Scrapy:在Scrapy中使用selenium来爬取简书全站内容,并存储到MySQL数据库中
创建爬虫
scrapy startproject jianshu
cd jianshu
scrapy gensipder -t crawl jianshu_spider “jianshu.com”
爬虫代码
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from pa_chong.Scrapy.jianshu.jianshu.items import ArticleItem
class JianshuSpiderSpider(CrawlSpider):
name = 'jianshu_spider'
allowed_domains = ['jianshu.com']
start_urls = ['https://www.jianshu.com/']
rules = (
Rule(LinkExtractor(allow=r'.*/p/[0-9a-z]{12}.*'), callback='parse_detail', follow=True),
)
# 文章内容url:www.jianshu.com/p/71d288a54072,
# p/71d288a54072的前面有可能没有字符(在文章详情页推荐的相关文章是相对路径)所以用.*,
# 后面有可能会有一些?xxxxxx的参数,所以也给个.* (匹配0个或多个(0-n个))
# 因为要对文章详情页的链接继续爬取满足条件的url,所以follow=Turn
def parse_detail(self, response):
title = response.xpath('//h1[@class="title"]/text()').get()
avatar = response.xpath('//a[@class="avatar"]/img/@src').get()
author = response.xpath('//span[@class="name"]/a/text()').get()
pub_time = response.xpath('//span[@class="publish-time"]/text()').get().replace('*', '')
# https://www.jianshu.com/p/71d288a54072
# 使用?分割,分割后会返回一个列表:“[https://www.jianshu.com/p/71d288a54072]”
# https://www.jianshu.com/p/bebcd592b099?utm_campaign=maleskine&utm_content=note&utm_medium=seo_notes&utm_source=recommendation
# 使用?分割,分割后会返回一个列表:“[https://www.jianshu.com/p/71d288a54072, utm_campaign=maleskine&utm_content=note&utm_medium=seo_notes&utm_source=recommendation]”
url = response.url
url1 = url.split('?')[0] # 根据问号分割url,一般一个url只会有一个?
article_id = url1.split('/')[-1] # 根据斜杠分割拿到id
content = response.xpath('//div[@class="show-content-free"]').get()
word_count = response.xpath('//span[@class="wordage"]/text()').get()
comment_count = response.xpath('//span[@class="comment-count"]/text()').get()
read_count = response.xpath('//span[@class="views-count"]/text()').get()
like_count = response.xpath('//span[@class="likes-count"]/text()').get()
subjects = ','.join(response.xpath('//div[@class="include-collection"]/a/div/text()').getall())
item = ArticleItem(title=title,
avatar=avatar,
author=author,
pub_time=pub_time,
article_id=article_id,
origin_url=response.url,
content=content,
word_count=word_count,
comment_count=comment_count,
read_count=read_count,
like_count=like_count,
subjects=subjects)
yield item
修改settings.py代码

SeleniumDownloadMiddleware,使用selenium
JianshuTwistedPipeline,异步的方式插入数据库
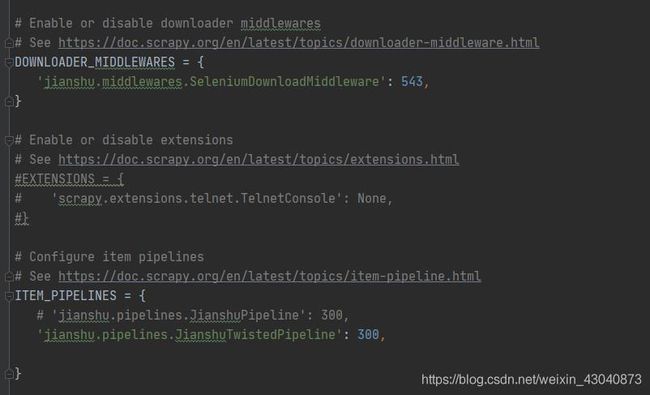
items.py代码
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ArticleItem(scrapy.Item):
title = scrapy.Field()
content = scrapy.Field()
article_id = scrapy.Field()
origin_url = scrapy.Field()
author = scrapy.Field()
avatar = scrapy.Field()
pub_time = scrapy.Field()
read_count = scrapy.Field()
like_count = scrapy.Field()
word_count = scrapy.Field()
comment_count = scrapy.Field()
subjects = scrapy.Field()
pipelins.py代码
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
class JianshuPipeline(object):
def __init__(self):
dbparams = {
'host': 'localhost',
'user': 'root',
'password': '数据库密码',
'database': 'jianshu',
'port': 3306,
'charset': 'utf8'} # MySQL里面不要写utf-8(不要带-)
self.conn = pymysql.connect(**dbparams)
# 把字典表以解包方式传值,相当于host='localhost', user='root'这种关键字参数
self.cursor = self.conn.cursor() # 创建游标
self._sql = None # sql语句
def process_item(self, item, spider):
self.cursor.execute(self.sql, (
item['title'],
item['content'],
item['author'],
item['avatar'],
item['pub_time'],
item['origin_url'],
item['article_id']
)) # 连接数据库并执行sql语句,传入一个元祖里面放入要插入的字段所对应的值
self.conn.commit() # 插入、删除、更改、都需要执行commit操作
return item
@property # 单独创建一个执行sql语句的属性
def sql(self):
if not self._sql: # 如果没有,就生成一个sql语句
self._sql = """
insert into article(id, title, content, author, avatar,
pub_time, origin_url, article_id) values(null, %s, %s, %s, %s, %s, %s, %s)
"""
return self._sql
return self._sql # 有的话 直接返回它
def close_spider(self, spider):
self.conn.close() # 关闭数据库连接
上面的同步方式很慢,一次插入一条每次都会等待
采用异步方式插入数据库:
from twisted.enterprise import adbapi # 专门做数据库处理的模块,用来创建数据库连接池
from pymysql import cursors # 数据库游标的模块,用来获取游标类对象
class JianshuTwistedPipeline(object):
def __init__(self):
dbparams = {
'host': 'localhost',
'user': 'root',
'password': '数据库密码',
'database': 'jianshu',
'port': 3306,
'charset': 'utf8',
'cursorclass': cursors.DictCursor}
self.dbpool = adbapi.ConnectionPool('pymysql', **dbparams)
# 第一个参数pymysql指的是当前连接数据库使用的模块,设置好这个以后它底层会去加载这个模块
# 第二个参数也是一样 以解包的方式传入数据库的一些信息,
# 只是需要多一个参数 'cursorclass': cursors.DictCursor (指定游标的类,不指定的话它不知道是哪一个类)
# self.cursor = self.conn.cursor() # 这一行创建游标的操作就不需要了
self._sql = None
@property
def sql(self):
if not self._sql: # 如果没有,就生成一个sql语句
self._sql = """
insert into article(id, title, content, author, avatar,
pub_time, origin_url, article_id) values(null, %s, %s, %s, %s, %s, %s, %s)
"""
return self._sql
return self._sql # 有的话 直接返回它
def process_item(self, item, spider):
defer = self.dbpool.runInteraction(self.insert_item, item)
# 通过dbpool.runInteraction把数据传给一个函数(self.insert_item)来执行插入操作
# 如果不这么传入一个函数的话直接在这里执行就跟上面同步的一样了
# 这里会把item和游标对象('cursorclass': cursors.DictCursor)同时传给下面的insert_item函数
defer.addErrback(self.handle_error, item, spider)
# 定义错误信息,在self.handle_error这个函数里做打印操作
return item
def insert_item(self, cursor, item): # 执行插入的函数
cursor.execute(self.sql, (
item['title'],
item['content'],
item['author'],
item['avatar'],
item['pub_time'],
item['origin_url'],
item['article_id']
)) # 连接数据库并执行sql语句,传入一个元祖里面放入要插入的字段所对应的值
def handle_error(self, error, item, spider):
print('='*10+'error'+'='*10)
print(error) # 打印错误信息
print('='*10+'error'+'='*10)
middlewares.py代码
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
from selenium import webdriver
import time
from scrapy.http.response.html import HtmlResponse # Response对象模块
'''使用selenium来执行,
这里就相当于把Scrapy模块半路截胡了,然后换成selenium模块来执行爬取部分'''
class SeleniumDownloadMiddleware(object):
def __init__(self):
self.driver = webdriver.Chrome(executable_path=r'D:\PycharmProjects\chromedriver\chromedriver.exe')
def process_request(self, request, spider):
self.driver.get(request.url) # 用selenium访问爬虫url
time.sleep(1)
try: # 专题-展开更多按钮
while True:
showMore = self.driver.find_element_by_class_name("show-more")
showMore.click() # 点击专题-展开更多按钮
if not showMore:
break
except:
pass # 如果捕获到异常说明没有展开更多按钮,就什么都不做
source = self.driver.page_source
response = HtmlResponse(url=self.driver.current_url, body=source, request=request, encoding='utf-8')
# 把selenium获取到的网页源代码source和网页url封装成response对象
return response # 最后再返回给response