【NLP】4 gensim word2vec库入门——官方手册embeddings和KeyedVectors
gensim word2vec库官方手册
- 1. Word2vec embeddings
-
- 1.1 简介
- 1.2 其它的嵌入
- 1.3 使用例程
- 1.4 多字ngrams的嵌入
- 1.5 预训练模型
- 补充: gensim-data
-
- (1) Gensim-data有什么用?
- (2) 它怎么工作?
- (3) 快速入门
- (4) 可获取的数据
- (5) 想要添加一个新的语料库或模型?
- 2. Store and query word vectors
-
- 2.1 为什么使用KeyedVectors而不是完整的模型?
- 2.2 如何获得单词向量?
- 2.3 词向量可以做什么?
- 小结
1. Word2vec embeddings
Gensim Word2vec embeddings 官方文档
1.1 简介
该模块使用高度优化的C语言例程、数据流和Pythonic接口实现了word2vec系列算法。
word2vec算法包括skip-gram和CBOW模型,使用层次softmax或负采样:Tomas Mikolov et al: Efficient Estimation of Word Representations in Vector Space,Tomas Mikolov et al: Distributed Representations of Words and Phrases and their Compositionality
1.2 其它的嵌入
在Gensim中,有更多的方法来训练单词向量,而不仅仅是Word2Vec。另请参见Doc2Vec、FastText以及VarEmbed和WordRank的包装器。
训练算法最初是从C语言包https://code.google.com/p/word2vec/ 移植过来的,经过多年的扩展,增加了更多的功能和优化。
有关Gensim word2vec的教程,以及在GoogleNews上训练的交互式网络应用,请访问https://rare-technologies.com/word2vec-tutorial/。
1.3 使用例程
初始化一个模型,例如:
from gensim.test.utils import common_texts
from gensim.models import Word2Vec
model = Word2Vec(sentences=common_texts, size=100, window=5, min_count=1, workers=4)
model.save("word2vec.model")
注意,官网例程里的vector_size参数Word2Vec函数里应该已经换成了size
其中,打开gensim.test.utils库可以发现common_texts长这样:
common_texts = [
['human', 'interface', 'computer'],
['survey', 'user', 'computer', 'system', 'response', 'time'],
['eps', 'user', 'interface', 'system'],
['system', 'human', 'system', 'eps'],
['user', 'response', 'time'],
['trees'],
['graph', 'trees'],
['graph', 'minors', 'trees'],
['graph', 'minors', 'survey']
]
训练是流式的,所以 sentences可以是一个可迭代的,从磁盘或网络中即时读取输入数据,而无需将整个语料加载到RAM中。
请注意,sentences迭代必须是可重启的(而不仅仅是一个生成器),以允许算法多次流过你的数据集。关于流式迭代的一些例子,请参见BrownCorpus、Text8Corpus或LineSentence。
如果你保存了模型,以后可以继续训练它:
from gensim.models import Word2Vec
model = Word2Vec.load("word2vec.model")
print(model.train([["hello", "world"]], total_examples=1, epochs=1))
结果:
(0, 2)
训练好的词向量存储在一个KeyedVectors实例中,为model.wv:
vector = model.wv['computer'] # 获取单词的numpy向量
将训练好的向量分离成KeyedVectors的原因是,如果你不需要完整的模型状态了(不需要继续训练),它的状态可以丢弃,只保留向量和它们的键就可以了
这就产生一个更小更快的对象,可以通过被映射来实现闪电般的快速加载,并在进程间共享RAM中的向量
from gensim.models import KeyedVectors
word_vector = model.wv # 只存储单词+其训练好的嵌入物
word_vector.save('word2vec.wordvectors')
wv = KeyedVectors.load('word2vec.wordvectors', mmap='r') # 加载回内存映射=只读,跨进程共享
vector = wv['computer'] # 获取单词的numpy向量
Gensim还可以加载 "word2vec C格式 "的字向量,作为KeyedVectors实例:
from gensim.test.utils import datapath
wv_from_text = KeyedVectors.load_word2vec_format(datapath('word2vec_pre_kv_c'), binary=False) # 加载一个以C*text*格式存储的word2vec模型
wv_from_bin = KeyedVectors.load_word2vec_format(datapath('euclidean_vectors.bin'), binary=True) # 加载一个以C*binary*格式存储的word2vec模型
因为缺少了隐藏权重、词汇频率和二进制树,所以无法继续训练从C格式加载的向量。要想继续训练,你需要完整的Word2Vec对象状态,就像save()存储的那样,而不仅仅是`KeyedVectors
您可以使用训练好的模型执行各种 NLP 任务。有些操作已经是内置的–参见gensim.models.keyedvectors
如果你完成了一个模型的训练(即不再更新,只进行查询),你可以切换到KeyedVectors实例:
word_vectors = model.wv
del model
以削减不需要的模型状态=使用更少的RAM,并允许快速加载和内存共享(mmap)
1.4 多字ngrams的嵌入
有一个gensim.models.phrases模块,它可以让你自动检测超过一个词的短语,使用搭配统计(collocation statistics)。使用短语,你可以学习一个word2vec模型,其中的 "词 "实际上是多词表达,比如new_york_times或financial_crisis
from gensim.test.utils import common_texts
from gensim.models import Word2Vec
from gensim.models import Phrases
bigram_transformer = Phrases(common_texts)
model = Word2Vec(bigram_transformer[common_texts], min_count=1)
1.5 预训练模型
Gensim在Gensim-data资源库中附带了几个已经预先训练好的模型
运行程序,报错:
ValueError: unable to read local cache 'C:\\Users\\Yang SiCheng/gensim-data\\information.json' during fallback, connect to the Internet and retry
解决办法见gensim下载时出现找不到information.json的问题,即Gensim-data资源库中list.json文件
import gensim.downloader
print(list(gensim.downloader.info()['models'].keys())) # 在gensim-data中显示所有可用的模型
结果:
['fasttext-wiki-news-subwords-300', 'conceptnet-numberbatch-17-06-300', 'word2vec-ruscorpora-300', 'word2vec-google-news-300', 'glove-wiki-gigaword-50', 'glove-wiki-gigaword-100', 'glove-wiki-gigaword-200', 'glove-wiki-gigaword-300', 'glove-twitter-25', 'glove-twitter-50', 'glove-twitter-100', 'glove-twitter-200', '__testing_word2vec-matrix-synopsis']
import gensim.downloader
glove_vectors = gensim.downloader.load('glove-twitter-25') # 下载 "glove-twitter-25 "的嵌入
print(glove_vectors.most_similar('twitter')) # 照常使用下载的向量
报错:
urllib.error.ContentTooShortError: 解决措施:再下载一遍,这一次的下载速度很快,下载好之后可以在C盘的user文件夹中找到下载的数据集:
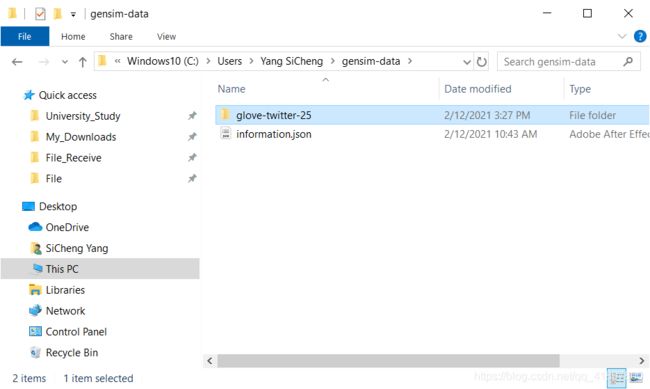
运行结果:
[('facebook', 0.948005199432373), ('tweet', 0.9403422474861145), ('fb', 0.9342359304428101), ('instagram', 0.9104823470115662), ('chat', 0.8964965343475342), ('hashtag', 0.8885936737060547), ('tweets', 0.8878158926963806), ('tl', 0.8778461813926697), ('link', 0.8778210878372192), ('internet', 0.8753897547721863)]
补充: gensim-data
预训练的NLP模型和NLP语料库的数据库
(1) Gensim-data有什么用?
研究数据集经常性地消失、随着时间的推移而变化、过时或没有一个合理的实现来处理数据格式的读取和处理。
为此,Gensim推出了自己的数据集存储,致力于长期支持,一个合理的标准化使用API,并专注于非结构化文本处理的数据集(没有图像或音频)。这个Gensim-data存储库就是作为该存储库。
你不需要直接使用这个软件库。相反,只需安装 Gensim 并使用其下载 API(见下面的快速入门)。它将自动与这个软件库 “对话”。
当您使用Gensim下载API时,所有数据都存储在您的~/gensim-data主页面文件夹中。
在本文中阅读更多关于项目理由和设计决策的内容。新的预训练NLP模型和数据集的下载API(New Download API for Pretrained NLP Models and Datasets.)。
(2) 它怎么工作?
从技术上讲,实际的(有时是大的)体例和模型文件是作为发布附件存储在Github上的,每个数据集(以及每个数据集的新版本)都有自己的发布版本,永远不可更改。
每个版本都附有使用范例和发布说明,例如:2017年美国专利商标局专利的语料库(Corpus of USPTO Patents from 2017);2017年的英文维基百科与明文部分(English Wikipedia from 2017 with plaintext section)。
每个数据集都有自己的许可证,用户在使用数据集之前要仔细研究!
(3) 快速入门
要加载模型或语料库,可以使用Gensim的Python或命令行界面(你需要先安装Gensim)。
- Python API
例子:加载一个预训练的模型(gloVe词向量):
import gensim.downloader as api
info = api.info() # show info about available models/datasets
model = api.load("glove-twitter-25") # download the model and return as object ready for use
model.most_similar("cat")
"""
output:
[(u'dog', 0.9590819478034973),
(u'monkey', 0.9203578233718872),
(u'bear', 0.9143137335777283),
(u'pet', 0.9108031392097473),
(u'girl', 0.8880630135536194),
(u'horse', 0.8872727155685425),
(u'kitty', 0.8870542049407959),
(u'puppy', 0.886769711971283),
(u'hot', 0.8865255117416382),
(u'lady', 0.8845518827438354)]
"""
例子:加载一个语料库,并用它来训练一个Word2Vec模型:
from gensim.models.word2vec import Word2Vec
import gensim.downloader as api
corpus = api.load('text8') # download the corpus and return it opened as an iterable
model = Word2Vec(corpus) # train a model from the corpus
model.most_similar("car")
"""
output:
[(u'driver', 0.8273754119873047),
(u'motorcycle', 0.769528865814209),
(u'cars', 0.7356342077255249),
(u'truck', 0.7331641912460327),
(u'taxi', 0.718338131904602),
(u'vehicle', 0.7177008390426636),
(u'racing', 0.6697118878364563),
(u'automobile', 0.6657308340072632),
(u'passenger', 0.6377975344657898),
(u'glider', 0.6374964714050293)]
"""
例如:只下载一个数据集,并返回本地文件路径(不打开):
import gensim.downloader as api
print(api.load("20-newsgroups", return_path=True)) # output: /home/user/gensim-data/20-newsgroups/20-newsgroups.gz
print(api.load("glove-twitter-25", return_path=True)) # output: /home/user/gensim-data/glove-twitter-25/glove-twitter-25.gz
- 同样的操作,但来自CLI,命令行界面
python -m gensim.downloader --info # show info about available models/datasets
python -m gensim.downloader --download text8 # download text8 dataset to ~/gensim-data/text8
python -m gensim.downloader --download glove-twitter-25 # download model to ~/gensim-data/glove-twitter-50/
(4) 可获取的数据
数据集
| name | file size | read_more | description | license |
|---|---|---|---|---|
| 20-newsgroups | 13 MB |
|
The notorious collection of approximately 20,000 newsgroup posts, partitioned (nearly) evenly across 20 different newsgroups. | not found |
| fake-news | 19 MB |
|
News dataset, contains text and metadata from 244 websites and represents 12,999 posts in total from a specific window of 30 days. The data was pulled using the webhose.io API, and because it’s coming from their crawler, not all websites identified by their BS Detector are present in this dataset. Data sources that were missing a label were simply assigned a label of ‘bs’. There are (ostensibly) no genuine, reliable, or trustworthy news sources represented in this dataset (so far), so don’t trust anything you read. | https://creativecommons.org/publicdomain/zero/1.0/ |
| patent-2017 | 2944 MB |
|
Patent Grant Full Text. Contains the full text including tables, sequence data and ‘in-line’ mathematical expressions of each patent grant issued in 2017. | not found |
| quora-duplicate-questions | 20 MB |
|
Over 400,000 lines of potential question duplicate pairs. Each line contains IDs for each question in the pair, the full text for each question, and a binary value that indicates whether the line contains a duplicate pair or not. | probably https://www.quora.com/about/tos |
| semeval-2016-2017-task3-subtaskA-unannotated | 223 MB |
|
SemEval 2016 / 2017 Task 3 Subtask A unannotated dataset contains 189,941 questions and 1,894,456 comments in English collected from the Community Question Answering (CQA) web forum of Qatar Living. These can be used as a corpus for language modelling. | These datasets are free for general research use. |
| semeval-2016-2017-task3-subtaskBC | 6 MB |
|
SemEval 2016 / 2017 Task 3 Subtask B and C datasets contain train+development (317 original questions, 3,169 related questions, and 31,690 comments), and test datasets in English. The description of the tasks and the collected data is given in sections 3 and 4.1 of the task paper http://alt.qcri.org/semeval2016/task3/data/uploads/semeval2016-task3-report.pdf linked in section “Papers” of https://github.com/RaRe-Technologies/gensim-data/issues/18. | All files released for the task are free for general research use |
| text8 | 31 MB |
|
First 100,000,000 bytes of plain text from Wikipedia. Used for testing purposes; see wiki-english-* for proper full Wikipedia datasets. | not found |
| wiki-english-20171001 | 6214 MB |
|
Extracted Wikipedia dump from October 2017. Produced by python -m gensim.scripts.segment_wiki -f enwiki-20171001-pages-articles.xml.bz2 -o wiki-en.gz |
https://dumps.wikimedia.org/legal.html |
模型
| name | num vectors | file size | base dataset | read_more | description | parameters | preprocessing | license |
|---|---|---|---|---|---|---|---|---|
| conceptnet-numberbatch-17-06-300 | 1917247 | 1168 MB | ConceptNet, word2vec, GloVe, and OpenSubtitles 2016 |
|
ConceptNet Numberbatch consists of state-of-the-art semantic vectors (also known as word embeddings) that can be used directly as a representation of word meanings or as a starting point for further machine learning. ConceptNet Numberbatch is part of the ConceptNet open data project. ConceptNet provides lots of ways to compute with word meanings, one of which is word embeddings. ConceptNet Numberbatch is a snapshot of just the word embeddings. It is built using an ensemble that combines data from ConceptNet, word2vec, GloVe, and OpenSubtitles 2016, using a variation on retrofitting. |
|
- | https://github.com/commonsense/conceptnet-numberbatch/blob/master/LICENSE.txt |
| fasttext-wiki-news-subwords-300 | 999999 | 958 MB | Wikipedia 2017, UMBC webbase corpus and statmt.org news dataset (16B tokens) |
|
1 million word vectors trained on Wikipedia 2017, UMBC webbase corpus and statmt.org news dataset (16B tokens). |
|
- | https://creativecommons.org/licenses/by-sa/3.0/ |
| glove-twitter-100 | 1193514 | 387 MB | Twitter (2B tweets, 27B tokens, 1.2M vocab, uncased) |
|
Pre-trained vectors based on 2B tweets, 27B tokens, 1.2M vocab, uncased (https://nlp.stanford.edu/projects/glove/) |
|
Converted to w2v format with python -m gensim.scripts.glove2word2vec -i . |
http://opendatacommons.org/licenses/pddl/ |
| glove-twitter-200 | 1193514 | 758 MB | Twitter (2B tweets, 27B tokens, 1.2M vocab, uncased) |
|
Pre-trained vectors based on 2B tweets, 27B tokens, 1.2M vocab, uncased (https://nlp.stanford.edu/projects/glove/). |
|
Converted to w2v format with python -m gensim.scripts.glove2word2vec -i . |
http://opendatacommons.org/licenses/pddl/ |
| glove-twitter-25 | 1193514 | 104 MB | Twitter (2B tweets, 27B tokens, 1.2M vocab, uncased) |
|
Pre-trained vectors based on 2B tweets, 27B tokens, 1.2M vocab, uncased (https://nlp.stanford.edu/projects/glove/). |
|
Converted to w2v format with python -m gensim.scripts.glove2word2vec -i . |
http://opendatacommons.org/licenses/pddl/ |
| glove-twitter-50 | 1193514 | 199 MB | Twitter (2B tweets, 27B tokens, 1.2M vocab, uncased) |
|
Pre-trained vectors based on 2B tweets, 27B tokens, 1.2M vocab, uncased (https://nlp.stanford.edu/projects/glove/) |
|
Converted to w2v format with python -m gensim.scripts.glove2word2vec -i . |
http://opendatacommons.org/licenses/pddl/ |
| glove-wiki-gigaword-100 | 400000 | 128 MB | Wikipedia 2014 + Gigaword 5 (6B tokens, uncased) |
|
Pre-trained vectors based on Wikipedia 2014 + Gigaword 5.6B tokens, 400K vocab, uncased (https://nlp.stanford.edu/projects/glove/). |
|
Converted to w2v format with python -m gensim.scripts.glove2word2vec -i . |
http://opendatacommons.org/licenses/pddl/ |
| glove-wiki-gigaword-200 | 400000 | 252 MB | Wikipedia 2014 + Gigaword 5 (6B tokens, uncased) |
|
Pre-trained vectors based on Wikipedia 2014 + Gigaword, 5.6B tokens, 400K vocab, uncased (https://nlp.stanford.edu/projects/glove/). |
|
Converted to w2v format with python -m gensim.scripts.glove2word2vec -i . |
http://opendatacommons.org/licenses/pddl/ |
| glove-wiki-gigaword-300 | 400000 | 376 MB | Wikipedia 2014 + Gigaword 5 (6B tokens, uncased) |
|
Pre-trained vectors based on Wikipedia 2014 + Gigaword, 5.6B tokens, 400K vocab, uncased (https://nlp.stanford.edu/projects/glove/). |
|
Converted to w2v format with python -m gensim.scripts.glove2word2vec -i . |
http://opendatacommons.org/licenses/pddl/ |
| glove-wiki-gigaword-50 | 400000 | 65 MB | Wikipedia 2014 + Gigaword 5 (6B tokens, uncased) |
|
Pre-trained vectors based on Wikipedia 2014 + Gigaword, 5.6B tokens, 400K vocab, uncased (https://nlp.stanford.edu/projects/glove/). |
|
Converted to w2v format with python -m gensim.scripts.glove2word2vec -i . |
http://opendatacommons.org/licenses/pddl/ |
| word2vec-google-news-300 | 3000000 | 1662 MB | Google News (about 100 billion words) |
|
Pre-trained vectors trained on a part of the Google News dataset (about 100 billion words). The model contains 300-dimensional vectors for 3 million words and phrases. The phrases were obtained using a simple data-driven approach described in ‘Distributed Representations of Words and Phrases and their Compositionality’ (https://code.google.com/archive/p/word2vec/). |
|
- | not found |
| word2vec-ruscorpora-300 | 184973 | 198 MB | Russian National Corpus (about 250M words) |
|
Word2vec Continuous Skipgram vectors trained on full Russian National Corpus (about 250M words). The model contains 185K words. |
|
The corpus was lemmatized and tagged with Universal PoS | https://creativecommons.org/licenses/by/4.0/deed.en |
(5) 想要添加一个新的语料库或模型?
- 使用gzip或bz2压缩你的数据集
- 在任何文件共享服务上共享压缩文件
- 创建一个新问题(new issue),并给我们提供数据集的链接。添加一个详细的描述,说明你为什么和如何创建数据集,任何相关的论文或研究,加上你希望其他用户如何使用它。包括相关的代码示例
2. Store and query word vectors
这个模块实现了词向量,更一般的说是由查找tokens/ints键入的向量集和各种相似性查询。
由于训练后的词向量与训练方式(Word2Vec、FastText、WordRank、VarEmbed等)无关,因此可以用独立的结构来表示,如本模块所实现的
这个结构叫做 “KeyedVectors”,本质上是键和向量之间的映射。每个向量都由它的查找键来标识,最常见的是一个短字符串令牌,所以这通常是{str => 1D numpy数组}之间的映射
在最初的动机情况下,key是一个单词(所以映射单词到一维向量),但对于某些模型来说,密钥也可以对应一个文档、一个图节点等
(因为一些应用程序可能会维护他们自己的积分标识符,从零开始的邻域和连续,所以此类还支持使用纯整数作为键——在这种情况下,使用它们作为文字指针,指向所需向量在底层数组中的位置,并节省了查找映射条目的开销。)
2.1 为什么使用KeyedVectors而不是完整的模型?
- 继续训练向量:full model√——你需要完整的模型来训练或更新向量
- 小体积:KeyedVectors√——KeyedVectors体积更小,需要的RAM更少,因为它们不需要存储实现训练的模型状态
- 从本地fasttext/word2vec格式保存/加载:KeyedVectors√——Facebook和Google工具导出的Vectors不支持进一步的训练,但你仍然可以将它们加载到KeyedVectors中
- 附加新向量:all√——在映射中动态添加新的向量条目
- 并发:all√——线程安全,允许并发向量查询
- 共享内存:all√——多个进程可以重复使用相同的数据,使用mmap只在RAM中保留一个副本
- 快速加载:all√——支持mmap从磁盘即时加载数据
主要区别在于,KeyedVectors不支持进一步的训练。另一方面,通过舍弃训练所需的内部数据结构,KeyedVectors提供了更小的RAM占用空间和更简单的接口
2.2 如何获得单词向量?
训练一个完整的模型,然后访问其model.wv属性,该属性持有独立的键控向量。例如,使用Word2Vec算法来训练向量:
报错:
RuntimeError: you must first build vocabulary before training the model
解决办法:min_count属性值,默认值是5,会忽略频次少于5的词,发生这个错是因为词表里所有词的频率都少于5,把这个值改小一点就可以了
from gensim.test.utils import common_texts
from gensim.models import Word2Vec
model = Word2Vec(sentences=common_texts, size=24, window=5, min_count=1)
word_vectors = model.wv
将字向量保留在磁盘上,用
from gensim.models import KeyedVectors
word_vectors.save('vectors.kv')
reloaded_word_vectors = KeyedVectors.load('vectors.kv')
向量也可以从磁盘上现有的文件中实例化,以原始Google的word2vec C格式作为KeyedVectors实例,代码见1
2.3 词向量可以做什么?
你可以用训练好的向量执行各种句法/语义NLP词任务。其中一些任务已经是内置的
程序运行报错:
from pyemd import emd
ModuleNotFoundError: No module named 'pyemd'
PyEMD——an implementation of the Earth Mover’s Distance.
那先安装一下pyemd这个库,报错:
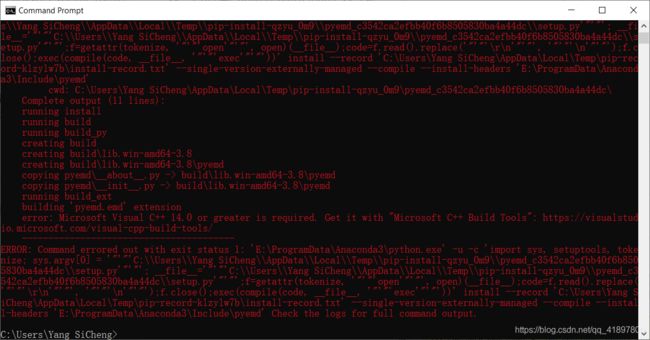
先安装一下Microsoft Visual C++ 14.0 or greater
并不是,应该是
pip install EMD-signal
继续报错,解决办法:pyemd库的大小写问题,把库源码替换为
from PyEMD import EMD
运行程序还是会报错,这里还是想尝试安装pyemd这个库,所以首先需要安装vs_buildtools,但装不上,尝试按这些方法、Microsoft Visual C++ 14.0 is required解决方法进行解决:
- 更新一下win10
- 下载whl离线文件到本地
利用以下命令安装
pip install ****.whl
- 感谢Microsoft Visual C++ 14.0 is required解决方法,在百度网盘里下载的Microsoft Visual C++ Build Tools可以使用
安装成功:
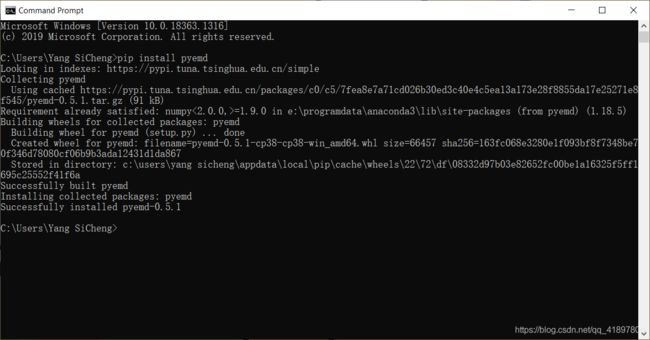
但依然报错
- 参考PyEMD包安装:No module named ‘PyEMD‘,使用:
conda install -c conda-forge pyemd
还是不行,而且下载很慢
- 参考此文,将PyEmd中所有的EMD换成小写emd,把PyEmd换成pyemd,问题解决
其它报错:
TypeError: get_vector() got an unexpected keyword argument 'norm'
解决方法:删除’norm’参数
报错:
KeyError: "word 'O' not in vocabulary"
解决方法:.n_similarity不能是字符串形式,只能是列表,删除以下代码
similarity = word_vectors.n_similarity('Obama speaks to the media in Illinois', 'The president greets the press in Chicago')
print(f"{similarity:.4f}")
完整代码:
import gensim.downloader as api
from gensim.models import KeyedVectors
# word_vectors = api.load('glove-twitter-25') # 从gensim-data加载预先训练好的词向量
# word_vectors.save('glove-twitter-25.model')
word_vectors = KeyedVectors.load('glove-twitter-25.model')
# 使用默认的 "余弦相似度 "测量法,检查 "最相似的词"
result = word_vectors.most_similar(positive=['woman', 'king'], negative=['man'])
most_similar_key, similarity = result[0] # 查看最匹配的结果
print(f'{most_similar_key}:{similarity:4f}')
# 使用不同的相似性测量:"cosmul"
result = word_vectors.most_similar_cosmul(positive=['woman', 'king'], negative=['man'])
most_similar_key, similarity = result[0] # look at the first match
print(f"{most_similar_key}: {similarity:.4f}")
print(word_vectors.doesnt_match("breakfast cereal dinner lunch".split()))
similarity = word_vectors.similarity('woman', 'man')
print(similarity > 0.8)
result = word_vectors.similar_by_word("cat")
most_similar_key, similarity = result[0] # look at the first match
print(f"{most_similar_key}: {similarity:.4f}")
sentence_obama = 'Obama speaks to the media in Illinois'.lower().split()
sentence_president = 'The president greets the press in Chicago'.lower().split()
similarity = word_vectors.wmdistance('Obama speaks to the media in Illinois', 'The president greets the press in Chicago')
print(f"{similarity:.4f}")
similarity = word_vectors.wmdistance(sentence_obama, sentence_president)
print(f"{similarity:.4f}")
similarity = word_vectors.n_similarity(sentence_obama, sentence_president)
print(f"{similarity:.4f}")
distance = word_vectors.distance("media", "media")
print(f"{distance:.1f}")
similarity = word_vectors.n_similarity(['sushi', 'shop'], ['japanese', 'restaurant'])
print(f"{similarity:.4f}")
vector = word_vectors['computer'] # 一个词的numpy向量
print(vector.shape)
print(vector)
vector = word_vectors.wv.get_vector('computer')
print(vector.shape)
print(vector)
结果:
meets:0.884192
E:\ProgramData\Anaconda3\lib\site-packages\gensim\models\keyedvectors.py:877: FutureWarning: arrays to stack must be passed as a "sequence" type such as list or tuple. Support for non-sequence iterables such as generators is deprecated as of NumPy 1.16 and will raise an error in the future.
vectors = vstack(self.word_vec(word, use_norm=True) for word in used_words).astype(REAL)
meets: 1.0725
cereal
False
dog: 0.9591
1.2571
2.2929
0.9773
0.0
0.8187
(25,)
[ 0.64005 -0.019514 0.70148 -0.66123 1.1723 -0.58859 0.25917
-0.81541 1.1708 1.1413 -0.15405 -0.11369 -3.8414 -0.87233
0.47489 1.1541 0.97678 1.1107 -0.14572 -0.52013 -0.52234
-0.92349 0.34651 0.061939 -0.57375 ]
(25,)
[ 0.64005 -0.019514 0.70148 -0.66123 1.1723 -0.58859 0.25917
-0.81541 1.1708 1.1413 -0.15405 -0.11369 -3.8414 -0.87233
0.47489 1.1541 0.97678 1.1107 -0.14572 -0.52013 -0.52234
-0.92349 0.34651 0.061939 -0.57375 ]
E:/Users/Yang SiCheng/PycharmProjects/Graduation_Project/main.py:170: DeprecationWarning: Call to deprecated `wv` (Attribute will be removed in 4.0.0, use self instead).
vector = word_vectors.wv.get_vector('computer')
分析:
- woman + king - man的余弦相似度、cosmul测量方法最佳匹配都是meets,分别打印出前十个结果看看:
[('meets', 0.8841923475265503), ('prince', 0.8321634531021118), ('queen', 0.8257461190223694), ('’s', 0.817409873008728), ('crow', 0.813499391078949), ('hunter', 0.8131037950515747), ('father', 0.811583399772644), ('soldier', 0.81113600730896), ('mercy', 0.8082393407821655), ('hero', 0.8082263469696045)]
[('meets', 1.0724927186965942), ('crow', 1.0357956886291504), ('hedgehog', 1.0280965566635132), ('prince', 1.0248892307281494), ('hunter', 1.0226764678955078), ('mercy', 1.0204172134399414), ('queen', 1.019834280014038), ('shepherd', 1.0195919275283813), ('soldier', 1.019392728805542), ('widow', 1.0162570476531982)]
感觉这个模型训练的结果不太好……
- word_vectors[‘computer’]和word_vectors.wv.get_vector(‘computer’)结果一样,但 vector = word_vectors.wv.get_vector(‘computer’)会报一个警告,这里直接把后者删除,但还是会报一个:
FutureWarning: arrays to stack must be passed as a "sequence" type such as list or tuple. Support for non-sequence iterables such as generators is deprecated as of NumPy 1.16 and will raise an error in the future.
vectors = vstack(self.word_vec(word, use_norm=True) for word in used_words).astype(REAL)
这在第一次安装gensim库的实验中就遇到过,暂未解决
- word_vectors.similarity(‘woman’, ‘man’)的similarity是0.76541775,所以print(similarity > 0.8)结果是False
similarity = word_vectors.wmdistance('Obama speaks to the media in Illinois', 'The president greets the press in Chicago')
similarity = word_vectors.wmdistance(sentence_obama, sentence_president)
similarity = word_vectors.n_similarity(sentence_obama, sentence_president)
结果分别为1.2571、2.2929、0.9773,暂不知道这三个句子的相似度是怎么求出来的
词语相似度与人类认知的关系
from gensim.test.utils import datapath
similarities = model.wv.evaluate_word_pairs(datapath('wordsim353.tsv'))
关于词语类比
analogy_scores = model.wv.evaluate_word_analogies(datapath('questions-words.txt'))
小结
从官方手册了解了word embeddings 和 KeyedVectors两个重要方法,一个是如何训练,一个是如何应用词向量,但是问题在于,目前跑的程序都是基于gensim-data:
- 对于英文来说,最后需要练习自己找或者做语料库训练模型
- 对于中文来说,gensim-data没有中文数据,更需要自己会找语料库训练模型
总而言之,官方文档作为gensim word2vec入门的教程可以了解一下,其后肯定需要深入查阅相关代码以及参数的含义,例如:
- wmdistance怎么计算字符串的?
- wmdistance怎么计算单词列表的?
- n_similarity怎么计算单词列表相似度的?
- cosmul具体计算方式是什么?
- 与人类认知的关系(是否为皮尔逊相关系数、spearman相关系数)
- 句子相似性doc2vec模型怎么实现的?
- ……
下一步计划自己找英文和中文语料库,用gensim的word2vec实践一下,希望woman + king - man的结果是queen,希望清华大学匹配的结果是北京大学、中国人民大学等等