动手学深度学习 图像分类数据集(二) softmax回归的从零开始实现
动手学深度学习 图像分类数据集(二) softmax回归的从零开始实现
动手学深度学习 图像分类数据系列:
- 动手学深度学习 图像分类数据集(一) Fashion-MNIST的获取与查看
- 动手学深度学习 图像分类数据集(二) softmax回归的从零开始实现
- 动手学深度学习 图像分类数据集(三) softmax回归的简洁实现
本文的内容是介绍如何从零开始使用softmax回归完成对Fashion-MNIST的图像分类
资源均可去文末下载
1.读取数据集
具体的操作放在了上一篇文章,这里可以直接使用书本提供的 py文件
import d2lzh as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size) # 返回DataLoader类型
2.初始化模型参数
模型的输入向量长度为 784 对应2828像素的图像*
输出类型为 10 对应了10个类别
num_inputs = 784
num_outputs = 10
W = torch.tensor(np.random.normal(0, 0.01, (num_inputs, num_outputs)), dtype=torch.float32)
b = torch.zeros(num_outputs, dtype=torch.float32)
W.requires_grad_(True)
b.requires_grad_(True)
3.实现softmax运算
核心思想:
- 对每个元素做指数运算 (目的: 非负)
- 每行的元素与该行元素和相除 (目的: 和为1 相当于概率 )
def softmax(X):
X_exp = torch.exp(X)
partition = X_exp.sum(dim=1, keepdim=True)
# 这里应用了广播机制
return X_exp / partition
4.定义模型
这里的模型还是很简单的一个式子
y = x ∗ w + b y = x*w + b y=x∗w+b
torch.mm 用来计算矩阵的乘积
W 在之前定义 784 ∗ 10 784*10 784∗10
b 在之前定义 1 ∗ 10 1*10 1∗10
softmax之后 输出 1 ∗ 10 1*10 1∗10
def net(X):
return softmax(torch.mm(X.view((-1, num_inputs)), W) + b)
5.定义损失函数
gather函数用来获取样本对应的概率,其案例如下
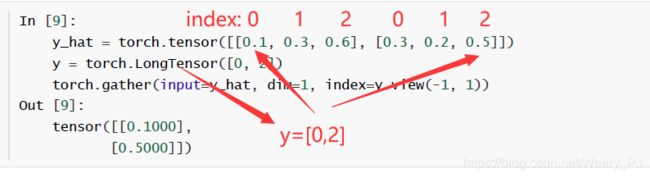
交叉熵
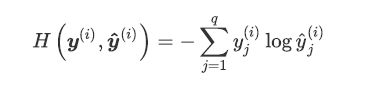
代码:
def cross_entropy(y_hat, y):
return -torch.log(y_hat.gather(1, y.view(-1, 1)))
计算分类准确率
解析:
给定一个类别的预测概率分布y_hat ,我们把预测概率最大的类别作为输出类别。如果它与真实类别y 一致,说明这次预测是正确的。分类准确率即正确预测数量与总预测数量之比。
def accuracy(y_hat, y):
return (y_hat.argmax(dim=1) == y).float().mean().item()
举例说明: 假设对于一个三分类问题,其预测值 y_hat如下 真实值y如下
[0.1000, 0.3000, 0.6000] 代表对于第一个样本, 每个类别的概率值
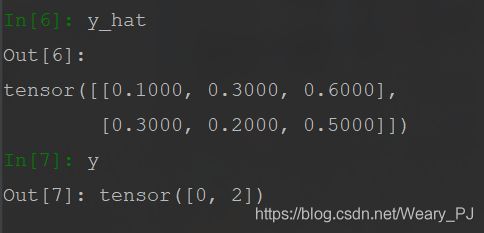
argmax(dim=1) 函数的作用是返回每一行最大值的索引
在这里 刚好标签对应的就是索引, 最大值对应的是最大概率 所以这个所以就是我们预测的标签值
y_hat.argmax(dim=1) == y判断预测值是否与真实值相等
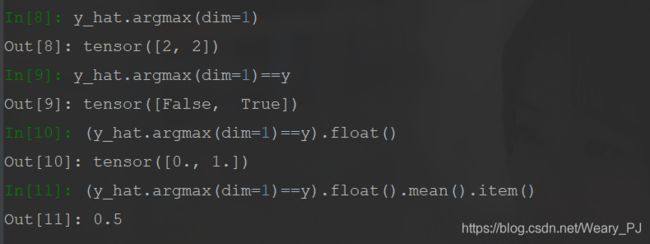
最终的结果计算出了准确率
放到本题的模型中,计算分类准确率
def evaluate_accuracy(data_iter, net):
acc_sum, n = 0.0, 0
for X, y in data_iter:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
print(evaluate_accuracy(test_iter, net))
0.0647
训练模型
# 超参数定义
num_epochs, lr = 5, 0.1
# 训练模型
def train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, params=None, lr=None, optimizer=None):
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n = 0.0, 0.0, 0
for X, y in train_iter:
y_hat = net(X)
l = loss(y_hat, y).sum()
# 梯度清零
if optimizer is not None:
optimizer.zero_grad()
elif params is not None and params[0].grad is not None:
for param in params:
param.grad.data.zero_()
l.backward()
if optimizer is None:
d2l.sgd(params, lr, batch_size)
else:
optimizer.step()
train_l_sum += l.item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item()
n += y.shape[0]
test_acc = evaluate_accuracy(test_iter, net)
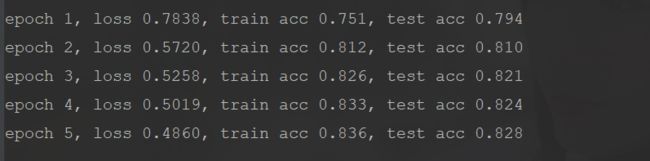
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f' % (epoch+1, train_l_sum/n, train_acc_sum/n, test_acc))
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, batch_size, [W, b], lr)
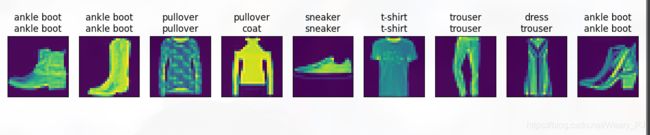
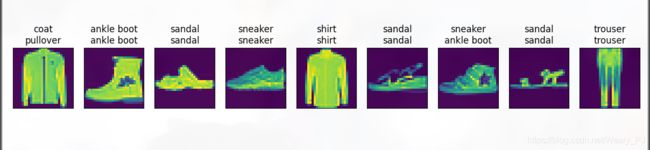
结果预测
给定一系列图像,我们比较一下它们的真实标签(第一行文本输出)和模型预测结果(第二行文本输出)
get_fashion_mnist_labels方法将标签从数字转换为文本
 下面的方法是取十个batch中的数据来查看 (显示的数据是每个batch中的前十个)
下面的方法是取十个batch中的数据来查看 (显示的数据是每个batch中的前十个)
预测的结果和实际的结果的比较
for index, (X, y) in enumerate(test_iter):
if index == 9:
break
true_labels = d2l.get_fashion_mnist_labels(y.numpy())
pred_labels = d2l.get_fashion_mnist_labels(net(X).argmax(dim=1).numpy())
titles = [true + '\n' + pred for true, pred in zip(true_labels, pred_labels)]
d2l.show_fashion_mnist(X[:9], titles[:9])
d2l.plt.show()
如果只查看第一个batch的前十张图片可以这样写
X, y = iter(test_iter).next()
结果如下, 可以看出结果还算理想,基本上都对了

全代码
d2lzh文件可以去文末链接下载
# -*- coding: utf-8 -*-
# @Time : 2021/2/11 14:47
# @Author : JokerTong
# @File : 图像分类数据集(二) softmax回归的从零开始实现.py
import d2lzh as d2l
import torch
import numpy as np
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
num_inputs = 784
num_outputs = 10
W = torch.tensor(np.random.normal(0, 0.01, (num_inputs, num_outputs)), dtype=torch.float32)
b = torch.zeros(num_outputs, dtype=torch.float32)
W.requires_grad_(True)
b.requires_grad_(True)
def softmax(X):
X_exp = torch.exp(X)
partition = X_exp.sum(dim=1, keepdim=True)
# 这里应用了广播机制
return X_exp / partition
def net(X):
return softmax(torch.mm(X.view((-1, num_inputs)), W) + b)
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
y = torch.LongTensor([0, 2])
torch.gather(input=y_hat, dim=1, index=y.view(-1, 1))
def cross_entropy(y_hat, y):
return -torch.log(y_hat.gather(1, y.view(-1, 1)))
def accuracy(y_hat, y):
return (y_hat.argmax(dim=1) == y).float().mean().item()
def evaluate_accuracy(data_iter, net):
acc_sum, n = 0.0, 0
for X, y in data_iter:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
print(evaluate_accuracy(test_iter, net))
num_epochs, lr = 5, 0.1
def train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, params=None, lr=None, optimizer=None):
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n = 0.0, 0.0, 0
for X, y in train_iter:
y_hat = net(X)
l = loss(y_hat, y).sum()
# 梯度清零
if optimizer is not None:
optimizer.zero_grad()
elif params is not None and params[0].grad is not None:
for param in params:
param.grad.data.zero_()
l.backward()
if optimizer is None:
d2l.sgd(params, lr, batch_size)
else:
optimizer.step()
train_l_sum += l.item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item()
n += y.shape[0]
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f' % (
epoch + 1, train_l_sum / n, train_acc_sum / n, test_acc))
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, batch_size, [W, b], lr)
for index, (X, y) in enumerate(test_iter):
if index == 9:
break
true_labels = d2l.get_fashion_mnist_labels(y.numpy())
pred_labels = d2l.get_fashion_mnist_labels(net(X).argmax(dim=1).numpy())
titles = [true + '\n' + pred for true, pred in zip(true_labels, pred_labels)]
d2l.show_fashion_mnist(X[:9], titles[:9])
d2l.plt.show()
引用资料来源
本文内容来自吴振宇博士的Github项目
对中文版《动手学深度学习》中的代码进行整理,并用Pytorch实现
【深度学习】李沐《动手学深度学习》的PyTorch实现已完成