【Python_005】利用jieba及wordcloud生成词频及词云图
词云图在数据分析中是比较常见的可视化操作,尤其在做定性分析时,通过词云图展示对某件产品或某个现象讨论最热的词,直观又好看
词频
生成词云图之前首先要确定各个词的词频,从而知道每个词的热门程度及后续在词云中不同大小的展示(词频即每个词出现的频率)
如何计算词频呢?
下面就需要介绍一个第三方库:jieba (没错,就是你想的那个结巴。。。
jieba库:做最好的 Python 中文分词组件
Github官方文档
安装jieba
我用的是anaconda,比较方便。
直接打开anaconda promot, 输入 pip install jieba 就可
验证一下是否安装成功:
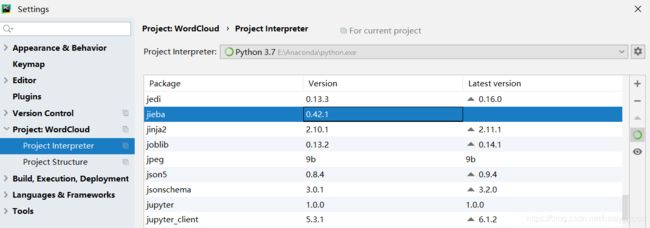
打开pycharm -> File -> Setting -> Project Interpreter
在列表中看到jieba库就说明安装成功了,如图:
jieba 切词
共有三种模式:
- 搜索引擎模式
- 全模式
- 精确模式
个人认为三种模式中精确模式最好用,最适合用来文本分析。
用我大《三体》来举个例子嘎嘎嘎
import jieba
str = '斩尽杀绝,这是对一个文明的最高重视'
'''
精确模式效果在一般情况下 效果最好
jieba.cut() 生成 generator,需要for loop 返回里面的每一个词
jieba.lcut() 生成list
'''
seg_list_search = jieba.cut_for_search(str) # 搜索引擎模式
seg_list1 = jieba.cut(str, cut_all = True) #全模式
seg_list2 = jieba.cut(str, cut_all = False) #精确模式, 默认为精确, cut_all=False 可缺省
print(f'搜索引擎模式效果:{"/".join(seg_list_search)}')
print(f'全模式效果:{"/".join(seg_list1)}')
print(f'精确模式效果:{"/".join(seg_list2)}') #比较适合文本分析
效果:

这三种模式返回的数据类型为generator
在后续统计词频时候不是很方便
jieba.lcut()就可以返回list,

计算词频
在计算词频时,我们引入一个停用词表
对切词后的列表进行遍历,当碰到停用词表中的词时,则跳过。
我爬了豆瓣 神夏1(顺便安利一波真爱剧) 的100条短评,保存在excel中。
100条短评如图:

import jieba
from jieba import analyse
import pandas as pd
import codecs
#载入文本
data_io = 'E:/Python Project/WordCloud/comment.xlsx'
data = pd.read_excel(data_io, header=0, encoding='utf-8',dtype=str)
#载入停用词表
stopwords = [line.strip() for line in codecs.open('E:/Python Project/WordCloud/中文停用词表.txt','r',encoding ='utf-8').readlines()]
#保存全局分词,用于词频统计
segments = []
for index,row in data.iterrows():
content = row['comment']
words = jieba.lcut(content, cut_all=False)
for word in words:
#停用词判断,非停用词才记录
if word not in stopwords:
segments.append({
'word':word, 'count':1})
#将结果数组转为dataframe
seg_df = pd.DataFrame(segments)
#词频统计
word_df = seg_df.groupby('word')['count'].sum()
word_df = word_df.drop([' '])
result = word_df.sort_values(ascending=False)
#导出频率前300的关键词
result[:300].to_excel('E:/Python Project/WordCloud/result.xlsx', encoding='utf-8')
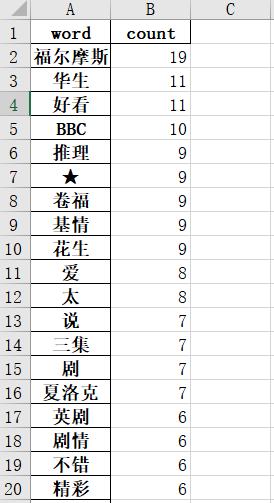
词频保存到excel中效果如下:
词云图
统计完词频,接下来就该画词云了。
使用教程,我参考的是这篇博客:Python词云 wordcloud 十五分钟入门与进阶
from wordcloud import WordCloud
import PIL
import numpy as np
import matplotlib.pyplot as plt
#制作词云图
image_background = PIL.Image.open('E:/Python Project/WordCloud/sherlock.jpg')
MASK = np.array(image_background)
wc = WordCloud(font_path='msyh.ttc',background_color='white', width=4000, height=2000, margin=10, max_words=200, mask =MASK).fit_words(result[0:300]) #mysh.ttc微软雅黑
plt.imshow(wc)
plt.show()
wc.to_file('E:/Python Project/WordCloud/final.png')
背景图:
词云图效果: