百度飞桨领航团零基础python(2)
一,字符串进阶
学习地址:https://aistudio.baidu.com/aistudio/course/introduce/7073
1,索引
方法 : 字符串变量名[下标]
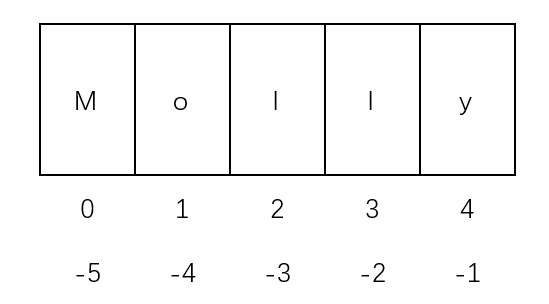
示例代码
name = 'molly'
name[1]
运行结果 ‘o’
2,切片
切片的语法:[起始:结束:步长]
字符串[start: end: step]
这三个参数都有默认值,默认截取方向是从左往右的
start:默认值为0; end : 默认值未字符串结尾元素; step : 默认值为1;
如果切片步长是负值,截取方向则是从右往左的
左开右闭
示例代码(1)
name[1:4]
运行结果 ‘oll’
示例代码(2)
name[::-1]
运行结果 ‘yllom’
3,字符串常用函数
(1)count 计数功能
显示自定字符在字符串当中的个数
示例代码(1)
my_string = 'hello_world'
my_string.count('o') #对应字符个数
运行结果 2
示例代码(2)
article = 'Disney and Marvel’s upcoming superhero epic should light the box office on fire when it launches this weekend, with the hopes of setting domestic, international, and global records. In North America alone, “Avengers: Endgame” is expected to earn between $250 million and $268 million in its first three days of release. If it hits the higher part of that range it would qualify as the biggest domestic debut of all time, a distinction currently held by 2018’s “Avengers: Infinity War,” the precursor to “Endgame,” which launched with $257.7 million.'
article.count('and')#对应字符串的个数
运行结果
3
(2)find 查找功能
返回从左第一个指定字符的索引,找不到返回-1
index 查找
返回从左第一个指定字符的索引,找不到报错
示例代码
my_string = 'hello_world'
my_string.find('o')#如果是字符串返回首字符的下标
运行结果 4 (第一次出现的下标)
示例代码
my_string = 'hello_world'
my_string.index('o')
运行结果 4 (同上)
示例代码
my_string = 'hello_world'
my_string.startswith('hello') # 是否以hello开始
my_string.endswith('world') # 是否以world结尾
运行结果 True True
(4)split 字符串的拆分
按照指定的内容进行分割
示例代码
my_string = 'hello_world'
my_string.split('_')
运行结果 [‘hello’, ‘world’]
(5)字符串的替换
从左到右替换指定的元素,可以指定替换的个数(第三个参数),默认全部替换
示例代码
my_string = 'hello_world'
my_string.replace('_',' ')
运行结果 ‘hello world’
(6)字符串标准化
默认去除两边的空格、换行符之类的,去除内容可以指定
示例代码
my_string = ' hello world\n'
my_string.strip()
运行结果 ‘hello world’
4,字符串的格式化输出
(1)%

示例代码
name = 'Molly'
hight = 170.4
score_math = 95
score_english = 89
print('大家好!我叫%s,我的身高是%d cm, 数学成绩%.2f分,英语成绩%d分' % (name, hight, score_math, score_english))
运行结果 大家好!我叫Molly,我的身高是170 cm, 数学成绩95.00分,英语成绩89分
(2)format
指定了:s ,则只能传字符串值,如果传其他类型值不会自动转换
当你不指定类型时,你传任何类型都能成功,如无特殊必要,可以不用指定类型
示例代码
print('大家好!我叫{},我的身高是{:d} cm, 数学成绩{:.2f}分,英语成绩{}分'.format(name, int(hight), score_math, score_english))
运行结果 大家好!我叫Molly,我的身高是170 cm, 数学成绩95.00分,英语成绩89分
示例代码(位置参数)
'Hello, {0}, 成绩提升了{2:.1f}分,百分比为 {2:.1f}%'\
.format('小明', 17.523, 6)
输出结果 ‘Hello, 小明, 成绩提升了6.0分,百分比为 17.5%’
(3)f-string(python 3.6+)
示例代码
name = 'Molly'
hight = 170.4
score_math = 95
score_english = 89
print(f"大家好!我叫{name},我的身高是{hight:.3f} cm, 数学成绩{score_math}分,英语成绩{score_english}分")
运行结果 大家好!我叫Molly,我的身高是170.400 cm, 数学成绩95分,英语成绩89分
二,list进阶
1,索引和切片(同字符串)
2,常用函数
(1)添加元素
示例代码
list1 = ['a','b','c','d','e','f']
list1.append('g') # 在末尾添加元素
print(list1)
list1.insert(2, 'ooo') # 在指定位置添加元素,如果指定的下标不存在,那么就是在末尾添加
print(list1)
list2 = ['z','y','x']
list1.extend(list2) #合并两个list list2中仍有元素
print(list1)
print(list2)
运行结果
[‘a’, ‘b’, ‘c’, ‘d’, ‘e’, ‘f’, ‘g’]
[‘a’, ‘b’, ‘ooo’, ‘c’, ‘d’, ‘e’, ‘f’, ‘g’]
[‘a’, ‘b’, ‘ooo’, ‘c’, ‘d’, ‘e’, ‘f’, ‘g’, ‘z’, ‘y’, ‘x’]
[‘z’, ‘y’, ‘x’]
(2)count 和 index (同字符串)
(3)删除元素
list1 = ['a','b','a','d','a','f']
print(list1.pop(3))
print(list1)
list1.remove('a')#删除第一次出现的
print(list1)
3,列表生成式
list_1 = [1,2,3,4,5]
[n+1 for n in list_1]
运行结果 [2, 3, 4, 5, 6]
三,生成器(不可以索引)
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
个人感觉像c语言的共用体,只开辟一个空间,后面的值覆盖前面的。
# 第一种方法:类似列表生成式
L = [x * x for x in range(10)] #生成列表
g = (x * x for x in range(10)) #生成器
next(g)#逐一输出
# 第二种方法:基于函数
def factor(max_num):
# 这是一个函数 用于输出所有小于max_num的质数
factor_list = []
n = 2
while n<max_num:
find = False
for f in factor_list:
# 先看看列表里面有没有能整除它的
if n % f == 0:
find = True
break
if not find:
factor_list.append(n)
yield n
#yield 与return相似,但不会结束运行,再次调用时从yield开始运行
n+=1
g = factor(10)
for n in g:
print(n)
运行结果 2 3 5 7