《数据结构》c语言版学习笔记——单链表结构(线性表的链式存储结构Part1)
线性表的链式存储结构
数据结构系列文章 第二章 单链表结构
文章目录
- 线性表的链式存储结构
- 前言
- 一、单链表的建立
-
- 代码
- 二、单链表的读取
-
- 代码
- 三、单链表的插入
-
- 代码
- 四、单链表的删除
-
- 代码
- 五、单链表的整表创建
-
- 1.头插法建立单链表
- 代码
- 2.尾插法建立单链表
- 代码
- 六、单链表的整表删除
-
- 代码
- 总结
前言
提示:本系列文章均使用Visual Studio 2019编程,编程语言为c语言。
一、单链表的建立
为了使单链表中每个数据元素与其直接后继的数据元素之间存在逻辑关系,除了存储其本身的信息之外,还需要存储一个指示其直接后继存储位置的信息(存储后继元素的存储地址,即指针)。
存储数据元素信息的域称为数据域,将存储直接后继位置的域称为指针域,其中指针域中存储的信息称为指针或链,同时这两部分信息组成数据元素的存储映像称为结点。结点由存放数据元素的数据域存放后继结点地址的指针域组成。n个结点链从而结合成一个链表,即为线性表的链式存储结构,又由于链表的每个结点中只包含一个指针域,所以称为单链表。
代码
#include 二、单链表的读取
由于单链表与线性表的顺序存储结构不一样,当我们要查找任意一个元素的存储位置时,单链表的查找得从头开始找。我们来看看怎么查找吧,可以说
单链表的读取分为以下几步:(例如读取链表中第n个元素的值)
1、首先声明一个指针p(结点)指向单链表的第一个结点,即p=L->next,同时设定一个计数器j从1开始计数;
2、开始查找,当j
4、否则,查找成功,用e返回L中第n个元素的数据;
5、返回成功。
代码
//单链表的读取
typedef int Status;
Status GetElem(LinkList L, int n, ElemType* e)
{
int j=1; //j为计数器
LinkList p; //声明一结点
p = L->next; //让p指向链表L的第一个结点
while (p &&j<n) //当p为空或者计数器j等于n时,结束循环
{
p = p->next; //让p指向下一个结点
++j;
}
if (!p || j > n)
return ERROR; //第n个元素不存在
*e = p->data; //取第n个元素的数据
return OK;
}
三、单链表的插入
对于实现单链表的插入操作,我们以以下图示来解释,我们设要插入的元素e的结点为s,我们要实现将结点s插入到结点p和p->next之间,即可以将p的后继结点改为s的后继结点,再把结点s变成p的后继结点,通过代码改变其指针实现即s->next=p->next ; p->next=s。(特别注意这两句的顺序不可写反)
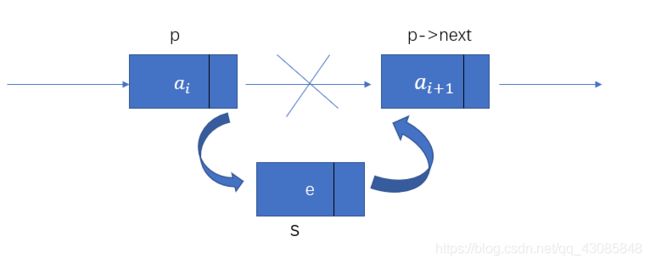
单链表的插入分为以下几步:(例如链表中第i个数据元素位置之前插入数据元素e)
1、首先声明一个指针p(结点)指向单链表的第一个结点并且声明一个空结点s,同时设定一个计数器j从1开始计数;
2、由于要找第i-1个结点,因为要插入的是第i个结点。当j
4、否则此时查找成功,此时用动态分配函数生成一个新结点s,即分配整型存储单元,并将连续的整型存储单元的首地址存储到指针变量s当中;
5、将数据元素e赋值给s->data;
6、将p结点的后缀结点赋值给s的后继并将s赋值给p的后继;
7、返回成功。
代码
//单链表的插入
typedef int Status;
Status ListInsert(LinkList* L, int i, ElemType e)
{
int j = 1;
LinkList p, s;
p = *L;
while (p && j<i) //当p为空或者计数器j等于i时,结束循环(即寻找第i个结点)
{
p = p->next;
++j;
}
if (!p || j > i)
return ERROR; //第i个元素不存在
s = (LinkList)malloc(sizeof(Node)); //malloc()是动态分配函数,用来向系统请求分配内存空间,即分配整型存储单元,并将连续的整型存储单元的首地址存储到指针变量s当中
s->data = e;
s->next = p->next; //将p的后缀结点赋值给s的后继
p->next = s; //将s赋值给p的后继
return OK;
}
四、单链表的删除
对于实现单链表的插入操作,我们以以下图示来解释,我们要删除的结点是q,只要绕过它的前继结点的指针,直接指向它的后继结点就行,即①q=p->next②p->next=q->next,我们可以用一步来描述,这一步是p->next=p->next->next。
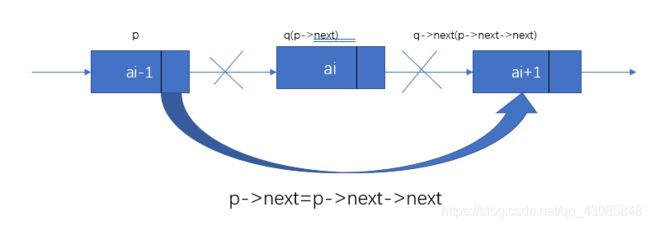
单链表的删除分为以下几步:(例如删除链表中第i个数据元素)
1、首先声明一个指针p(结点)指向单链表的第一个结点,同时设定一个计数器j从1开始计数;
2、当j
4、否则此时查找成功,将准备删除的结点p->next赋值给q;
5、执行删除操作,p->next=q->next;
6、将q结点中的数据赋给e,作为返回,用e返回其值;
7、使用free()函数,释放q结点;
8、返回成功。
代码
//单链表的删除
typedef int Status;
Status ListDelete(LinkList *L, int i, ElemType *e)
{
int j = 1;
LinkList p, q;
p = *L;
while (p->next && j < i) //遍历寻找第i个元素
{
p = p->next;
++j;
}
if (!(p->next) || j > i)
return ERROR; //第i个元素不存在
q = p->next;
p->next = q->next;
*e = q->data; //将q结点中的数据给e
free(q); //free()函数,让系统回收此结点,释放内存
return OK;
}
五、单链表的整表创建
1.头插法建立单链表
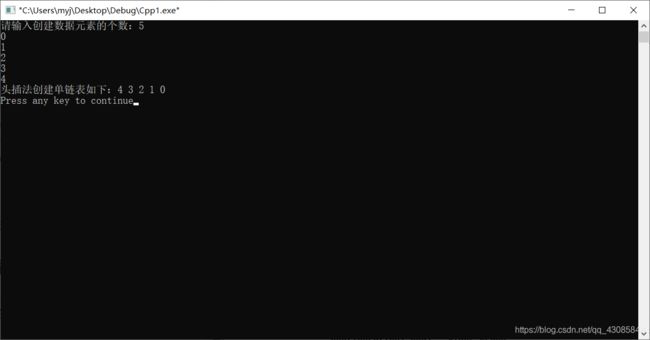
头插法创建单链表,即始终让新结点处于表中第一的位置,最后输入的元素和输出的元素顺序刚好相反。从一个空表开始,生成新结点,读取数据存放到新结点的数据域中,然后将新结点插入到当前链表的表头位置上,直到结束为止。(先让新结点的next指向头结点之后,然后让表头的next指向新结点)
代码
#include 测试输入五个数据元素:0、1、2、3、4。
(输出的顺序与输入的顺序是相反的)
2.尾插法建立单链表
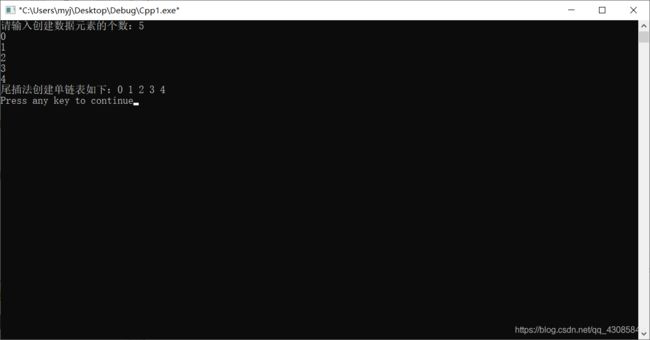
第二种方法就是尾插法,也就是将所加入的新结点全部插在终端结点的后面依次排下去,就相当于正常排队的思维来运行程序, 其中
q->next = p;这一语句即将表尾终端结点q的指针指向新的下一个结点p,然后q=p;这一语句q就相当于一个中继(是当前链表的最后结点),在进行下一个元素的创建时,q本来是上一个数据元素的结点,但后面仍有结点,所以这时应该将这个p结点(也就是当前链表的最后结点)赋值给q,此时q又是当前链表的尾结点。循环结束后q->next = NULL;即让这个链表的指针域置空,以便在之后遍历时可以知道是其当前链表尾部。
代码
#include测试输入五个数据元素:0、1、2、3、4。
(输出的顺序与输入的顺序相同)
六、单链表的整表删除
当要删除这个单链表时,即在内存中释放它时,我们给出以下算法:
1、声明一结点p和q;
2、将第一个结点赋值给p;
3、循环语句:将下一结点赋值给q,释放p,将q赋值给p。
代码
#include总结
以上就是本次的笔记内容,本文仅仅通过文字和代码简单介绍了单链表结构的各项操作,建议自己分析总结其各个操作并结合自己的编程能力选择编程语言再写一遍代码从而加深印象,可以使自己的编程能力提升,其实数据结构不难,要有心地去学习和总结,才能事半功倍,若有错误欢迎指正。
附: 在本系列下一文章会单独介绍其他链表(如:静态链表、循环链表以及双向链表)的各项操作,持续更新ing……