Python爬虫,实现爬取静态网站数据(小白入门)
简言:
python最近越来越火了,我也跟着潮流学习了一把,今天写的就是教大家如何通过 简简单单 的二十几行代码爬取豆瓣前250名的高分电影名。

第一步:导入模块
导入我们所需要的模块,这里我们使用到的有三大模块
(导入的模块都是需要预先安装的,不知道如何安装的朋友可先移步到链接: 模块安装.)
- requests:用于访问网络资源
- lxml:用于网页的解析
- BeatifulSoup:通过解析文档为用户提供需要抓取的数据
import requests
import lxml
from bs4 import BeautifulSoup
from lxml import etree
第二步:设置请求路径
这里我们设置我们需要请求的网页路径,本次爬取的网页是豆瓣前250高分电影排行榜
链接: https://movie.douban.com/top250.
url = 'https://movie.douban.com/top250'
第三步:设置请求头
因为部分网页是不能直接通过爬虫去爬取数据的,这里我们设置请求头,来模拟我们是通过浏览器去进行的网页访问。
hread = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
'Referer': 'https://movie.douban.com/'
}
我们可以通过打开浏览器的任意网页,按F12后查看NetWork,刷新网页后,点击任意一 .js 文件查看自己浏览器的请求头。

第四步:请求网页
这里的hread就是我们刚刚设置的请求头。
response = requests.get(url, headers=hread)
第五步:解析网页
这里的response.text,是对请求网页得到的数据进行了一次类型转换,因为我们请求网页得到是reqeust类型的数据,这里必须将它转换成byte或是string类型的数据。
这里通过BeautifulSoup模块,对转换过的数据进行格式化(即将其转化成可以利用库中方法进行检索的对象)
boj = BeautifulSoup(response.text, 'lxml')
第六步:获取到网页源码中显示电影名的标签(重点)
这里我们需要打开我们要爬取数据网页,查看网页源代码,找显示电影名的标签的规律。
通过图片我们可以得知,电影名都存放在类名为 hd 下的 a 超链接中的span中

所以我们先通过find_all方法,查出网页所有类名为 hd 及它下面的子标签,
find_all会根据你的要求去查找标签参数的所有子标签,以及子标签的子标签
# 获取网页内容,hd属性下存放有电影名
# 通过find定位标签
movies_title = boj.find_all('div', class_='hd')
第七步:输出电影名
这里我们使用for循环,将所有电影名输出,因为我们在第六步中只获取到了电影名的父标签,这里我们还要往下获取电影名,这里的a.span.text.strip()就是获取到了电影名,
strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
for i in movies_title:
print(i.a.span.text.strip())
第八步:运行程序
我们运行程序后,就能得到电影名了…
然鹅
只有25个电影名是什么鬼,作者你在搞我吗?其他的名字被你吃掉了?

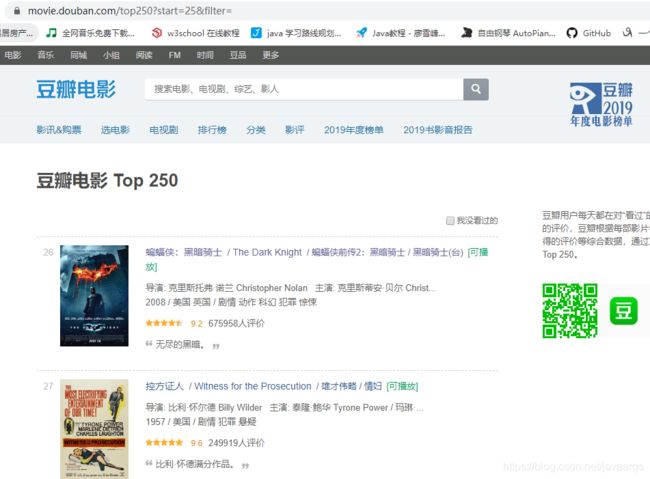
第九步:观察切换网页后的网页路径名(重点)
因为我们可以观察到,在我们请求的页面中,只有25个电影,所以我们爬取到的电影名也只有25个。所以我们要通过切换页面,观察网页路径的状态来判断如何去获取其他的电影名。
然后我们点击下面分页的数字,观察网页路径的变化。

通过点击几页路径之后,我们可以发现,点击其他的页面后,都会在路径上加上
?start= &filter=,这就是电影名的翻页规律了, start= 后面的数字的规律我们也可以很简单的发现就是每往下翻一页,这个值就会加25
第十步:改造请求路径
我们如果要爬取全部250个电影名,必须要将请求的路径从静态转变成动态。所以我们要稍微改造一下我们的代码
首先我们将我们的请求路径变成这样的带变量的拼接路径,这个url还是原来的url;
href = url + '?start=' + str(_page) + '&filter='
然后这个变量是从for循环中取出的
我们在这个改造后的路径前加上for循环,因为通过我们的观察,最后一页是225,所以不难发现,我们的循环范围就是0-9,因为python的range函数右边值是小于,所以我们写成range(0,10),然后再将循环数乘以25。
for page in range(0,10):
# 访问多页面去获取250条数据
_page = int(page) * 25
然后将,请求网页部分改成:
response = requests.get(href, headers=hread)
这个herf就是改造后的路径。其他代码不变,运行程序。
就会发现获取到了全部250个电影名,是不是特别有成就感

最后:附上全部代码
注意:Python是根据缩进来区分代码块的,一定要严格注意缩进格式噢
import requests
import lxml
from bs4 import BeautifulSoup
from lxml import etree
url = 'https://movie.douban.com/top250'
hread = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
'Referer': 'https://movie.douban.com/'
}
movies_list = list()
for page in range(0,10):
# 访问多页面去获取250条数据
_page = int(page) * 25
href = url + '?start=' + str(_page) + '&filter='
response = requests.get(href, headers=hread)
boj = BeautifulSoup(response.text, 'lxml')
movies_title = boj.find_all('div', class_='hd')
for i in movies_title:
print(i.a.span.text.strip())