Hadoop系列之(二)JDK和Hadoop安装配置
1.JDK安装配置
之前在有篇博客是搭建apache tomcat + nutch + solr的已经讲过jdk的详细搭建,此次在这里采用第一种搭建方式,即在/etc/profile里进行环境变量的配置。
1).JDK解压安装
我所有的软件包,全部在mac上通过terminal下的scp发送到master上了,全部放在/usr/local/src下,如下图: 切换到
切换到root用户,在/usr下创建java目录,将jdk包拷贝到java目录下,解压
mkdir /usr/java
cp /usr/local/src/jdk-8u111-linux-x64.tar.gz /usr/java #将jdk包拷贝到java目录下
tar zxvf jdk-8u111-linux-x64.tar.gz #解压jdk包
rm jdk-8u111-linux-x64.tar.gz #解压完成后,将其删除
ll #查看解压后的jdk包
即可看到如下目录

接下来为在profile中设置环境变量
2).profile配置
打开/etc/profile文件,在文件最后加入如下代码:
vi /etc/profile
#set java environment
export JAVA_HOME=/usr/java/jdk1.8.0_111
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
如图: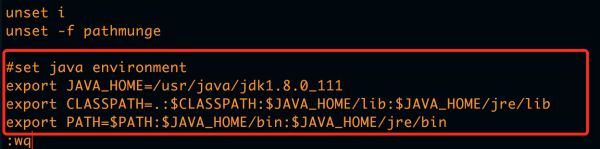
添加完成后保存退出:wq,然后source /etc/profile 让配置生效
查看jdk是否配置成功
java -version
显示如下,表示配置成功
2.Hadoop安装配置
1).Hadoop解压安装
将/usr/local/src/hadoop-2.7.1.tar.gz拷贝到/usr下并将其解压,并将其分配给hadoop用户读的权限,需用root用户登录
cp /usr/local/src/hadoop-2.7.1.tar.gz /usr
tar zxvf hadoop-2.7.1.tar.gz
mv hadoop-2.7.1.tar.gz hadoop
rm hadoop-2.7.1.tar.gz
chown -R hadoop:hadoop hadoop/
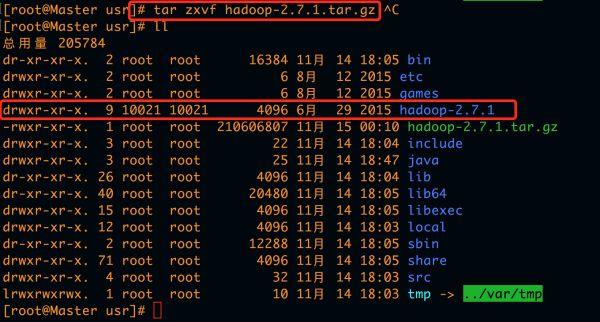

2).Hadoop配置
Hadoop 所有的配置文件全部在/usr/hadoop/etc/hadoop下,进行相应的配置时可用vi编辑器进行打开配置。其中主要配置其中的5歌文件,如下所示:

(1).第一步,hadoop-env.sh配置
在24行
# The java implementation to use.
# export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/java/jdk1.8.0_111
如下所示: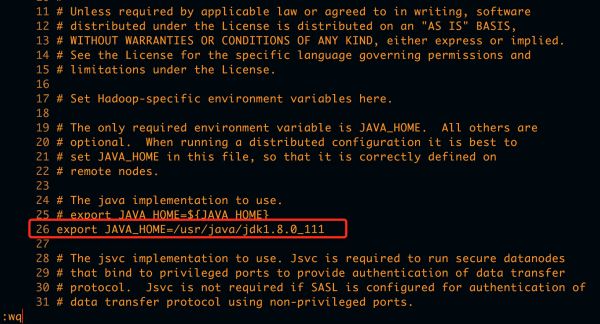
(2).第二步,core-site.xml配置
fs.defaultFS
hdfs://Master.Hadoop:9000
hadoop.tmp.dir
file:/home/hadoop/hadoop-2.7.1/tmp
io.file.buffer.size
131702
如图所示:
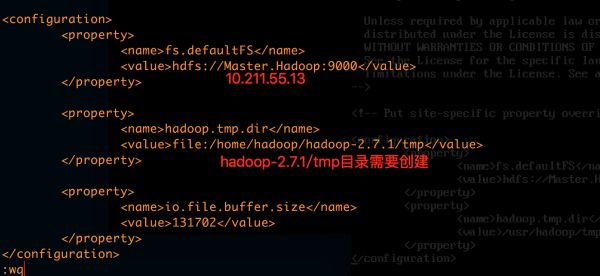
(3).第三步,hdfs-site.xml配置
dfs.namenode.name.dir
/home/hadoop/hadoop-2.7.1/hdfs/name
dfs.namenode.data.dir
/home/hadoop/hadoop-2.7.1/hdfs/data
dfs.replication
2
dfs.namenode.secondary.http-address
Master.Hadoop:9001
dfs.webhdfs.enabled
true
dfs.permissions
false
如图所示:
(4).第四步,mapred-site.xml配置
需要将mapred-site.xml.template重命名为mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
Master.Hadoop:10020
mapreduce.jobhistory.webapp.address
Master.Hadoop:19888
如图所示:
(5).第五步,yarn-site.xml配置
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.auxservices.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
Master.Hadoop:8032
yarn.resourcemanager.scheduler.address
Master.Hadoop:8030
yarn.resourcemanager.resource-tracker.address
Master.Hadoop:8031
yarn.resourcemanager.admin.address
Master.Hadoop:8033
yarn.resourcemanager.webapp.address
Master.Hadoop:8088
yarn.nodemanager.resource.memory-mb
2048
如图所示: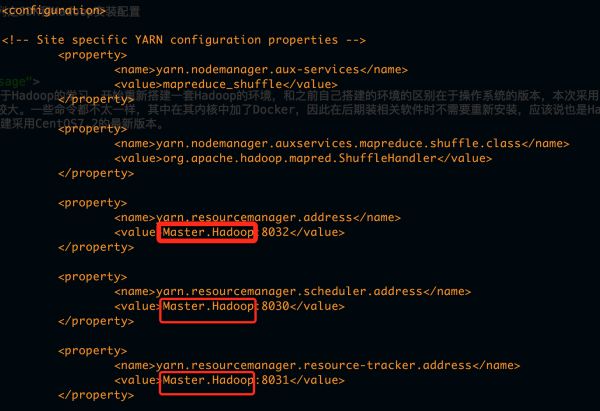

(6).第六步,slaves配置
Slave1.Hadoop
Slave2.Hadoop
如图所示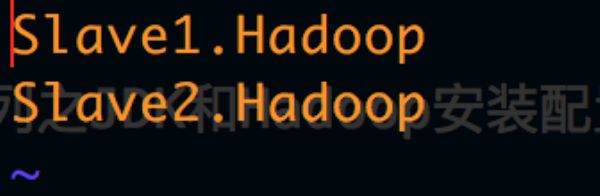 注意:slaves 文件只是在Master节点上有用,其他Slave节点没用,但复制过去时带着也无妨。
注意:slaves 文件只是在Master节点上有用,其他Slave节点没用,但复制过去时带着也无妨。
(7).第七步,profile配置Hadoop命令(可省)
#set hadoop enviroment
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
如图所示: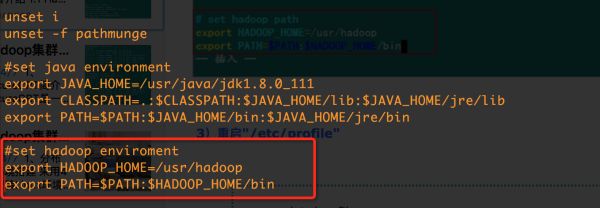
3).发送给所有slave节点并进行配置
先将Master配置好的各项文件发给所有的Slave,然后再单独对Slave的相关文件进行设置。
1.将Master的hosts文件发给Slave
scp /etc/hosts [email protected]:/etc/
scp /etc/hosts [email protected]:/etc/
2.将Master的JDK发给Slave
scp -r /usr/java/ [email protected]:/usr/
scp -r /usr/java/ [email protected]:/usr/
3.将Master的hadoop发送给Slave
scp -r /usr/hadoop/ [email protected]:/usr/
scp -r /usr/hadoop/ [email protected]:/usr/
4.将Master的profile发送给Slave
scp /etc/profile [email protected]:/etc/
scp /etc/profile [email protected]:/etc/
5.将Master创建的hadoop-2.7.1目录发送到Slave
scp -r hadoop-2.7.1/ [email protected]:~/
6.登录所有的Slave进行配置,让profile生效,给hadoop文件增加hadoop用户读的权限。
source /etc/profile
su & cd /usr
chown -R hadoop:hadoop hadoop/
至此,所有的安装配置工作完成,接下来要进行验证是否配置成功。
4).启动验证
(1).格式化HDFS文件系统
在”Master.Hadoop”上使用普通用户hadoop进行操作。(备注:只需一次,下次启动不再需要格式化,只需 start-all.sh)
hadoop namenode -format
如图所示表示格式化成功:


(2).启动Hadoop
进入到cd /usr/hadoop/sbin目录下
./start-all.sh
可以通过以下启动日志看出,首先启动namenode 接着启动datanode1,datanode2,…,然后启动secondarynamenode。再启动yarn,resourcemanager,nodemanager.
启动 hadoop成功后,在 Master 中的 tmp 文件夹中生成了 dfs 文件夹,在Slave 中的 tmp 文件夹中均生成了 dfs 文件夹和 nm-local-dir 文件夹。
(3).验证Hadoop
通过jps查看进程 Master上查看:
jps
含有:
8515 SecondaryNameNode
8325 NameNode
9448 Jps
8667 ResourceManager
进程,如图所示,表示master运行成功。
Slave上查看: 含有:
12338 Jps
11884 NodeManager
11775 DataNode
进程,如图所示,表示slave上运行成功。

还可使用
[hadoop@Master hadoop]$ hadoop dfsadmin -report
来查看hadoop集群状态。
回到mac上打开chrome浏览器,输入10.211.55.13:8088 10.211.55.13:50070 可查看相关网页版状态。

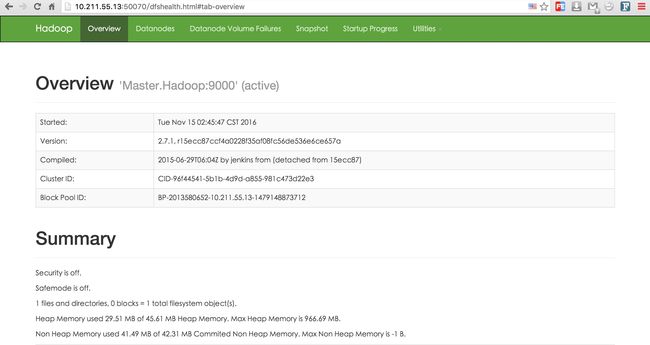
至此,hadoop配置完成,下一步配置Zookeeper+Hbase+Hive.
#看在我辛苦截图敲代码的份上,喜欢的话打赏一下吧,哈哈。

转个人博客:http://ferdbi.com/%E5%A4%A7%E6%95%B0%E6%8D%AE/2016/11/15/Hadoop%E7%B3%BB%E5%88%97%E4%B9%8BJDK%E5%92%8CHadoop%E5%AE%89%E8%A3%85%E9%85%8D%E7%BD%AE.html