通过实例学习RobotFrameWork - 2
这次我们来分析代码拉~~
测试实例代码分析
(注:本次分析代码较文章1中代码有部分改动,以本文为准)
1. RFS基本介绍
1.1 RobotFramework 架构
在进行代码分析之前,我们先来简单地介绍一下RobotFramework的文件、代码结构及语法。我们给出RobotFramework官方的架构图:
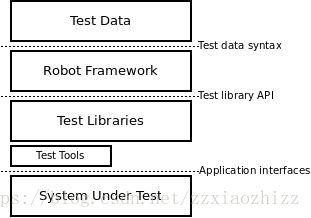
这里有一个很重要的概念是,RobotFrameWork将用户编写的大部分文件,包括test case, resource文件等都称为 Test data, 这一点需要跟我们印象中的测试数据区别开。根据架构图,RobotFrameWork将整个测试流程中涉及到的各个部分做了模块化处理:用户只需要关注具体逻辑,在TestData文件中 使用RobotFramework层中封装好的关键字对下层系统进行测试。然而RobotFramework本身并不知道下层待测系统究竟是何种应用,是Web还是数据库还是移动端,所有的具体操作都是通过调用加载进来的test libraries以及其他test tools(例如selenium driver, 以及用户自定义的代码,关键字)的接口,来实现对待测系统的操作。举一个粗糙的例子,如果我们的测试逻辑是:
· 打开浏览器
· 访问特定网址
· 点击一个button
· 产生一个结果
· 关闭浏览器
TestData层面的代码可以用上述关键字来编写。在中间层,如果加载的是Selenium2Library 并设置测试网站,此套用例就适用于网站自动化测试;如果我们加载AppiumLibrary并设置手机端,那么RobotFramework便会在手机端按照同样的逻辑进行操作。客户只写一套关键字用例,具体的web操作或者手机端操作,都是由Selenium2Library或者AppniumLibrary来执行。
1.2 文件及目录结构
1.2.1 测试用例文件
测试用例文件(Test Case files)是RobotFramework最基本的文件。一个测试用例文件中可以包括多条测试用例及其具体的测试步骤。同时,每个测试用例文件都会自然生成一个Test Suite。我们通过实例的代码来理解这句话:
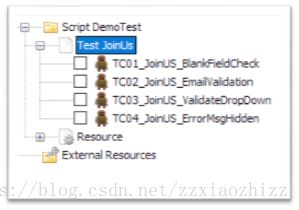
从RIDE中的树形图我们可以到,本次demo的测试代码中有一个名为Test JoinUS的Test suite,下面包含了4条测试用例,以TC01 – TC04进行命名。我们转到测试代码实际存放的文件夹:
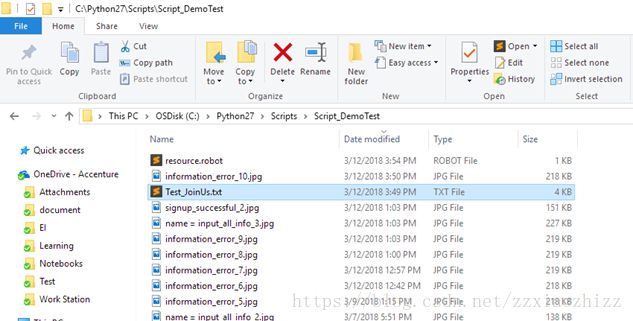
我们可以看到实际的测试用例只是以Test Suite名字命名的一个文本文件 Test_JoinUs.txt
而打开文件后我们可以看到:
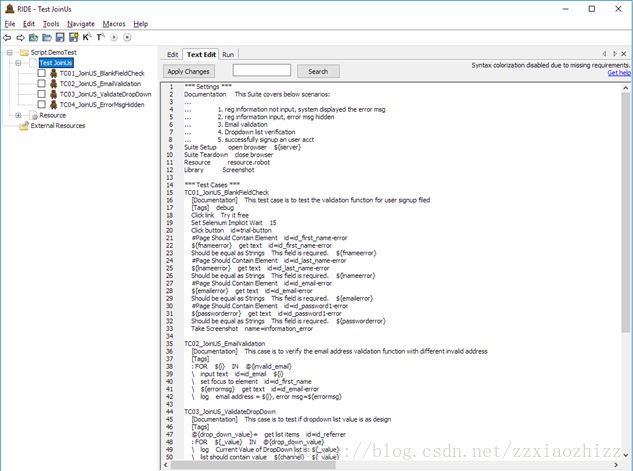
代码通过***Test Cases***来定义测试用例的开始。每一个测试用例名称和代码之间使用类似python语法的缩进来判定。
1.2.2 目录
现阶段我们可以简单地理解为目录就是存放Test Suite files以及初始化文件 __init__.ext的文件夹,与windows文件夹结构类似,支持嵌套。
1.2.3 Test data 文件类型
RobotFramework支持的文件类型包括
· HTML
· TSV(一种使用Tab键来分割单元格的文件)
· reStructuredText - 一种轻量级的文本标记语言,与MarkDown类似
· Plain Text
由于HTML, reStructuredText有语法学习成本, TSV格式在编辑处理方面较为不便。因此推荐使用Plain Text来编写测试用例。
1.2.4 Test data 文件 内容格式
RobotFrameWork定义每一个独立的Test data文件都包含下面四部分内容
Table |
Used for |
***Settings*** |
1) Importing test libraries, resource files and variable files. 2) Defining metadata for test suites and test cases. |
***Variables*** |
Defining variables that can be used elsewhere in the test data. |
***Test Cases*** |
Creating test cases from available keywords. |
***Keywords*** |
Creating user keywords from existing lower-level keywords |
我们可以简单地做如下理解:
Setting – 定义了说明性文档,引用的库,标签,以及测试用例的Setup, Teardown等配置信息
Variables – 文件中所用到的变量
TestCases – 具体的测试用例描述及操作步骤
Keywords – 用户自定义的关键字,是对系统关键字的再次封装。
以上就是对RobotFrameWork文档的一些粗略的介绍,下面我们进入测试实例的分析
2. 测试实例代码分析
2.1 Resource代码分析
2.1.1 代码截图

2.1.2 代码文本
*** Settings ***
Documentation A resource file with Library, reusablekeywords and varilables.
... The system specific keywardscreated here for our own domain specific language
Library Selenium2Library
Library Screenshot ${CURDIR}
Library OperatingSystem
Library Collections
*** Variables***
${server} https://www.safaribooksonline.com/
${browser} Chrome
@{invalid_email} 123 asd @ 123@ @wer 123#asdw
@{channel} Please select an option Other Friend or Co-worker Conferenceor Trade-show Radio Ad Blog News (Website, TV, or Radio)
... Email TVAd Search Engine Social Media (Facebook, LinkedIn, Twitter,etc.) Podcast2.1.3 代码分析
从RIDE工具的Edit页面分析,首先,setting中定义了说明文档,类似代码开发中的最开始的注释文档,是对整个文件的一个介绍;其次,我们在resource中引入了Selenium2Library,Screenshot,OperatingSystem,Collection这几个库,在下面的test case中,我们会用到这几个库中封装好的关键字;最后,我们定义了变量,其中:
${server} – 定义了待测网站
${browser} – 定义了测试使用的浏览器
@{invalid_email} – 测试数据列表,定义了用于测试email地址验证模块的无效email地址
@{channel} – 测试数据列表,定义了下拉列表的期待值
在这里我们需要注意的是,如果是单独的变量,我们的前缀使用$;如果是列表变量,我们的前缀使用@。
2.2 TestCase 代码分析
2.2.1 Test Suite设置
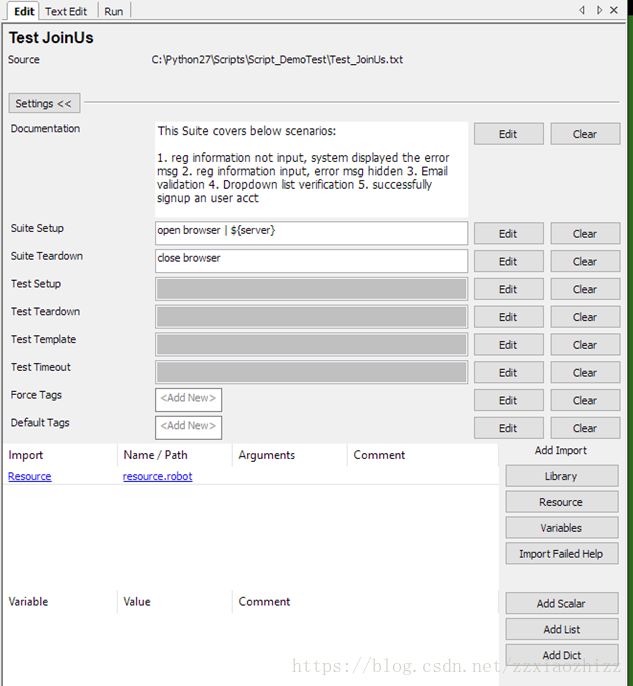
如前文所述,Test suite 在RIDE上显示为一个单独的节点,实际是test case的一部分。通过截图可以看到,test suite通过Documentation描述了此文件所要涵盖的测试点,然后通过Suite Setup和Suite Teardown设置了每次suite运行前和运行完成后所要进行的打开,关闭浏览器操作,这么做的原因是suite中所包含的4个用例是一个end to end flow,也就是说四个用例一个接一个执行,互相之间有联系,因此只定义整个suite的开始和结束动作即可。
最后,我们用过Import引入上一章节定义好的resource文件,使接下来的测试用例可以调用resource中所引入的库。
2.2.2 Test Case01 – 验证空白文本框
分析用例代码之前,我们先来看一下RIDE的优点。使用RIDE最大的好处在于:
第一可以第一时间知道编写的代码是否正确,因为RIDE 可以自动将合法的内置关键字标为蓝色粗体,参数使用正常的黑色字体,变量使用正常的绿色字体,而且绝大多数情况下不需要担心大小写和参数双引号的问题。
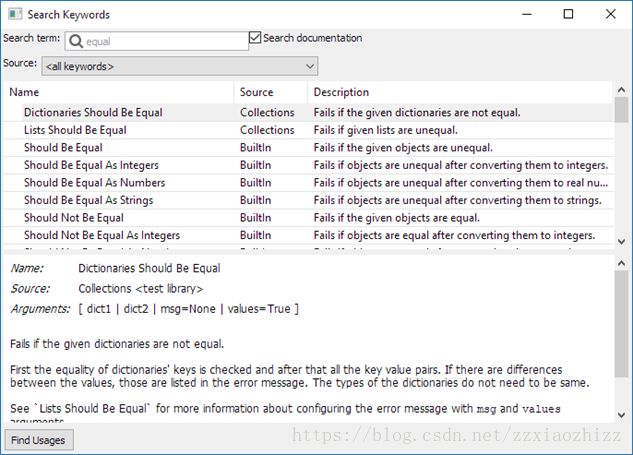
第二,如果需要查询某些狗能具体的用法,随时可以按F5,RIDE会弹出帮助文档,其实详细的描述了各种关键字的用法,并且支持模糊查询功能。例如,想知道如何判断2个对象是否相等,就可以在F5中直接搜索equal,所有和equal有关的关键字及其使用方法,参数都会显示出来,不必再去网页或者帮助文档中查看。
再看代码
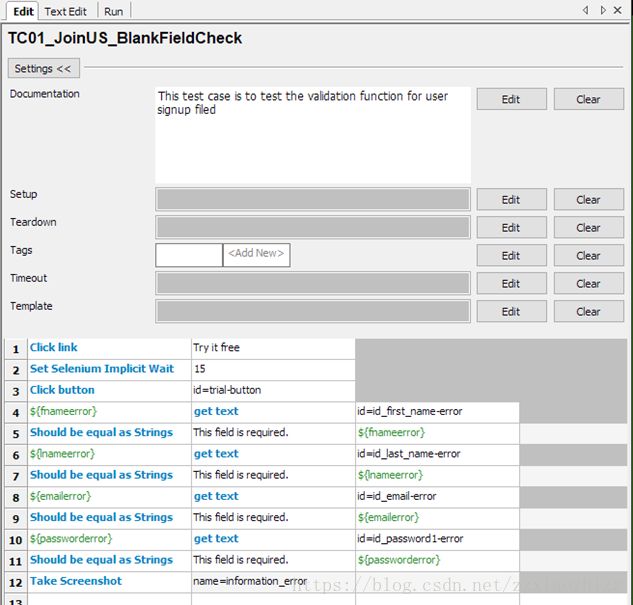
a. 用Click link关键字实现 点击链接 的操作,后面的Try it free就是链接的文字
b. Set SeleniumImplicit Wait, 设置隐式等待时间
c. Click button关键字,实现 点击按钮 的操作,后面id=trial-button是button这个网页元素的定位值(locator),相当于python代码的driver.getElementbyID(“trial-button”). 这里可以看到,RIDE本身不关注双引号,再也不用担心整篇代码有有没有中文格式的双引号所引起的代码错误。Buttonas
d. 接下来,使用${}设置了4个变量用于存放网页上的错误提示信息,提示信息的提取使用gettext关键字,locator使用ID。之后,使用关键字Should be equal as Strings来判断关键字后面的2个参数- 每个变量所存放的信息及期待值(Thisfield is required)是否一致。
e. 最后,在所有步骤完成后使用关键字Take screenshot来截取关键截图,并命名为information_error
总结用例一中所用到的操作方法:
链接的定位及点击,button的定位及点击,变量赋值,Strings对比及最后的截图。
2.2.3 Test Case02 – Email地址验证
在用例二中,我们来看一下RF中的循环是如何使用的,使大家对 多数据验证同一功能点的方式有一个认识。
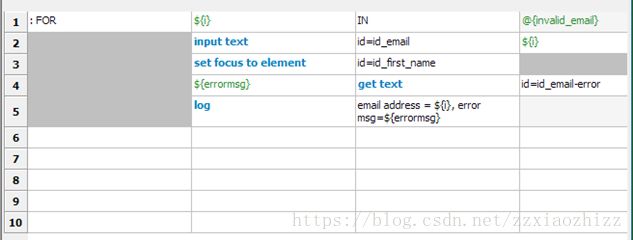
首先,语法与Python的变成代码类似,使用 For i IN Range的形式实现。@{invalid_email}是之前在资源文件中定义好的非法email地址列表。用 ${i} 遍历地址列表,每一次遍历都进行如下操作:
a. 取出列表中的值,使用Input text关键字输入到email地址栏
b. 使用set focus toelement实现光标焦点移到其他元素,触发地址栏对输入地址的验证
c. 通过get text关键字取出email地址的错误提示并存放于${errormsg}变量。
d. 在log文件中,记录每次迭代的非法Email地址以及错误信息
总结用例二中所用的到操作方法:
For 循环;输入文本关键字;Log记录关键字
2.2.4 Test Case03 – 下拉列表值校验
在用例三中我们继续使用循环来验证下拉列表值是否与期待值一致。
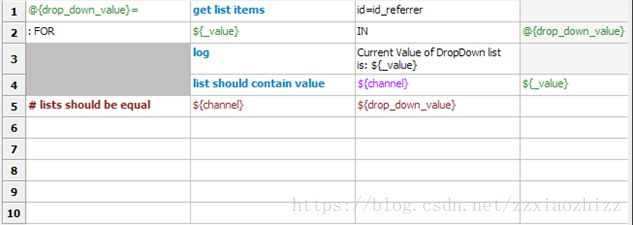
首先,使用get list items关键字取出下拉列表中所有的值,并存放于自定义的列表变量@{drop_down_value}中。
其次,使用for 循环,遍历下拉列表中每一个值,并进行下列操作:
a. 使用log关键字记录当前遍历列表值
b. 使用list should containvalue关键字。通过语义可以理解为此关键字用于验证给定列表中是否包含待测值,这里我们来判断在resource中定义的列表变量@{channel}是否包含每个遍历到的下拉列表值。
需要注意的是,尽管在resource中定义的列表变量是@{}形式,但是RF在所有列表相关的比较及操作关键字中,如果列表作为参数,就一定要将@改写为$,否则会发生运行错误。
c. 最后我们使用#注释掉一句代码# lists should be equal.此关键字的作用是比较给定的2个列表是否从长度到顺序都一致。在实际项目中,可以根据不同的需求进行选择。
2.2.5 Test Case04 – 空白文本框错误隐藏及注册成功
最后,在用例四中我们主要关注下面几个关键字的使用:
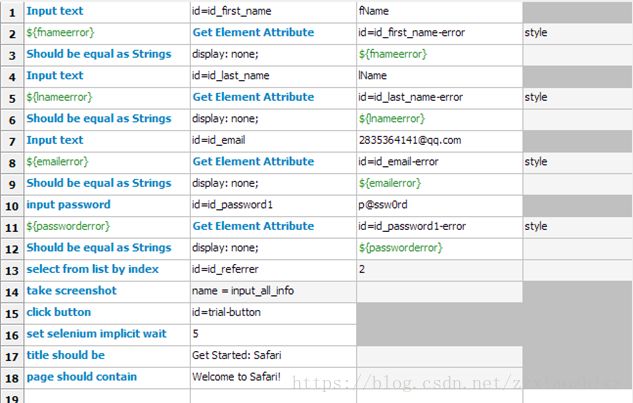
a. 关键字 select from listby index. 此关键字实现了通过索引编号(从0开始)来选择下拉列表的值,2个参数,第一个是locator, 第二个为索引值。
b. 关键字 title should be. 此关键字用来判断页面的title值是否满足给定期待值。
c. 关键字 page shouldcontain. 此关键字会遍历页面上所有的信息,并判断是否包含给定的期待值。
2.3 总结
至此,本次实例中对于代码的分析到此结束,再次总结一下使用RFS+RIDE编写测试代码的优势:
a. 关键字驱动,将底层操作代码封装,对于用户来说只需要使用与自然语言极为相似的关键字便可以编写自动化操作代码。
b. 关键字查询的便利,按F5便可以模糊查询各种关键字的用法。
c. 合法关键字的加粗高亮,大小写不敏感,不用写引号。
最后,如果要说RF有没有缺点的话,个人认为是环境的搭建特别是对MAC系统搭建环境不是很友好。大家如果看到这里,对于RF的兴趣依旧存在并想自己搭建RFS环境进行实践,请关注本系列最后一篇,RobotFrameWork测试环境搭建。