爬虫(18)Scrapy简介
文章目录
- 第18章 Scrapy简介
-
- 1. 简介
- 2. 安装scrapy
- 3. Scrapy工作流程
- 4. Scrapy的快速入门
- 5.案例
- 6. 存储pipelines
第18章 Scrapy简介
1. 简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量的代码,就能够快速的抓取。
crapy使用了Twisted异步网络框架,可以加快我们的下载速度。
Scrapy可以把爬虫变得更快更强大。是异步爬虫框架。
优点是可配置,扩展性高。框架是基于异步的。Twisted异步网络框架。单词的意思是扭曲的的,代码里面有很多的闭包,函数嵌套。
介绍网站:http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/overview.html
2. 安装scrapy
这里安装颇费周折,中间出现两个报错,我是用换源安装的。后来百度发现scrapy的安装依赖几个库:
lxml、 pyOpenSSL 、 Twisted 、pywin32
第一个我安装过了,pyOpenSSL直接pip install 就可以了。 Twisted这个库的安装很不顺利,也是报错。后来用下载轮子的方法安装成功的。具体步骤:
- 打开轮子的网站:https://www.lfd.uci.edu/~gohlke/pythonlibs/
- 按Ctrl+F打开搜索栏,输入Twisted,点击进入
- 找到对应的版本,我的python是3.8的,电脑是64位的,所以找到了Twisted‑20.3.0‑cp38‑cp38‑win_amd64.whl这个版本
- 点击下载到本地
- 复制文件路径,右键文件,属性,安全,在最上方由文件路径C:\Users\MI\Downloads\Twisted-20.3.0-cp38-cp38-win_amd64.whl,下面是安装命令:
pip install C:\Users\MI\Downloads\Twisted-20.3.0-cp38-cp38-win_amd64.whl
瞬间完成。
- pywin32库是用中国科技大学的源,换源安装的https://pypi.mirrors.ustc.edu.cn/simple/
- 最后也用这个源换源安装scrapy
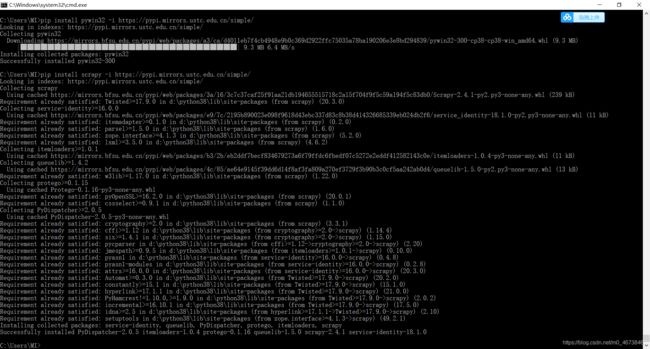
pip install scrapy -i https://pypi.mirrors.ustc.edu.cn/simple/
回车后瞬间安装成功,截个图:
我们可以通过
pip freeze > E:\pip.txt
命令导出所有的安装包来查看。
也可以通过命令
pip freeze -r E:\pip.txt
来安装所有的库。
3. Scrapy工作流程
这个工作流程如果明白了,就掌握了scrapy的60%了,不仅能够明白,而且要求面试的时候能够给面试官思路清晰的解释出来。
- 1 引擎整个框架的核心
- 2 调度器 接受从引擎发过来的url并入列
- 3 下载器 下载网页源码,返回给爬虫程序
- 4 项目管道 数据处理
- 5 下载中间件 处理引擎与下载器之间的请求
- 6 爬虫中间件 处理爬虫程序响应和输出结果,以及新的请求
- 7 下载中间件负责引擎与下载器之间的数据传输
- 8 爬虫中间件负责引擎与爬虫程序之间的数据传输
后面会附图
4. Scrapy的快速入门
第一步创建Scrapy项目
创建scrapy项目的命令:
scrapy startproject mySpider
mySpider是项目的名称,可以改变。其他的是固定语句,不可改变。
我们可以在自己的电脑pycharm里创建一个新的文件夹来存放项目,这里我命名为Scrapy_01
并拷贝一下路径,在pycharm终端里cd D:\work\爬虫\Day18\my_code\scrapy回车,然后就进入了项目文件夹。
我们按照创建项目的语句来创建:
D:\work>cd D:\work\爬虫\Day18\my_code\Scrapy_01
D:\work\爬虫\Day18\my_code\Scrapy_01>scrapy startproject mySpider
New Scrapy project 'mySpider', using template directory 'd:\python38\lib\site-packages\scrapy\templates\pr
oject', created in:
D:\work\爬虫\Day18\my_code\Scrapy_01\mySpider
You can start your first spider with:
cd mySpider
scrapy genspider example example.com
D:\work\爬虫\Day18\my_code\Scrapy_01>
我们打开项目文件夹Scrapy_01可以看到已经生成了新的文件夹,并且里面已经自动有了几个程序文件了。
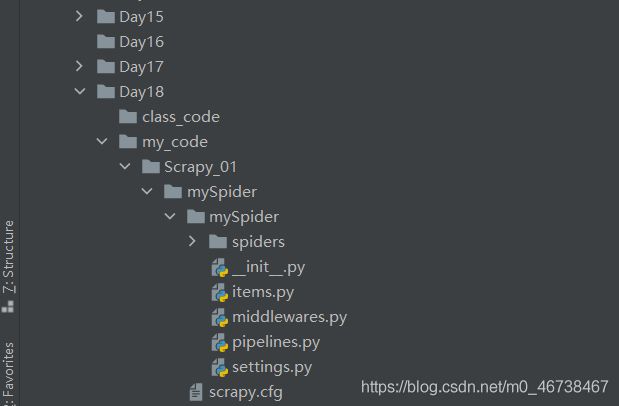
其中有个文件的后缀是cfg,和其他的文件不一样,这个文件是用来作一些提示和说明的。
第二步创建一个爬虫的程序
cd mySpider
scrapy genspider example example.com
example是爬虫程序的名字,example.com是要爬取的网站的域名(范围)。我们可以按照提示操作:
You can start your first spider with:
cd mySpider
scrapy genspider example example.com
D:\work\爬虫\Day18\my_code\Scrapy_01>cd mySpider
D:\work\爬虫\Day18\my_code\Scrapy_01\mySpider>
继续按照提示创建爬虫程序:
You can start your first spider with:
cd mySpider
scrapy genspider example example.com
D:\work\爬虫\Day18\my_code\Scrapy_01>cd mySpider
D:\work\爬虫\Day18\my_code\Scrapy_01\mySpider>scrapy genspider db douban.com
Created spider 'db' using template 'basic' in module:
mySpider.spiders.db
D:\work\爬虫\Day18\my_code\Scrapy_01\mySpider>
我们创建一个豆瓣爬虫程序,前面的db是程序的名字,后面的douban.com是爬取的范围,或叫域名。
Created spider 'db' using template 'basic' in module:
mySpider.spiders.db
这个语句代表我们的爬虫程序创建成功了。
我们看到在原来的项目文件夹里多出了我们刚才创建的爬虫项目文件db.py
我们点开看一下这个文件,发现里面有如下的代码:
import scrapy
class DbSpider(scrapy.Spider):
name = 'db'
allowed_domains = ['douban.com'] # 这个是可以修改的
start_urls = ['http://douban.com/'] # 这个也是可以修改成为我们要爬的网站的
def parse(self, response):
pass
我们点开看看items文件
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class MyspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
再点开看看middlewares
# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
# useful for handling different item types with a single interface
from itemadapter import is_item, ItemAdapter
class MyspiderSpiderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, or item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Request or item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class MyspiderDownloaderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
看看pipelines
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class MyspiderPipeline:
def process_item(self, item, spider):
return item
最后看看settints
# Scrapy settings for mySpider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
# scrapy项目名
BOT_NAME = 'mySpider'
SPIDER_MODULES = ['mySpider.spiders']
NEWSPIDER_MODULE = 'mySpider.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'mySpider (+http://www.yourdomain.com)'
# Obey robots.txt rules robots协议 ,一般改为False
ROBOTSTXT_OBEY = True
# 最大并发量,默认16
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
# 下载延迟默认是3秒
# DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
# CONCURRENT_REQUESTS_PER_DOMAIN = 16
# CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
# 请求头
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
# 爬虫中间件
#SPIDER_MIDDLEWARES = {
# 'mySpider.middlewares.MyspiderSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# 下载中间件
#DOWNLOADER_MIDDLEWARES = {
# 'mySpider.middlewares.MyspiderDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# 管道
#ITEM_PIPELINES = {
# 'mySpider.pipelines.MyspiderPipeline': 300,
#}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
5.案例
下面我们爬一个豆瓣的导航标签作为一个小案例。

我们右键>检查 来分析一下这些标签。

我们找到了最近的总标签,是class="side-links nav-anon"的div标签。我们再看看数据是不是在网页源码里,还是动态加载出来的。右键查看网页源码,Ctrl+F调出搜索栏,输入“科技”,发现找到了。证明在源码内。
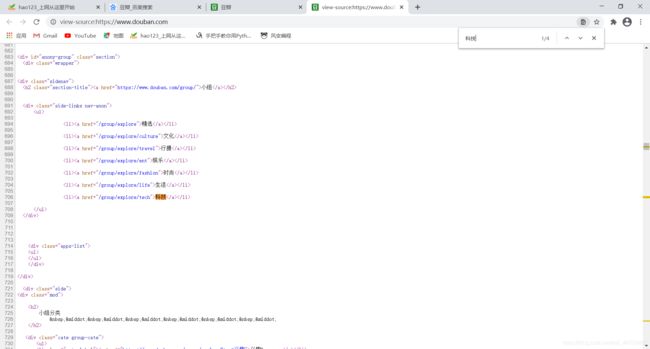
我们看到数据在网页源码里面。我们打开db程序:
import scrapy
class DbSpider(scrapy.Spider):
name = 'db'
allowed_domains = ['douban.com']
start_urls = ['http://douban.com/']
def parse(self, response):
pass
这里的response就是经过了爬虫程序以后的响应。
我们可以打印一下,看看得到什么数据。
def parse(self, response):
print(response)
我们运行的方法有两种,第一种是在终端输入scrapy crawl db回车,以下是结果:
Microsoft Windows [版本 10.0.18363.1316]
(c) 2019 Microsoft Corporation。保留所有权利。
D:\work\爬虫\Day18\my_code\Scrapy_01\mySpider>scrapy crawl db
2021-02-06 13:28:36 [scrapy.utils.log] INFO: Scrapy 2.4.1 started (bot: mySpider)
2021-02-06 13:28:36 [scrapy.utils.log] INFO: Versions: lxml 4.6.2.0, libxml2 2.9.5, cssselect 1.1.0, parse
l 1.6.0, w3lib 1.22.0, Twisted 20.3.0, Python 3.8.6rc1 (tags/v3.8.6rc1:08bd63d, Sep 7 2020, 23:10:23) [MS
C v.1927 64 bit (AMD64)], pyOpenSSL 20.0.1 (OpenSSL 1.1.1i 8 Dec 2020), cryptography 3.3.1, Platform Wind
ows-10-10.0.18362-SP0
2021-02-06 13:28:36 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.selectreactor.SelectReactor
2021-02-06 13:28:36 [scrapy.crawler] INFO: Overridden settings:
{'BOT_NAME': 'mySpider',
'NEWSPIDER_MODULE': 'mySpider.spiders',
'ROBOTSTXT_OBEY': True,
'SPIDER_MODULES': ['mySpider.spiders']}
2021-02-06 13:28:37 [scrapy.extensions.telnet] INFO: Telnet Password: c75195456bb7de41
2021-02-06 13:28:37 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2021-02-06 13:28:38 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2021-02-06 13:28:38 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2021-02-06 13:28:38 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2021-02-06 13:28:38 [scrapy.core.engine] INFO: Spider opened
2021-02-06 13:28:38 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (
at 0 items/min)
2021-02-06 13:28:38 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2021-02-06 13:28:38 [scrapy.core.engine] DEBUG: Crawled (403) (referer:
None)
2021-02-06 13:28:38 [scrapy.core.engine] DEBUG: Crawled (403) 真正的数据是在2021-02-06 13:28:38 [scrapy.core.engine] INFO: Spider opened
这句后面开始的,前面都是关于我们的爬虫程序的信息,包括scrapy的版本,python的版本,Twisted的版本。robot协议是True。
我们发现并没有我们想要的内容,出现了403错误。这是因为豆瓣的反爬功能。我们打开settings,在请求头那里DEFAULT_REQUEST_HEADERS 添加一个urser_agent。Robot协议那里改为False。然后我们再运行一下程序,为了看的更清晰,我们画个线:
import scrapy
class DbSpider(scrapy.Spider):
name = 'db'
allowed_domains = ['douban.com']
start_urls = ['http://douban.com/']
def parse(self, response):
print('*='*60)
print(type(response),response)
print('*=' * 60)
scrapy crawl db一下
2021-02-06 14:22:02 [scrapy.core.engine] DEBUG: Crawled (200) <200 https://www.douban.com/>
*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=
*=*=*=*=*=*=*=
2021-02-06 14:22:02 [scrapy.core.engine] INFO: Closing spider (finished)
两条线中间的内容是我们所要的。我们看到是 'scrapy.http.response.html.HtmlResponse’这样一个类型。这个类型里面封装了xpath方法,css方法,text方法,我们可以使用其语法进行解析。 那么我们可以找总标签:
def parse(self, response):
li_lst = response.xpath('//div[@class="side-links nav-anon"]/ul/li')
print('*='*60)
print(li_lst)
print('*='*60)
为了那些不必要的数据不要出现,方便我们看必要的数据,我们在settins里写一行代码:
LOG_LEVEL = 'WARNING'
我们回到db里面,scrapy crawl db 一下
D:\work\爬虫\Day18\my_code\Scrapy_01\mySpider>scrapy crawl db
*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=
*=*=*=*=*=*=*=
[, , , , , , , , , , , , , , , , , , , , , , , <
Selector xpath='//div[@class="side-links nav-anon"]/ul/li' data=', , , , , , , , ]
*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=
*=*=*=*=*=*=*=
D:\work\爬虫\Day18\my_code\Scrapy_01\mySpider>
发现得到的是列表,元素是selector对象,我们要的内容在里面。我们下面遍历列表,把我们要的数据提取出来以字典形式存储。
def parse(self, response):
li_lst = response.xpath('//div[@class="side-links nav-anon"]/ul/li')
item = {}
k = 0
for lst in li_lst:
k += 1
item['name%s'%k] = lst.xpath('a/text()')
print('*=' * 60)
print(item)
print('*=' * 60)
scrapy crawl db一下
D:\work\爬虫\Day18\my_code\Scrapy_01\mySpider>scrapy crawl db
*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=
*=*=*=*=*=*=*=
{'name1': [], 'name2': [], 'name3': [], 'name4': [], 'name5': [], 'name6': [], 'name7': [], 'name8': [], 'name9': [], 'name10': [], 'name11': [], 'name12': [], 'name13': [], 'name14': [], 'name15': [], 'name16': [], 'name17': [], 'name18': [], 'name19': [], 'name20': [, ], 'name21': [], 'name22': [], 'name23': [], 'name24': [], 'name25'
: [], 'name26': [], 'n
ame27': [], 'name28': [],
'name29': [], 'name30': [], 'name31': [], 'name32': [], 'name33': []}
*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=
*=*=*=*=*=*=*=
D:\work\爬虫\Day18\my_code\Scrapy_01\mySpider>
selector对象中有四个方法,可以提取出数据:
extract_first() # 取出第一个数据
extract() # 取出所有数据
get() # 取出第一个数据
getall() # 取出所有数据
其中前两个属于旧方法,后两个属于新方法。
def parse(self, response):
li_lst = response.xpath('//div[@class="side-links nav-anon"]/ul/li')
item = {}
k = 0
for lst in li_lst:
# k += 1
item['name'] = lst.xpath('a/text()').extract_first()
# print('*=' * 60)
print(item)
scrapy crawl db一下
D:\work\爬虫\Day18\my_code\Scrapy_01\mySpider>scrapy crawl db
{'name': '影讯&购票'}
{'name': '选电影'}
{'name': '电视剧'}
{'name': '排行榜'}
{'name': '分类'}
{'name': '影评'}
{'name': '预告片'}
{'name': '问答'}
{'name': '精选'}
{'name': '文化'}
{'name': '行摄'}
{'name': '娱乐'}
{'name': '时尚'}
{'name': '生活'}
{'name': '科技'}
{'name': '分类浏览'}
{'name': '阅读'}
{'name': '作者'}
{'name': '书评'}
{'name': '\n '}
{'name': '音乐人'}
{'name': '潮潮豆瓣音乐周'}
{'name': '金羊毛计划'}
{'name': '专题'}
{'name': '排行榜'}
{'name': '分类浏览'}
{'name': '乐评'}
{'name': '豆瓣FM'}
{'name': '歌单'}
{'name': '阿比鹿音乐奖'}
{'name': '近期活动'}
{'name': '主办方'}
{'name': '舞台剧'}
D:\work\爬虫\Day18\my_code\Scrapy_01\mySpider>
我们看到在’书评’和’音乐人’之间有一个数据没有打印出来,我们查看一下是怎么回事。
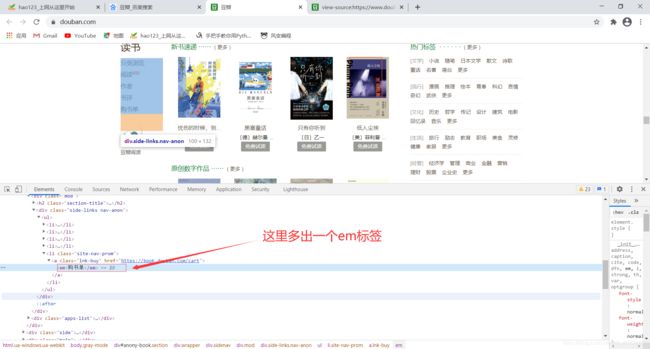
于是我们把代码改一下:
import scrapy
class DbSpider(scrapy.Spider):
name = 'db'
allowed_domains = ['douban.com']
start_urls = ['http://douban.com/']
def parse(self, response):
li_lst = response.xpath('//div[@class="side-links nav-anon"]/ul/li')
item = {}
k = 0
for lst in li_lst:
item['name'] = lst.xpath('a/em/text()').extract_first()
if item['name'] == None:
item['name'] = lst.xpath('a/text()').extract_first()
print(item)
else:
print(item)
scrapy crawl db一下
D:\work\爬虫\Day18\my_code\Scrapy_01\mySpider>scrapy crawl db
{'name': '影讯&购票'}
{'name': '选电影'}
{'name': '电视剧'}
{'name': '排行榜'}
{'name': '分类'}
{'name': '影评'}
{'name': '预告片'}
{'name': '问答'}
{'name': '精选'}
{'name': '文化'}
{'name': '行摄'}
{'name': '娱乐'}
{'name': '时尚'}
{'name': '生活'}
{'name': '科技'}
{'name': '分类浏览'}
{'name': '阅读'}
{'name': '作者'}
{'name': '书评'}
{'name': '购书单'}
{'name': '音乐人'}
{'name': '潮潮豆瓣音乐周'}
{'name': '金羊毛计划'}
{'name': '专题'}
{'name': '排行榜'}
{'name': '分类浏览'}
{'name': '乐评'}
{'name': '豆瓣FM'}
{'name': '歌单'}
{'name': '阿比鹿音乐奖'}
{'name': '近期活动'}
{'name': '主办方'}
{'name': '舞台剧'}
D:\work\爬虫\Day18\my_code\Scrapy_01\mySpider>
这次全部爬取出来了。
我们还可以在pycharm控制台运行程序,具体方法是在mySpider文件夹里创建一个py文件,可以命名为start。代码这样写:
from scrapy import cmdline
cmdline.execute('scrapy crawl db'.split())
# 或者
# cmdline.execute(['scrapy','crawl','db'])
运行一下

同样的结果。
这是关于scrapy的一个应用的小案例。
6. 存储pipelines
上一步我们已经得到了数据,如果我们只是打印出来,或者再自己设计存储程序就太蠢了,因为scrapy已经帮我们做了,这就是pipelines的工作。
我们把爬取的数据交给pipelines来处理,具体方法如下:
- 找到settings里的ITEM_PIPELINES
- 把注释打开
ITEM_PIPELINES = {
'mySpider.pipelines.MyspiderPipeline': 300,
}
将db里面的后面加return
import scrapy
class DbSpider(scrapy.Spider):
name = 'db'
allowed_domains = ['douban.com']
start_urls = ['http://douban.com/']
def parse(self, response):
li_lst = response.xpath('//div[@class="side-links nav-anon"]/ul/li')
item = {}
k = 0
for lst in li_lst:
item['name'] = lst.xpath('a/em/text()').extract_first()
if item['name'] == None:
item['name'] = lst.xpath('a/text()').extract_first()
return item
在pipelines里加上打印语句,
class MyspiderPipeline:
def process_item(self, item, spider):
print(item)
return item
运行一下start看看有没有结果。
{'name': '影讯&购票'}
结果只有一个数据。在scrapy里,我们不用return,用yield。
import scrapy
class DbSpider(scrapy.Spider):
name = 'db'
allowed_domains = ['douban.com']
start_urls = ['http://douban.com/']
def parse(self, response):
li_lst = response.xpath('//div[@class="side-links nav-anon"]/ul/li')
item = {}
k = 0
for lst in li_lst:
item['name'] = lst.xpath('a/em/text()').extract_first()
if item['name'] == None:
item['name'] = lst.xpath('a/text()').extract_first()
# return item
yield item
再运行一下:
D:\Python38\python.exe D:/work/爬虫/Day18/my_code/Scrapy_01/mySpider/mySpider/start.py
{'name': '影讯&购票'}
{'name': '选电影'}
{'name': '电视剧'}
{'name': '排行榜'}
{'name': '分类'}
{'name': '影评'}
{'name': '预告片'}
{'name': '问答'}
{'name': '精选'}
{'name': '文化'}
{'name': '行摄'}
{'name': '娱乐'}
{'name': '时尚'}
{'name': '生活'}
{'name': '科技'}
{'name': '分类浏览'}
{'name': '阅读'}
{'name': '作者'}
{'name': '书评'}
{'name': '购书单'}
{'name': '音乐人'}
{'name': '潮潮豆瓣音乐周'}
{'name': '金羊毛计划'}
{'name': '专题'}
{'name': '排行榜'}
{'name': '分类浏览'}
{'name': '乐评'}
{'name': '豆瓣FM'}
{'name': '歌单'}
{'name': '阿比鹿音乐奖'}
{'name': '近期活动'}
{'name': '主办方'}
{'name': '舞台剧'}
Process finished with exit code 0
db里面的打印语句我们已经删掉了,只有pipelines里面有打印语句,所以这个结果被传递到pipelines管道里了。
那么下面我们可以对pipelines进行操作。
import json
class MyspiderPipeline:
def __init__(self):
self.f = open('demo.json','w',encoding='utf-8')
def open_spider(self): # 爬虫开始的名字不能改变
print('爬虫开始了')
def process_item(self, item, spider):
item_json = json.dumps(item)
self.f.write(item)
print(item)
return item
def close_spider(self): # 爬虫结束的名字不能改变
print('爬虫结束了')
我们运行一下试试:
yield self.engine.open_spider(self.spider, start_requests)
builtins.TypeError: open_spider() takes 1 positional argument but 2 were given
2021-02-06 17:33:32 [twisted] CRITICAL:
Traceback (most recent call last):
File "D:\Python38\lib\site-packages\twisted\internet\defer.py", line 1418, in _inlineCallbacks
result = g.send(result)
File "D:\Python38\lib\site-packages\scrapy\crawler.py", line 89, in crawl
yield self.engine.open_spider(self.spider, start_requests)
TypeError: open_spider() takes 1 positional argument but 2 were given
报了个错
“open_spider()接受1个位置参数,但给出了2个”
缺少了一个位置参数,我们就随便再设置一个。
from itemadapter import ItemAdapter
import json
class MyspiderPipeline:
def __init__(self):
self.f = open('demo.json','w',encoding='utf-8')
def open_spider(self,item): # 爬虫开始的名字不能改变
print('爬虫开始了')
def process_item(self, item, spider):
item_json = json.dumps(item)
self.f.write(item_json)
print(item)
return item
def close_spider(self,item): # 爬虫结束的名字不能改变
print('爬虫结束了')
再运行
D:\Python38\python.exe D:/work/爬虫/Day18/my_code/Scrapy_01/mySpider/mySpider/start.py
爬虫开始了
{'name': '影讯&购票'}
{'name': '选电影'}
{'name': '电视剧'}
{'name': '排行榜'}
{'name': '分类'}
{'name': '影评'}
{'name': '预告片'}
{'name': '问答'}
{'name': '精选'}
{'name': '文化'}
{'name': '行摄'}
{'name': '娱乐'}
{'name': '时尚'}
{'name': '生活'}
{'name': '科技'}
{'name': '分类浏览'}
{'name': '阅读'}
{'name': '作者'}
{'name': '书评'}
{'name': '购书单'}
{'name': '音乐人'}
{'name': '潮潮豆瓣音乐周'}
{'name': '金羊毛计划'}
{'name': '专题'}
{'name': '排行榜'}
{'name': '分类浏览'}
{'name': '乐评'}
{'name': '豆瓣FM'}
{'name': '歌单'}
{'name': '阿比鹿音乐奖'}
{'name': '近期活动'}
{'name': '主办方'}
{'name': '舞台剧'}
爬虫结束了
Process finished with exit code 0
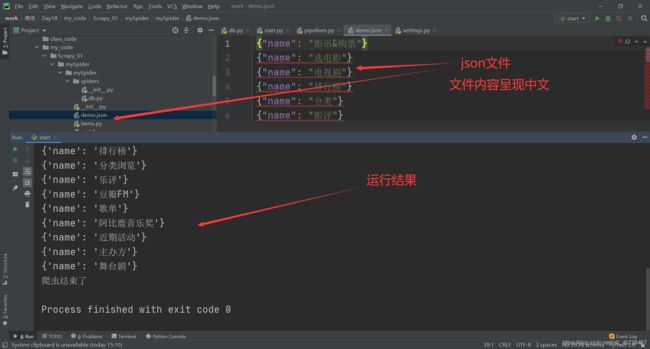
这次全部打印出来,我们看看保存的json文件:

点开看看

发现全再一行里面,而且没有中文,全是ASCII编码,我们需要设置一下json.dumps语句
item_json = json.dumps(item,ensure_ascii=False) # json.dumps默认ascii编码,这里设置ascii为False
而且在后面的spider_close()语句里面加上self.f.close()语句。写入的时候加上换行符。
from itemadapter import ItemAdapter
import json
class MyspiderPipeline:
def __init__(self):
self.f = open('demo.json','w',encoding='utf-8')
def open_spider(self,item): # 爬虫开始的名字不能改变
print('爬虫开始了')
def process_item(self, item, spider):
item_json = json.dumps(item,ensure_ascii=False)
self.f.write(item_json+'\n')
print(item)
return item
def close_spider(self,item): # 爬虫结束的名字不能改变
self.f.close()
print('爬虫结束了')
再运行一下
总结:
- 在爬虫程序中要使用yield关键字,把爬虫文件传递给pipelines
- settings文件里一定要开启管道
- open_spider() 爬虫开始了,后面open函数创建文件保存数据 这里方法名不能改变
- close_spider() 爬虫结束了,后面跟self.f.close()关闭文件 这里方法名不能改变
- json.dumps()里面的编码方式默认是ascii