yolov2训练_YOLO、YOLOv2整理
1. YOLO
原文:You Only Look Once: Unified, Real-Time Object Detection
YOLO的思路是将目标检测问题直接看做是分类回归问题,将图片划分为S×S的格子区域,每个格子区域可能包含有物体,以格子为单位进行物体的分类,同时预测出一组目标框的参数。
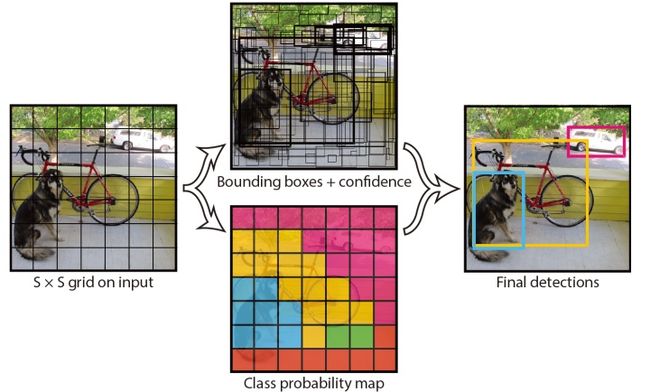
检测过程
YOLO相当于将图片划分成
每个目标框包括5个参数:
-
表示格子左上角坐标,
表示整张图的宽高,
表示计算得到的预测框的中心坐标。
- 整理得到
,即当
时,预测框的中心坐标落在格子内部。
- 如写成
,则可以得到一些博客中写的形式:
,使用格子的行列(
)直接替换坐标。
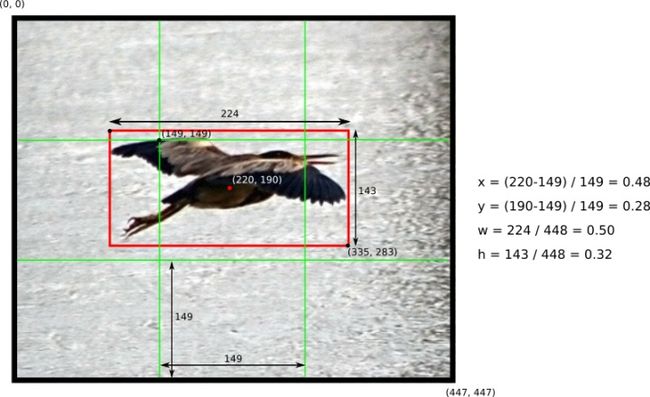
- 此处格子左上角坐标为(149,149),预测框中心坐标为(220,190)。
目标框置信度的定义为
由于YOLO只以格子为单位进行分类,每个目标框属于每一类的置信度由对应格子的分类概率和目标框的置信度相乘得到,即
因此,网络的整体输出为一个张量,大小为
最后,同样预测对得到的目标框使用NMS,抑制掉多余的目标框。
网络结构
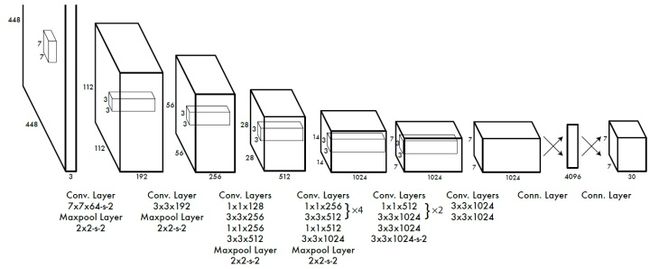
YOLO的网络结构较为简洁,只使用了
训练过程
YOLO的loss function简单地采用了平方损失,定义为:
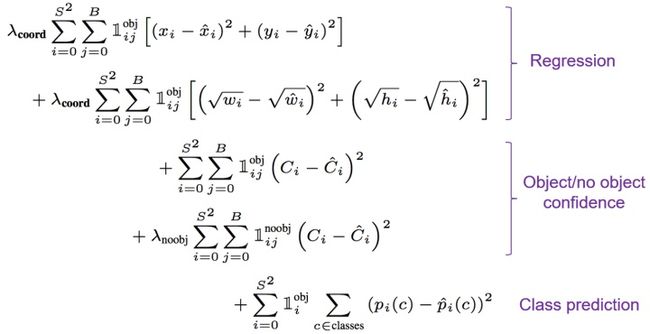
前两行为目标框回归的损失;第三四行分别计算物体和背景部分目标框的置信度损失;第五行计算包含物体格子的分类损失。
-
表示第i个格子包含物体时值为1,否则为0;在
个预测框中,当第j个与预测框和ground truth有最大的IoU时,
值为1,否则为0,即回归损失是微调性质。
- 为了使得目标框的偏移对 较大目标框 的的影响低于 小的目标框,对于
进行了开平方根操作。
-
和
为超参,用来权重协调,论文中使用
,
,增大回归损失的比例,减少对背景置信度损失的计算。
实验部分
YOLO出色的地方就是有着极高的检测速度(45fps),同时又能达到较好的mAP(63.4%)。
由于按照空间划分格子,对于较小物体的检测受限制。
Fast R-CNN和YOLO的错误分析:
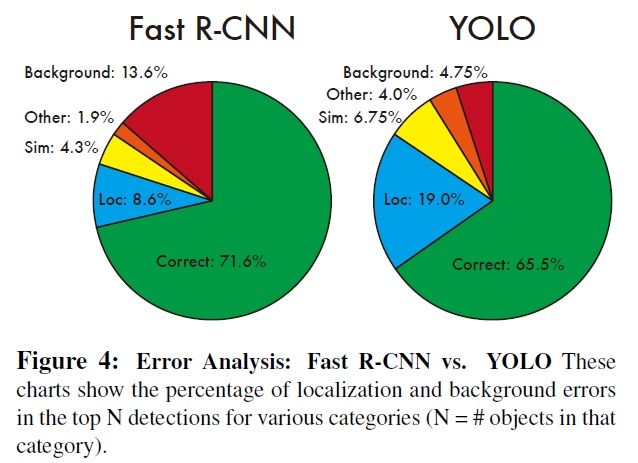
错误类型:
- Correct: correct class and IOU > .5
- Localization: correct class, .1 < IOU < .5
- Similar: class is similar, IOU > .1
- Other: class is wrong, IOU > .1
- Background: IOU < .1 for any object
和Fast R-CNN相比反映,YOLO很难准确定位目标,但是对背景识别能力较强一些。
文中尝试将两者结合,达到了较高的mAP,弥补了彼此的缺陷,没有明显增加计算负担,但是损失了YOLO检测速度。
2. YOLOv2
原文:YOLO9000: Better, Faster, Stronger
YOLOv2在原有的基础上,使用了anchor,提出了一系列的改进,同时使用了一种新的网络结构,在保持实时速度的前提下,提高了性能(76.8 mAP,67fps)。
并进一步通过联合训练,使用很多只包含标签信息的数据集,训练扩充分类的能力,得到了可以分类9000类物体的YOLO9000,可以说是很大的跨越。
改进
k-means clusters
YOLOv2使用了anchor,但并非手动选取,而是通过聚类的方式学习得到。在训练集上使用k-means算法,距离衡量的方式为:
目的使得大框小框的损失同等衡量。
聚类的结果发现,聚类中心的目标框和以前手动选取的不大一样,更多的是较高、较窄的目标框。聚类结果也有了更好的性能。
框回归
YOLOv2对框回归过程进行了改进,过去的框回归过程,由于对
YOLOv2在框回归时,为每一个目标框预测5个参数:
-
为格子的左上角坐标(行列值),
为anchor原始的宽高。
- 当
时,
,
刚好位于格子的中间。
-
用来控制宽高的缩放,
用来表达置信度信息。
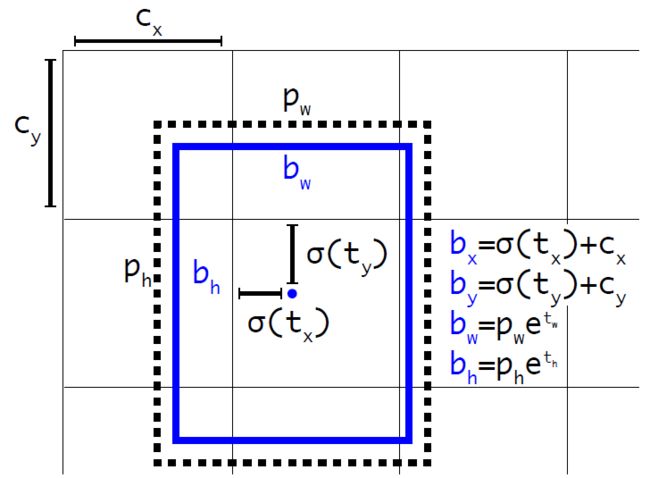
通过使用sigmid函数,将偏移量的范围限制到
另外,YOLOv2的分类置信度不再共享,每个anchor单独预测。即每一个anchor得到
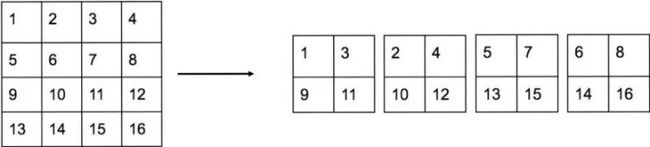
passthrough layer
passthrough层在预测时使用,将网络中间层的特征图输出(具体见下文),将下采样时同一位置的像素分解成4个子图,concat合并起来。变换后通道数变为4倍,下采样2倍。如从512×26×26变为2048×13×13。
passthrough层的使用,融合了较高分辨率下的特征信息。
多尺度训练
由于网络中只包含卷积层和池化层,YOLOv2为了增加网络的鲁棒性,在训练过程中动态调整网络的输入大小,同时相应地调整网络的结构以满足输入。因为网络下采样32倍,要求输入尺寸包含因数32。
网络结构
YOLOv2中使用了一种新的基础网络结构,基于Googlenet,名为Darknet-19。拥有19个卷积层和5个Max Pooling层,网络中使用了Batch Normalization来加快收敛。
下图为基础网络的结构,output部分是输入为224×224的输出情况,网络总体下采样32倍。
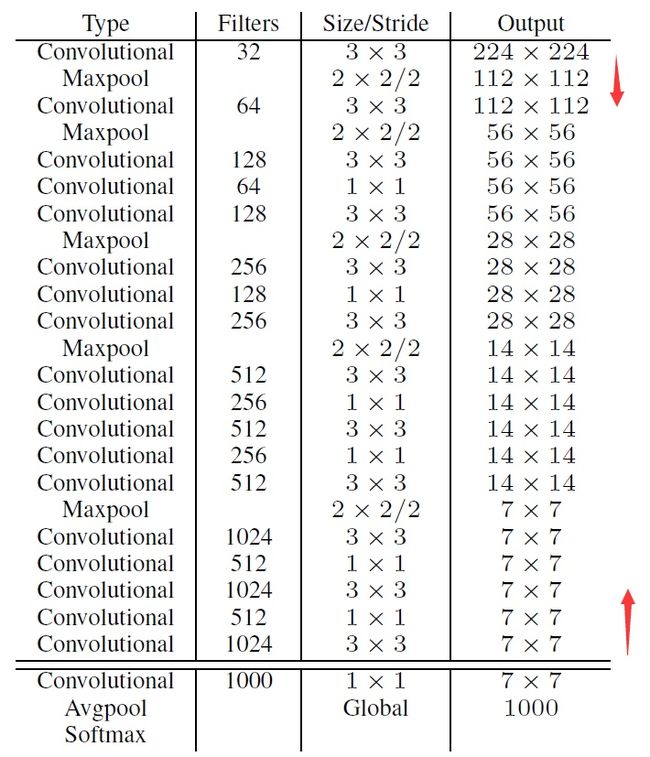
最后的conv层、avgpool层和softmax层是用于分类训练时的输出结构。当进行预测时,去掉这三层,只保留箭头间的部分进行特征提取。
用网络进行目标检测时,再添加一些conv层和一个passthrough层。具体组织如下:
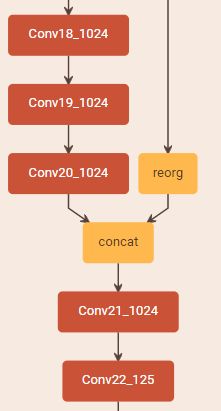
- conv18即Darknet-19去掉分类输出3层后的最后一个卷积层。
- conv19,conv20,conv21为
的卷积层。通道数均为1024。
- reorg即论文中提到的passthrough layer。将conv13(第5个Max Pooling层之前的conv层)进行变换,再和conv20的输出进行concat后作为conv21的输入。conv13层下采样16倍,当图片输入为3×418×418时,conv15的尺寸为512×26×26,进行reorg变换后,尺寸为2048×13×13,和conv20特征图输出的大小一致。
- conv22为
的卷积层,得到预测输出的张量,生成目标框。输出的通道大小为
,
为每个格子预测的anchor数(论文中取5)。
附:完整的网络结构(Netscope)
训练过程
主要的训练过程为:
(1)先使用ImageNet数据集对Darknet-19进行分类训练,输入图片大小为224×224,包含标准的数据扩充方式。
(2)将输入图片大小调整为448×448,进行fine-tune。
(3)去掉分类的输出层,添加上文提到的目标检测输出层,进行目标检查的训练。
YOLOv2在上述训练的基础上,又进行了一个联合训练,额外使用只包含标签信息的数据集来进行分类训练,扩大网络可以预测的物体种类数,使其变得更加强大,即YOLO9000。
标签结构化
(之后补充)
Ex. 参考及部分图片来源
- https://deepsystems.ai/reviews
- https://blog.csdn.net/u011974639/article/details/78208773
- https://hackernoon.com/understanding-yolo-f5a74bbc7967