函数与编程
Python中的函数用法及编程一般思路
- 一 Python的自定义函数
-
- 1.函数名
- 2.返回值
-
- 1)无返回值
- 2)返回值为数字类型
- 3)返回值为字符串型
- 4)返回值为列表或字典
- 5)返回值类型为元组
- 3.参数
-
- 1)位置参数
- 2)默认参数
- 3)可变参数(元组传参)
- 4)字典传参
- 5)参数作用域
- 6)传参顺序
- 4.函数的嵌套使用
- 二、编程思路及具体问题解决
-
- 1.解决问题的思路介绍
- 2.实例演示
- 3.格式符的应用
一 Python的自定义函数
函数是组织好的、可以重复使用的、用来实现单一功能的代码。作为拆解大问题的有效手段,在实际的编程中必不可少。
函数定义
函数的主体包括函数名,参数,函数体和返回值。其定义为:
def 函数名 (参数):
函数体
return语句
以下对函数的各个要素进行讲解:
1.函数名
函数名是用户自定义的,可以通过简单的字母和部分符号组合标定函数的主要功能。需要注意自定义函数不能与系统函数“重名”。
2.返回值
在Python中,一个函数可以存在一个或多个返回值,也可以不设返回值。返回值类型可以为整形、浮点型、字符串型、列表、字典或元组。以下分别探讨各类型的返回值:
1)无返回值
无返回值的函数通常在函数内部就完成了特定功能,无需返回。观察下面的例子:
def add(x,y):
print(x+y)
add(1,2)
print(add(1,2))
#输出结果为: 3
# 3
# None
由于add()函数没有返回值,所以print(add(1,2))的打印结果会是None。但细心的小伙伴一定已经发现了一个问题,那就是3这个结果输出了两次。这一结果出现的原因其实是add()函数在上述代码中调用了两次,分别在第三行和第四行。关于这一现象,后面会具体讨论。
2)返回值为数字类型
以下讨论的数字类型有两种,分别为int型和float型。下面通过代码进行探究:
def add(x,y):
return x+y
a=1
b=1
print(a,b,type(a),type(b))
print(add(a,b),type(add(1,2)))
#结果为:1 1
# 2 可以看到,这里的a和b都是int型,调用了函数后结果还是int型。
那么a和b中有float型或者都为float型,结果如何呢?(以a,b均为float型为例)
def add(x,y):
return x+y
a=1.0
b=1.5
print(a,b,type(a),type(b))
print(add(a,b),type(add(1,2)))
#结果为:1.0 1.5
# 2.5 结果依旧是int型。
def add(x,y):
return float(x+y)
a=1
b=2
print((add(a,b)),type(add(a,b)))
#结果为:3.0 返回值为float型。
3)返回值为字符串型
利用下面函数拼接输入的字母:
def joint(x,y):
z=x+y
return z
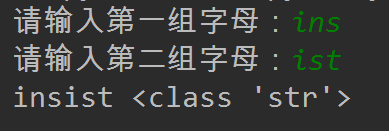
a=input('请输入第一组字母:')
b=input('请输入第二组字母:')
print((joint(a,b)),type((joint(a,b))))
运行结果为:
4)返回值为列表或字典
列表和字典作为返回值的情况并不复杂,和单一的字符或数字作为返回值比较类似。当函数的返回值为一个列表时,其返回值类型为list。示例如下:
def gift_list():
gift=['蛋挞','鸡翅','薯条']
return gift
print('赠品为:',end='')
list=gift_list()
print(list,type(list))
#结果为:赠品为:['蛋挞', '鸡翅', '薯条'] 当函数的返回值为字典时,其返回值类型为list。示例如下:
def gift_list():
gift={
'a':'蛋挞','b':'鸡翅','c':'薯条'}
return gift
#也可以直接合并成一句:return {'a':'蛋挞','b':'鸡翅','c':'薯条'}。下同
print('赠品为:',end='')
dict=gift_list()
print(dict,type(dict))
#结果为:赠品为:{'a': '蛋挞', 'b': '鸡翅', 'c': '薯条'}可以在主函数里定义新变量将返回的字典或列表接收。
5)返回值类型为元组
元组类型作为返回值时,可以和列表、字典作为返回值的情况比较类似,示例如下:
def gift_list():
gift=('赠品有:',['蛋挞','鸡翅','薯条'])
return gift
tuple=gift_list()
print(tuple,type(tuple))
#结果为:('赠品有:', ['蛋挞', '鸡翅', '薯条']) 但是,由于元组类型内可以存储包括数字类型、字符串型、列表和字典在内的所有数据类型的数据,因此以元组作为返回值更多的时候用于函数有多个返回值时。假如我们需要编写一段程序,要求在三种增品种随机抽取一个搭配冰激凌送出:
#random.choice()函数可以完成在元组或列表中随机选取一个元素的功能
#但random.choice()函数不能完成在字典中随机取一个元素的功能
import random
foodten = ['蛋挞','鸡翅','薯条']
def order():
a = random.choice(foodten)
return a,'冰激淋'
res=order()
print(res,type(res))
#结果为:('薯条', '冰激淋') 这种情况下,计算机会默认返回值类型是元组。即使在res接收返回值之前将其定义为其他类型,接收后也依旧会被转换为元组类型。如:
import random
foodten = ['蛋挞','鸡翅','薯条']
def order():
a = random.choice(foodten)
return a,'冰激淋'
res=1
#将res定义为整型
res=order()
print(res,type(res))
输出的结果依然为:(‘薯条’, ‘冰激淋’)
3.参数
1)位置参数
位置参数是描述总体最常用的一种参数。举例为:
def func (x,y,z):
这个定义中,x、y、z就是位置参数。
调用函数时,传参数量必须和位置参数数量相同,否则计算机会报错。示例如下:
def add (x,y):
return x+y
res1=add(1,2)
print(res1)
res2=add(1)
print(res2)
这样一来的输出结果为:

错误的原因是第五行调用add()函数时缺少一个必须的位置参数“y”。
2)默认参数
含有默认参数的函数举例:
def add (x,y=0):
return x+y
res=add(1)
print(res)
#运行结果为:1
这个例子中,y就是默认参数。如果调用add()时没有对y进行传参,那么计算机会默认y为0,从而得出结果。同时,如果调用add()函数时,又一次对y进行传参,会有以下结果:
def add (x,y=0):
return x+y
res=add(1,2)
print(res)
#输出结果为:3
这个结果表明,默认的y=0被传入的参数y=2覆盖。
因此,如果需要定义一个不被修改的默认参数,其位置一定要放在默认参数之后,否则无法在默认参数不被覆盖的情况下完成对位置参数的传参。
3)可变参数(元组传参)
元组传参的定义形式举例:
def func (*tup):
前文提到,元组类型内可以存储所有数据类型的数据,因此元组传参的方式对传入参数应该也没有数据类型要求。下面我们对元组传参的功能进行探究:
def menu(*food):
#返回套餐内容
return food
order1=menu('香辣鸡腿堡','可乐')
order2=menu('卤肉饭','老北京鸡肉卷','雪碧','可乐')
order3=menu('烤串','火锅','培根烤鸡腿堡','橙汁','薯条','甜筒')
print(order1)
print(order2)
print(order3)
#结果为:('香辣鸡腿堡', '可乐')
# ('卤肉饭', '老北京鸡肉卷', '雪碧', '可乐')
# ('烤串', '火锅', '培根烤鸡腿堡', '橙汁', '薯条', '甜筒')
从以上结果看出,输入数量不同的参数,函数都可以完成函数返回套餐内容的功能,这说明元组传参的方式可以传递未知数量的参数。
下面来试验一下元组传参是否支持不同数据类型参数:
def menu(*food):
return food
order=menu(('烤串'),{
'火锅':'expensive','培根烤鸡腿堡':'cheep'},['橙汁','薯条','甜筒'])
print(order)
#结果为:('烤串', {'火锅': 'expensive', '培根烤鸡腿堡': 'cheep'}, ['橙汁', '薯条', '甜筒'])
这个结果说明,之前的猜想完全正确,元组传参可以传递未知个数、不同类型的参数。
4)字典传参
字典传参不是指用字典作为参数传递给函数,而是传入的参数在字典中以字典的形式呈现。其定义为:
def func (**dit):
举个简单的例子:
调用函数打印一个简易成绩单
def grade (**stu):
print(stu)
grade(zhang=90,wang=120,zhao=150)
#结果为:{'zhang': 90, 'wang': 120, 'zhao': 150}
从上例中我们可以看出,字典传参实际上是在函数中以字典类型存储参数,同时可以通过字典的访问方式访问各个参数。字典传参的方式也没有对参数的数量限制。
5)参数作用域
函数的作用于分为全局作用域和局部作用域,下面我们举例探索全局作用域和局部作用域的区别:
例1:编写制作成绩单函数:
def grade (**stu):
return stu
grade(zhang=90,wang=120,zhao=150)
print(stu)
运行的结果为:

可以看到虽然我们在函数内部制作了成绩单“stu”,但是依然出现了“stu”没有定义的错误。这说明函数内申请的变量只在函数内存在,即其作用域为局部。
例2:编写将传入参数翻倍的函数:
a=2
def double (x):
return 2*x
res=double(23)
print(res)
#结果为:46
可以看出,在主函数内定义的变量,可以直接在子函数中使用,即其作用域为全局。
对于局部变量,可以在其前面加一个“global”修饰,将其更改为全局变量,还以成绩单函数为例:
def grade (**s):
global stu
stu=s
grade(zhang=90,wang=120,zhao=150)
print(stu)
#结果为:{'zhang': 90, 'wang': 120, 'zhao': 150}
可以看出,“stu”被修改为全局变量之后,在grade()函数以外就可以直接使用了。
6)传参顺序
既然函数传参方式有很多种,那么在一个需要同时使用多种方式传参的函数中,就会对传参顺序就会有额外要求。比如,一个需要1个位置参数,1个默认参数和1个可变参数,那么顺序就应该为:(位置参数,可变参数,默认参数)。如果将可变参数放在首位,那么位置参数将无法接收到传参,因为所有的传参都会被可变参数接收,而如果将默认参数放在位置参数或可变参数之前,那么在传参过程中,默认参数又一定会被覆盖。因此,传参顺序一般为:位置参数,可变参数,默认参数。字典传参则一定要放在最后面,否则会引起计算机报错。
下面我们研究一下系统函数print的传参顺序:
查找到print函数的定义为:
print(*objects, sep = ' ', end = '\n', file = sys.stdout, flush = False)
从这个函数的参数分布来看,默认参数确实是放在可变参数之后的。同时,我们也可以修改默认参数来改变部分功能:
print(1,2,3,4,5,sep=' and ')
#打印五个数字,以' and '作为分隔
#结果为:1 and 2 and 3 and 4 and 5
4.函数的嵌套使用
函数除了可以单独使用,也可以嵌套使用。所谓的嵌套使用,即为向某个函数传递的参数是调用其它函数运算的结果,比如:
import time
def mul (x,y):#乘法函数
time.sleep(1)
print(x*y)
return x*y
def add (x,y):#加法函数
#由于x,y为局部作用域,因此mul()函数中定义的
#参数x,y在离开mul()函数后就会失效,因此add()函数里依然用
#x,y作为参数是可行的。
time.sleep(1)
print(x+y)
return x+y
print(mul(add(2,3),add(2,2)))
#结果为:5
# 4
# 20
# 20
看到“print(mul(add(2,3),add(2,2)))”这行代码可以看出,这里的print函数嵌套了mul函数,而mul函数又嵌套了add函数。从结果不难看出,计算及实际执行的顺序为:
1.add(2,3),打印5,返回5;
2.add(2,2),打印4,返回5;
2.mul(5,4),打印20,返回20;
3.print(20),打印结果20。
计算机在面对嵌套使用的函数时,先执行的是最内层的函数,在最内层函数执行完成后,再继续执行此时的最内层函数,直到所有函数都执行完毕。在同一层有多次函数调用时,会从左到右依次执行。
函数的嵌套使用还有一种特殊情况:自己调用自己。这种情况会在之后讲到。
二、编程思路及具体问题解决
1.解决问题的思路介绍
利用编程解决问题的基本思路是将一个大问题拆解成多个步骤和方面,逐渐完成最简单的步骤和方面,进而解决整个问题。
项目完成流程
1.明确项目目的;
2.分析流程,拆解项目;
3.逐步解决,逐渐完善。
2.实例演示
下面我们通过一个实例演示如何解决问题:
利用函数的自调用完成任意数的阶乘计算,并将计算结果返回。
第一步:假设需要计算的是5的阶乘,第一步需要计算5*(5-1):
def fac(x):
res=x
x-=1
res*=x
print(res)
fac(5)
#结果为:20
以上结果说明,我们已经完成利用函数计算5*(5-1)了。那么第二步,我们需要完成利用函数自调用计算5*(5-1)*((5-1)-1)…:
根据上一步的经验,我们对函数作出以下改动:
def fac(x):
res=x
x-=1
res*=x
if x>1:
fac(x)
else:
print(res)
fac(5)
#结果为:2
很显然,不是我们想要的结果。那么问题在哪里呢?进入单步调试发现,在计算机第一次执行完第四行代码时,res为20,此时x=4,执行fac(4)。由于res作用域为局部,所以之前的内容(res=20)会丢失并在之后被重新赋值为4。为了可以将之前的res储存并且在之后不被覆盖,我们引入另一个默认参数y:
def fac(x,y=1):
res=y
#在首次调用函数时,要将res的置为1,在之后调用中保存
#上一步的res结果
res=x*y
x-=1
if x>1:
fac(x,res)
else:
print(res)
fac(5)
#结果为120
结果正确,说明我们通过函数自调用的方法计算并打印5的阶乘的任务已经完成。
第三步:输入任意数字,完成阶乘计算:
def fac(x,y=1):
res=y
res=x*y
x-=1
if x>1:
fac(x,res)
else:
print(res)
#单步调用前要从主函数最先执行的地方设置标记点
f=int(input("请输入一个数:"))
fac(f)
#输入5,结果为:120
结果正确。下面需要完成将计算的结果返回的任务:
def fac (x,y=1):
res=y
res*=x
x-=1
if x>1:
fac(x,res)
else:
print(res)
return res
f=int(input("请输入一个数:"))
#结果为:请输入一个数:5
# 120
# 5的阶乘为:None
返回值出现错误。继续进行单步调试发现代码运行的过程为:
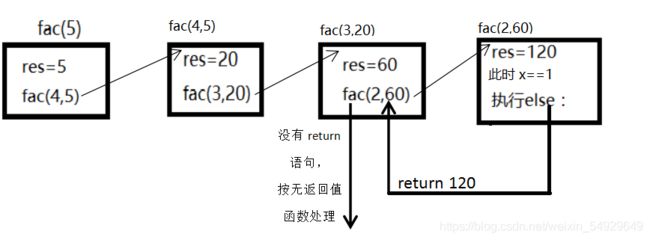
函数的自调用与简单嵌套区别在于:函数的自调用过程中,计算机没办法直接从最内层的函数fac(2,60)开始执行,只能从fac(5)开始,一层一层向内执行,因此在最内层函数执行完成之后,需要逐层返回结果,而不是直接返回到主函数。因此我们实际需要的运行方式为:

因此将程序做以下修改:
def fac (x,y=1):
res=y
res*=x
x-=1
if x>1:
return fac(x,res)
else:
return res
f=int(input("请输入一个数:"))
print(str(f)+'的阶乘为:'+str(fac(f)))
#结果为:请输入一个数:5
# 5的阶乘为:120
结果正确。下面我们需要完成对代码的测试:键入其他数字看是否可以得到正确结果。当输入0时,结果出现错误:
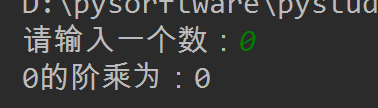
因此需要再次修改程序:
def fac (x,y=1):
res=y
if x==0:
return 1#如果输入数字为0,直接返回1
res*=x
x-=1
if x>1:
return fac(x,res)
else:
return res
f=int(input("请输入一个数:"))
print(str(f)+'的阶乘为:'+str(fac(f)))
这样,利用自调用求阶乘的函数就正式完成了。
3.格式符的应用
通过上面解决问题的举例,我们已经介绍了如何利用编程解决具体问题,接下来讲一种化简方式。观察以下程序片段:
print(str(f)+'的阶乘为:'+str(fac(f)))
我们使用【+】拼接字符串和变量的时候,常常要考虑变量是什么类型的数据,数据类型不统一,还要先进行强制类型转换以统一类型,再进行拼接。实际编程之中,可能会有需要多次强制类型转换后才能拼接的情况,非常麻烦。
因此我们介绍一种简单的拼接方式,即格式符(%):

将上述代码作以下改动:
print('%d的阶乘为:%d'%(f,fac(f)))
可以发现,这样处理后输出的结果相同,并且由于【%d的阶乘为:%d】在一个单引号内,所以尽管这三个部分格式不相同,依然可以打印出我们需要的结果,更为方便。