【paddle深度学习高层API七日打卡营】三岁水课第五天——新春对联
paddle深度学习高层API七日打卡营第五天
-
-
- 基本概念
- 课程目标
- 文本生成任务
- seq2seq
- attention机制(权重)
-
- 数据处理
- 长短时记忆网络(LSTM)
- nn.LSTM的输出
- 注意力机制(Attention)
- 项目实战
-
- 数据
- 构造dataloder
- 模型
-
- 定义AttentionLayer
- 定义Seq2SeqDecoderCell
- 构建主网络Seq2SeqAttnModel
- 总结
-
大家好,这里是三岁,别的不会,擅长白话,今天就是我们的白话系列,内容是paddle2.0新出的高程API,在这里的七日打卡营0基础学习,emmm我这个负基础的也来凑凑热闹,那么就开始吧~~~~
注:以下白话内容为个人理解,如有不同看法和观点及不对的地方欢迎大家批评指正!
课程传送门
基本概念

课程目标

文本生成任务

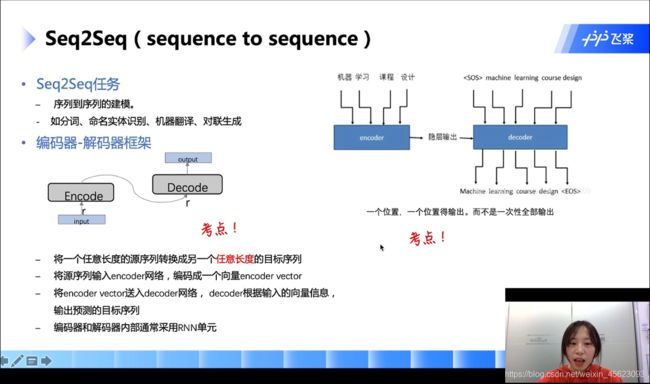
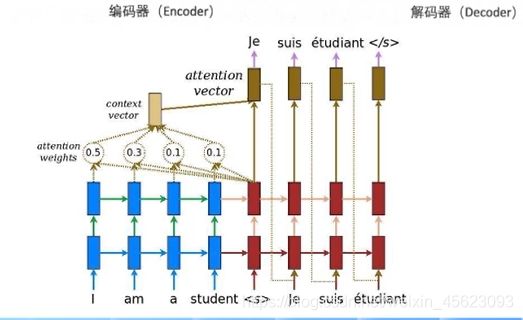
seq2seq
数据经过编码器编码然后到解码器进行解码最后得到以后输出
在里面是一个位置一个位置输出,而不是一起一次性输出
然后他可以将任意长度的原序列转换成另一个任意长度的目标序列
里面编码器和解码器基本上用的是RNN的单元
编码器和解码器的缺点就是无法充分利用输入序列的信息这个时候就会引入一个新的机制——attention
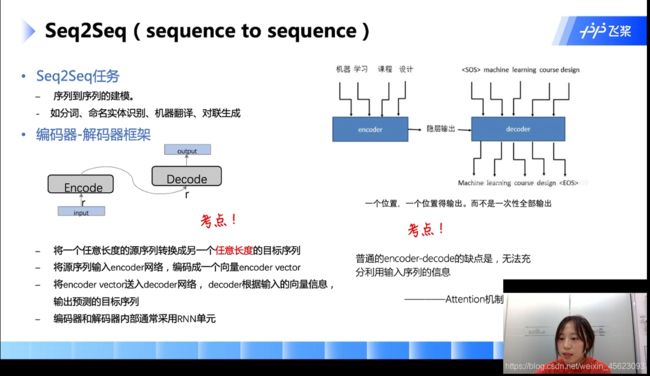
attention机制(权重)


数据处理
-
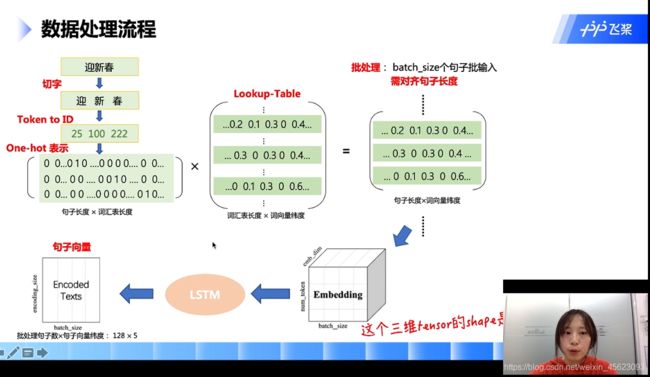
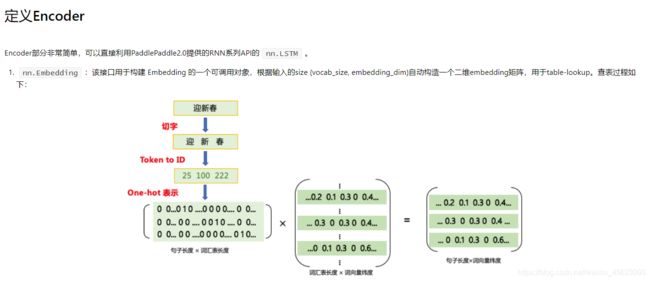
输入一个数据:进行切词然后对照着我们的词汇表对每个词的ID进行查找(ID相当于我们的身份证号码是词汇的唯一标识)
-
然后利用数组把这句话进行表示(表示的方式:词汇表的长度在id位置处显示为1其他均为0)也就是这个数组的大小为句子的长度 * 词汇表的长度
-
数组和已经准备好的字典(这个需要通过其他方式进行学习)进行乘积得到一个新的表示数值
-
一定数量的文本组成一个三维的数据去共同进行处理
-
三维数据经过
LSTM得到了一个降维以后的词向量
长短时记忆网络(LSTM)

nn.LSTM的输出
该网络逐个词进行输入,前一个时刻输入的内容会对下一个时刻产生一定的影响,这样子可以对一些比较长的句子进行解析,内部也存在一定的记忆
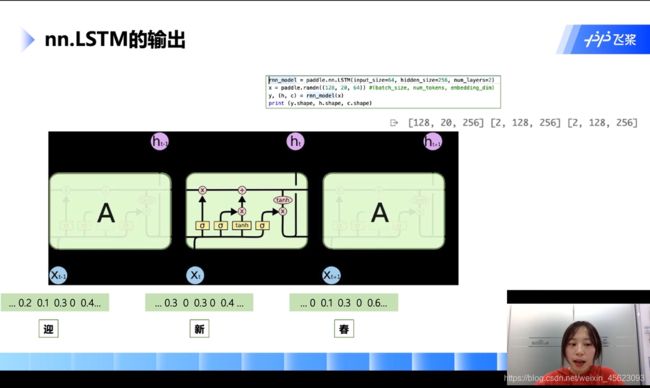
里面X是输入:是一个随机函数,作用:随机初始化一个(128,20,64)的矩阵
128:128个样本同时处理
20:统一的长度20
64:词向量的维度是64
rnn_madel是paddle.nn.LSTM()初始化的一个结果
然后把x输入网络rnn_madel得到y和(h,c)h,c分别代表网络里面的记忆信号和输出信号。y是每个时刻的输出信号

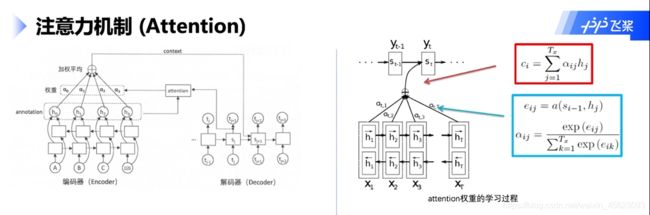
注意力机制(Attention)
逐个输入数据在编码和解码的同时通过训练会得到一个权重,那个词语比较重要最后的权重也会进行一个偏移,整个过程中会更加重视这个词的内容以及对后面的影响。
项目实战
数据


通过paddlenlp.datasets.CoupletDataset.get_datasets()对数据进行读取
train_ds, dev_ds, test_ds = CoupletDataset.get_datasets(['train', 'dev', 'test'])
# 查看代码读取情况
print (len(train_ds), len(test_ds), len(dev_ds))
for i in range(5):
print (train_ds[i])
print ('\n')
for i in range(5):
print (test_ds[i])
数据样本一共是702594,999,10000
下面的数据是词汇ID然后以1为开头2为结尾

通过CoupletDataset.get_vocab来获取词汇表
用vocab.idx_to_token来表示起始符和结束符
vocab, _ = CoupletDataset.get_vocab()
trg_idx2word = vocab.idx_to_token
vocab_size = len(vocab)
pad_id = vocab[CoupletDataset.EOS_TOKEN]
bos_id = vocab[CoupletDataset.BOS_TOKEN]
eos_id = vocab[CoupletDataset.EOS_TOKEN]
print (pad_id, bos_id, eos_id)
构造dataloder


模型
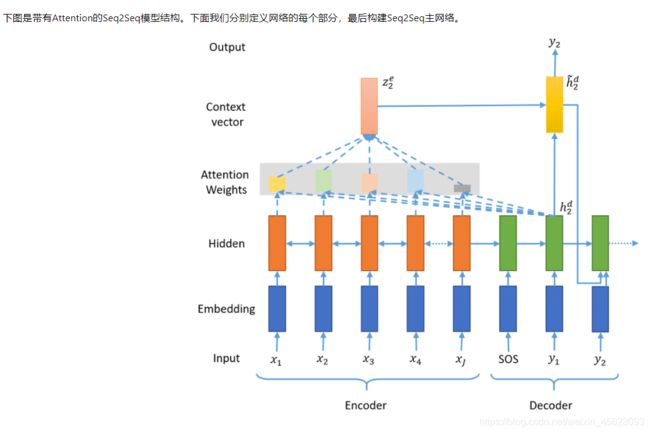
class Seq2SeqEncoder(nn.Layer):
def __init__(self, vocab_size, embed_dim, hidden_size, num_layers):
super(Seq2SeqEncoder, self).__init__()
self.embedder = nn.Embedding(vocab_size, embed_dim) # 完成查表,得到字词的向量
self.lstm = nn.LSTM( # 把数据输入LSTM得到句子的语义表示
input_size=embed_dim,
hidden_size=hidden_size,
num_layers=num_layers,
dropout=0.2 if num_layers > 1 else 0.)
def forward(self, sequence, sequence_length):
inputs = self.embedder(sequence)
encoder_output, encoder_state = self.lstm(
inputs, sequence_length=sequence_length)
# encoder_output [128, 18, 256] [batch_size,time_steps,hidden_size]
# encoder_state (tuple) - 最终状态,一个包含h和c的元组。 [2, 128, 256] [2, 128, 256] [num_lauers * num_directions, batch_size, hidden_size]
return encoder_output, encoder_state
定义AttentionLayer

定义Seq2SeqDecoderCell

构建主网络Seq2SeqAttnModel
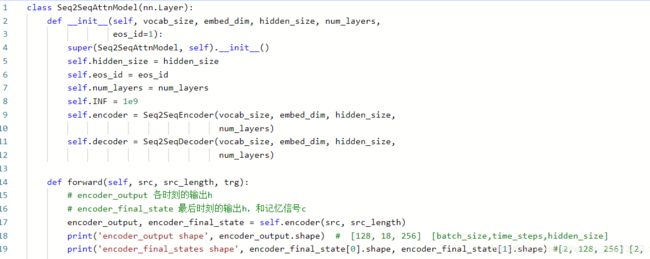
总结

课程已经结束人已经懵了,继续学习吧!
这里是三岁,飞桨社区最菜的小白
我在AI Studio上获得黄金等级,点亮7个徽章,来互关呀~
CSDN首页
如果喜欢记得关注呦!!!