数字图像处理之高斯滤波加速优化
在上一篇文章中,我们讲了高斯滤波以及分离高斯滤波的原理与C++实现。本文将在此基础上,分别详细讲解使用SSE指令和CUDA来对分离高斯滤波算法的优化加速。
一、SSE指令优化
我们知道,SSE指令优化的核心思路是在一条CPU指令内同时对4个浮点数进行相同的运算。所以可以使用SSE指令优化来加速计算加权和,每次循环计算窗口内同一行的8个像素点的加权和。显而易见,这就要求窗口的列数不能小于8,如果列数小于8则不适用SSE指令优化,不过,当窗口列数小于8时,窗口尺寸是相当小的,按正常那样每次循环计算一个像素点的像素值与权重的乘积,然后将乘积累加即可。
对于所取窗口的某一行,使用SSE指令加速计算的示意图所下图所示。对于像素窗口与权重矩阵,均每一次取同一行的8个值,并将其分成两组,每组的4个点构成一个SSE指令的__m128数据变量,然后使用SSE指令对__m128变量进行加权和运算。

结合上图,SSE指令计算过程主要分为以下几步:
1. 加载数据到__m128变量中:
X0变量:x3, x2, x1, x0
X1变量:x7, x6, x5, x4
K0变量:k3, k2, k1, k0
K1变量:k7, k6, k5, k4
2. SSE指令计算:
M0=X0*K0 --> x3*k3, x2*k2, x1*k1, x0*k0
M1=X1*K1 --> x7*k7, x6*k6, x5*k5, x4*k4
M=M0+M1 --> x3*k3+x7*k7, x2*k2+x6*k6, x1*k1+x5*k5, x0*k0+x4*k4
3. 使用SSE指令将变量M累加到另一个__m128变量中:
s=s+M
4. 循环结束之后,将变量s中的4个浮点数相加,就是最后的加权和:
sum=s[0]+s[1]+s[2]+s[3]
话不多说,下面直接上代码:
void gaussian_fiter_XY_SSE(Mat src, Mat &dst)
{
Mat src_board;
copyMakeBorder(src, src_board, Gaussian_Size_2, Gaussian_Size_2, Gaussian_Size_2, Gaussian_Size_2, BORDER_REFLECT); //扩充边缘
Mat dstx = Mat::zeros(src_board.size(), CV_32FC1);
dst = Mat::zeros(src.size(), CV_8UC1);
if (Gaussian_Size < 8) //如果窗口列数小于8则不适用SSE优化,正常计算即可
{
for (int i = 0; i < src_board.rows; i++) //x方向一维卷积
{
for (int j = Gaussian_Size_2; j < src_board.cols - Gaussian_Size_2; j++)
{
float sum = 0.0;
for (int x = 0; x < Gaussian_Size; x++)
{
sum += src_board.ptr(i)[j - Gaussian_Size_2 + x] * Gaussian_Ker_XY[x];
}
dstx.ptr(i)[j] = sum;
}
}
for (int i = Gaussian_Size_2; i < src_board.rows - Gaussian_Size_2; i++) //y方向一维卷积
{
for (int j = Gaussian_Size_2; j < src_board.cols - Gaussian_Size_2; j++)
{
float sum = 0.0;
for (int y = 0; y < Gaussian_Size; y++)
{
sum += dstx.ptr(i - Gaussian_Size_2 + y)[j] * Gaussian_Ker_XY[y];
}
dst.ptr(i - Gaussian_Size_2)[j - Gaussian_Size_2] = (uchar)sum;
}
}
}
else
{
for (int i = 0; i < src_board.rows; i++) //x方向一维卷积
{
for (int j = Gaussian_Size_2; j < src_board.cols - Gaussian_Size_2; j++)
{
float sum = 0.0;
__m128 m_sum = _mm_setzero_ps(); //累加变量
uchar *p = src_board.ptr(i);
int x = 0;
for (; x < Gaussian_Size-8; x+=8)
{
int idx = j - Gaussian_Size_2 + x;
//加载变量X0
__m128 m_src_L = _mm_set_ps(p[idx+3], p[idx+2], p[idx+1], p[idx]);
//加载变量X1
__m128 m_src_H = _mm_set_ps(p[idx+7], p[idx+6], p[idx+5], p[idx+4]);
//加载变量K0
__m128 g_L = _mm_loadu_ps(&Gaussian_Ker_XY[x]);
//加载变量K1
__m128 g_H = _mm_loadu_ps(&Gaussian_Ker_XY[x+4]);
__m128 dx_L = _mm_mul_ps(m_src_L, g_L); //计算M0=X0*K0
__m128 dx_H = _mm_mul_ps(m_src_H, g_H); //计算M1=X1*K1
//计算s = s + M = s + (M0 + M1)
m_sum = _mm_add_ps(m_sum, _mm_add_ps(dx_L, dx_H));
}
float *q = (float *)&m_sum;
//计算sum=s[0]+s[1]+s[2]+s[3]
sum = (q[0] + q[1]) + (q[2] + q[3]);
for (; x < Gaussian_Size; x++)
{
sum += src_board.ptr(i)[j - Gaussian_Size_2 + x] * Gaussian_Ker_XY[x];
}
dstx.ptr(i)[j] = sum;
}
}
for (int i = Gaussian_Size_2; i < src_board.rows - Gaussian_Size_2; i++) //y方向一维卷积
{
for (int j = Gaussian_Size_2; j < src_board.cols - Gaussian_Size_2; j++)
{
float sum = 0.0;
__m128 m_sum = _mm_setzero_ps();
int y = 0;
for (; y < Gaussian_Size - 8; y += 8)
{
int idx = i - Gaussian_Size_2 + y;
//列向取值
float *p0 = dstx.ptr(idx);
float *p1 = p0 + dstx.cols;
float *p2 = p1 + dstx.cols;
float *p3 = p2 + dstx.cols;
float *p4 = p3 + dstx.cols;
float *p5 = p4 + dstx.cols;
float *p6 = p5 + dstx.cols;
float *p7 = p6 + dstx.cols;
__m128 m_src_L = _mm_set_ps(p3[j], p2[j], p1[j], p0[j]);
__m128 m_src_H = _mm_set_ps(p7[j], p6[j], p5[j], p4[j]);
__m128 g_L = _mm_loadu_ps(&Gaussian_Ker_XY[y]);
__m128 g_H = _mm_loadu_ps(&Gaussian_Ker_XY[y+4]);
__m128 dy_L = _mm_mul_ps(m_src_L, g_L);
__m128 dy_H = _mm_mul_ps(m_src_H, g_H);
m_sum = _mm_add_ps(m_sum, _mm_add_ps(dy_L, dy_H));
}
float *q = (float *)&m_sum;
sum = (q[0] + q[1]) + (q[2] + q[3]);
for (; y < Gaussian_Size; y++)
{
sum += dstx.ptr(i - Gaussian_Size_2 + y)[j] * Gaussian_Ker_XY[y];
}
dst.ptr(i - Gaussian_Size_2)[j - Gaussian_Size_2] = (uchar)sum;
}
}
}
}
取59*59窗口,σ=1.0,对496*472的图像进行滤波,上述代码耗时约43.01 ms,而上篇文章中的一维分离滤波代码则耗时约54.74 ms。可以看到,耗时有所减少,不过减少的并不多。
二、CUDA优化
1. GPU与CUDA简介
GPU的概念最早由NVIDIA公司提出。GPU即图形处理器,又称为显示芯片,是一种专门用于图像数据处理的微处理器。随着GPU的发展和增强,GPU通用计算技术逐渐引起业界关注并得到广泛应用,GPU在并行计算和浮点运算等计算任务上,可提供优于CPU十倍甚至上百倍的性能。
CUDA是NVIDIA公司在2007年推出的并行编程模型和计算平台,它利用GPU强大计算能力实现复杂数据的并行运算,从而显著提高计算性能和计算效率。可以把CUDA看作是对GPU硬件计算功能进行封装的程序库,该程序库包含GPU内部的并行计算引擎和CUDA的指令集架构,开发人员通过调用CUDA程序库中的API接口,可以方便地在CPU和GPU之间互相传输数据,并控制GPU底层硬件进行并行运算。
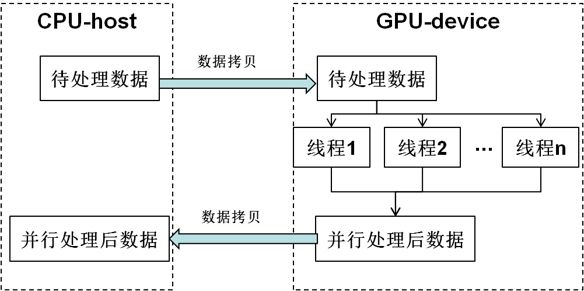
CUDA提供host-device编程模式,即CPU作为host,GPU作为device,通常是先把数据从host拷贝到device,在device利用多线程并行处理数据,等待所有线程处理完毕,再把处理后的数据从device拷贝回host中,一个典型的CUDA计算任务流程如下图所示。
2. 线程模型简介
假如图像有row*col个像素点,窗口尺寸为(2n+1)*(2n+1),对于每一个像素点都要计算其邻域窗口的像素加权和,那么总共需要计算row*col个邻域窗口的像素加权和,所以我们的并行优化思路为:对于行方向加权和与列方向加权和,都开启row*col个线程,每个线程对应一个像素点,其负责计算该点的邻域窗口像素加权和,且所有线程并行计算。如下图所示:

CUDA的线程模型如下图所示。Host启动内核(kernel)在device上执行,1个内核执行时启动的所有线程组成一个线程网格(grid),一个网格包含多个线程块(block),然后每个线程块又包含多个线程。

由于每一个线程块包含的最大线程数是有限的(根据NVIDIA显卡型号不一样,常见的限制有512个和1024个),编程时需要分配多个线程块,然后每个线程块分配多个线程才能满足总线程数要求。对于二维图像,需要对像素点的x坐标和y坐标分别通过线程块号与线程号进行索引寻址,因此适合把线程块和线程都设置成二维坐标索引,假设一个线程块的索引为(blockIdx_x,blockIdx_y),该线程块中一个线程的索引为(threadIdx_x,threadIdx_y),且在线程网格中线程块在x方向和y方向的维度分别为blockDim_x和blockDim_y,那么该线程对应图像中的点坐标(x, y)计算如下式:

3. 纹理内存简介
纹理内存是GPU中的一种只读存储器,其使用方式为将某一段全局内存绑定到纹理内存,这段全局内存通常的表现形式为一维、二维或三维CUDA数组,然后通过读取纹理内存(也称为纹理拾取)来获取全局内存的数据。纹理内存专门为图像纹理渲染而设计,对非对齐访问和随机访问具有良好的加速效果,然而全局内存的访问在GPU的所有存储类型中是最慢的。
对于每一个线程,计算加权和时对图像数据与权重的访问均为2n+1次,访问率还是比较频繁的,如果把图像数据和权重都存储在全局内存中并直接访问全局内存,会明显增加计算耗时。因此可以把存储图像数据和权重的GPU全局内存绑定到纹理内存,然后通过纹理拾取来读取,可进一步减少时间开销,如下图所示。

4. 代码实现
计算一维权重代码:
#define GAUSS_KSIZE 59
#define GAUSS_KSIZE_2 (GAUSS_KSIZE>>1)
float gauss_XY_ker[GAUSS_KSIZE];
void getGaussianArray_CUDA(float sigma) //计算高斯滤波的卷积核
{
float sum = 0.0f;
const float sigma_2 = sigma*sigma;
const float a = 1.0 / (2 * 3.14159*sigma_2);
for (int i = 0; i < GAUSS_KSIZE; i++)
{
float dx = i - GAUSS_KSIZE_2;
gauss_XY_ker[i] = a*exp(-dx*dx / (2.0*sigma_2));
sum += gauss_XY_ker[i];
}
sum = 1.0 / sum;
for (int i = 0; i < GAUSS_KSIZE; i++)
{
gauss_XY_ker[i] *= sum;
}
}
行方向一维加权和的核函数:
__global__ void gaussian_filterX(float *dst, int row, int col)
{
int x = blockIdx.x * blockDim.x + threadIdx.x; //col
int y = blockIdx.y * blockDim.y + threadIdx.y; //row
if (x < col && y < row)
{
int index = y*col + x;
float sum = 0.0;
if (x >= GAUSS_KSIZE_2 && x < col - GAUSS_KSIZE_2 && y >= GAUSS_KSIZE_2 && y < row - GAUSS_KSIZE_2)
{
int x_g = x - GAUSS_KSIZE_2;
for (int l = 0; l < GAUSS_KSIZE; l++)
{
sum += tex2D(tex_src, (float)(x_g + l), (float)y) * tex1Dfetch(tex_ker, l);
}
}
else
{
sum = (float)tex2D(tex_src, (float)x, (float)y);
}
dst[index] = sum;
}
}
列方向一维加权和的核函数:
__global__ void gaussian_filterY(uchar *dst, int row, int col)
{
int x = blockIdx.x * blockDim.x + threadIdx.x; //col
int y = blockIdx.y * blockDim.y + threadIdx.y; //row
if (x < col && y < row)
{
int index = y*col + x;
float sum = 0.0;
if (x >= GAUSS_KSIZE_2 && x < col - GAUSS_KSIZE_2 && y >= GAUSS_KSIZE_2 && y < row - GAUSS_KSIZE_2)
{
int y_g = y - GAUSS_KSIZE_2;
for (int l = 0; l < GAUSS_KSIZE; l++)
{
sum += tex2D(tex_dstx, (float)x, (float)(y_g + l)) * tex1Dfetch(tex_ker, l);
}
}
else
{
sum = tex2D(tex_dstx, (float)x, (float)y);
}
dst[index] = (uchar)sum;
}
}
主体函数:
void gaussian_fiter_cuda(Mat src, Mat &dst)
{
Mat src_board;
//边缘扩展
copyMakeBorder(src, src_board, GAUSS_KSIZE_2, GAUSS_KSIZE_2, GAUSS_KSIZE_2, GAUSS_KSIZE_2, BORDER_REFLECT); //扩充边缘
dst = Mat::zeros(src.size(), CV_8UC1);
const int row = src_board.rows;
const int col = src_board.cols;
const int img_size_float = row*col*sizeof(float);
//
float *dstx_cuda;
uchar *dst_cuda;
float *ker_cuda;
//申请全局内存
cudaMalloc((void**)&dstx_cuda, img_size_float);
cudaMalloc((void**)&dst_cuda, row*col);
cudaMalloc((void**)&ker_cuda, GAUSS_KSIZE*sizeof(float));
//将权重拷贝到全局内存
cudaMemcpy(ker_cuda, gauss_XY_ker, GAUSS_KSIZE*sizeof(float), cudaMemcpyHostToDevice);
//
//将存储权重的全局内存绑定到纹理内存
cudaBindTexture(0, tex_ker, ker_cuda); //绑定一维纹理
//
cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc();//声明数据类型
cudaArray *cuArray_src;
cudaMallocArray(&cuArray_src, &channelDesc, col, row); //分配大小为col*row的CUDA数组
//将图像数据拷贝到CUDA数组
cudaMemcpyToArray(cuArray_src, 0, 0, src_board.data, row*col, cudaMemcpyHostToDevice);
tex_src.addressMode[0] = cudaAddressModeWrap;//寻址方式
tex_src.addressMode[1] = cudaAddressModeWrap;//寻址方式 如果是三维数组则设置texRef.addressMode[2]
tex_src.normalized = false;//是否对纹理坐标归一化
tex_src.filterMode = cudaFilterModePoint;//纹理的滤波模式:最近点取样和线性滤波 cudaFilterModeLinear
cudaBindTextureToArray(&tex_src, cuArray_src, &channelDesc); //纹理绑定,CUDA数组和纹理参考的连接
//
cudaChannelFormatDesc channelDesc1 = cudaCreateChannelDesc();//声明数据类型
cudaArray *cuArray_dstx;
cudaMallocArray(&cuArray_dstx, &channelDesc1, col, row); //分配大小为col*row的CUDA数组
tex_dstx.addressMode[0] = cudaAddressModeWrap;//寻址方式
tex_dstx.addressMode[1] = cudaAddressModeWrap;//寻址方式 如果是三维数组则设置texRef.addressMode[2]
tex_dstx.normalized = false;//是否对纹理坐标归一化
tex_dstx.filterMode = cudaFilterModePoint;//纹理的滤波模式:最近点取样和线性滤波 cudaFilterModeLinear
cudaBindTextureToArray(&tex_dstx, cuArray_dstx, &channelDesc1); //纹理绑定,CUDA数组和纹理参考的连接
//
dim3 Block_G(16, 16);
dim3 Grid_G((col + 15) / 16, (row + 15) / 16);
//调用行方向加权和kernel函数
gaussian_filterX<<>>(dstx_cuda, row, col);
//将行方向加权和的结果拷贝到全局内存
cudaMemcpyToArray(cuArray_dstx, 0, 0, dstx_cuda, img_size_float, cudaMemcpyDeviceToDevice);
//调用列方向加权和kernel函数
gaussian_filterY<<>>(dst_cuda, row, col);
//
//将滤波结果从GPU拷贝到CPU
cudaMemcpy(src_board.data, dst_cuda, row*col, cudaMemcpyDeviceToHost);
src_board(Rect(GAUSS_KSIZE_2, GAUSS_KSIZE_2, src.cols, src.rows)).copyTo(dst);
//
cudaFree(dstx_cuda); //释放全局内存
cudaFree(dst_cuda);
cudaFree(ker_cuda);
cudaFreeArray(cuArray_src); //释放CUDA数组
cudaFreeArray(cuArray_dstx);
cudaUnbindTexture(tex_src); //解绑全局内存
cudaUnbindTexture(tex_dstx);
cudaUnbindTexture(tex_ker);
}
同样取59*59窗口,σ=1.0,对496*472的图像进行滤波,运行上述代码耗时约1.66 ms,可以看到,耗时相对于SSE优化的43.01 ms大大减小,因此使用CUDA并行加速的效果还是非常明显的。