Windows上安装运行Hadoop 最细最全 过坑 值得收藏 !!!
Windows上安装运行Hadoop 最细最全 过坑 值得收藏 !!!
Windows上安装运行Hadoop 最细最全 过坑 值得收藏 !!!
Windows上安装运行Hadoop 最细最全 过坑 值得收藏 !!!




1.下载安装JDK
并设置JAVA_HOME。一般在 c:\Program Files 路径下
JDK安装教程:https://jingyan.baidu.com/article/1709ad805318544635c4f042.html
2.下载hadoop
下载地址:http://hadoop.apache.org/releases.html
如果在当前页中没找到2.8.3版本,可以到所有版本的下载列表中去找:https://archive.apache.org/dist/hadoop/common/
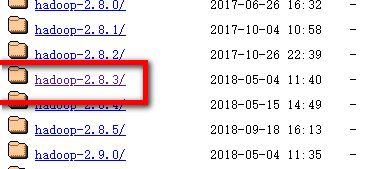
选择
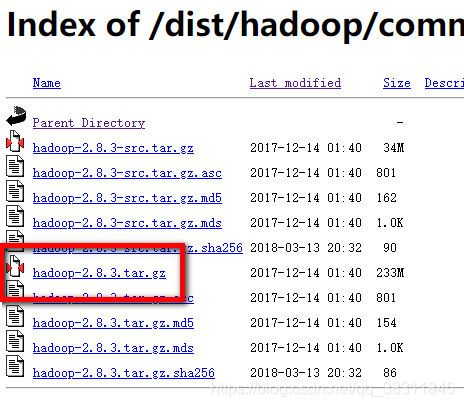
下载 hadoop-2.8.3.tar.gz 放置在 F盘 新建文件夹 hadoop2.8.3 下,并解压

3.下载winutils
下载地址:https://github.com/steveloughran/winutils

下载后,解压

进入 winutils-master, 选择自己对应的 hadoop 版本 实例为 2.8.3 版本

进入文件夹后 ,复制 bin 文件夹 !!! 复制 bin 文件夹 !!! 复制 bin 文件夹 !!!

进入之前下载 解压后的 hadoop 文件夹 hadoop-2.8.3

空白处 ==》 右击 ==》 黏贴 ==》 替换掉 bin 文件夹

4.修改配置文件
在路径F:\hadoop2.8.3\hadoop-2.8.3\etc\hadoop下修改文件
①core-site.xml(配置默认hdfs的访问端口)
只需复制黏贴即可
fs.defaultFS
hdfs://localhost:9000
②hdfs-site.xml(设置复制数为1,即不进行复制。namenode文件路径以及datanode数据路径。)
只需复制黏贴即可
dfs.replication
1
dfs.namenode.name.dir
file:/hadoop/data/dfs/namenode
dfs.datanode.data.dir
file:/hadoop/data/dfs/datanode
③将mapred-site.xml.template 名称修改为 mapred-site.xml 后再修改内容(设置mr使用的框架,这里使用yarn)
只需复制黏贴即可
mapreduce.framework.name
yarn
④yarn-site.xml(这里yarn设置使用了mr混洗)
只需复制黏贴即可
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
⑤hadoop-env.cmd
设置JAVA_HOME的值
# 将
set JAVA_HOME=%JAVA_HOME%
# 修改为
set JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_775.格式化hdfs
进入F:\hadoop2.8.3\hadoop-2.8.3\bin目录,格式化hdfs
在cmd中运行命令 hdfs namenode -format

6.运行hadoop
进入F:\hadoop2.8.3\hadoop-2.8.3\sbin目录
在cmd中运行命令start-all.cmd
出现找不到hadoop文件的错误时,
可以在start-all.cmd文件最上方加入hadoop文件所在位置目录。

会跳出很多黑框框,不要担心是正常的。会启动 4个结点,
resourcemanager
![]()
nodemanager
![]()
datanode
![]()
namenode
![]()
7.查看集群状态
在浏览器地址栏中输入:http://localhost:8088查看集群状态。
8.查看Hadoop状态
在浏览器地址栏中输入:http://localhost:50070查看Hadoop状态。
9.关闭Hadoop
执行stop-all.cmd关闭Hadoop