Apache Doris技术实践
1 Doris简述
Doris(原百度Palo)是一款基于大规模并行处理技术的分布式 SQL 数据库,由百度在2017年开源,2018年进入 Apache 孵化器。
1.1 Doris架构组成介绍
1.1.1 Doris的整体架构
Doris的架构组成主要是BackEnd,即Doris 的后端节点(以下简称BE);FrontEnd,即Doris 的前端节点(以下简称FE)和bdbje(BerkekeyDB Java Edition),负责元数据操作日志的持久化、FE 高可用等功能。
BE的磁盘空间主要用来存放用户数据,总磁盘空间按照总用户数量*3(副本数量)计算;然后再预留额外40% 的空间用作后台 compaction 以及一些中间数据的存存放。FE的磁盘空间主要用于存储元数据,包括日志和 image。通常从几百 MB 到几个 GB 不等。
一台机器上可以部署多个 BE 实例,但是只能部署一个 FE。如果需要 3 副本数据,那么至少需要 3 台机器各部署一个 BE 实例。(测试环境也可仅适用一个BE)。架构图如图1.1
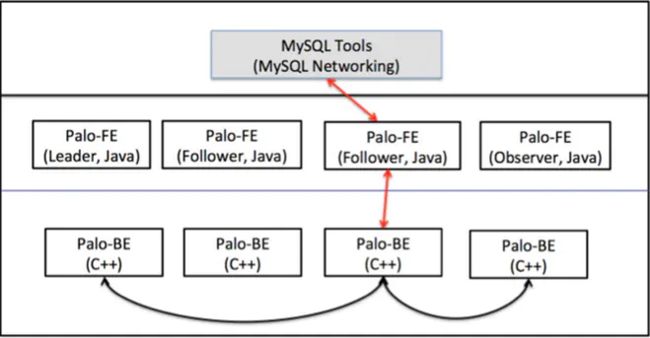
Doris 的整体架构分为两层。多个FE 组成第一层,提供 FE 的横向扩展和高可用。多个 BE 组成第二层,负责数据存储于管理。本文主要介绍 FE 这一层中,元数据的设计与实现方式。
1.1.2 FE
· FE 节点分为 follower 和 observer 两类。各个 FE 之间,通过bdbje进行leader 选举,数据同步等工作。
· follower节点通过选举,其中一个 follower 成为 leader 节点,负责元数据的写入操作。当 leader 节点宕机后,其他 follower 节点会重新选举出一个 leader,保证服务的高可用。
· observer节点仅从 leader 节点进行元数据同步,不参与选举。可以横向扩展以提供元数据的读服务的扩展性。
1.1.3 元数据
Doris 的元数据是全内存的。每个FE 内存中,都维护一个完整的元数据镜像。
Doris的元数据主要存储4类信息:
· 用户数据信息。包括数据库、表的 Schema、分片信息等。
· 各类作业信息。如导入作业,Clone 作业、SchemaChange 作业等。
· 用户及权限信息。
· 集群及节点信息。
元数据的数据流具体过程如下:
-
只有leader FE 可以对元数据进行写操作。写操作在修改 leader 的内存后,会序列化为一条log,按照 key-value 的形式写入 bdbje。其中 key 为连续的整型,作为 log id,value 即为序列化后的操作日志
-
日志写入 bdbje 后,bdbje 会根据策略(写多数/全写),将日志复制到其他 non-leader 的 FE 节点。non-leader
FE 节点通过对日志回放,修改自身的元数据内存镜像,完成与 leader 节点的元数据同步
-
leader 节点的日志条数达到阈值后(默认 10w 条),会启动 checkpoint 线程。checkpoint 会读取已有的 image 文件,和其之后的日志,重新在内存中回放出一份新的元数据镜像副本。然后将该副本写入到磁盘,形成一个新的 image。每次 checkpoint 会占用双倍内存空间。
-
image 文件生成后,leader节点会通知其他 non-leader 节点新的 image 已生成。non-leader 主动通过 http 拉取最新的 image 文件,来更换本地的旧文件
1.2 Doris特点
Doris的主要特性
· 兼容Mysql协议,支持包括多表 Join、子查询、窗口函数、CTE 在内的丰富的 SQL 语法。支持诸多常见 BI 报表系统,能极大降低用户的学习和迁移成本
· 支持高并发点查询和高吞吐的多维分析查询场景。通过分区裁剪、预聚合、谓词下推、向量化执行等技术,以及高效的列式存储引擎即数据压缩算法,满足不同业务场景下的延迟和吞吐需求。
· 特有的数据预聚合功能。支持预聚合表和基准表同步原子更新,为报表场景提供更快速的查询响应。
· 提供强大的扩展性和高可用特性。所有数据都采用多副本的方式保证数据的高可靠,同时提供全自动的副本选择、均衡和修复功能,为用户提供7*24小时的高可用数据库系统。
· 提供友好的在线表结构变更功能,能有效应对业务上的需求变化。
· 提供两级数据划分功能以及分层存储功能。用户可以更灵活地对数据进行管理和维护。
1.3 Doris的软硬件需求
| 环境名称 | 版本号 |
|---|---|
| CentOS/Ubuntu | 7.1及以上/16.04及以上 |
| Java | 1.8及以上 |
| GCC | 4.8.2及以上 |
| cmake | |
| python | 2.7及以上 |
测试环境
| 模块 | CPU | 内存 | 磁盘 | 网络 | 实例数 |
|---|---|---|---|---|---|
| FrontEnd | 8核+ | 8G+ | 10GB+ | 千兆网卡 | 1 |
| BackEnd | 8核+ | 16G+ | 50GB+ | 千兆网卡 | 1-3 |
生产环境
| 模块 | CPU | 内存 | 磁盘 | 网络 | 实例数 |
|---|---|---|---|---|---|
| FrontEnd | 16核+ | 64G+ | 100GB+ | 万兆网卡 | 1-5 |
| BackEnd | 16核+ | 64G+ | 100GB+ | 万兆网卡 | 10-100 |
· Doris的性能与节点数量及配置正相关。最少4台机器(一台 FE,三台 BE,其中一台 BE 混部一个 Observer FE 提供元数据备份)。测试环境可以只部署一台BE
· 如果 FE 和 BE 混部,需注意资源竞争问题,并保证元数据目录和数据目录分属不同磁盘
1.4 Doris各个实例通信网络端口
| 实例名称 | 端口名称 | 默认端口 | 通讯方向 | 说明 |
|---|---|---|---|---|
| BE | be_port | 9060 | FE --> BE | BE 上 thrift server 的端口,用于接收来自 FE 的请求 |
| BE | webserver_port | 8040 | BE <–> BE | BE 上的 http server 的端口 |
| BE | heartbeat_service_port | 9050 | FE --> BE | BE 上心跳服务端口(thrift),用于接收来自 FE 的心跳 |
| BE | brpc_port | 8060 | FE<–>BE, BE <–> BE | BE 上的 brpc 端口,用于 BE 之间通讯 |
| FE | http_port | 8030 | FE <–> FE,用户 | FE 上的 http server 端口 |
| FE | rpc_port | 9020 | BE --> FE, FE <–> FE | FE 上的 thrift server 端口 |
| FE | query_port | 9030 | 用户 | FE 上的 mysql server 端口 |
| FE | edit_log_port | 9010 | FE <–> FE | FE 上的 bdbje 之间通信用的端口 |
| Broker | broker_ipc_port | 8000 | FE --> Broker, BE --> Broker | Broker 上的 thrift server,用于接收请求 |
1.5 中间件版本选取
| 中间件名称 | 版本号 |
|---|---|
| CentOS | CentOS-7-x86_64-DVD-2003.iso |
| Java | 1.8.0_121 |
| Maven | 3.5.4 |
| Doris | 0.12.0 |
| cMake | 2.8.12.2 |
| python | 2.7.5 |
| gcc | 5.5.0 |
| docker | 18.03.1-ce |
2 Doris部署
2.1 环境准备
本次使用1台机器进行集群搭建,适用混编的方式在一台机器上同时部署FE和BE
2.1.1 CentOS7
CentOS7安装过程省略。Apache Doris官方要求CentOS需要在7.1版本以上。请确保虚拟机的CentOS版本符合要求。
2.1.2 关闭防火墙
针对centos7以上
1.查看防火墙状态
firewall-cmd --state
2.停止firewall
systemctl stop firewalld.service
3.禁止firewall开机启动
systemctl disable firewalld.service
针对centos7以下
1.查看防火墙状态
service iptables status
2.停止防火墙
service iptables stop
3.启动防火墙
service iptablesstart
2.1.3 关闭Swap
1.查看swap
[root@CentOS7 opt]# free
[root@CentOS7 opt]# cat /proc/vmstat |egrep "dirty|writeback"
[root@CentOS7 opt]# sysctl -wvm.swappiness=0
2.关闭swap
[root@CentOS7 opt]# echo"vm.swappiness = 0">> /etc/sysctl.conf
[root@CentOS7 opt]# swapoff -a
3.检查swap关闭

2.1.4 HostName设置
[root@CentOS7]# hostname -s
CentOS7
2.1.5 安装JDK
1.解压jdk1.8的安装包,并配置JAVA的环境变量
[root@CentOS7~]# vi /etc/profile.d/jdk.sh
#JAVA_HOME
exportJAVA_HOME=/opt/java/jdk1.8.0_121
exportJRE_HOME=$JAVA_HOME/jre
exportPATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
2.添加环境变量,刷新文件使其生效
[hadoop@hadoop04~]$ /etc/profile.d/jdk.sh
3.查阅是否安装成功

2.1.6 安装JCC
1.解压GCC5.5的安装包,并在环境变量中配置gcc
[root@CentOS7 ~]# vi ~/.bash_profile
export CC=/usr/local/bin/gcc
export CXX=/usr/local/bin/g++
2.安装GCC的依赖包:
yum -y install gmp-devel
yum -y install mpfr-devel
yum -y install libmpc-devel
yum -y install bzip2
3.进入到gcc的解压目录,执行配置:
[root@CentOS7 gcc-5.5.0]# cd /opt/gcc-5.5.0/
[root@CentOS7 gcc-5.5.0]#./configure--enable-checking=release --enable-languages=c,c++ --disable-multilib
[root@CentOS7 gcc-5.5.0]#export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib
#--disable-multilib 不产生32位的编译器
4.编译、安装:
[root@CentOS7 gcc-5.5.0]# make -j 4
[root@CentOS7 gcc-5.5.0]# make install
5.查看安装结果(如果版本号依然是CentOS自带的4.8,请检查环境变量设置):

参考链接:Linux安装gcc 7.3.0编译器详解(CentOS 7 64位系统)
2.1.7 安装Docker
1.指定docker版本安装即可
[root@CentOS7opt]# yum install docker-ce-18.03.1.ce
2.安装完成之后查看docker版本
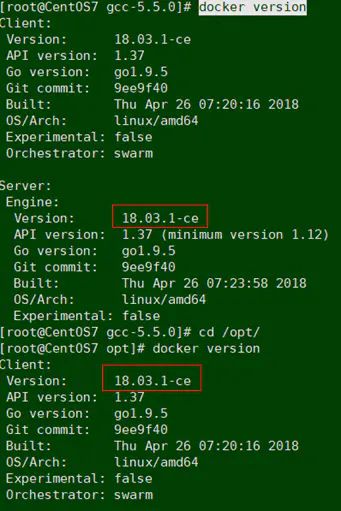
3.启动docker
[root@CentOS7opt]# systemctl start docker
4.设置开机自启
[root@CentOS7opt]# systemctl enable docker
2.1.8 安装mysql
- 下载mysql rpm包到/opt/package
- 安装mysql服务端
[root@CentOS7 package]# rpm -ivhMySQL-server-5.6.24-1.el6.x86_64.rpm
查看初始密码:
[root@CentOS7 mysql]# cat/root/.mysql_secret
查看mysql服务状态并启动
[root@CentOS7 package]# service mysqldstatus
##如果报错Unit mysqld.service could not be found.请查找mysql.server然后复制到/etc/init.d/mysqld
[root@CentOS7 mysql]# cp mysql.server/etc/init.d/mysqld
- 安装mysql客户端
[root@CentOS7 package]# rpm -ivhMySQL-client-5.6.24-1.el6.x86_64.rpm
使用查询到的初始密码登陆客户端
[root@CentOS7 package]# mysql -uroot-pMabbdrdTaRv0Gywq
修改密码:
mysql> SET PASSWORD=PASSWORD('000000');
2.2 Doris安装
2.2.1 环境检查
- 检查Java版本,$JAVA_HOME
- 检查Python版本
- 检查docker版本
- 检查GCC版本
2.2.2 Doris编译
网上有很多教程指导Doris的编译,众多的信息反而让人摸不清头脑,这里使用官网推荐的模拟docker镜像的镜像的方式编译Doris
官方链接
- 下载docker镜像(先确保安装docker)
docker pullapachedoris/doris-dev:build-env-1.2
# doris-dev:build-env-1.2 对应的是0.12.0版本Doris的镜像
- 检查镜像docker images

- 运行镜像
docker run -it apachedoris/doris-dev:build-env-1.2 - 下载源码
git clonehttps://github.com/apache/incubator-doris.git
- 找到下载源码的路径编译
find ./ -name build.sh
#这里通过Doris源码中的编译脚本去搜索下载源码的路径
- 到源码的路径下执行编译脚本
sh .build.sh
#这里编译的时候很长,如果失败了,需要删掉编译的目录重新编译(建议备份下载的源码,编译失败删除源码重新编译即可)
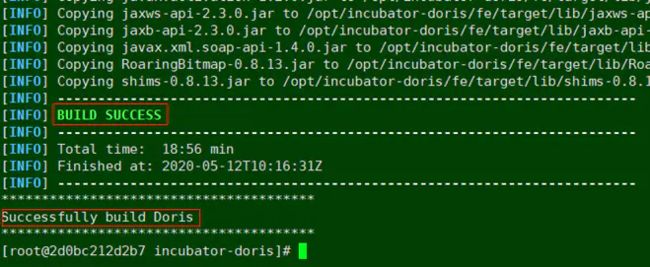
见到这张图就说明编译成功了
2.2.3 部署和启动FE
-
修改/conf/fe.conf中的meta_dir,指定元数据存放的位置
默认是${DORIS_HOME}/doris-meta 需要手动创建 -
修改FE节点IP
[root@CentOS7 fe]# vi ./conf/fe.conf
#priority_networks 设置成FE所在节点的IP
- 启动FE
[root@CentOS7 fe]# sh bin/start_fe.sh –daemon
#发生错误请通过查看fe/log/fe.log 或者 fe/log/fe.out 查看错误信息
#################FE配置#####################
# INFO, WARN, ERROR, FATAL
sys_log_level = INFO
# store metadata, create it if it is notexist.
meta_dir =/opt/doris/output/fe/palo-meta
http_port = 8030
#UI端口
rpc_port = 9020
query_port = 9030
edit_log_port = 9010
mysql_service_nio_enabled = true
priority_networks =CentOS7/24
#需要加上网关
4.在mysql中连接FE
#连接
[root@CentOS7 ~]# mysql -h CentOS7 -P 9030 -uroot
#添加BE
mysql> ALTER SYSTEM ADD BACKEND'CentOS7:9050';
2.2.4 部署和启动BE
-
修改/conf/be.conf中的storage_root_path,指定数据存放的位置
多目录使用;分隔,最后一个目录不加; -
添加BE节点
mysql连接FE:mysql -h CentOS7 -P 9030 -uroot
添加BE:ALTER SYSTEMADD FREE BACKEND “host:9050”;
host为BE所在节点
- 启动BE
[root@CentOS7 be]# sh bin/start_be.sh –daemon
#################FE配置
# INFO, WARNING, ERROR, FATAL
sys_log_level = INFO
# ports for admin, web, heartbeat service
be_port = 9060
be_rpc_port = 9070
webserver_port = 8040
heartbeat_service_port = 9050
brpc_port = 8060
priority_networks =CentOS7/24
#同理,需要加上网关
2.3 安装检查
1.mysql连接FE
2.界面访问
http://CentOS7:8030/api/bootstrap
3 DORIS操作说明
3.1 DORIS配置项
3.1.1 静态配置
修改conf/fe.conf或者conf/be.conf配置文件
3.1.2 动态配置
FE 启动后,可以通过以下命令动态设置配置项。该命令需要管理员权限。
ADMIN SET FRONTEND CONFIG ("fe_config_name" = "fe_config_value");
通过 ADMIN SHOW FRONTEND CONFIG; 命令结果中的 IsMutable 列查看是否支持动态配置
3.1.3 配置项列表
http://doris.apache.org/master/zh-CN/administrator-guide/config/fe_config.html#%E9%85%8D%E7%BD%AE%E9%A1%B9%E5%88%97%E8%A1%A8
http://doris.apache.org/master/zh-CN/administrator-guide/config/be_config.html#%E9%85%8D%E7%BD%AE%E9%A1%B9%E5%88%97%E8%A1%A8
3.2 DORIS操作
3.2.1 添加BE
见2.2.2
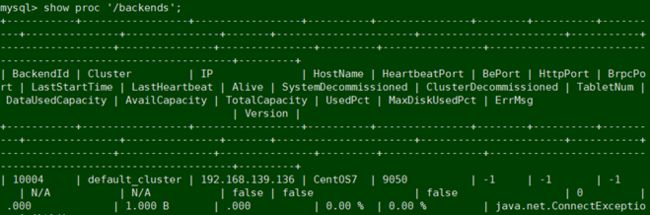
3.2.2 查询BE
mysql> show proc '/backends';
3.2.3 删除BE
mysql> ALTER SYSTEM DROP BACKEND "CentOS7:9050";
ERROR 1064 (HY000): errCode = 2, detailMessage = It is highly NOT RECOMMENDED to use DROP BACKEND stmt.It is not safe to directly drop a backend. All data on this backend will be discarded permanently. If you insist, use DROPP BACKEND stmt (double P).
mysql> ALTER SYSTEM DROPP BACKEND "CentOS7:9050";
Query OK, 0 rows affected (0.01 sec)
3.2.4 删除FE
mysql> ALTER SYSTEM DROPP FOLLOWER "CentOS7:9050";
3.3 数据库操作
3.3.1 修改默认用户的密码
默认用户root/admin:
mysql> set password for 'admin' = PASSWORD('000000');
修改完成之后可以访问页面查看系统信息
http://CentOS7:8030/system
3.3.2 创建数据库
mysql> create database doris;
3.3.3 创建用户
mysql> create user 'doris' identified by '000000';
3.3.4 授权用户
mysql> grant all on doris to doris;
3.3.5 创建表
Doris支持支持单分区和复合分区两种建表方式。
在复合分区中:
• 第一级称为 Partition,即分区。用户可以指定某一维度列作为分区列(当前只支持整型和时间类型的列),并指定每个分区的取值范围。
• 第二级称为 Distribution,即分桶。用户可以指定一个或多个维度列以及桶数对数据进行 HASH 分布。
以下场景推荐使用复合分区
• 有时间维度或类似带有有序值的维度,可以以这类维度列作为分区列。分区粒度可以根据导入频次、分区数据量等进行评估。
• 历史数据删除需求:如有删除历史数据的需求(比如仅保留最近N 天的数据)。使用复合分区,可以通过删除历史分区来达到目的。也可以通过在指定分区内发送 DELETE 语句进行数据删除。
• 解决数据倾斜问题:每个分区可以单独指定分桶数量。如按天分区,当每天的数据量差异很大时,可以通过指定分区的分桶数,合理划分不同分区的数据,分桶列建议选择区分度大的列。
用户也可以不使用复合分区,即使用单分区。则数据只做 HASH 分布
单分区建表
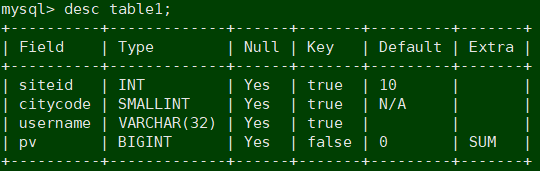
CREATE TABLE table1
(
siteid INT DEFAULT '10',
citycode SMALLINT,
username VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(siteid, citycode, username)
DISTRIBUTED BY HASH(siteid) BUCKETS 10
PROPERTIES("replication_num" = "1");
这个表的 schema 如下:
• siteid:类型是INT(4字节), 默认值为10
• citycode:类型是SMALLINT(2字节)
• username:类型是VARCHAR, 最大长度为32, 默认值为空字符串
• pv:类型是BIGINT(8字节), 默认值是0; 这是一个指标列, Doris内部会对指标列做聚合操作, 这个列的聚合方法是求和(SUM)
复合分区建表
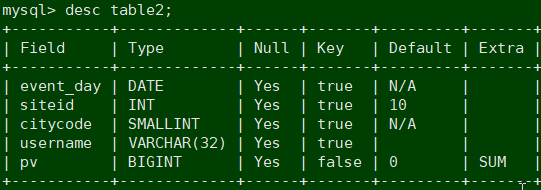
CREATE TABLE table2
(
event_day DATE,
siteid INT DEFAULT '10',
citycode SMALLINT,
username VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(event_day, siteid, citycode, username)
PARTITION BY RANGE(event_day)
(
PARTITION p201706 VALUES LESS THAN ('2017-07-01'),
PARTITION p201707 VALUES LESS THAN ('2017-08-01'),
PARTITION p201708 VALUES LESS THAN ('2017-09-01')
)
DISTRIBUTED BY HASH(siteid) BUCKETS 10
PROPERTIES("replication_num" = "1");
这个表的 schema 如下:
• event_day:类型是DATE,无默认值
• siteid:类型是INT(4字节), 默认值为10
• citycode:类型是SMALLINT(2字节)
• username:类型是VARCHAR, 最大长度为32, 默认值为空字符串
• pv:类型是BIGINT(8字节), 默认值是0; 这是一个指标列, Doris 内部会对指标列做聚合操作, 这个列的聚合方法是求和(SUM)
我们使用 event_day 列作为分区列,建立3个分区: p201706, p201707, p201708
• p201706:范围为 [最小值, 2017-07-01)
• p201707:范围为 [2017-07-01, 2017-08-01)
• p201708:范围为 [2017-08-01, 2017-09-01)
注意区间为左闭右开。
每个分区使用 siteid 进行哈希分桶,桶数为10
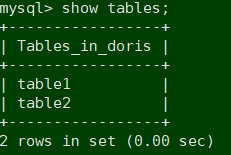
3.3.6 查看表
mysql> show tables;
mysql> desc table1;
mysql> desc tables2;
3.3.7 分区
在0.12.0版本中添加了临时分区的功能。只有分区表能建临时分区,归属于某一分区表
#添加临时分区
#可以通过 ALTER TABLE ADD TEMPORARY PARTITION 语句对一个表添加临时分区
mysql> ALTER TABLE table1 ADD TEMPORARY PARTITION tp1 VALUES LESS THAN("2020-02-01");
mysql> ALTER TABLE table1 ADD TEMPORARY PARTITION tp1 VALUES [("2020-01-01"), ("2020-02-01"));
mysql> ALTER TABLE table1 ADD TEMPORARY PARTITION tp1 VALUES LESS THAN("2020-02-01")
("in_memory" = "true", "replication_num" = "1")
DISTRIBUTED BY HASH(k1) BUCKETS 5;
#删除临时分区
#可以通过 ALTER TABLE DROP TEMPORARY PARTITION 语句删除一个表的临时分区
mysql> ALTER TABLE table1 DROP TEMPORARY PARTITION tp1;
#替换分区
#可以通过 ALTER TABLE DROP TEMPORARY PARTITION 语句删除一个表的临时分区
mysql> ALTER TABLE tbl1 REPLACE PARTITION (p1) WITH TEMPORARY PARTITION (tp1);
mysql> ALTER TABLE tbl1 REPLACE PARTITION (p1, p2) WITH TEMPORARY PARTITION (tp1, tp2, tp3);
mysql> ALTER TABLE tbl1 REPLACE PARTITION (p1, p2) WITH TEMPORARY PARTITION (tp1, tp2)
PROPERTIES (
"strict_range" = "false",
"use_temp_partition_name" = "true"
);
3.3.8 表结构变更
类似于mysql
• 增加列
• 删除列
• 修改列类型
• 改变列顺序
#增加列
mysql> ALTER TABLE table1 ADD COLUMN uv BIGINT SUM DEFAULT '0' after pv;
#查看修改
mysql> SHOW ALTER TABLE COLUMN;
#取消正在执行的作业
CANCEL ALTER TABLE COLUMN FROM table1
3.3.9 其他常用模命令
#drop
• 使用 Drop 操作直接删除数据库或表后,可以通过 Recover 命令恢复数据库或表(限定时间内),但临时分区不会被恢复。
• 使用 Alter 命令删除正式分区后,可以通过 Recover 命令恢复分区(限定时间内)。操作正式分区和临时分区无关。
• 使用 Alter 命令删除临时分区后,无法通过 Recover 命令恢复临时分区。
#truncate
• 使用 Truncate 命令清空表,表的临时分区会被删除,且不可恢复。
• 使用 Truncate 命令清空正式分区时,不影响临时分区。
• 不可使用 Truncate 命令清空临时分区。
#alter
• 当表存在临时分区时,无法使用 Alter 命令对表进行 Schema Change、Rollup 等变更操作。
• 当表在进行变更操作时,无法对表添加临时分区。
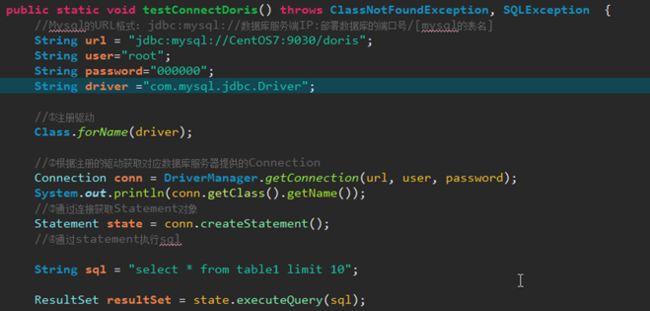
3.4 通过JDBC访问DORIS
doris可以直接使用JDBC编程的方式访问:
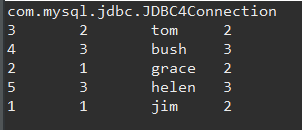
查询结果:
3.5 导入数据
3.5.1 Broker load
通过 Broker 进程访问并读取外部数据源(如 HDFS)导入到 Doris。用户通过 Mysql 协议提交导入作业后,异步执行。通过 SHOW LOAD 命令查看导入结果。
3.5.2 Stream load
用户通过 HTTP 协议提交请求并携带原始数据创建导入。主要用于快速将本地文件或数据流中的数据导入到 Doris。导入命令同步返回导入结果。
[root@CentOS7 data]# curl --location-trusted -u root:000000 -T table1.txt -XPUT http://CentOS7:8030/api/doris/tables1/_stream_load
3.5.3 Insert
类似 MySQL 中的 Insert 语句,Doris 提供 INSERT INTO tbl SELECT …; 的方式从 Doris 的表中读取数据并导入到另一张表。或者通过 INSERT INTO tbl VALUES(…); 插入单条数据
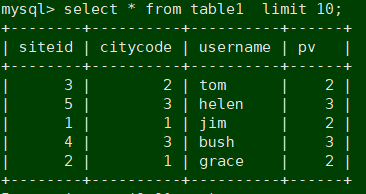
mysql> insert into table1 values(5,3,'helen',3);
3.5.4 Multi load
用户通过 HTTP 协议提交多个导入作业。Multi Load 可以保证多个导入作业的原子生效
3.5.5 Routine load
用户通过 MySQL 协议提交例行导入作业,生成一个常驻线程,不间断的从数据源(如 Kafka)中读取数据并导入到 Doris 中
3.5.6 数据导入场景说明
用户在接入 Doris 导入时,一般会采用程序接入的方式,这样可以保证数据被定期的导入到 Doris 中。下面主要说明了程序接入 Doris 的最佳实践。
- 选择合适的导入方式:根据数据源所在位置选择导入方式。例如:如果原始数据存放在 HDFS 上,则使用 Broker load 导入。
- 确定导入方式的协议:如果选择了 Broker load 导入方式,则外部系统需要能使用 MySQL 协议定期提交和查看导入作业。
- 确定导入方式的类型:导入方式为同步或异步。比如 Broker load 为异步导入方式,则外部系统在提交创建导入后,必须调用查看导入命令,根据查看导入命令的结果来判断导入是否成功。
- 制定 Label 生成策略:Label 生成策略需满足,每一批次数据唯一且固定的原则。这样 Doris 就可以保证 At-Most-Once。
- 程序自身保证 At-Least-Once:外部系统需要保证自身的 At-Least-Once,这样就可以保证导入流程的 Exactly-Once。
几种导入方式的比较:
3.5.7 参数说明
FE配置:
stream_load_default_timeout_second
导入任务的超时时间(以秒为单位),导入任务在设定的 timeout 时间内未完成则会被系统取消,变成 CANCELLED;默认的 timeout 时间为 600 秒。如果导入的源文件无法在规定时间内完成导入,用户可以在 stream load 请求中设置单独的超时时间。
BE配置:
streaming_load_max_mb
Stream load 的最大导入大小,默认为 10G,单位是 MB
3.6 查询操作
3.6.1 数据查询
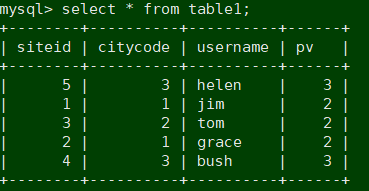
3.6.2 数据表查询
#查询表的内存限制
mysql> SHOW VARIABLES LIKE "exec_mem_limit";
exec_mem_limit 的单位是 byte,可以通过 SET 命令改变 exec_mem_limit 的值。如改为 8GB。
mysql> SET exec_mem_limit = 8589934592;
3.6.3 查询超时
#默认查询时间为 300 秒,超时会被 Doris 系统 cancel 掉
mysql> SHOW VARIABLES LIKE "%query_timeout%";
#设置超时时间,单位s
mysql> SET query_timeout = 60;
• 当前超时的检查间隔为 5 秒,所以小于 5 秒的超时不会太准确。
• 以上修改同样为 session 级别。可以通过 SET GLOBAL 修改全局有效
3.6.4 Broadcast/Shuffle Join
Broadcast(默认查询方式)
将小表进行条件过滤后,将其广播到大表所在的各个节点上,形成一个内存 Hash 表,然后流式读出大表的数据进行Hash Join。但是如果当小表过滤后的数据量无法放入内存的话,此时 Join 将无法完成,通常的报错应该是首先造成内存超限
mysql> select sum(table1.pv) from table1 join table2 where table1.siteid = 2;
#显示指定使用BroadCast
mysql> select sum(table1.pv) from table1 join [broadcast] table2 where table1.siteid = 2;
Shuffle Join
也称作 Partitioned Join。即将小表和大表都按照 Join 的 key 进行 Hash,然后进行分布式的 Join。这个对内存的消耗就会分摊到集群的所有计算节点上
#显示指定使用Shuffle Join
mysql> select sum(table1.pv) from table1 join [shuffle] table2 where table1.siteid = 2;
3.7 备份与恢复
数据备份功能只支持版本0.8.2+
Doris 支持将当前数据以文件的形式,通过 broker 备份到远端存储系统中。之后可以通过 恢复 命令,从远端存储系统中将数据恢复到任意 Doris 集群。
使用该功能,需要部署对应远端存储的 broker。如 BOS、HDFS 等。可以通过 SHOW BROKER; 查看当前部署的 broker
3.7.1 backup备份
将指定表或分区的数据,直接以 Doris 存储的文件的形式,上传到远端仓库中进行存储。当用户提交 Backup 请求后,系统内部会做如下操作:
• 快照及快照上传
快照阶段会对指定的表或分区数据文件进行快照。之后,备份都是对快照进行操作。在快照之后,对表进行的更改、导入等操作都不再影响备份的结果。快照只是对当前数据文件产生一个硬链,耗时很少。快照完成后,会开始对这些快照文件进行逐一上传。快照上传由各个 Backend 并发完成。
• 元数据准备及上传
数据文件快照上传完成后,Frontend 会首先将对应元数据写成本地文件,然后通过 broker 将本地元数据文件上传到远端仓库。完成最终备份作业
3.7.2 restore恢复
需要指定一个远端仓库中已存在的备份,然后将这个备份的内容恢复到本地集群中。当用户提交 Restore 请求后,系统内部会做如下操作:
• 在本地创建对应的元数据
这一步首先会在本地集群中,创建恢复对应的表分区等结构。创建完成后,该表可见,但是不可访问。
• 本地snapshot
这一步是将上一步创建的表做一个快照。这其实是一个空快照(因为刚创建的表是没有数据的),其目的主要是在 Backend 上产生对应的快照目录,用于之后接收从远端仓库下载的快照文件。
• 下载快照
远端仓库中的快照文件,会被下载到对应的上一步生成的快照目录中。这一步由各个 Backend 并发完成。
• 生效快照
快照下载完成后,我们要将各个快照映射为当前本地表的元数据。然后重新加载这些快照,使之生效,完成最终的恢复作业
3.7.3 常用命令
#REATE REPOSITORY
创建一个远端仓库路径,用于备份或恢复。该命令需要借助 Broker 进程访问远端存储,不同的 Broker 需要提供不同的参数
#BACKUP
执行一次备份操作
#SHOW BACKUP
查看最近一次backup的执行情况
#SHOW SNAPSHOT
查看远端仓库存在的备份
#RESTORE
执行一次恢复操作
#SHOW RESTORE
查看最近一次restore的执行情况
#CANCEL BACKUP
取消正在执行的backup操作
#CANCEL RESTORE
取消正在执行的restore操作
#DROP REPOSITORY
删除已创建的远端仓库。仅仅是删除该仓库在 Doris 中的映射,不会删除实际的仓库数据
3.8 监控和报警
Doris 使用 Prometheus 和 Grafana 进项监控项的采集和展示
省略。
4 DORIS应用场景
4.1 DORIS添加KAFKA实时数据流
4.1.1 doris订阅kafka
使用routine load的方式将kafka中的数据实时的导入到doris中。
1、Doris内部支持订阅 Kafka 数据流,实现直接对接 Kafka:
CREATE ROUTINE LOAD my_job ON db1.tbl1
COLUMNS DETERMINATED BY ','
COLUMNS (k1,k2,v1,v2,v3 = day(k1))
FROM KAFKA
(
"kafka_broker_list" = "xxx"
"kafka_topic" = "topic"
)
2、用户数据源经 Kafka 消息队列收集后,可以依次进入到 Doris 中,通过 Doris 做报表展示和决策分析等工作
4.1.2 保证数据不丢失
精确记录 Kafka 消费的 Offset,只有在确认 Kafka 消息成功被 Doris 消费时,对应的 Kafka 消息才会在 Mysql Meta 中被标记为 Committed
4.1.3 保证数据不重复
- Label 生成策略:Label 生成策略需满足,每一批次数据唯一且固定的原则。这样 Doris 就可以保证 At-Most-Once
- 在Doris进行去重操作。
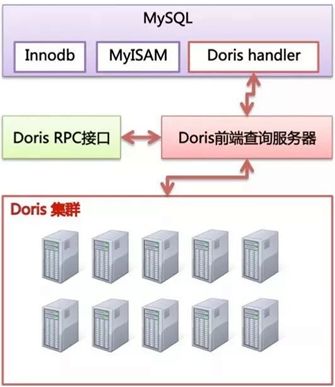
4.2 MYSQL+DORIS
将 Doris伪装成一个 MySQL 的存储后端,类似于 MyISAM、InnoDB 一样。这样既能够利用上 MySQL 对于 SQL 的支持,也能利用上 Doris对于大数据量的支持。由于这里 MySQL 是计算单点,为了减轻 MySQL 的计算压力,Doris 应用了 MySQL 的 BKA(Batched Key Access)以及 MRR(Multi-Range Read)等机制尽量将计算下推到 Doris来完成,从而减轻 MySQL 的计算压力
架构图如下:
4.3 HDFS+DORIS
使用broker load的方式将hdfs中的数据导入到Doris中。依赖broker。
-
fs-site.xml 把你集群对应的内容写进去
-
添加borker节点
mysql> ALTER SYSTEM ADD BROKER broker1 "hdfs_host:8000";
- 查看broker
mysql> SHOW PROC “/brokers”;
- Broker load 创建导入语句
mysql> LOAD LABEL db1.label1
(
DATA INFILE("hdfs://abc.com:8888/user/palo/test/ml/file1")
INTO TABLE tbl1
COLUMNS TERMINATED BY ","
(tmp_c1,tmp_c2)
SET
(
id=tmp_c2,
name=tmp_c1
),
DATA INFILE("hdfs://abc.com:8888/user/palo/test/ml/file2")
INTO TABLE tbl2
COLUMNS TERMINATED BY ","
(col1, col2)
where col1 > 1
)
WITH BROKER 'broker'
(
"username"="user",
"password"="pass"
)
PROPERTIES
(
"timeout" = "3600"
);
4.4 DORIS在EASTICSEARCH中的应用
1、ES 的优点是索引,可支持多列索引,甚至可支持全文语义索引(如 term,match,fuzzy 等);然而其缺点是没有分布式计算引擎,不支持 join 等操作
2、与 ES 相反,Palo 具备丰富的 SQL 计算能力,以及分布式查询能力;然而其索引性能较低,不支持全文索引。
3、Doris 在 ES 开发的过程中,分别借鉴 ES 和 Palo 的长处,支持了 Elasticsearch 多表 Join 操作,同时引入 Elasticsearch 的语义搜索功能,扩充了 Doris 的查询能力。
使用方式:
第一步:建立一张 ES 的外部表。
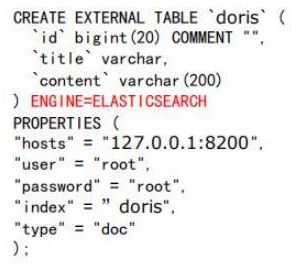
第二步:在 ES 外部表中导入一些数据:

第三步:使用和 ES 一样的搜索语句,进行全文检索查询:

4.5 DORIS个人感受
从个人的使用中,我觉得DORIS比较适合实时/离线的业务数据的计算。
首先从计算方面将,Doris兼容sql协议,让它能很好的处理业务库中的关系型数据,然后它的缺点就在于对非关系型数据的处理了,因为doris实际上也是以表作为处理单位的。
其次说说Doris的存储。Doris的存储十分类似于HDFS,分为FE和BE两个组件。FE负责存储元数据,BE负责实际的数据存储。但是从官网的介绍来看,它的功能又没有HDFS那么强大,至少不能像HDFS那样创建目录,这样就没法做到数据的分层管理,只能是存储。这个地方就有点类似于HBASE了。但是又和HBASE有一些不同,HBASE支持的数据存储方式更加灵活,Doris对数据的计算又更加方便。
再说说Doris的数据导入问题。Doris支持的五种两类数据导入方式,大概就是流式、http方式的文件还有insert into了。方式多种多样基本能覆盖kafka、hdfs、mysql等作为数据上游。但是从官方的介绍来看,doris的数据导入是有一个弊端的,就是导入数据的部分异常,可能会导致整个任务的失败:

从以上几点来看,个人认为DORIS比较合适的场景架构是mysql -> sqoop/canal ->kafka -> [hdfs] -> Doris。其中Doris在架构中扮演的角色是作为实时查询的计算引擎。Doris的insert into TableName select […]的导数据的方式,可以建立新表专门用来存储计算的结果;
但是当数据量超过PB级别的时候,官方还是建议使用Hive。
4.6 DORIS在美团点评的实践
参考链接:
https://blog.bcmeng.com/post/meituan-doris.html
4.6.1 美团外卖Doris实践概述
Apache Doris已经在百度,美团,京东,小米等互联网期中中广泛使用。在这里只简单介绍下Doris与美团外卖的准实时数仓。
美团外卖Doris准实时数仓结构图如下:
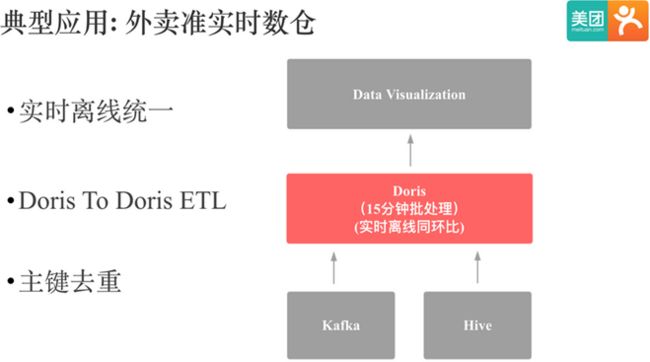
上图是Doris在美团外卖准实时数仓中应用的简单架构。数据会从kafka和hive中进入Doris,然后每 15 分钟会通过 Doris to Doris ETL 计算实时和离线的同环比(外卖的特殊业务需求)。
这个应用中主要依赖了 Doris 以下特性:
• 同时支持实时和离线数据导入。
• Doris To Doris ETL, 这个指的是 Doris insert into select 的功能
• 还有一个是主键去重,建模时用的是 Doris 的 UNIQUE KEY 模型,Doris 的主键去重和主键更新也是我们用户广泛使用的功能。
另外,帖子中还对比了Storm实时数仓和Doris准实时数仓的开发效率:
| 生产模式 | 开发效率 | 运维成本 |
|---|---|---|
| Storm实时 | 20人日 | 代码运维成本高 |
| Doris准实时 | 10人日 | SQL运维成本低 |
源于Doris对SQL协议的兼容,Doris的开发效率要远远高于Storm。
4.6.2 美团外卖Doris准实时数仓平台建设
美团外卖的Doris数仓建设大致分两条线:hive to doris 和 kafka to doris。
Hive To Doris
流程示意图:
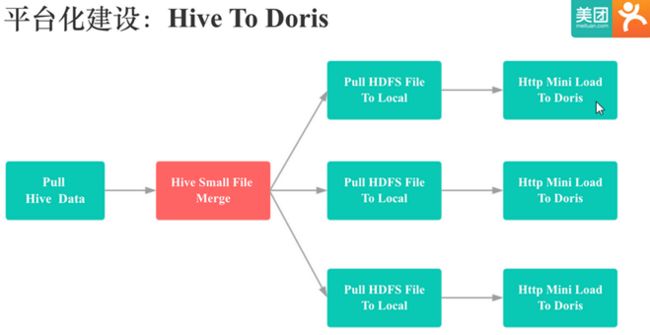
Hive To Doris 是基于 Doris 的 Http mini load 实现的。首先会用 Hive 客户端将 Hive 表数据经过过滤,Null 值处理,格式转换,Split 后存储到 HDFS 上,然后多线程从 HDFS 将数据拉取到本地,紧接着将数据通过 Http 方式导入到 Doris 中。
Doris HTTP mini Load 对单次导入文件的大小是有限制的。这里分享这个 Hive 小文件合并过程,是用 Hive 小文件合并解决了大文件 Split 的问题,可以利用 MR 来分布式 Split,让 Split 过程十分高效:
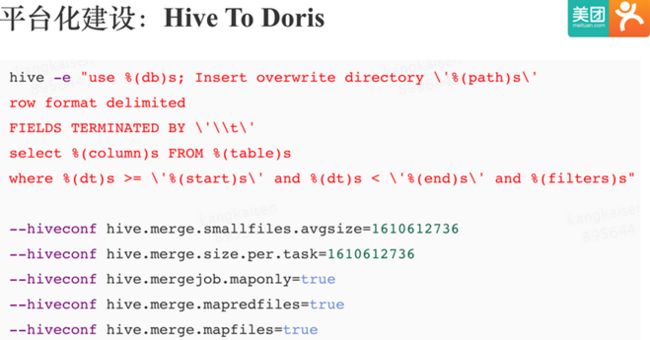
这里需要注意的一点是,在极端情况下,有些 ORC 格式存储的 Hive 表压缩比很高,导致第一步MR的单个 Mapper 输出文件大小达到好几 G,进而无法触发 Hive 小文件合并过程。 解决方法可以调大 Doris BE 的mini_load_max_mb参数,或者让用户修改 Hive 表存储格式。
Kafka To Doris
流程示意图:

• 不丢 是通过 Mysql 记录 Kafka Offsets 来 保证的,只有确认 Kafka 的一批数据已经被 Doris 成功消费后,才会更新 mysql 中 Kafka 的 offsets。
• 不重 是通过 Doris 的 label 机制保证的,前面提到 Doris 内部的事务机制可以保证同一个 Label 的导入只会成功提交一次。
5 DORIS FAQS
5.1 安装GCC之后版本号仍然是CENTOS7默认的4.8
修改环境变量GCC:
[root@CentOS7 ~]# vi ~/.bash_profile
export CC=/usr/local/bin/gcc
export CXX=/usr/local/bin/g++
5.2 安装MYSQL报错UNIT MYSQLD.SERVICE COULD NOT BE FOUND
报错:
Unit mysqld.service could not be found
请查找mysql.server然后复制到/etc/init.d/mysqld
[root@CentOS7 be]# find ./ -name ‘mysql.server’
[root@CentOS7 be]# cp mysql.server /etc/init.d/mysqld
5.3 手动编译SH BUILD.SH失败
5.3.1 报错download ora158.tar.gz failed
使用官方推荐的方式,用docker镜像编译
5.3.2 报错gcc -V找不到指定的目录
开始的时候安装的GCC 7.3,发现版本过高导致gcc -V这个命令已经废弃了。删除gcc7.3重新安装gcc5.5(但是版本一定要在4.8.2以上)

5.4 部署FE,报错找不到IMAGE.0
报错:
/opt/doris/output/fe/doris-meta/image/image.0 not found
配置文件的问题,配置文件需要指定并创建meta_dir。详见FE配置文件2.2.3
5.5 使用MYSQL连接FE失败
报错:
ERROR 2003 (HY000) Cant’t connect to MySQL server on ‘CentOS7’(111)
解决方案:
配置文件中绑定的IP需要带上网关
priority_networks =CentOS7/24
使用免密登陆
mysql -h CentOS7 -P 9030 -uroot
5.6 添加BE失败
报错
连接FE之后使用Alter语句添加BE失败:
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'SYSTEM ADD BACKEND 'CentOS7:9050'' at line 1
![]()
失败原因:
mysql连接FE失败,使用正确的连接方式、端口号连接FE才能创建BE
[root@CentOS7]# mysql -h CentOS7 -P 9030 -uroot
界面访问UI失败
http://CentOS7:8030/system
5.7 BE启动失败
报错:
![]()
解决:
1.修改最大文件句柄数
echo "* soft nofile 204800" >> /etc/security/limits.conf
echo "* hard nofile 204800" >> /etc/security/limits.conf
echo "* soft nproc 204800" >> /etc/security/limits.conf
echo "* hard nproc 204800 " >> /etc/security/limits.conf
修改 /etc/sysctl.conf, 加入
echo fs.file-max = 6553560 >> /etc/sysctl.conf
2.查看是否修改成功
cat /etc/security/limits.conf
cat /etc/sysctl.conf
3.重启
reboot -h now
5.8 BE连接失败
报错如下:可以查询到BE,但是显示BE连接失败
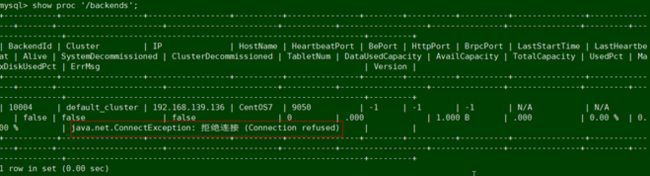
解决:
在 be/bin/be.pid中有BE的进程号,查看进程是否启动成功