reinforcement learning,增强学习:Model-Free Prediction
首先回忆上一次的内容:
对于给定的MDP,
使用Policy Evaluation进行prediction(对于给定的policy π,evaluate该policy π能够达到的Vπ(s))
使用Policy Iteration、Value Iteration进行control(没有特定的policy π,希望找到针对该MDP最优的policy π*,同时给出π*在每个状态的最优值Vπ*(s))
本次内容:
Model-Free Prediction。所谓model-free,是指没有给定MDP(即MDP未知,甚至不知道是不是MDP过程)。
希望在未给出MDP的情况下,进行prediction(对于给定的policy π,evaluate该policy π能够达到的Vπ(s))。
Model-Free Prediction有两大方法:Monte-Carlo Learning和Temporal-Difference Learning。
下次内容:
Model-Free Control。所谓model-free,是指没有给定MDP(即MDP未知,甚至不知道是不是MDP过程)。
希望在未给出MDP的情况下,进行Control(policy也没有给出,Optimise the value function of an unknown MDP )。
Monte-Carlo Learning:
1)要解决的问题:
MDP未知,但Policy π已知,希望learn Vπ from complete episodes of experience under policy π~S1,A1,R2,...,ST。
由于需要完整的(complete)experience,所以也称为offline的。
所谓complete,就是指,必须要得到真正的Gt,这意味着必须持续采取action,直到进入terminal state。
2)解决方法:
MC uses the simplest possible idea:value = empirical mean return instead of expected return

3)实际计算empirical mean return时有两种策略:
First-Visit Monte-Carlo Policy Evaluation:

Every-Visit Monte-Carlo Policy Evaluation:

4)评价:
MC methods learn directly from episodes of experience
MC is model-free: no knowledge of MDP transitions / rewards
MC learns from complete episodes(All episodes must terminate)
5)Incremental Monte-Carlo Updates

可以按照上面的式子更新,是因为:
The mean µ1, µ2, ... of a sequence x1, x2, ... can be computed incrementally,

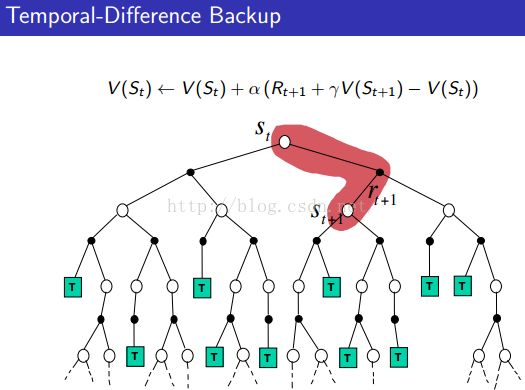
Temporal-Difference Learning:
1)要解决的问题:
MDP未知,但Policy π已知,希望learn Vπ from in-complete episodes of experience under policy π~S1,A1,R2,...,ST。
由于仅仅需要不完整的(in-complete)experience,所以也称为online的。
2)解决方法:
TD uses the simplest possible idea:value = estimated return instead of empirical mean return(MC),更不采用expected return。

3)评价:
TD methods learn directly from episodes of experience (same as MC)
TD is model-free: no knowledge of MDP transitions / rewards (same as MC)
TD learns from in-complete episodes, TD can learn before knowing the final outcome (MC learns from complete episodes, MC must wait until end of episode before return is known )
MC can only learn from complete sequences
TD works in continuing (non-terminating) environments
MC only works for episodic (terminating) environments
MC和TD(0)比较:
1)MC vs. TD例子(下面的例子能懂,就明白MC和TD了):
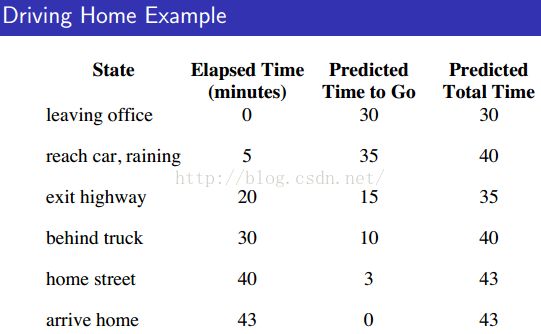
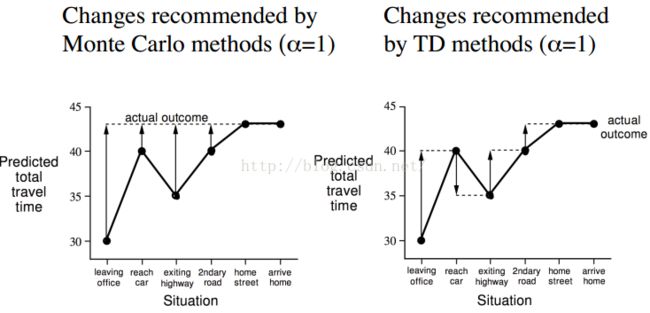
2)Batch MC and TD(0)

AB Example:
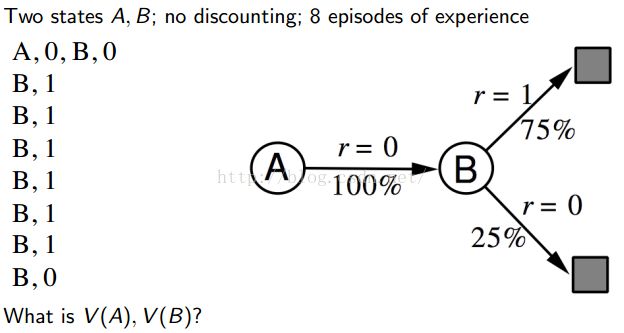

3)Advantages and Disadvantages of MC vs. TD :


TD exploits Markov property:Usually more efficient in Markov environments
MC does not exploit Markov property:Usually more effective in non-Markov environments
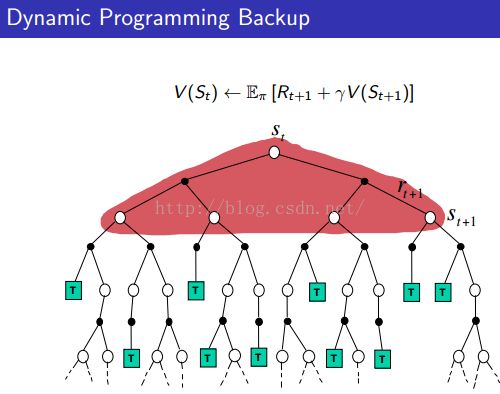
4)Unified View of MC/TD/DP: