pytorch tensorboard_小白学PyTorch | 14 tensorboardX可视化教程
公众号关注 “Python遇见机器学习”
设为“星标”,第一时间知晓最新干货~
 来源:机器学习炼丹术
来源:机器学习炼丹术
参考目录:
1 安装
2 标量可视化
3 权重直方图
4 特征图可视化
5 模型图的可视化
6 卷积核的可视化
本章节来初次使用tensorboard来可视化pytorch深度学习中的一些内容,主要可视化的内容包括:标量变化(模型损失、准确率等);权重值的直方图;特征图的可视化;模型图的可视化;卷积核的可视化。
其实tensorboard一开始是给tensorflow使用的可视化工具,PyTorch框架自己的可视化工具是Visdom,但是这个API需要设置的参数过于复杂,而且功能不太方便也不强大,所以有人写了一个库函数TensorboardX来让PyTorch也可以使用tensorboard。
1 安装
安装非常的简单,直接需要安装tensorboardX,tensorboard和tensorflow三个库函数:
# 控制台运行
pip install tensorboardX
pip install tensorboard
pip install tensorflow
这时候我们就已经安装完成了。
2 标量可视化
这里我是用的是第8课的MNIST作为基本代码,然后在其中增加可视化的功能。
先导入库函数
# 导入可视化模块
from tensorboardX import SummaryWriter
writer = SummaryWriter('../result_tensorboard')
这里面的writer就是我们要记录的一个写入tensorboard的一个接口。这个../result_tensorboard就是数据保存的具体位置。
for batch_idx, (data, target) in enumerate(train_loader):
#...省略一些代码...
if (batch_idx + 1) % 50 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
100. * (batch_idx + 1) / len(train_loader), loss.item()))
writer.add_scalar('loss',loss.item(),tensorboard_ind)
tensorboard_ind += 1
关键就是writer.add_scalar(),其中有三个关键的参数:
def add_scalar(self, tag, scalar_value, global_step):
- tag就是一个字符串吧,在上面的代码中,我是每50个batch记录一次loss的值,所以这个tag就是'loss':
- scalar_value就是这一次记录的标量了,上面记录的就是
loss.item()。这个loss的变化应该会输出一个折线图的吧,这个scalar_value就是y轴的值; - global_step其实就是折线图的x轴的值,所以我每记录一个点就把
tensorboard_ind加一。
运行上面的代码,会生成这样的一个文件: 这个
这个events.out.巴拉巴拉这个文件就是代码中保存的标量,我们需要在控制台启动tensorboard来可视化:
tensorboard --logdir==D:\Kaggle\result_tensorboard
这个--logdir=后面跟上之前writer定义的时候的那个地址,也就是../result_tensorboard,然后运行。
运行结果为: 点击上图中的蓝色字体,会弹出一个网页,这个网页就是tensorboald的可视化面板。
点击上图中的蓝色字体,会弹出一个网页,这个网页就是tensorboald的可视化面板。
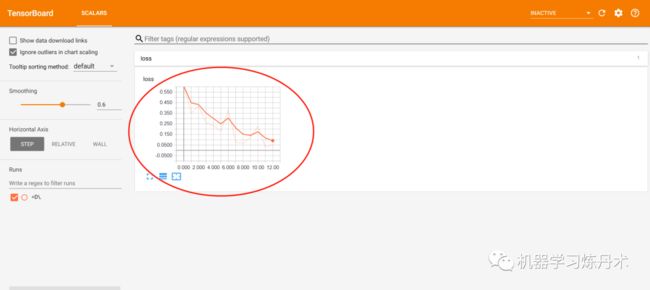
从图中可以看到一个标量的折线图,就是我们的loss。
3 权重直方图
增加部分代码,目的是在每一个epoch训练完成之后,记录一次模型每一层的参数直方图。
n_epochs = 5
for epoch in range(n_epochs):
train(epoch,epoch * len(train_loader))
# 每一个epoch之后输出网络中每一层的权重值的直方图
for i, (name, param) in enumerate(model.named_parameters()):
if 'bn' not in name:
writer.add_histogram(name, param, epoch)
运行结束之后依然是一个名字很长的数据文件,我们在tensorboard中运行这个文件,展示出直方图变化,上面的代码是记录了一个网络中所有层的权重值直方图,在具体任务中,可以只需要输出某一些层的权重直方图即可。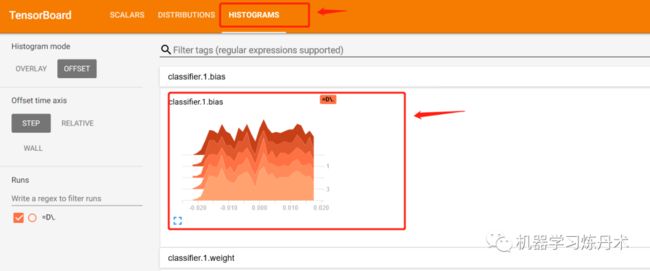
4 特征图可视化
在代码中的train函数内,增加了这样一段代码:
# 第一个batch记录数据
if batch_idx == 0:
out1 = model.features1(data[0:1,:,:,:])
out2 = model.features(out1)
grid1 = make_grid(out1.view(-1,1,out1.shape[2],out1.shape[3]), nrow=8)
grid2 = make_grid(out2.view(-1,1,out1.shape[2],out1.shape[3]), nrow=8)
writer.add_image('features1', grid1, global_step=epoch)
writer.add_image('features', grid2, global_step=epoch)
就是让第一个batch的第一个样本放到模型中,然后把卷积输出的特征图输出成out1和out2,然后使用torchvision.utils.make_grid函数把特征图变成网格的形式。然后写道writer里面,标签是'features1'和'features'。
运行tensorboard结果:
在features1中可以比较明显的看到32个‘6’的图片,这个是一个样本的特征图的32个通道的展示,上面的那个feature在检查代码之后,虽然看起来是4个图片,但是其实是64个通道,只是每个特征图都很小所以看起来比较模糊和迷惑。这也是因为MNIST数据集中是28尺寸的输入图片,对于Imagenet的大图片一般都蚕蛹224或者448像素的输入,就会好一些。
总之这是特征图的展示。我专门录了一个这个tensorboard的GIF展示。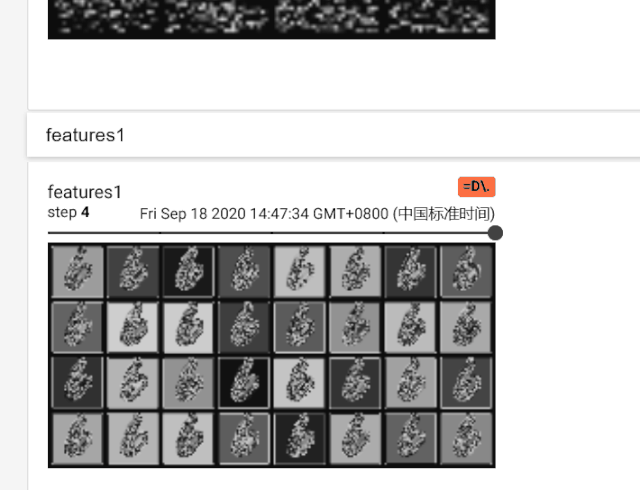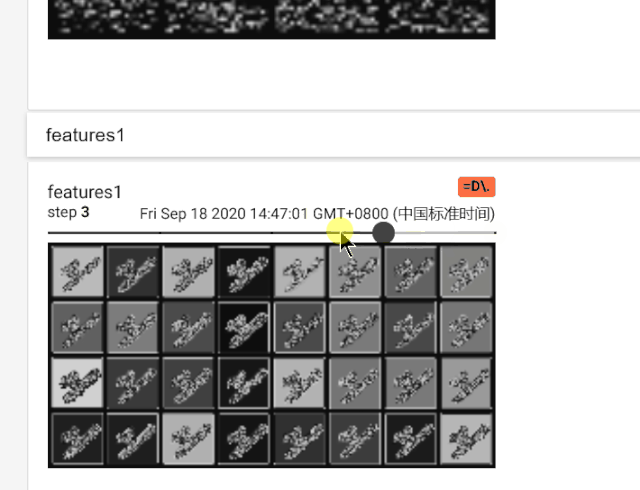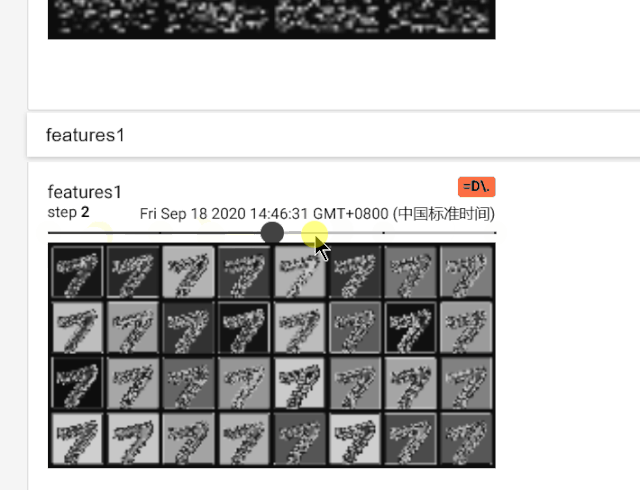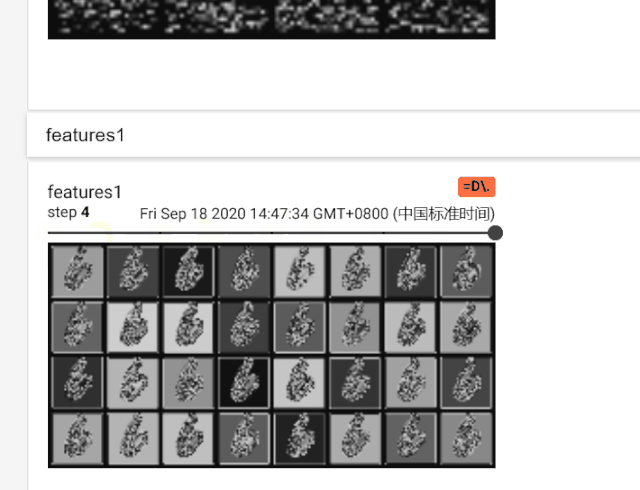
5 模型图的可视化
这个非常的简单:
model = Net().to(device)
writer.add_graph(model, torch.rand([1,3,28,28]))
这里呢有一个问题,就是自己定义的模型结构会显示不出来。目前在网上搜索过但是没有比较好的解决方案,所以这里就不作模型的可视化了。对于部分官方提供的模型是可以可视化的,下面展示的是官方可视化的效果: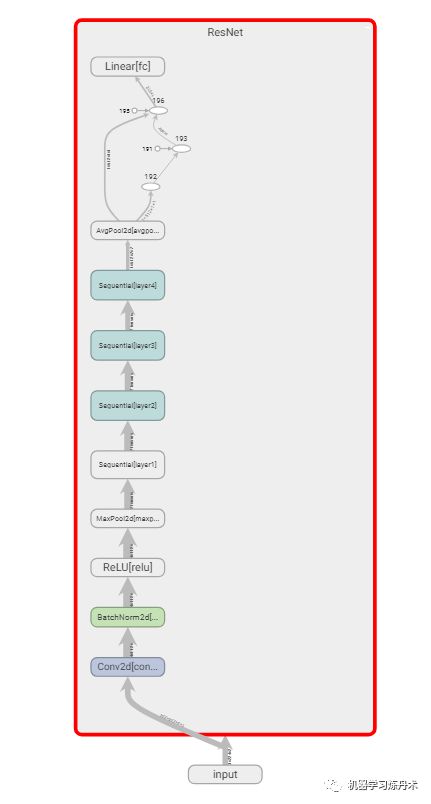
其实个人感觉,这个模型结构可视化的结果也不是非常的好看。而且对于模型可视化的结果还有其他的办法,所以不用tensorboard也罢。tensorboard来可视化loss,特征图等的功能也足够了。
6 卷积核的可视化
# 卷积核的可视化
for idx, (name, m) in enumerate(model.named_modules()):
if name == 'features1':
print(m.weight.shape)
in_channels = m.weight.shape[1]
out_channels = m.weight.shape[0]
k_w,k_h = m.weight.shape[3],m.weight.shape[2]
kernel_all = m.weight.view(-1, 1, k_w, k_h) # 每个通道的卷积核
kernel_grid = make_grid(kernel_all, nrow=in_channels)
writer.add_image(f'{name}_kernel', kernel_grid, global_step=epoch)
这个个也比较好理解,之前的关于卷积的基础知识,模型的遍历都讲过了,所以这里相信大家都没有什么比较难理解的地方了。
运行结果:
重磅!
Python遇见机器学习交流群已成立!
额外赠送福利资源!邱锡鹏深度学习与神经网络,pytorch官方中文教程,利用Python进行数据分析,机器学习学习笔记,pandas官方文档中文版,effective java(中文版)等20项福利资源

获取方式:进入群后点开群公告即可领取下载链接

注意:请大家添加时修改备注为
[学校/公司 + 姓名 + 方向]
例如 —— 哈工大+张三+对话系统。
号主,微商等广告请自觉绕道。谢谢!
推荐阅读
• 超越ReLU却鲜为人知,3年后被挖掘:BERT、GPT-2等都在用的激活函数
• 这5件事情我希望自己能在刚开始学习数据科学的时候就知道
• 5个基本概念,从统计学到机器学习
• GitHub霸榜项目:30万字图解算法题典,超全实用资源,狂揽6000星
• 明确了!导师再也不能让研究生干这种事!
• 这个Chrome上的重磅隐藏功能,Edge浏览器也有了!
• 整理一套pandas详细教程,希望对你有帮助!
• YOLO算法最全综述:从YOLOv1到YOLOv5
• 再见,正则表达式
• GPU必知必会 | 哪款显卡配得上我的炼丹炉
• 5 个pandas神级操作,最后一个长见识了!
• Numpy核心语法和代码整理汇总!
