【深度学习】【AdvProp对抗传播算法】【论文翻译】 对抗样本法对图像识别性能的提升

| [原论文链接](https://www.zhuanzhi.ai/paper/f2ee9c8c003e01f4137af10d2bc5f467) |
说明:本文翻译自以上链接中的论文,该论文论述了对抗样本可能有利于提高网络模型对图像识别的能力。翻译中只包含了原论文中前四页的核心内容,在一些必要的地方进行了精简,建议读者大大们配合原论文阅读,相关的实验还望读者自行查看原论文。论文对应的代码链接在原论文中已有标注。
翻译人:Mou Chaoli
文章目录
-
-
- 摘要
- 介绍
- 相关工作
- 一种提高性能的简单尝试
- 方法论
-
- 对抗训练
- 通过辅助性 B N BN BN实现的解纠缠学习
- A d v P r o p AdvProp AdvProp算法
-
摘要
在正确方式下,对抗样本可以用来改善图像识别模型。我们提出 A d v P r o p AdvProp AdvProp算法,一种增强对抗训练的方式,这种算法将对抗样例作为多余的样本来进行处理,以防止过拟合。该算法的关键是对对抗样本采用独立的辅助性的 b a t c h n o r m batchnorm batchnorm,因为相对于普通样本来说,对抗样本具有不同的潜在分布。
我们发现 A d v P r o p AdvProp AdvProp改进了各种图像识别任务的模型,并且当模型规模较大时效果更佳。
介绍
通过在图像中加入精心制作而不易察觉的人工噪声所得到的对抗样本,会导致卷积神经网络做出错误的预测。对抗样本的存在,不仅揭示了卷积网络有限的泛化能力,而且对这些模型的实际部署也造成了威胁。自从第一次发现卷积网络易受对抗样例的威胁以来,大量的工作都用在了提高网络的健壮性。
在本篇论文中,我们将注意力转移到利用对抗样本来提高模型的识别率,而不是专注于解决对抗样本产生的威胁。以前的研究表明,利用对抗样本对模型进行训练可以提高模型的泛化能力,但这仅限于某些情况——这种实验结果只能在完全监督学习环境下的小数据集(如 M N I S T MNIST MNIST)上观察到,或者在半监督学习环境下的大数据集上观察到。同时,最近的研究也表明,在大数据集(如 I m a g e N e t ImageNet ImageNet)上基于有监督学习方法、使用对抗样本进行训练,会导致在清晰图像上的识别性能下降。总之,如何有效地利用对抗样本来提高视觉模型的性能仍然是一个悬而未决的问题。
我们观察到,联合所有以往的方法,对清晰图像和对抗样本分别进行训练,二者训练结果的区别并不大,即便它们应该服从不同的潜在分布。我们假设清晰样例和对抗样例各自所服从的潜在分布的不匹配是导致先前工作中模型性能下降的一个关键因素。
在本篇论文中,我们提出了一种新的训练方案 A d v P r o p AdvProp AdvProp,即对对抗传播( A d v e r s a r i a l Adversarial Adversarial P r o p a g a t i o n Propagation Propagation)的简称。它用一种简单而有效的 t w o − b a t c h n o r m two-batchnorm two−batchnorm方法来弥补潜在分布的不匹配。具体而言,我们打算使用两个 b a t c h n o r m batchnorm batchnorm统计,一个作用于清晰图像,另一个辅助性地作用于对抗样本。这两个 b a t c h n o r m batchnorm batchnorm在归一化层将两个分布适当地分开,以便进行准确的统计估计。我们展示了这种分布分离的操作是至关重要的,这种方法使我们成功地利用对抗样本来提高模型性能,而非降低。
据我们所知,对于 I m a g e N e t ImageNet ImageNet数据集,在全监督的环境下,我们的工作第一次展示了对抗样本可以提高模型的性能。例如,使用 A d v P r o p AdvProp AdvProp算法训练的 E f f i c i e n t N e t − B 7 EfficientNet-B7 EfficientNet−B7达到 85.2 85.2 85.2%的 t o p − 1 top-1 top−1的准确率,比相对应的普通网络高出 0.8 0.8 0.8%。当将模型运用到对经过处理后失真的图像的识别中时, A d v P r o p AdvProp AdvProp对性能的提升更为显著。如图 1 1 1所示, A d v P r o p AdvProp AdvProp帮助 E f f i c i t N e t − B 7 EfficitNet-B7 EfficitNet−B7在 I m a g e N e t − C ImageNet-C ImageNet−C、 I m a g e N e t − A ImageNet-A ImageNet−A和 S t y l e i z e d − I m a g e N e t Styleized-ImageNet Styleized−ImageNet在绝对改善率上分别提高了 9.0 9.0 9.0%、 7.0 7.0 7.0%和 5.0 5.0 5.0%。

相关工作
对抗训练。对抗训练采取利用对抗样本训练网络的方式,这构成了目前抵御对抗样本造成的威胁的最新技术。尽管对抗训练显著提高了模型的鲁棒性,但如何通过对抗训练提高清晰图像的准确度仍有待探索。在半监督环境下, V A T VAT VAT和深度联合训练试图( d e e p deep deep c o − t r a i n i n g co-training co−training)利用对抗样本,但它们需要大量额外的未标记的图像。在监督环境下,对抗训练通常被认为会损害对清晰图像的识别率,例如, C I F A R − 10 CIFAR-10 CIFAR−10下降 10 10 10%, I m a g e N e t ImageNet ImageNet下降 15 15 15%。 T s i p r a s Tsipras Tsipras等人认为,对抗训练的健壮性和标准准确率之间的性能权衡是不可避免的,并将这种现象归因于健壮性分类器所学习的特征表示与标准分类器有着根本上的不同。其他的研究则试图从对抗样本复杂度增加、训练数据量有限或网络过度参数化的角度来解释这种性能权衡现象。本文关注的是无需额外数据的标准监督学习。虽然使用了类似的对抗训练技术,但是从前面的工作来看,我们的目标是使用对抗样本来提高对清晰图像的识别率。
学习对抗特征的好处。许多相关的工作证实,训练对抗样本带来了额外的好处。以卷积网络为例,与清晰的图像相比,对抗样本使网络的表征更加明显,使其具有显著的数据特征和人类感知。此外,这样训练出的模型对高频噪声的鲁棒性更高。 Z h a n g Zhang Zhang等人进一步指出,这种基于对抗样本的学习所得到的特征表示对纹理的失真与否不太敏感,而是更多地关注形状信息。
数据增强。数据增强是一种重要而有效的防止网络过拟合的方法,它对图像应用了一组保留标签的变换。除了传统的水平平移和随机裁剪等方法外,还提出了不同的增强技术,如对图像中的区域进行掩蔽或加上高斯噪声,或将成对的图像及其标签以凸函数的方式进行重组混合。最近的工作还表明,可以自动学习数据增强策略,以获得更好的图像分类和目标检测的性能。我们的工作可以看作是一种数据增强:通过注入噪声来创建额外的训练样本。然而,所有先前的尝试,通过增加随机噪声不能提高对清晰图像的识别率。
一种提高性能的简单尝试
M a d r y Madry Madry等人将对抗训练描述为一个求 m i n min min求 m a x max max的博弈过程,并专门利用对抗样本来训练模型,以有效地提高模型的鲁棒性。然而,经过这种方式训练的模型通常不能很好地推广到一些清晰图像。我们使用 P G D a t t a c k e r 1 PGD attacker1 PGDattacker1在 I m a g e N e t ImageNet ImageNet上训练了一个中等规模的模型( E f f i c i e n t N e t − B 3 EfficientNet-B3 EfficientNet−B3)和一个大规模的模型( E f f i c i e n t N e t − B 7 Ef ficientNet-B7 EfficientNet−B7),从而验证了这一结果即这两个经过对抗训练的模型在清晰图像上的识别率都比普通模型低得多。例如,这种经过对抗训练的 E f f i c i e n t N e t − B 3 EfficientNet-B3 EfficientNet−B3在清晰图像上的识别率仅为 78.2 78.2 78.2%,而普通训练的 E f f i c i e n t N e t − B 3 EfficientNet-B3 EfficientNet−B3的准确率为 81.7 81.7 81.7%(见图 2 2 2)。
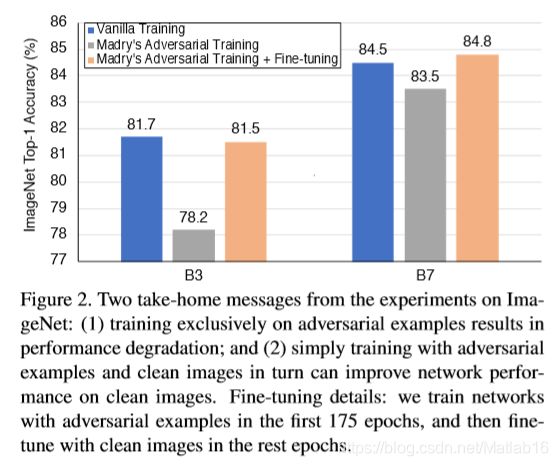
我们假设这种性能下降主要是由分布不匹配引起的——对抗样本和清晰图像来自两个不同的域,因此只在一个域上进行训练不能很好地转移到另一个域。如果这种分布不匹配可以适当地桥接,那么即便使用对抗样本进行训练,也应该能够缓解在清晰图像上模型性能下降的问题。为了验证这种假设,我们将考察一种简单的策略——先用对抗样本对网络进行,然后再用清晰图像对其进行微调。结果如图 2 2 2所示。正如预期的那样,这种简单的微调策略(以浅橙色标记)总是比作为基准的 M a d r y Madry Madry的对抗训练(以灰色标记)产生更高的识别率。例如,它将 E f f i c i e n t N e t − B 3 EfficientNet-B3 EfficientNet−B3的准确度提高了 3.3 3.3 3.3%。有趣的是,与仅使用清晰图像进行训练(用蓝色标记)的普通标准训练方式相比,这种微调策略有时甚至有助于网络实现卓越的性能,例如,它将 E f f i c i t N e t − B 7 EfficitNet-B7 EfficitNet−B7的准确率提高了 0.3 0.3 0.3%,在 I m a g e N e t ImageNet ImageNet上实现了 84.8 84.8 84.8%的前 t o p − 1 top-1 top−1准确率。上述观察结果发送了一个很有希望的信号——如果使用得当,利用对抗样本进行训练可能有利于提高模型性能。尽管如此,我们注意到这种方法并非在所有情况下都能提高模型性能,例如,尽管这种训练有素的 E f f i c i e n t N e t − B 3 EfficientNet-B3 EfficientNet−B3显著优于作为基准的 M a d r y Madry Madry的对抗训练,但效果仍略低于普通的训练方式( − 0.2 -0.2 −0.2%)。因此,一个自然的问题出现了:是否有可能以更有效的方式从对抗样本中提取有价值的特征,并进一步提高模型性能?
方法论
前面的结果表明,即便以简单的方式适当地整合来自对抗样本和清晰图像的信息都可以提高模型的性能。然而,这种精确的调整策略可能会覆盖部分从对抗样本中学习到的特征,从而导致只能得到一种只有次优解决的方案。为了解决这个问题,我们提出了一种更为优雅的方法—— A d v P r o p AdvProp AdvProp,它可以从清晰图像和对抗样本中共同学习。我们的方法通过在规范化层( n o r m a l i z a t i o n normalization normalization l a y e r s layers layers)上显式地对批量统计信息( b a t c h batch batch s t a t i s t i c s statistics statistics)进行解耦分离,以此处理分布不匹配的问题,从而能够更好地汲取对抗样本和清晰图像的特征。在本节中,我们首先回顾了在[对抗训练]部分中的对抗训练的机制,然后在[通过辅助性 B N BN BN实现的解纠缠学习]中介绍如何通过辅助 B N s BNs BNs为混合在一起的分布使用解纠缠学习( d i s t a n g l e d distangled distangled l e a r n i n g learning learning)。最后,我们总结了[ A d v P r o p AdvProp AdvProp]中的训练和测试流程。
对抗训练
我们首先回顾在一般普通训练中的目标函数:
arg min θ E ( x , y ) ∼ D [ L ( θ , x , y ) ] ( 1 ) \mathop{\arg\min}\limits_{\theta}E_{(x,y)\sim D}\Big[ L(\theta,x,y) \Big](1) θargminE(x,y)∼D[L(θ,x,y)](1)
其中 D D D是潜在的数据分布, L ( ⋅ , ⋅ , ⋅ ) L(·,·,·) L(⋅,⋅,⋅)是损失函数, θ θ θ是网络参数, x x x是带有真实标签 y y y的训练样本。
考虑 M a d r y Madry Madry的对抗训练的框架,它并未采用原始样本进行训练,而是用故意添加扰动后的样本来训练网络,
arg min θ E ( x , y ) ∼ D [ max ϵ ∼ s L ( θ , x + ϵ , y ) ] ( 2 ) \mathop{\arg\min}\limits_{\theta}E_{(x,y)\sim D}\Big[ \mathop{\max}\limits_{\epsilon\sim s} L(\theta,x+\epsilon,y) \Big](2) θargminE(x,y)∼D[ϵ∼smaxL(θ,x+ϵ,y)](2)
其中 ϵ \epsilon ϵ是对抗扰动, S S S是允许的扰动范围。虽然这样训练而出的模型有几个优良的性质,但它无法很好地推广到清晰图像。与 M a d r y Madry Madry的对抗训练不同,我们的主要目标是通过利用对抗样本的正则化能力来提高网络在清晰图像上的性能。因此,我们将对抗图像视为额外的训练样本,并使用对抗样本和清晰图像的来混合训练网络。
arg min θ E ( x , y ) ∼ D [ max ϵ ∼ s L ( θ , x + ϵ , y ) + L ( θ , x , y ) ] ( 3 ) \mathop{\arg\min}\limits_{\theta}E_{(x,y)\sim D}\Big[ \mathop{\max}\limits_{\epsilon\sim s} L(\theta,x+\epsilon,y)+L(\theta,x,y) \Big](3) θargminE(x,y)∼D[ϵ∼smaxL(θ,x+ϵ,y)+L(θ,x,y)](3)
理想情况下,这些经过严格训练的模型应该同时获得来自训练对抗样本和清晰图像的好处。然而,正如在之前的研究中所观察到的,直接优化式 ( 3 ) (3) (3)通常比普通训练机制在清晰图像上产生略低的性能。我们假设对抗样本和清晰图像之间的分布不匹配会妨碍网络从这两个来源准确有效地提取有价值的特征。接下来,我们将介绍如何通过我们所设计的辅助性 b a t c h batch batch n o r m norm norm准确地分离这两个不同的分布。
通过辅助性 B N BN BN实现的解纠缠学习
批量标准化( B a t c h Batch Batch N o r m a l i z a t i o n , B N Normalization,BN Normalization,BN)是许多先进的计算机视觉模型的重要组成部分。具体来说, B N BN BN通过计算每个小批量的均值和方差来规范化输入特征。利用 B N BN BN的一个内在假设是,输入特征应该来自单个相同的或类似的分布。如果小批量包含来自不同分布的数据,则这种规范化行为可能会有问题,从而导致不准确的统计估计。
我们认为,对抗样本和清晰图像各自有不同的潜在分布,而式 ( 3 ) (3) (3)所定义的对抗训练的框架本质上涉及一个包含两种成分的混合分布。为了将这种混合分布拆分为两个简单的分布,我们在此提出了一种辅助性 B N BN BN,它将保证其规范化的操作只在对抗样本上进行。具体而言,如图 3 ( b ) 3(b) 3(b)所示,我们提出的辅助性 B N BN BN有助于将混合分布拆解,从而得到属于不同域的特征各自所对应的独立 B N s BNs BNs。
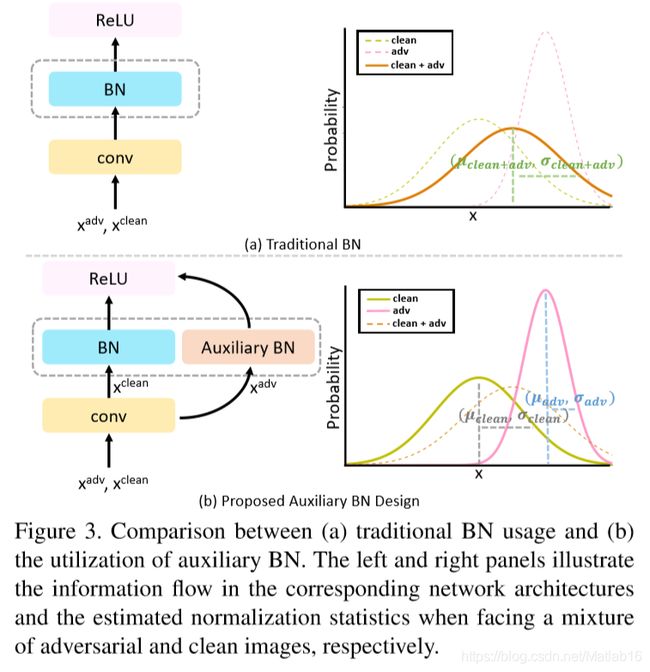
否则,如图 3 ( a ) 3(a) 3(a)所示,简单地只保留一组 B N BN BN会导致错误的统计量估计,这可能导致性能降低。
注意,我们可以将这个概念推广到多个辅助性 B N BN BN,其中辅助性 B N BN BN的数量由训练样本源的数量决定。例如,如果训练数据包含清晰图像、失真图像和对抗图像,则需要保留两个辅助性 B N BN BN。后面部分的研究表明,如此细腻度的多 B N s BNs BNs解纠缠学习可以进一步提高性能。在未来的工作中将进一步探讨多个 B N s BNs BNs的更普遍的用法。
A d v P r o p AdvProp AdvProp算法
我们在算法 1 1 1中正式提出了 A d v P r o p AdvProp AdvProp,以便在训练过程中准确地获取清晰样本和对抗样本的特征。对于每份清晰样本的小批量,我们首先使用辅助性 B N s BNs BNs来对网络进行侵扰以生成相应的对抗样本;然后我们将清晰样本小批量和对抗样本小批量投喂到同一个网络,然后应用不同的 B N s BNs BNs进行损失计算,即对清晰样本小批量使用主要 B N s BNs BNs,对对抗样本小批量使用辅助 B N s BNs BNs;最后,我们将总损失函数最小化,对网络参数的梯度进行更新。换句话说,除了 B N s BNs BNs层,卷积层和其他层都是对对抗样本和清晰样本直接进行联合优化的。
注意: A d v P r o p AdvProp AdvProp中辅助 B N s BNs BNs的引入所增加的额外的网络训练参数是可以忽略不计的。例如,在 E f f i c i e n t N e t − B 7 EfficientNet-B7 EfficientNet−B7上比基准的参数量多增加 0.5 0.5 0.5%的参数。在测试时,这些额外的辅助 B N s BNs BNs层都被丢弃,我们只使用相同的主要 B N s BNs BNs。

说明:论文的翻译到这里就结束了。文中有翻译不合适的地方还望各位读者大大指出。希望大家读有所获。若需转载,还望麻烦备注出处。