RocketMQ的原理及应用,与RabbitMQ如何保证消费顺序的吗?以及它们是如何保证消息不丢失的吗?
一、简介
RocketMQ 是一款开源的分布式消息系统,基于高可用分布式集群技术,提供低延时的、高可靠的消息发布与订阅服务。 最初是由阿里开源的分布式消息引擎,由于后面维护问题,提交给Apache下的顶级维护项目之一。现在最新版本V4.8.0,如需了解官网地址:https://rocketmq.apache.org
消息队列作为高并发系统的核心组件之一,能够帮助业务系统解构提升开发效率和系统稳定性。主要具有以下优势:
- 削峰填谷(主要解决瞬时写压力大于应用服务能力导致消息丢失、系统奔溃等问题)
- 系统解耦(解决不同重要程度、不同能力级别系统之间依赖导致一死全死)
- 提升性能(当存在一对多调用时,可以发一条消息给消息系统,让消息系统通知相关系统)
- 蓄流压测(线上有些链路不好压测,可以通过堆积一定量消息再放开来压测)
目前主流的MQ主要是Rocketmq、kafka、Rabbitmq,Rocketmq相比于Rabbitmq、kafka具有主要优势特性有:
1.支持事务型消息(消息发送和DB操作保持两方的最终一致性,rabbitmq和kafka不支持)
2.支持结合rocketmq的多个系统之间数据最终一致性(多方事务,二方事务是前提)
3.支持18个级别的延迟消息(rabbitmq和kafka不支持)
4.支持指定次数和时间间隔的失败消息重发(kafka不支持,rabbitmq需要手动确认)
5.支持consumer端tag过滤,减少不必要的网络传输(rabbitmq和kafka不支持)
6.支持重复消费(rabbitmq不支持,kafka支持)
二、RocketMQ集群部署结构:
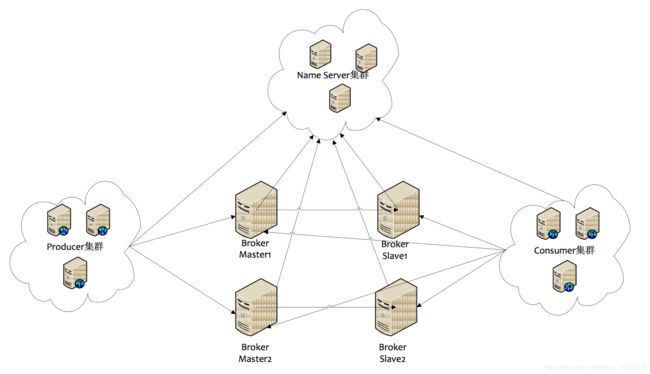
1) Name Server
Name Server是一个几乎无状态节点,可集群部署,节点之间无任何信息同步。
2) Broker
Broker部署相对复杂,Broker分为Master与Slave,一个Master可以对应多个Slave,但是一个Slave只能对应一个Master,Master与Slave的对应关系通过指定相同的Broker Name,不同的Broker Id来定义,BrokerId为0表示Master,非0表示Slave。Master也可以部署多个。
每个Broker与Name Server集群中的所有节点建立长连接,定时(每隔30s)注册Topic信息到所有Name Server。Name Server定时(每隔10s)扫描所有存活broker的连接,如果Name Server超过2分钟没有收到心跳,则Name Server断开与Broker的连接。
3) Producer
Producer与Name Server集群中的其中一个节点(随机选择)建立长连接,定期从Name Server取Topic路由信息,并向提供Topic服务的Master建立长连接,且定时向Master发送心跳。Producer完全无状态,可集群部署。
Producer每隔30s(由ClientConfig的pollNameServerInterval)从Name server获取所有topic队列的最新情况,这意味着如果Broker不可用,Producer最多30s能够感知,在此期间内发往Broker的所有消息都会失败。
Producer每隔30s(由ClientConfig中heartbeatBrokerInterval决定)向所有关联的broker发送心跳,Broker每隔10s中扫描所有存活的连接,如果Broker在2分钟内没有收到心跳数据,则关闭与Producer的连接。
4) Consumer
Consumer与Name Server集群中的其中一个节点(随机选择)建立长连接,定期从Name Server取Topic路由信息,并向提供Topic服务的Master、Slave建立长连接,且定时向Master、Slave发送心跳。Consumer既可以从Master订阅消息,也可以从Slave订阅消息,订阅规则由Broker配置决定。
Consumer每隔30s从Name server获取topic的最新队列情况,这意味着Broker不可用时,Consumer最多最需要30s才能感知。
Consumer每隔30s(由ClientConfig中heartbeatBrokerInterval决定)向所有关联的broker发送心跳,Broker每隔10s扫描所有存活的连接,若某个连接2分钟内没有发送心跳数据,则关闭连接;并向该Consumer Group的所有Consumer发出通知,Group内的Consumer重新分配队列,然后继续消费。
当Consumer得到master宕机通知后,转向slave消费,slave不能保证master的消息100%都同步过来了,因此会有少量的消息丢失。但是一旦master恢复,未同步过去的消息会被最终消费掉。
消费者对列是消费者连接之后(或者之前有连接过)才创建的。我们将原生的消费者标识由 {IP}@{消费者group}扩展为 {IP}@{消费者group}{topic}{tag},(例如xxx.xxx.xxx.xxx@mqtest_producer-group_2m2sTest_tag-zyk)。任何一个元素不同,都认为是不同的消费端,每个消费端会拥有一份自己消费对列(默认是broker对列数量*broker数量)。新挂载的消费者对列中拥有commitlog中的所有数据。
三、RocketMQ如何支持分布式事务:
应用场景:
A(存在DB操作)、B(存在DB操作)两方需要保证分布式事务一致性,通过引入中间层MQ,A和MQ保持事务一致性(异常情况下通过MQ反查A接口实现check),B和MQ保证事务一致(通过重试),从而达到最终事务一致性。
原理:大事务 = 小事务 + 异步
MQ与DB一致性原理(双方事务):

上图是RocketMQ提供的保证MQ消息、DB事务一致性的方案。
MQ消息、DB操作一致性方案:
-
发送消息到MQ服务器,此时消息状态为SEND_OK。此消息为consumer不可见。
-
执行DB操作;DB执行成功Commit DB操作,DB执行失败Rollback DB操作。
-
如果DB执行成功,回复MQ服务器,将状态为COMMIT_MESSAGE;如果DB执行失败,回复MQ服务器,将状态改为ROLLBACK_MESSAGE。注意此过程有可能失败。
-
MQ内部提供一个名为“事务状态服务”的服务,此服务会检查事务消息的状态,如果发现消息未COMMIT,则通过Producer启动时注册的TransactionCheckListener来回调业务系统,业务系统在checkLocalTransactionState方法中检查DB事务状态,如果成功,则回复COMMIT_MESSAGE,否则回复ROLLBACK_MESSAGE。
说明:
上面以DB为例,其实此处可以是任何业务或者数据源。
以上SEND_OK、COMMIT_MESSAGE、ROLLBACK_MESSAGE均是client jar提供的状态,在MQ服务器内部是一个数字。
TransactionCheckListener 是在消息的commit或者rollback消息丢失的情况下才会回调(上图中灰色部分)。这种消息丢失只存在于断网或者rocketmq集群挂了的情况下。当rocketmq集群挂了,如果采用异步刷盘,存在1s内数据丢失风险,异步刷盘场景下保障事务没有意义。所以如果要核心业务用Rocketmq解决分布式事务问题,建议选择同步刷盘模式。
四、RocketMQ如何保证消费顺序:
Produce在发送消息的时候,把消息发到同一个队列(Queue)中,消费者注册消息监听器为MessageListenerOrderly,这样就可以保证消费端只有一个线程去消费消息。
注意:把消息发到同一个队列(queue),不是同一个topic,默认情况下一个topic包括4个queue
拓展:可以通过实现发送消息的对列选择器方法,实现部分顺序消息。
举例:比如一个数据库通过MQ来同步,只需要保证每个表的数据是同步的就可以。解析binlog,将表名作为对列选择器的参数,这样就可以保证每个表的数据到同一个对列里面,从而保证表数据的顺序消费
总结: Producer端保证发送消息有序,且发送到同一个队列; Consumer端保证消费同一个队列有且只有一个线程消费。
五、RocketMQ如何保证消息不丢失:
分别从Producer发送机制、Broker的持久化机制,以及消费者的offSet机制来最大程度保证消息不易丢失。
- Producer的视角来看:如果消息未能正确的存储在MQ中,或者消费者未能正确的消费到这条消息,都是消息丢失。
- Broker的视角来看:如果消息已经存在Broker里面了,如何保证不会丢失呢(宕机、磁盘崩溃)
- Comsumer的视角来看:如果消息已经完成持久化了,但是Comsumer取了,但是未消费成功且没有反馈,就是消息丢失
Producer分析:如何确保消息正确的发送到了Broker?
- 默认情况下,可以通过同步的方式阻塞式的发送,check SendStatus,状态是OK,表示消息一定成功的投递到了Broker,状态超时或者失败,则会触发默认的2次重试。此方法的发送结果,可能Broker存储成功了,也可能没成功
- 采取事务消息的投递方式,并不能保证消息100%投递成功到了Broker,但是如果消息发送Ack失败的话,此消息会存储在CommitLog当中,但是对ComsumerQueue是不可见的。可以在日志中查看到这条异常的消息,严格意义上来讲,也并没有完全丢失
- RocketMQ支持 日志的索引,如果一条消息发送之后超时,也可以通过查询日志的API,来check是否在Broker存储成功
Broker分析:如果确保接收到的消息不会丢失?
- 消息支持持久化到Commitlog里面,即使宕机后重启,未消费的消息也是可以加载出来的
- Broker自身支持同步刷盘、异步刷盘的策略,可以保证接收到的消息一定存储在本地的内存中
- Broker集群支持 1主N从的策略,支持同步复制和异步复制的方式,同步复制可以保证即使Master 磁盘崩溃,消息仍然不会丢失
Comsumer分析:如何确保拉取到的消息被成功消费?
- 消费者可以根据自身的策略批量Pull消息
- Comsumer自身维护一个持久化的offset(对应MessageQueue里面的min offset),标记已经成功消费或者已经成功发回到broker的消息下标
- 如果Comsumer消费失败,那么它会把这个消息发回给Broker,发回成功后,再更新自己的offset
- 如果Comsumer消费失败,发回给broker时,broker挂掉了,那么Comsumer会定时重试这个操作
- 如果Comsumer和broker一起挂了,消息也不会丢失,因为Comsumer里面的offset是定时持久化的,重启之后,继续拉取offset之前的消息到本地
六、RabbitMQ如何保证消费顺序:
Producer在发送消息时将多个消费者消费的队列,拆分为多个队列,也就是一个消费者对应一个队列,避免了多个消费者消费同一个队列,造成消费顺序错乱。但这样就会损耗资源,无非就多了很多队列。
Comsumer在消费消息时,要保证一个队列且一个线程去消费。
七、RabbitMQ如何保证消息不丢失:
1、消息持久化 2、ACK确认机制 3、设置集群镜像模式 4、消息补偿机制
第一种(消息持久化):
RabbitMQ 的消息默认存放在内存上面,如果不特别声明设置,消息不会持久化保存到硬盘上面的,如果节点重启或者意外crash掉,消息就会丢失。
所以就要对消息进行持久化处理。如何持久化,下面具体说明下:
要想做到消息持久化,必须满足以下三个条件,缺一不可:
1)Exchange 设置持久化
2)Queue 设置持久化
3)Message持久化发送:发送消息设置发送模式deliveryMode=2,代表持久化消息
第二种(ACK确认机制):
多个消费者同时收取消息,比如消息接收到一半的时候,一个消费者死掉了(逻辑复杂时间太长,超时了或者消费被停机或者网络断开链接),如何保证消息不丢?
这个使用就要使用Message acknowledgment 机制,就是消费端消费完成要通知服务端,服务端才把消息从内存删除。
这样就解决了,及时一个消费者出了问题,没有同步消息给服务端,还有其他的消费端去消费,保证了消息不丢的case。
第三种(设置集群镜像模式):
我先来介绍下RabbitMQ三种部署模式:
1)单节点模式:最简单的情况,非集群模式,节点挂了,消息就不能用了。业务可能瘫痪,只能等待。
2)普通模式:默认的集群模式,某个节点挂了,该节点上的消息不能用,有影响的业务瘫痪,只能等待节点恢复重启可用(必须持久化消息情况下)。
3)镜像模式:把需要的队列做成镜像队列,存在于多个节点,属于RabbitMQ的HA方案
为什么设置镜像模式集群,因为队列的内容仅仅存在某一个节点上面,不会存在所有节点上面,所有节点仅仅存放消息结构和元数据。下面自己画了一张图介绍普通集群丢失消息情况:
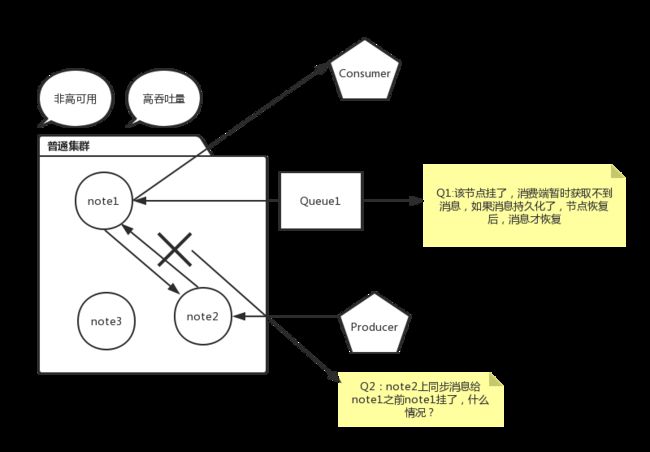
如果想解决上面途中问题,保证消息不丢失,需要采用HA 镜像模式队列。
1)同步至所有的
2)同步最多N个机器
3)只同步至符合指定名称的nodes
命令处理HA策略模版:rabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority]
1)为每个以“rock.wechat”开头的队列设置所有节点的镜像,并且设置为自动同步模式
rabbitmqctl set_policy ha-all “^rock.wechat” ‘{“ha-mode”:“all”,“ha-sync-mode”:“automatic”}’
rabbitmqctl set_policy -p rock ha-all “^rock.wechat” ‘{“ha-mode”:“all”,“ha-sync-mode”:“automatic”}’
2)为每个以“rock.wechat.”开头的队列设置两个节点的镜像,并且设置为自动同步模式
rabbitmqctl set_policy -p rock ha-exacly “^rock.wechat”
‘{“ha-mode”:“exactly”,“ha-params”:2,“ha-sync-mode”:“automatic”}’
3)为每个以“node.”开头的队列分配指定的节点做镜像
rabbitmqctl set_policy ha-nodes “^nodes.”
‘{“ha-mode”:“nodes”,“ha-params”:[“rabbit@nodeA”, “rabbit@nodeB”]}’
但是:HA 镜像队列有一个很大的缺点就是: 系统的吞吐量会有所下降。
第四种(消息补偿机制):
为什么还要消息补偿机制呢?难道消息还会丢失,没错,系统是在一个复杂的环境,不要想的太简单了,虽然以上的三种方案,基本可以保证消息的高可用不丢失的问题,
但是作为有追求的程序员来讲,要绝对保证我的系统的稳定性,有一种危机意识。
比如:持久化的消息,保存到硬盘过程中,当前队列节点挂了,存储节点硬盘又坏了,消息丢了,怎么办?
产线网络环境太复杂,所以不知数太多,消息补偿机制需要建立在消息要写入DB日志,发送日志,接受日志,两者的状态必须记录。
然后根据DB日志记录check 消息发送消费是否成功,不成功,进行消息补偿措施,重新发送消息处理。
八、RocketMQ与RabbitMQ之间的区别:
RabbitMQ 2007年发布,是一个在AMQP(高级消息队列协议)基础上完成的,可复用的企业消息系统,是当前最主流的消息中间件之一。
RabbitMQ优点:
由于erlang语言的特性,mq 性能较好,高并发;
吞吐量到万级,MQ功能比较完备 ;
健壮、稳定、易用、跨平台、支持多种语言、文档齐全;
开源提供的管理界面非常棒,用起来很好用;
社区活跃度高。
RabbitMQ缺点:
erlang开发,很难去看懂源码,基本职能依赖于开源社区的快速维护和修复bug,不利于做二次开发和维护。
RabbitMQ确实吞吐量会低一些,这是因为他做的实现机制比较重。
需要学习比较复杂的接口和协议,学习和维护成本较高。
RocketMQ
RocketMQ出自 阿里公司的开源产品,用 Java 语言实现,在设计时参考了 Kafka,并做出了自己的一些改进。
RocketMQ在阿里集团被广泛应用在订单,交易,充值,流计算,消息推送,日志流式处理,binglog分发等场景。
RocketMQ优点:
单机吞吐量:十万级
可用性:非常高,分布式架构
消息可靠性:经过参数优化配置,消息可以做到0丢失
功能支持:MQ功能较为完善,还是分布式的,扩展性好
支持10亿级别的消息堆积,不会因为堆积导致性能下降
源码是java,我们可以自己阅读源码,定制自己公司的MQ,可以掌控
RocketMQ缺点:
支持的客户端语言不多,目前是java及c++,其中c++不成熟;
社区活跃度一般;
没有在 mq 核心中去实现JMS等接口,有些系统要迁移需要修改大量代码 。
九、消息队列选择建议:
RocketMQ
天生为金融互联网领域而生,对于可靠性要求很高的场景,尤其是电商里面的订单扣款,以及业务削峰,在大量交易涌入时,后端可能无法及时处理的情况。
RoketMQ在稳定性上可能更值得信赖,这些业务场景在阿里双11已经经历了多次考验,如果你的业务有上述并发场景,建议可以选择RocketMQ。
RabbitMQ
RabbitMQ :结合erlang语言本身的并发优势,性能较好,社区活跃度也比较高,但是不利于做二次开发和维护。不过,RabbitMQ的社区十分活跃,可以解决开发过程中遇到的bug。