豆瓣电影Top250数据爬取、数据分析及数据可视化
文章目录
- 引言
- 数据爬取与解析
-
- 数据爬取
-
- urllib方法
- requests方法
- 数据解析
-
- BeaufifulSoup
- xpath
- re正则表达式
- 数据存储
-
- 本地excel保存
- sqlite数据库保存
-
- 结果展示
- 数据可视化
-
-
- Flask
- Echarts
- WordCloud
-
- 新手问题总结与解决方法
-
- ip被封
- 查看网页源码和"F12 Elements"后不一致
- 其他问题
引言
在爬虫学习中,一套完整的项目实战对于代码和计算机思维能力有很大的提升。本文基于B站视频《Python爬虫基础5天速成(2021全新合集)Python入门+数据可视化》关于 “豆瓣电影Top250” 项目做出的总结、拓展与分享。
在本文中,只展示数据爬取到数据保存的工作,数据可视化部分只做部分分析和结果展示。具体关于库的操作我选择了一些官方文档做链接,知识点比较全面请参考下列表。如果想要项目源代码,请评论或私信。
- URL处理系统模块:urllib
- URL处理第三方模块:requests
- 数据提取bs4模块:BeautifulSoup
- 数据提取正则表达式模块:re
- 数据库保存模块:sqlite3
- 本地文件保存模块:xlwt
数据爬取与解析
数据爬取
数据爬取工作是整个工程的第一步,这一阶段所要做的工作是将网页上带有我们需要的信息的网页源码抓取下来。建议在此步骤时,如果数据量不大全部抓取保存到本地;如果数据量很大,则先保存一组到多组数据到本地。在接下的数据解析时通过本地文件解析,这样做会避免后面多次访问网站而被封ip,当然针对被封ip有相应的解决办法,但是这些内容涉及到网络知识,建议后面再学。
urllib方法
import urllib.request
base_url = "https://movie.douban.com/top250?start="
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36"
}
#构建请求
req = urllib.request.Request(url=base_url,headers=header)
#得到响应
response = urllib.request.urlopen(req)
html = response.read().decode("utf-8")
with open("top250_first_page.html","w",encoding="utf-8") as f:
f.write(html)
requests方法
import requests
base_url = "https://movie.douban.com/top250?start="
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36"
}
response = requests.get(url=base_url,headers=header)
data = response.content.decode()
with open("top250_first_page.html","w",encoding="utf-8") as f:
f.write(data)
数据解析
数据解析作为第二步是整个工程的核心,这一步直接决定了 我们是否能够在海量的数据中只得到我们想要的数据。爬虫中三种重要的数据解析的方法分别是:BeautifulSoup、re正则表达式和xpath,三种方法没有优劣好坏,按照我前面给出的文档,自己用好一种即可满足需求,当然三种方法根据场景使用是最高效的,如果你是大佬的话。
我自己常用的是xpath方法。第一,xpath路径可以直接在网页上进行复制;第二,可以通过XPath Helper工具进行更好的测试,我在之前的博客有提到可以点击查看。下面我用三种不同的方法对保存到本地的一页上的数据进行了解析。
BeaufifulSoup
from bs4 import BeautifulSoup
import re
#将要解析的网站打开
html = open("top250_first_page.html","rb")
#构建BeautifulSoup对象
soup = BeautifulSoup(html,"html.parser")
#得到每一块的内容
blocks = soup.select(".grid_view .item")
#构建电影列表
movie_list = []
#电影链接和电影图片链接
for index,block in enumerate(blocks):
movie_dict = {
}
movie_dict["movie_href"] = block.select("a")[0].get("href") #电影详情页链接
movie_dict["pic_href"] = block.select("img")[0].get("src") #电影链接
title = block.select(".title") #电影名字
if len(title)==2:
movie_dict["c_title"] = block.select(".title")[0].text #电影中文名字
o_title = block.select(".title")[1].text # 电影中文名字
movie_dict["o_title"] = o_title.replace("/","")
else:
movie_dict["c_title"] = block.select(".title")[0].text #电影中文名字
movie_dict["o_title"] = " " #电影外文名字
movie_dict["rate"] = block.select(".star .rating_num")[0].text #电影评分
movie_dict["judge"] = block.select(".star span")[3].text[:-3] #评分人数
bd = block.select(".bd p")[0].text
movie_dict["bd"] = re.sub(" ","",bd)
movie_dict["inq"] = block.select(".quote .inq")[0].text.replace("。","")
movie_list.append(movie_dict)
#打印测试
print(movie_list)
xpath
from lxml import etree
import re
#将要解析的网站打开
html = open("top250_first_page.html","rb")
content = html.read().decode("utf-8")
#构建etree对象
data = etree.HTML(content)
#获取多个电影信息列表
divs = data.xpath('//div[@class="item"]')
for div in divs:
movie_dict = {
}
movie_dict["movie_href"] = div.xpath('div[@class="pic"]/a/@href')
#print(movie_href) #测试
movie_dict["pic_href"] = div.xpath('div[@class="pic"]//img/@src')
#print(pic_href) #测试
title = div.xpath('div[@class="info"]//a/span[@class="title"]/text()')
if len(title)==2:
movie_dict["c_title"] = title[0]
o_title = title[1].replace("/","")
movie_dict["o_title"] = "".join(o_title.split())
else:
movie_dict["c_title"] = title[0]
movie_dict["o_title"] = " "
#print(c_title,o_title) #测试
movie_dict["rate"] = div.xpath('div//div[2]/div/span[2]/text()')
#print(rate) #测试
judge = div.xpath('div//div[2]/div/span[4]/text()')
movie_dict["judge"] = (str(judge))[2:-5]
#print(judge) #测试
bd = str(div.xpath('div//div[@class="bd"]/p[1]/text()'))
movie_dict["bd"] = bd.replace(" ","").replace(r"\xa0","").replace(r"\r","").replace(r"\n","")
#print(bd) #测试
print(movie_dict)
re正则表达式
import re
from bs4 import BeautifulSoup
#影片详情链接规则
findLink = re.compile(r'') #创建正则表达式对象,表示规则(字符串的模式)
#影片图片规则
findSrclink = re.compile(r',re.S)
#影片片名规则
findTitle = re.compile(r'(.*)')
#影片的评分规则
findGrade = re.compile(r'')
#评价人数规则
findJud = re.compile(r'(.*)人评价')
#找到概况
findInq = re.compile(r'(.*)')
#影片相关内容
findBd = re.compile(r'(.*?)
',re.S)
#将要解析的网站打开
html = open("top250_first_page.html","rb")
content = html.read().decode("utf-8")
datalist = []
soup = BeautifulSoup(content, "html.parser")
for item in soup.find_all("div",class_ = "item"):
item = str(item)
#print(html) #测试电影信息的一小段有没有内解析拿到
data = [ ]
title = re.findall(findTitle,item)
if(len(title)==2):
Ctitle = title[0]
data.append(Ctitle)
Ftitle = title[1]
Ftitle = title[1].replace("/", "")
Ftitle = "".join(Ftitle.split())
data.append(Ftitle)
else:
Ctitle = title[0]
data.append(Ctitle)
Ftitle = " "
data.append(Ftitle)
link = re.findall(findLink,item)[0]
data.append(link)
srclink = re.findall(findSrclink,item)[0]
data.append(srclink)
grade = re.findall(findGrade,item)
data.append(grade)
judge = re.findall(findJud,item)
data.append(judge)
inq = re.findall(findInq,item)
data.append(inq)
bd = re.findall(findBd,item)[0]
bd = re.sub(' 数据存储
本地excel保存
import xlwt
workbook = xlwt.Workbook(encoding="utf-8", style_compression=0)
worksheet = workbook.add_sheet("豆瓣电影250")
col = ["中文名", "外文名", "电影链接", "图片链接", "评分", "评价人数", "概评", "概述"]
for i in range(0, 8):
worksheet.write(0, i, col[i])
for i in range(len(datalist)):
for j in range(0, 8):
worksheet.write(i + 1, j, datalist[i][j])
workbook.save("豆瓣top250_firstPage.xls")
sqlite数据库保存
import sqlite3
def init_db(dbpath):
sql = '''
create table movie250
(
id integer primary key autoincrement,
info_link text,
pic_link text,
cname varchar,
ename varchar,
score numeric ,
rated numeric ,
instroduction text,
info text
)
''' # 创建数据表
conn = sqlite3.connect(dbpath)
cursor = conn.cursor()
cursor.execute(sql)
conn.commit()
conn.close()
def saveData2DB(datalist, dbpath):
#init_db(dbpath)
conn = sqlite3.connect(dbpath)
cur = conn.cursor()
for data in datalist:
for index in range(len(data)):
if index == 4 or index == 5 or index==6:
#data[index] = '"' + data[index] + '"'
data[index] = str(data[index])
sql = '''
insert into movie250 (
info_link,pic_link,cname,ename,score,rated,instroduction,info)
values(%s)''' % ",".join(data)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
saveData2DB(datalist,"movie.db")
结果展示
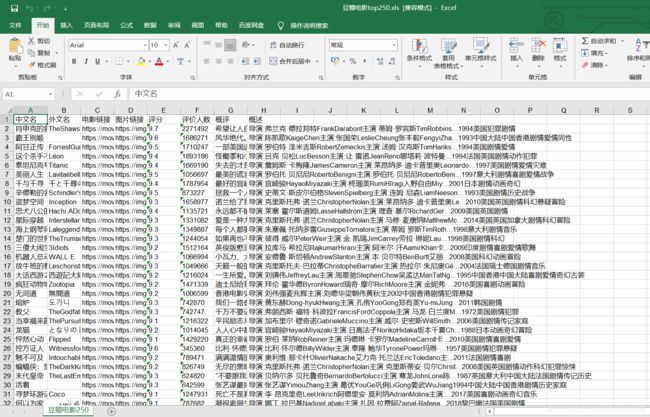
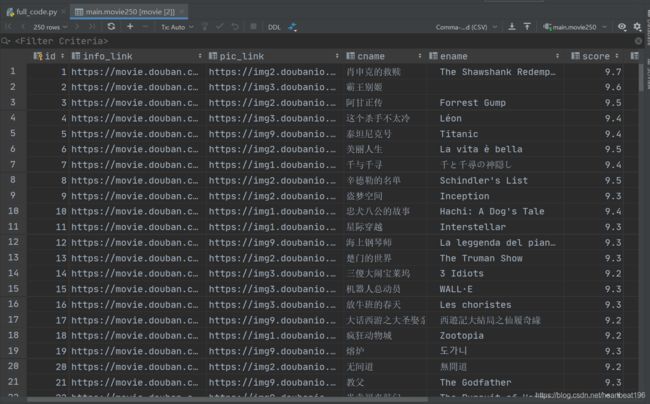
数据可视化
Flask
Flask 是一个微型的 Python 开发的 Web 框架,基于Werkzeug WSGI工具箱和Jinja2 模板引擎。 Flask使用BSD授权。 Flask也被称为“microframework”,因为它使用简单的核心,用extension增加其他功能。Flask没有默认使用的数据库、窗体验证工具。
简单来说在此项目中,Flask框架给我们提供了一个本地网页平台展示数据。我们根据不同的路由地址进行到不同的页面访问。如下图是首界面,通过不同的链接地址可以实现页面跳转,当然只是本地!

Echarts
Echarts是一个纯基于js的图表库,可以流畅的运行在 PC 和移动设备上。在本项目中可以将数据进行统计分类从而用不同的展示方法进行展现。在Echarts中可以支持的图表类型有很多,同时其有一个很好的点在于它能满足我们实时修改查看,最终形成自己想要的图,便将js代码复制粘贴到我们所需要的网页代码的地方。
由于在页面内有动态显示,所以不在进行展示。
WordCloud
词云展示方法是近些年来较为常用的数据可视化方法。其主要是通过分词技术将一篇文章或者一段话分成若干单词,然后统计这些词出现的频率,我们根据自定义化设置画布和这些词出现的颜色大小等等来得到某个词云。词云中重要的是画布的配置、自己所要定义的形式是什么样子,其他更多的是某些固定的方法。下图为我通过爬取毛不易的歌词内容获得毛不易的歌词词云图,如果需要此项目源码或者方法请私信。

新手问题总结与解决方法
ip被封
ip被封可能是新手在爬虫学习阶段遇到的最大的问题。首先如果是初学想要尽快实现一些成果时,建议在合理范围内减少爬取次数,如果我们能获得网页内容了首先将其存到本地文件夹下进行后续的测试和解析。俗话说:上有政策下有对策,面对ip被封:基础阶段我们可以添加请求头,尽可能的进行伪装像一个浏览器在访问;再进一步我们可以自己构建代理ip函数,仿照源码添加免费ip,构建handler处理器使用opener方法也可以;如果有能力的话,可以学习代理ip池的方法来解决该问题。
当然,爬虫我们是要在合法范围内进行抓取,如果某些数据是机密或者不能访问的,我们还一直访问可能就很快有自己的小手镯子了。我们只爬取我们可以访问到的,爬虫只是提高效率,不是翻过禁墙。
查看网页源码和"F12 Elements"后不一致
该问题可以总结为用一般方法有些需要的元素抓取不到。在本次项目中我们爬取的页面是静态网页所以可以直接抓取,但是对于动态网页就会无能为力。
查看网页源码:最原始的代码,指的是服务器直接发送到浏览器的代码。
F12检查元素:js渲染后的代码。而确实的部分就是js所渲染的。
如果我们想要抓取这部分代码可以采取以下两种方法:
- 在页面上进行抓包,获取表单的元素和js链接提交请求
- 通过selenium技术,模拟用户打开网页,进行自动化的抓取。
其他问题
以上两个问题是我在这个项目中所遇到的,当然在面对更复杂的爬虫工作时,会有更加繁琐的问题出现。还有一些其他问题,我将其总结为基础知识问题。在很多初学的时候,我们获得的数据往往以不同的格式进行存储,但是某些方法只能针对某些固定数据格式,这些需要我们提起注意;还有就是我们不可避免的马虎问题,关键词拼写错误,变量书写错误等等,这些最好的解决办法就是孰能生巧。
最后就是建议大家在完成一个项目时选择分块按照不同的模块去练习测试,最终完成项目。