python爬取PM2.5信息
sentinel-1数据用snap的处理方法
前面因为需要,写了一个爬取PM数据的网站,但是因为长期访问,没有改IP,同一个IP多次访问一个网站,被网站察觉了。后果,你们知道的,hhhhhh,如果说只是一天的话,是肯定没问题的,但是不能太长时间,不然需要自己再加一个代理池。因为代理这个东西,…当然,这个是html格式的,所以只能适用于特定的网站。如果需要 可以试一下。但是因为前后改代码太多,所以原始可以直接跑的代码已经不知道哪里去了,这个是删了一些东西的,如果有错误,可以适当修改下。
import requests
from bs4 import BeautifulSoup
import re
import csv
from apscheduler.schedulers.blocking import BlockingScheduler
from datetime import datetime
import csv
import os
import datetime
import random
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
dir='E:\\Desktop\\11111111111111\\'#位置为双斜杠,最后两根斜杆不要去掉,添加需要将爬取的表格放入的文件夹位置。
header=["Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"\
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",\
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",\
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",\
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",\
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",\
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"]
url='https://pm25.im/city/'
header_1=random.choice(header)
tou={
'User-Agent':header_1,
'Connection':'close'}
try:
res = requests.get(url, headers=tou, timeout=1)
except:
header_1 = random.choice(header)
res = requests.get(url, headers=tou, timeout=1)
soup=BeautifulSoup(res.text,'html.parser')
count=0
citys=soup.find_all('p')
bbbb=[]
for city in citys:
cc=city.find('a')['href']
count+=1
if count>416:
break
else:
bbbb.append(cc)
print(bbbb)
def job():
# sc=['chengdu','zigong','panzhihua','luzhou','deyang','mianyang','guangyuan','suining','neijiang','leshan','nanchong','meishan'
# ,'yibin','guangan','dazhou','yaan','bazhong','ziyang','aba','ganzi','liangshan']
head=['station','local','year','month','day','houre','PM25','PM10','AQI']
# url1='https://pm25.im/'
for u in bbbb:
url=u
global year,month,day,houre
header_1=random.choice(header)
host_1=random.choice(host)
tou={
'User-Agent':header_1,
'Connection':'close'}
proxies={
"http":host_1}
try:
res=requests.get(url,headers=tou,timeout=200,verify=False,proxies=proxies)
except:
header_1 = random.choice(header)
res = requests.get(url, headers=tou, timeout=200, verify=False, proxies=proxies)
soup=BeautifulSoup(res.text,'html.parser')
print(soup)
try:
station=soup.find_all('span',class_="location")
PM25=soup.find_all('span',class_="pm25num")
PM10=soup.find_all('span',class_="pm10num")
time=soup.find('span',class_="time").text
year=time[:4]
month=time[5:7]
day=time[8:10]
houre=time[12:14]
# aqi=soup.find_all('div',class_="usaqi")
aqinum=soup.find_all('strong')
aqiz=soup.find_all('b')
aqi=[]
for i in range(0,len(aqinum)):
aqi.append(aqinum[i].text+'·'+aqiz[i].text)
local=soup.find('span',class_="cityname").text
sta=[]
pm25=[]
pm10=[]
rows=[]
aqi2=[]
count=0
for st in station:
sta.append(st.text)
count+=1
for p25 in PM25:
pm25.append(p25.text)
for p10 in PM10:
pm10.append(p10.text)
if count != len(aqinum):
sz = count-len(aqinum)
for i in range(0,sz):
aqi.append('No date')
for i in range(0,count):
row=[]
row.append(sta[i])
row.append(local)
row.append(year)
row.append(month)
row.append(day)
row.append(houre)
row.append(pm25[i])
row.append(pm10[i])
row.append(aqi[i])
rows.append(row)
with open(dir+year+month+day+houre.zfill(2)+local+'.csv','w',encoding='gbk',newline="")as f:
csvwriter=csv.writer(f,dialect='excel')
csvwriter.writerow(head)
for row in rows:
csvwriter.writerow(row)
except:
continue
with open(dir+'运行记录.txt','a',encoding='utf-8') as p:
nowTime=datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
year=nowTime[:4]
month=nowTime[5:7]
day=nowTime[8:10]
houre=nowTime[11:13]
p.write(year+month+day+houre+'已完成')
print(year+month+day+houre+'已完成')
scheduler = BlockingScheduler()
scheduler.add_job(func=job, trigger="cron",day="*", hour='0-23',minute='42')#从每天每个小时的01分开始爬取
scheduler.start()
#我们可以通过命令行输入如下,比如此处的这个程序 pyhon E:\Desktop\爬虫实例(空气污染)\crowd.p
这个程序加了schedule,每个小时都会固定爬取一次
一次爬取400多个城市的数据
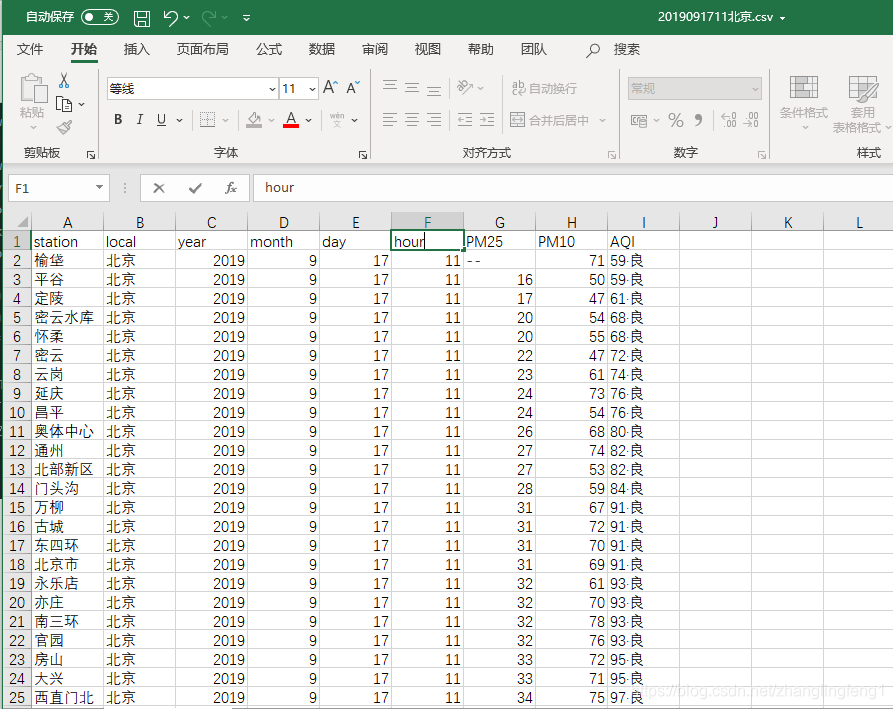
每个文件大致像上面一样