word2vec 原理(二)基于 Hierarchical Softmax 的模型
基于 Hierarchical Softmax 的模型
- 1. negative sampling and hierarchical softmax
- 2. CBOW model
-
-
- 2.1 原理图
- 2.2 梯度计算
-
- 2.2.1 参数
- 2.2.2 举例说明
- 2.2.3 loss and 梯度上升法
- 2.2.4 cbow参数更新伪代码
-
- 3. skip-gram模型
-
-
- 3.1 原理图
- 3.2 梯度计算
-
- 3.2.1 伪代码
-
1. negative sampling and hierarchical softmax
由于softmax运算考虑了背景词可能是词典 V 中的任一词,以上损失包含了词典大小数目的项的累加。在上一节中我们看到,不论是skip-gram模型还是cbow模型,由于条件概率使用了softmax运算,每一步的梯度计算都包含词典大小数目的项的累加。对于含几十万或上百万词的较大词典,每次的梯度计算开销可能过大。为了降低该计算复杂度,提出了2种优化,即负采样(negative sampling)或层序softmax(hierarchical softmax),这一节,将主要讲解基于 Hierarchical Softmax 的cbow和skip-gram模型
2. CBOW model
2.1 原理图
cbow是在已知当前中心词 w t w_t wt的上下文 w t − 2 , w t − 1 , w t + 1 , w t + 2 w_{t-2},w_{t-1},w_{t+1},w_{t+2} wt−2,wt−1,wt+1,wt+2的情况下来预测当前词 w t w_t wt。
图为cbow的网络结构:
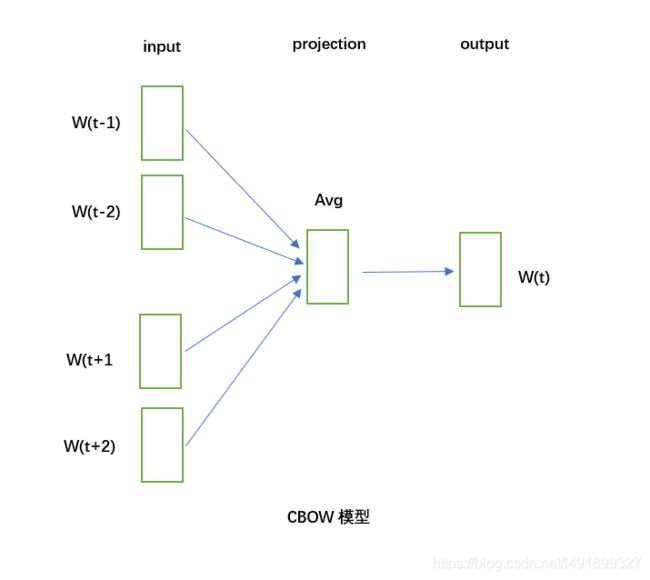
可以看到,cbow分为输入层,隐藏层和输出层,以(contenxt(w),w)为例,其中context(w)包含w的上下文,假设窗口长度为c,则context(w)包含了w前c个词和后c个词的词向量。
这里将对输入、隐藏、输出层做出解释:
输入层:context(w),由于包含2c个向量,此处假设context(w) = ( v 1 , v 2 , . . . , v c , v c + 1 , . . . , v 2 c , v ∈ R m v_1,v_2,...,v_c,v_{c+1},...,v_{2c},v \in \mathbb{R}^m v1,v2,...,vc,vc+1,...,v2c,v∈Rm,此处m为词向量长度)
隐藏层:将输入层的2c个向量作求和平均, x w = ∑ i = 1 2 c v i 2 c , x w ∈ R m x_w = \frac{\sum_{i=1}^{2c} v_i}{2c},x_w \in \mathbb{R}^m xw=2c∑i=12cvi,xw∈Rm

输出层:一棵Huffman树,它是以语料库中出现过的词作为叶子节点,词的出现次数作为叶子节点的权重。在huffman树中,叶子节点个数 N = ∣ D ∣ N=|D| N=∣D∣,分别对应词典D中的词,非叶子节点数为 ∣ D − 1 ∣ |D-1| ∣D−1∣
2.2 梯度计算
2.2.1 参数
Hierarchical Softmax是word2vec中用于提高性能的一项关键技术。为了描述方便,引入若干符号。考虑到Huffman树种的某个叶子结点,假设对应词典D中的词w,记
- p w p^w pw:从根结点出发到达w对应的叶子结点的路劲。
- l w l^w lw:路径 p w p^w pw中包含结点的个数。
- p 1 w , p 2 w , . . . , p l w w p_1^w,p_2^w,...,p_{l^w}^{w} p1w,p2w,...,plww:路径 p w p^w pw中的 l w l^w lw个结点,其中 p 1 w p_1^w p1w表示根结点, p l w w p_{l^w}^{w} plww表示词 w w w对应的结点。
- d 1 w , d 2 w , . . . , d l w w ∈ [ 0 , 1 ] d_1^w,d_2^w,...,d_{l^w}^{w} \in [0,1] d1w,d2w,...,dlww∈[0,1]:词 w w w的Huffman编码,它由 l w − 1 l^w-1 lw−1位编码组成, d j w d_j^w djw表示路径 p w p_w pw中第j个结点对应的编码(根结点不对应编码)。
- θ 1 w , θ 2 w , . . . , θ l w − 1 w ∈ R m : 路 径 p w 中 非 叶 子 结 点 对 应 的 向 量 , θ j w 表 示 路 径 p w 中 第 j 个 非 叶 子 结 点 对 应 的 向 量 。 \theta_1^w,\theta_2^w,...,\theta_{l^w-1}^{w} \in \mathbb{R^m}:路径p^w中非叶子结点对应的向量,\theta_j^w表示路径p^w中第j个非叶子结点对应的向量。 θ1w,θ2w,...,θlw−1w∈Rm:路径pw中非叶子结点对应的向量,θjw表示路径pw中第j个非叶子结点对应的向量。
2.2.2 举例说明
既然引入了一堆符号,那么现在通过一个简单的例子来说明下
图1中由4个橙色边连起来的5个结点构成路径 p w p^w pw,其长度 l w l^w lw = 5. p 1 w , p 2 w , p 3 w , p 4 w , p 5 w p_1^w,p_2^w,p_3^w,p_4^w,p_5^w p1w,p2w,p3w,p4w,p5w成为路劲 p w p^w pw上的5个结点,其中 p 1 w p_1^w p1w对应根结点。 d 1 w , d 2 w , d 3 w , d 4 w d_1^w,d_2^w,d_3^w,d_4^w d1w,d2w,d3w,d4w分别为1,0,0,1,即“足球”的huffman编码为1001,此外, θ 1 w , θ 2 w , θ 3 w , θ 4 w \theta_1^w,\theta_2^w,\theta_3^w,\theta_4^w θ1w,θ2w,θ3w,θ4w分别表示路径 p w p^w pw上4个非叶子结点对应的向量。

那么,如何计算 p ( w ∣ c o n t e x t ( w ) ) 呢 p(w|context(w))呢 p(w∣context(w))呢,或者说该如何计算 p ( w ∣ x w ) p(w|x_w) p(w∣xw),以 w = " 足 球 " w="足球" w="足球"为例,从根结点到达"足球"这个叶子结点,中间总共经历了4词分支,也可以看做进行了4次2分类,在Word2vec源码中,定义左边叶子为1,右边为0,同时定义1为负类,0为正类。
此处引用sigmoid函数来计算概率,即一个结点被分为正类的概率为
σ ( x w T θ ) = 1 1 + e − x w T θ \sigma(x_w^T \theta) = \frac{1}{1+e^{-x_w^T \theta}} σ(xwTθ)=1+e−xwTθ1
分为负类的概率为
1 − σ ( x w T θ ) 1-\sigma(x_w^T \theta) 1−σ(xwTθ)
那么从根结点到达"足球"这个叶子结点所经历的4次二分类,每次分类对应的概率记为
- 第一次: p ( d 2 w ∣ x w , θ 1 w ) = 1 − σ ( x w T θ 1 w ) p(d_2^w|x_w,\theta_1^w) =1-\sigma(x_w^T \theta_1^w) p(d2w∣xw,θ1w)=1−σ(xwTθ1w)
- 第二次: p ( d 3 w ∣ x w , θ 2 w ) = σ ( x w T θ 2 w ) p(d_3^w|x_w,\theta_2^w) = \sigma(x_w^T \theta_2^w) p(d3w∣xw,θ2w)=σ(xwTθ2w)
- 第三次: p ( d 4 w ∣ x w , θ 3 w ) = σ ( x w T θ 3 w ) p(d_4^w|x_w,\theta_3^w) = \sigma(x_w^T \theta_3^w) p(d4w∣xw,θ3w)=σ(xwTθ3w)
- 第四次: p ( d 5 w ∣ x w , θ 4 w ) = 1 − σ ( x w T θ 4 w ) p(d_5^w|x_w,\theta_4^w) =1-\sigma(x_w^T \theta_4^w) p(d5w∣xw,θ4w)=1−σ(xwTθ4w)
所以 p ( 足 球 ∣ c o n t e n t ( 足 球 ) ) = ∏ j = 2 5 p ( d j w ∣ x w , θ j − 1 w ) p(足球|content(足球)) = \prod_{j=2}^{5} p(d_j^w|x_w,\theta_{j-1}^w) p(足球∣content(足球))=∏j=25p(djw∣xw,θj−1w)
2.2.3 loss and 梯度上升法
cbow实现的是:在已知w的背景词的情况下,预测中心词为w的概率最大。
即:最大化 p ( w ∣ c o n t e n t ( w ) ) = ∏ j = 2 l w p ( d j w ∣ x w , θ j − 1 w ) p(w|content(w)) = \prod_{j=2}^{l_w} p(d_j^w|x_w,\theta_{j-1}^w) p(w∣content(w))=∏j=2lwp(djw∣xw,θj−1w)
其中
p ( d j w ∣ x w , θ j − 1 w ) = { σ ( x w T θ j − 1 w ) d j w = 0 1 − σ ( x w T θ j − 1 w ) d j w = 1 p(d_j^w|x_w,\theta_{j-1}^w)= \begin{cases} \sigma(x_w^T \theta_{j-1}^w) & {d_j^w=0}\\ 1-\sigma(x_w^T \theta_{j-1}^w) & {d_j^w=1} \end{cases} p(djw∣xw,θj−1w)={ σ(xwTθj−1w)1−σ(xwTθj−1w)djw=0djw=1
则
p ( d j w ∣ x w , θ j − 1 w ) = σ ( x w T θ j − 1 w ) 1 − d j w ⋅ [ 1 − σ ( x w T θ j − 1 w ) ] d j w p(d_j^w|x_w,\theta_{j-1}^w) = {\sigma(x_w^T \theta_{j-1}^w)}^{1-d_j^w} \cdot {[1-\sigma(x_w^T \theta_{j-1}^w)}]^{d_j^w} p(djw∣xw,θj−1w)=σ(xwTθj−1w)1−djw⋅[1−σ(xwTθj−1w)]djw
将此公式运用到字典C中,即希望最大化
∏ w ∈ C p ( w ∣ c o n t e n t ( w ) ) = ∏ w ∈ C ∏ j = 2 l w σ ( x w T θ j − 1 w ) 1 − d j w ⋅ [ 1 − σ ( x w T θ j − 1 w ) ] d j w \prod_{w \in C} p(w|content(w)) = \prod_{w \in C} \prod_{j=2}^{l_w} {\sigma(x_w^T \theta_{j-1}^w)}^{1-d_j^w} \cdot {[1-\sigma(x_w^T \theta_{j-1}^w)}]^{d_j^w} w∈C∏p(w∣content(w))=w∈C∏j=2∏lwσ(xwTθj−1w)1−djw⋅[1−σ(xwTθj−1w)]djw
此公式取log,引入对数似然函数,使得
L = ∑ w ∈ C ∑ j = 2 l w ( 1 − d j w ) ⋅ l o g [ σ ( x w T θ j − 1 w ) ] + d j w ⋅ l o g [ 1 − σ ( x w T θ j − 1 w ) ] L = \sum_{w \in C} \sum_{j=2}^{l^w} (1-d_j^w) \cdot log[\sigma(x_w^T \theta_{j-1}^w)] +d_j^w \cdot log[1-\sigma(x_w^T \theta_{j-1}^w)] L=w∈C∑j=2∑lw(1−djw)⋅log[σ(xwTθj−1w)]+djw⋅log[1−σ(xwTθj−1w)]
为了求导方便,将上式中2个求和下的公式简记为:
L = ∑ w ∈ C ∑ j = 2 l w l ( w , j ) L = \sum_{w \in C} \sum_{j=2}^{l^w} l(w,j) L=w∈C∑j=2∑lwl(w,j)
即
l ( w , j ) = ( 1 − d j w ) ⋅ l o g [ σ ( x w T θ j − 1 w ) ] + d j w ⋅ l o g [ 1 − σ ( x w T θ j − 1 w ) ] l(w,j)= (1-d_j^w) \cdot log[\sigma(x_w^T \theta_{j-1}^w)] +d_j^w \cdot log[1-\sigma(x_w^T \theta_{j-1}^w)] l(w,j)=(1−djw)⋅log[σ(xwTθj−1w)]+djw⋅log[1−σ(xwTθj−1w)]
至此,已经推导出对数似然函数L为cbow模型的目标函数,word2vec中采用随机梯度上升法来求解目标函数
随机梯度上升法:每取一个样本(context(w),w),就对目标函数中的所有相关参数做一次更新,每次循环更新的参数包括
x w , θ j − 1 w , w ∈ C , j = 2 , 3 , . . . , l w x_w,\theta_{j-1}^{w},w \in C,j = 2,3,...,l_w xw,θj−1w,w∈C,j=2,3,...,lw
为此,先给出 l ( w , j ) l(w,j) l(w,j)关于这些向量的梯度
l ( w , j ) 关 于 θ j − 1 w 的 梯 度 计 算 : l(w,j)关于\theta_{j-1}^w的梯度计算: l(w,j)关于θj−1w的梯度计算:
∂ l ( w , j ) ∂ θ j − 1 w = ∂ ∂ θ j − 1 w { ( 1 − d j w ) ⋅ l o g [ σ ( x w T θ j − 1 w ) ] + d j w ⋅ l o g [ 1 − σ ( x w T θ j − 1 w ) ] } = ( 1 − d j w ) [ 1 − σ ( x w T θ j − 1 w ) ] x w − d j w σ ( x w T θ j − 1 w ) x w = { ( 1 − d j w ) [ 1 − σ ( x w T θ j − 1 w ) ] − d j w σ ( x w T θ j − 1 w ) } x w = [ 1 − d j w − σ ( x w T θ j − 1 w ) ] x w \begin{aligned} \frac{ \partial l(w,j)}{ \partial \theta_{j-1}^w} & = \frac{ \partial }{ \partial \theta_{j-1}^w} \{ (1-d_j^w) \cdot log[\sigma(x_w^T \theta_{j-1}^w)] +d_j^w \cdot log[1-\sigma(x_w^T \theta_{j-1}^w)] \} \\ &= {}(1-d_j^w)[1-\sigma(x_w^T \theta_{j-1}^w)]x_w - d_j^w\sigma(x_w^T \theta_{j-1}^w)x_w \\ &= \{(1-d_j^w) [1-\sigma(x_w^T \theta_{j-1}^w)] -d_j^w \sigma(x_w^T \theta_{j-1}^w) \}x_w \\ &= [1-d_j^w - \sigma(x_w^T \theta_{j-1}^w)]x_w \end{aligned} ∂θj−1w∂l(w,j)=∂θj−1w∂{ (1−djw)⋅log[σ(xwTθj−1w)]+djw⋅log[1−σ(xwTθj−1w)]}=(1−djw)[1−σ(xwTθj−1w)]xw−djwσ(xwTθj−1w)xw={ (1−djw)[1−σ(xwTθj−1w)]−djwσ(xwTθj−1w)}xw=[1−djw−σ(xwTθj−1w)]xw
于是, θ j − 1 w \theta_{j-1}^w θj−1w的更新公式为
θ j − 1 w : = θ j − 1 w + η [ 1 − d j w − σ ( x w T θ j − 1 w ) ] x w \theta_{j-1}^w:=\theta_{j-1}^w + \eta[1-d_j^w-\sigma(x_w^T \theta_{j-1}^w)]x_w θj−1w:=θj−1w+η[1−djw−σ(xwTθj−1w)]xw
其中 η \eta η表示学习率,下同。
可得
∂ l ( w , j ) ∂ x w = [ 1 − d j w − σ ( x w T θ j − 1 w ) ] θ j − 1 w \frac{ \partial l(w,j)}{ \partial x_w}= [1-d_j^w-\sigma(x_w^T \theta_{j-1}^w)]\theta_{j-1}^w ∂xw∂l(w,j)=[1−djw−σ(xwTθj−1w)]θj−1w
我们的最终目的是要求词典D中每个词的词向量,而这里的 x w x_w xw表示的是context(w)中各词词向量的均值,那么如何利用 ∂ l ( w , j ) ∂ x w \frac{ \partial l(w,j)}{ \partial x_w} ∂xw∂l(w,j)来对 v ( w ~ ) , w ~ ∈ c o n t e x t ( w ) v(\widetilde{w}),\widetilde{w} \in context(w) v(w ),w ∈context(w)进行更新?
word2vec的做法很简单,直接取
v ( w ~ ) : = v ( w ~ ) + η ∑ j = 2 l w ∂ l ( w , j ) ∂ x w , w ~ ∈ c o n t e x t ( w ) v(\widetilde{w}) := v(\widetilde{w}) + \eta \sum_{j=2}^{l^w} \frac{ \partial l(w,j)}{ \partial x_w},\widetilde{w} \in context(w) v(w ):=v(w )+ηj=2∑lw∂xw∂l(w,j),w ∈context(w)
即把 ∑ j = 2 l w ∂ l ( w , j ) ∂ x w \sum_{j=2}^{l^w} \frac{ \partial l(w,j)}{ \partial x_w} ∑j=2lw∂xw∂l(w,j)贡献到context(w)的每一个词的词向量上。因为 x w x_w xw本身就是有context(w)中每个词的词向量的均值,求完梯度也应该讲此梯度贡献到每个分量上去。
2.2.4 cbow参数更新伪代码
- e=0
- x w = ∑ u ∈ c o n t e x t ( w ) v ( u ) x_w = \sum_{u \in context(w)} v(u) xw=∑u∈context(w)v(u)
- For j = 2 : l w \quad j=2 : l^w j=2:lw
{
3.1 q = σ ( x w T θ j − 1 w ) \quad q = \sigma(x_w^T \theta_{j-1}^w) q=σ(xwTθj−1w)
3.2 g = η ( 1 − d d w − q ) \quad g= \eta (1-d_d^w - q) g=η(1−ddw−q)
3.3 e : = e + g θ j − 1 w \quad e:=e+g \theta_{j-1}^{w} e:=e+gθj−1w
3.4 θ j − 1 w : = θ j − 1 w + g x w \quad \theta_{j-1}^{w}:=\theta_{j-1}^{w} + gx_w θj−1w:=θj−1w+gxw
} - For u ∈ c o n t e x t ( w ) \quad u \in context(w) u∈context(w)
{
v ( u ) : = v ( u ) + e \qquad v(u):=v(u) + e v(u):=v(u)+e
}
注释:结合伪代码,给出与word2vec源码中的对应关系如下:syn0对应 v ( ⋅ ) v(\cdot) v(⋅),syn1对应 θ j − 1 w \theta_{j-1}^{w} θj−1w,neu1对应 x w x_w xw,neu1e对应e
3. skip-gram模型
skip-gram模型的网络结构同cbow的差不多,都是分为3层:输入层、投影层和输出层。但是与cbow不同,cbow的将背景词的词向量求平均在投影层生成 x w x_w xw向量,输出也是一颗huffman树。
3.1 原理图

skip-gram:在已知中心词 v w v_w vw的情况下,预测背景词context(w)。
首先先看3个层:
- 输入层: 只包含当前样本中心词w的词向量 v w ∈ R m v_w \in \mathbb{R}^m vw∈Rm
- 投影层:当前样本中心词w的词向量 v w ∈ R m v_w \in \mathbb{R}^m vw∈Rm,这是个恒等投影,只是为了和cbow的网络结构作对比。
- 输出层: huffman树
3.2 梯度计算
对于skip-gram来说,已知当前词w,需要对其上下文context(w)中的词做预测。因此目标函数应该是中心词w对每个背景词的条件概率,skip-gram模型将其定义为
p ( c o n t e x t ( w ) ∣ w ) = ∏ u ∈ c o n t e x t ( w ) p ( u ∣ w ) p(context(w)|w) = \prod_{u \in context(w)} p(u|w) p(context(w)∣w)=u∈context(w)∏p(u∣w)
然而,如果使用此目标函数,每次迭代都只能更新 v ( w ) v(w) v(w)这一个输入的向量,并不能对背景词中词向量进行更新。
所以skip-gram在Word2vec源码中做出了修改
我们在希望最大化
∏ u ∈ c o n t e x t ( w ) p ( u ∣ w ) ) \prod_{u \in context(w)} p(u|w)) u∈context(w)∏p(u∣w))
的同时,我们也希望
∏ u ∈ c o n t e x t ( w ) p ( w ∣ u ) \prod_{u \in context(w)} p(w|u) u∈context(w)∏p(w∣u)
可以得到最大化,这与cbow的思想一摸一样,只是从更新背景词中2c个词向量的均值 x w x_w xw变为直接更新背景词中的2c个输出的词向量,也就是损失函数直接对 u ( i ) , i = 1 , 2 , 3 , 4 , . . . 2 c u(i),i = 1,2,3,4,...2c u(i),i=1,2,3,4,...2c进行求导。
也可变相理解为:cbow的输入是2c个背景词的均值向量,而skip-gram的输入直接是2c个背景词词向量,这样可以直接对2c个背景词的词向量单独计算梯度进行向量更新,效果远好于单独对一个字w的词向量进行更新。
3.2.1 伪代码
{
for i =1 to 2c:
e = 0 \qquad e=0 e=0
\qquad for j = 2 to l w l^w lw:
q = σ ( u i T θ j − 1 w ) \qquad \qquad q = \sigma(u_i^T \theta_{j-1}^w) q=σ(uiTθj−1w)
g = η ( 1 − d j w − q ) \qquad \qquad g = \eta (1-d_j^w - q) g=η(1−djw−q)
e : = e + g θ j − 1 w \qquad\qquad e:=e+g \theta_{j-1}^{w} e:=e+gθj−1w
θ j − 1 w : = θ j − 1 w + g u i \qquad\qquad \theta_{j-1}^{w}:=\theta_{j-1}^{w} + gu_i θj−1w:=θj−1w+gui
u i : = u i + e \qquad\qquad u_i:= u_i+e ui:=ui+e
}