python实现 感知机(Perceptron)算法
1. 感知机简介
神经网络如下图所示:
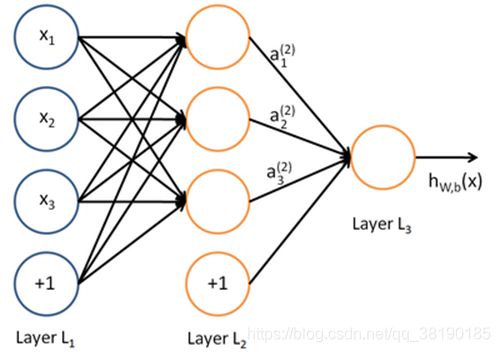
上图中每个圆圈都是一个神经元,每条线表示神经元之间的连接。我们可以看
到,上面的神经元被分成了多层,层与层之间的神经元有连接,而层内之间的
神经元没有连接。最左边的层叫做输入层,这层负责接收输入数据;最右边的
层叫输出层,我们可以从这层获取神经网络输出数据。输入层和输出层之间的
层叫做隐藏层。
感知器——神经网络的组成单元
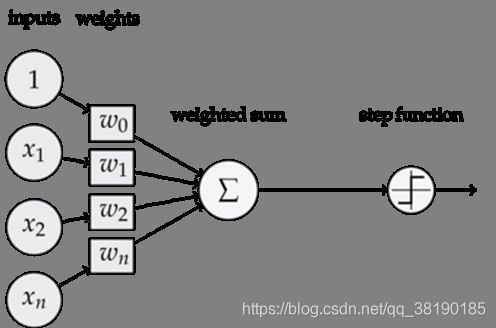
一个感知机有如下组成部分:

感知机训练算法
感知器训练算法:将权重项和偏置项初始化为0,然后,利用下面的感知器规则迭代的修改wi和b,直到训练完成。
其中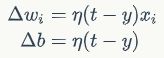
wi是与输入xi对应的权重项,b是偏置项。事实上,可以把b看作是值永远为1的输入xb所对应的权重。t是训练样本的实际值,一般称之为label。而y是感知器的输出值,它是根据公式(1)计算得出。ηη是一个称为学习速率的常数,其作用是控制每一步调整权的幅度。
每次从训练数据中取出一个样本的输入向量x,使用感知器计算其输出y,再根据上面的规则来调整权重。每处理一个样本就调整一次权重。经过多轮迭代后(即全部的训练数据被反复处理多轮),就可以训练出感知器的权重,使之实现目标函数。
2. 实验数据
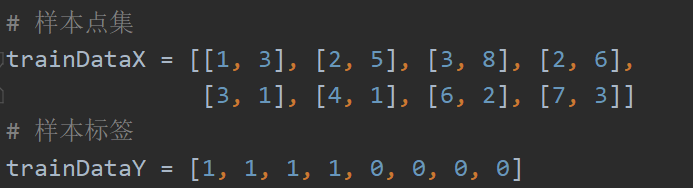
其中,trainDataX为实验所需点集,trainDataY为各点的标签
3. 代码实现
import numpy as np
import random
from matplotlib import pyplot as plt
# 样本点集
trainDataX = [[1, 3], [2, 5], [3, 8], [2, 6],
[3, 1], [4, 1], [6, 2], [7, 3]]
# 样本标签
trainDataY = [1, 1, 1, 1, 0, 0, 0, 0]
# 记录该点是否已经绘制在图像上
flag = np.zeros(8)
# 权重
weight = [0, 0]
# 偏置量
bias = 0
# 学习速率,控制每一步调整权的幅度
learnRate = 1
# 统计图片数
picCount = 0
# 输入最大训练次数
trainNum = 50
# 分别用来存放标签为0的点x坐标和y坐标
xSet1 = []
ySet1 = []
# 分别用来存放标签为1的点x坐标和y坐标
xSet2 = []
ySet2 = []
# 激活函数
def fun(n):
if n >= 0:
return 1
else:
return 0
# 绘制图像
def drawing():
global picCount
x_points = np.linspace(-2, 10, 6)
# 误差分类点到超平面的距离
y_ = -(weight[0] * x_points + bias) / weight[1]
plt.plot(xSet1, ySet1, 'o', color='blue', label='0')
plt.plot(xSet2, ySet2, 'o', color='orange', label='1')
plt.plot(x_points, y_)
plt.savefig(r'E:\Material\Perceptron3\\' + str(picCount) + 'jpg') # 保存图片
picCount += 1
plt.show()
def training():
global weight, bias
for j in range(trainNum):
# 从点集中随机取数
i = random.randint(0, len(trainDataX) - 1)
# 获取分类结果
result = fun(np.dot(trainDataX[i], weight) + bias)
# 若点分类正确且已经在图像上,则后面代码不需要执行
if result == trainDataY[i] and flag[i] == 1:
continue
# 更新权重
# 等价于下面两个式子
weight = weight + np.dot((trainDataY[i] - result), trainDataX[i]) \
* learnRate
# weight[0] = weight[0] + (trainDataY[i] - result) * \
# trainDataX[i][0] * learnRate
# weight[1] = weight[1] + (trainDataY[i] - result) * \
# trainDataX[i][1] * learnRate
print(trainDataX[i])
print(str(result) + ' ' + str(trainDataY[i]))
# 更新偏移量
bias = bias + (trainDataY[i] - result) \
* learnRate
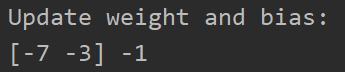
print("Update weight and bias: ")
print(weight, bias)
if trainDataY[i] == 1:
xSet2.append(trainDataX[i][0])
ySet2.append(trainDataX[i][1])
else:
xSet1.append(trainDataX[i][0])
ySet1.append(trainDataX[i][1])
drawing()
flag[i] = 1
print(str(j) + '------------------------------------------------ ' + str(trainNum))
if __name__ == '__main__':
training()
while True:
testData = []
data = input('enter test data (x1, x2): ')
if data == 'q': break
testData += [int(n) for n in data.split(',')]
predict = fun(weight[0] * testData[0] + weight[1] * testData[1] + bias)
print("predict ----- %d" % predict)
if predict == 1:
xSet2.append(testData[0])
ySet2.append(testData[1])
else:
xSet1.append(testData[0])
ySet1.append(testData[1])
drawing()4. 训练过程
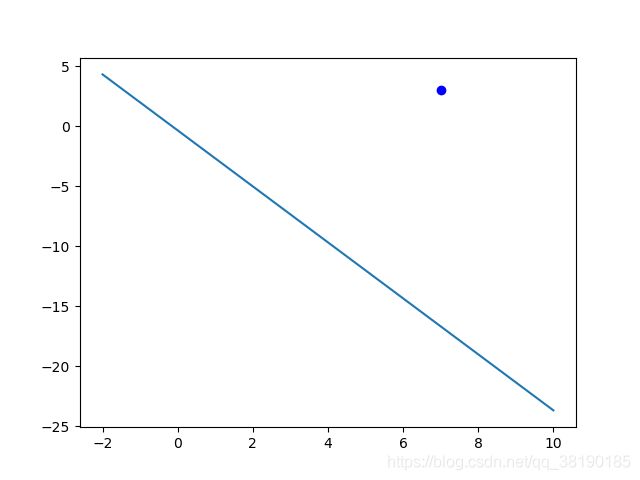
首先从数据集随机取出一个点(7,3),计算出分类结果为1,但其实际样本标本标签为0,所以需要调整weight(权重值)和bias(偏置值),修改后的值和得到的图像如下所示:
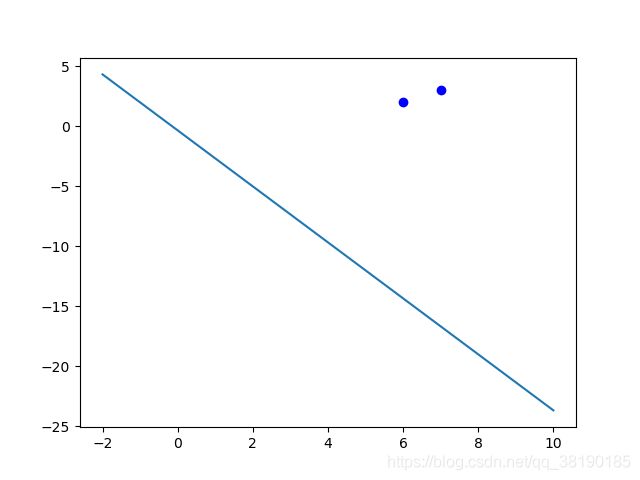
同理,随机取出点(6,2),计算出分类结果为0,实际样本标签为0,所以无需调整weight和bias
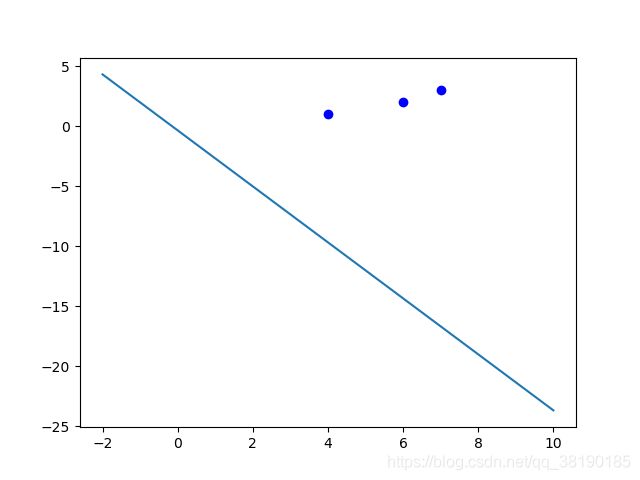
取出点(4,1),无需修改weight和bias
取出点(2,6),修改后的值为
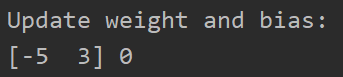
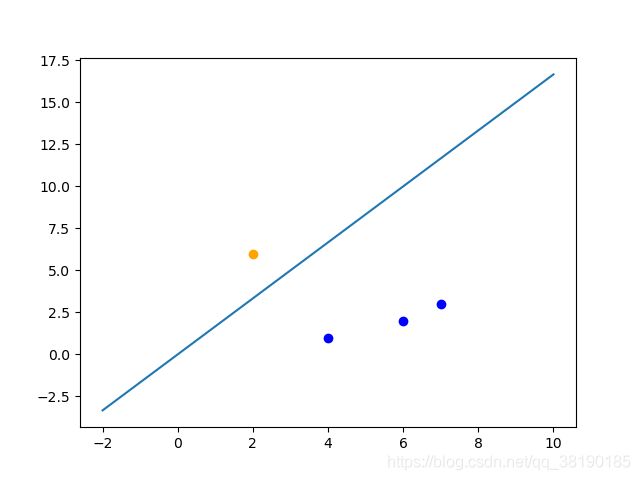
取出点(1,3),无需修改weight和bias
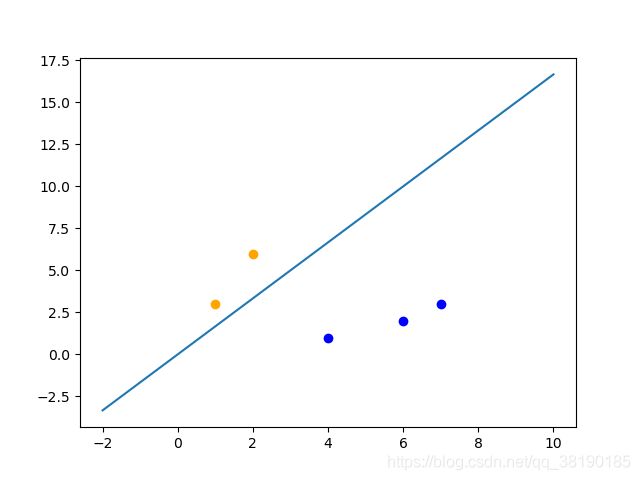
取出点(2,5),无需修改weight和bias
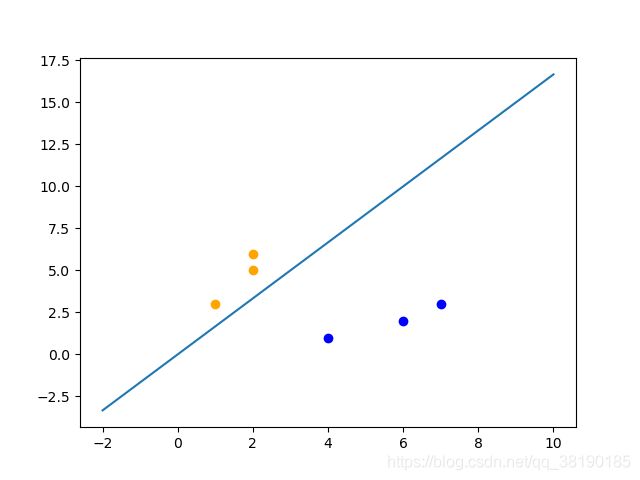
取出点(3,1),无需修改weight和bias
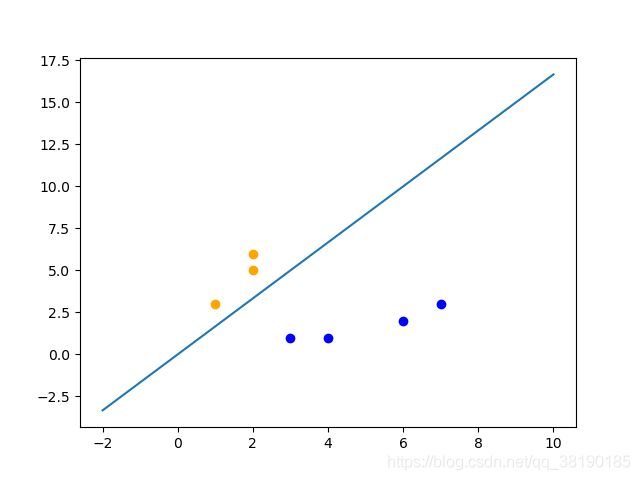
取出点(3,8),无需修改weight和bias
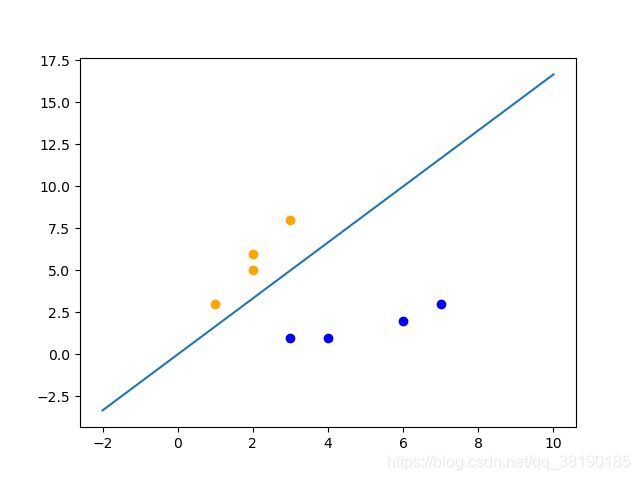
4. 测试过程
输入测试点(2,3),其分类结果为0,所以置其为蓝色

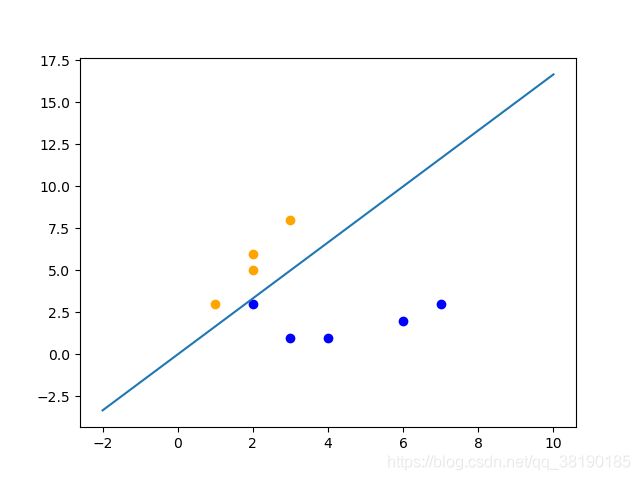 、
、
输入测试点(6,6),其分类结果为0,所以置其为蓝色

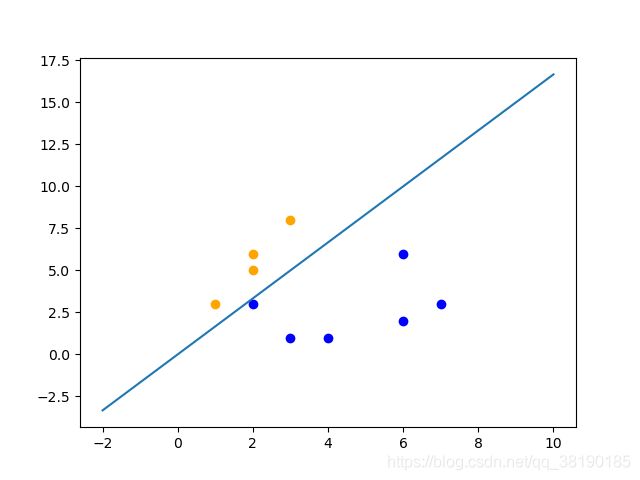
输入测试点(2,10),其分类结果为1,所以置其为黄色

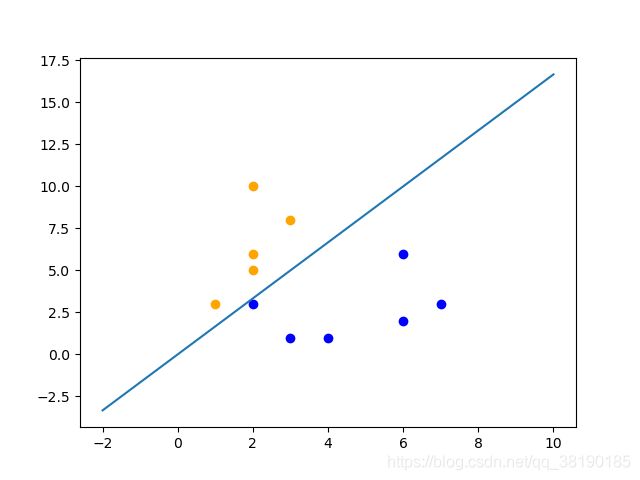
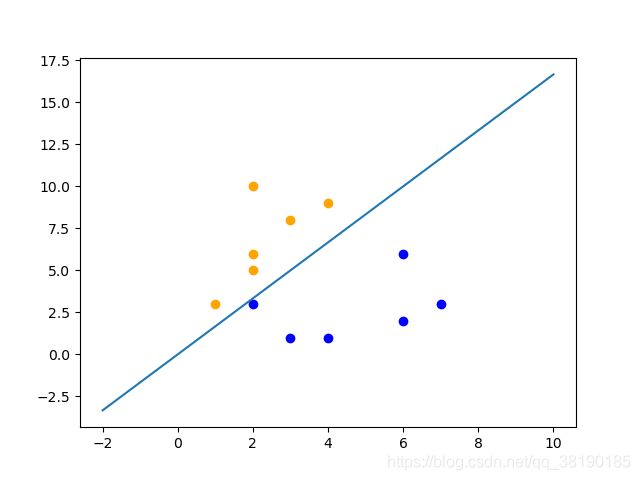
输入测试点(4,9),其分类结果为1,所以置其为黄色

参考:
https://www.cnblogs.com/xym4869/p/11282469.html