,我们训练模型使均方误差(MSE)的损失函数最小化:
loss 1 = 1 m ∑ i = 1 m ( sim p − sim l ) 2 (12) \operatorname{loss}_{1}=\frac{1}{m} \sum_{i=1}^{m}\left(\operatorname{sim}_{p}-\operatorname{sim}_{l}\right)^{2} \tag{12} loss1=m1i=1∑m(simp−siml)2(12)
其中, s i m p sim_p simp表示相似度得分的预测值, s i m l sim_l siml表示相似度得分,相似度得分是按每对数据收集的10个人类评分的平均值计算的,m是训练数据集的规模。
此外,为了探究损失函数对结果的影响,我们使用了另一个损失函数,即KL发散损失:
loss 2 = 1 m ∑ i = 1 m [ q ⋅ log q p + ( 1 − q ) ⋅ log ( 1 − q ) ( 1 − p ) ] (13) \operatorname{loss}_{2}=\frac{1}{m} \sum_{i=1}^{m}\left[q \cdot \log \frac{q}{p}+(1-q) \cdot \log \frac{(1-q)}{(1-p)}\right] \tag{13} loss2=m1i=1∑m[q⋅logpq+(1−q)⋅log(1−p)(1−q)](13)
其中p为归一化 s i m p sim_p simp,q为归一化 s i m l sim_l siml。考虑到分母p和1-p可能为零,因此对该损失函数采用拉普拉斯平滑法。
在MSRP数据集上,我们训练模型以最小化预测值和标签之间的交叉熵。
4.3 实验分析
图5展示了SICK测试集上的结果。图下方的六个结果是SemEval发布的最好的六个结果。这些结果代表了传统方法的高水平。可以看出,根据Pearson系数(SemEval官方排名),该模型的结果在上述结果中排名第三。同样,根据Spearman系数,该结果排名第三,MSE上的结果排名第四,非常接近第三0.3593。我们模型的结果与最佳结果之间没有明显的差异。我们的结果与最好的在Pearson、Spearman、MSE上的差异分别为0.0159、0.0137、0.0382。图5还提供了本工作结果与两种不同RNN模型结果的比较。与RNN相比,CNN网络在处理句子中词与词之间的长期和短期依赖关系方面处于劣势。令人惊讶的是,模型的测试结果比这两种RNN模型的结果略好。但我们模型的结果不如文献的结果(参见He et al和He and Lin的作品)。他们的工作结果在Pearson系数上分别为0.8686和0.8784。尽管我们的模型性能比这些深度神经网络差,但我们的工作还是很有价值的:与传统方法相比,我们的工作取得了更好的性能;与深度神经网络相比,我们的模型由于架构简单,训练速度快,所以在应用中非常实用。
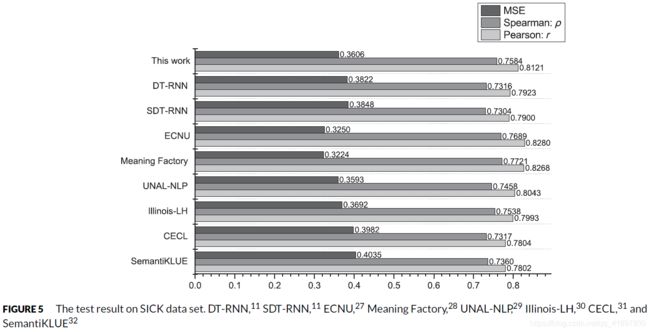
表1列出了在SICK数据集上表现良好的几个模型使用的方法和资源。可以看出,表现良好的ECNUmodel使用了四种学习方法、WordNet和额外的语料库(Corpus);排名第二的模型,即The Meaning Factory,也使用了三种不同的资源,包括WordNet。相比之下,我们的模型只使用了词嵌入和卷积神经网络。我们的模型在结构上要简单得多,但可以达到同样程度的测试性能。

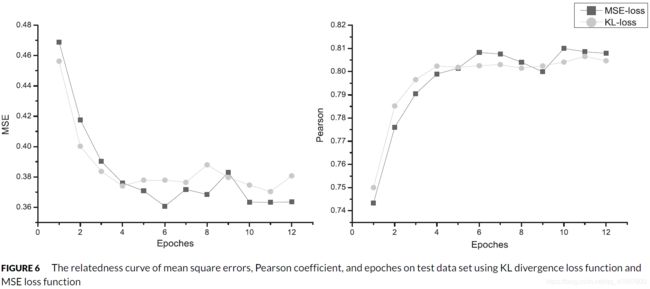
图6展示了我们模型在SICK集上的训练曲线(学习率为10-3)。从图6可以看出,这两种损失函数的性能在测试结果上没有明显的差异。结果表明,两条曲线都是快速收敛的。
我们使用不同维度的词嵌入来测试我们的模型,并记录其训练时间。我们选择了一个单层网络来完成实验。表2显示了相应的结果。所有列出训练时间的实验都是在同一台计算机上完成的。
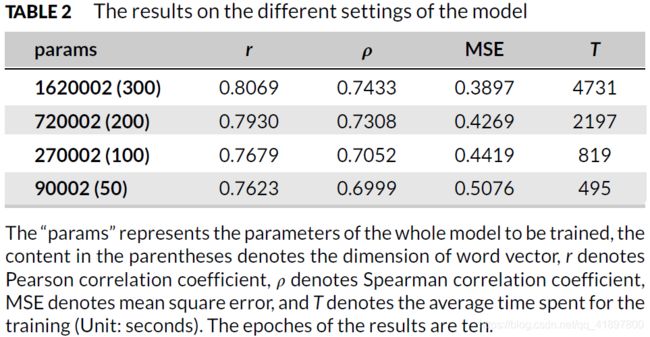
从表2可以看出,一个包含162万个参数、花费80分钟左右的单层网络的训练结果可以排在图5中的第三位。在减少一半的参数数量后,测试结果并没有表现出明显的差异,同样的时间段,测试结果的皮尔逊相关系数达到0.5。结果皮尔逊相关系数达到0.793,即图5中的第四位,与第三位非常接近。同时,消耗的时间可以减少到一半:训练过程可以在37分钟内完成。
虽然表中第三行的模型(100维词向量)在10个epochs下的表现并不亮眼,但如果epochs为40个,其皮尔逊相关系数的指标为0.7868左右,其均方误差约为0.3878,而整个模型的参数只有表中第二种情况的3/8。
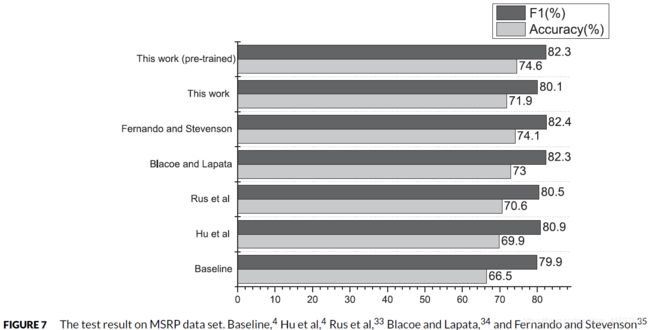
图7显示,我们的模型在SICK语料上进行预训练的结果在MSRP测试集上的表现优于其他模型。同时,我们的模型在没有进行预训练的情况下,其结果表现不佳。因此,预训练对提高我们模型的性能是有帮助的,我们假设我们的模型在大量合适的训练数据上进行预训练后可能会有更好的表现,这一点我们留待以后的工作来解决。(图7中,Huet al的工作是基于CNN的,其他工作是基于传统方法的。Hu et al报道了Baseline和Rus et al的工作结果,Rus et al的工作结果是报告中最好的一个)
5. 结论
本文提出了一种基于神经网络的词嵌入模型来测量句子的相似度。在这个领域,很多复杂的架构被提出来测量句子的相似度。这些模型在减少资源占用方面表现不佳。本文的模型就是为了处理这类问题而提出的。
本文中,模型的层数小于4层。简单模型的参数较少,训练时间成本短。我们的实验证明,即使是浅层卷积神经网络也能实现相似度得分的良好预测。本文还比较了词嵌入的不同维度和不同损失函数对测试结果的影响。在实验中证明,我们的模型是非常灵活的。提高嵌入维数可以达到更好的效果,降低嵌入维数可以大大提高训练速度,但对Pearson相关系数的影响较小。