pointconv pytorch modelnet40 点云分类结果可视化
文章目录
- 前言
- 环境
-
- 服务器环境
- 本地环境
- 准备工作
-
- 下载项目文件
- 下载数据集
- 训练
- 预测
-
- 下载训练权重
- 预测
-
- 部分代码解析
- 可视化输出
- 运行预测
- 查看运行结果
前言
上一篇博客介绍了在scannet数据集和tensorflow环境下, 运行pointconv项目进行点云分割
这一篇介绍在modelnet40_resampled数据集和pytorch环境下, 运行pointconv进行点云分类, 并将结果可视化输出并保存
本篇会现在服务器上预训练, 然后下载权重到本地, 进行预测, 并将预测结果可视化输出, 保存
环境
服务器环境
- anaconda3
- python虚拟环境3.6
- cuda10.1
- Tensorflow-gpu 1.11.0
- 3 x GTX TITAN X
本地环境
- anaconda3
- python虚拟环境3.6
- cuda10.1
- Tensor flow-gpu 1.14.0
- GTX 1060 6G
准备工作
下载项目文件
在服务器上运行下面的命令
git clone https://github.com/DylanWusee/pointconv_pytorch.git
整个项目的一级目录是这样的
pointconv_pytorch/
├── LICENSE
├── README.md
├── __pycache__
├── checkpoints/
├── data_utils/
├── eval_cls_conv.py
├── model/
├── provider.py
├── train_cls_conv.py
├── train_cls_conv2.py
└── utils/
下载数据集
在服务器上运行下面的命令
wget https://shapenet.cs.stanford.edu/media/modelnet40_normal_resampled.zip --no-check-certificate
后面的–no-check-certificate不可少, 不然会由于证书的原因报错
由于本地也需要这个数据集, 如果本地有安装wget的话, 直接执行上面的命令, 没有的话, 点击这个链接
数据集下载下来后, 解压到pointconv_pytorch/data/modelnet40_normal_resampled/这个目录.
训练
这个项目运行起来比较简单, 不像tensorflow版的还需要重新编译. 直接在终端输入以下命令即可
screen python train_cls_conv.py --model pointconv_modelnet40 --normal --batch_size 12
screen的作用在之前的博客里已经解释过了, 这里不再赘述.
同时针对点云的模型, 我建议batch_size尽量给小, 以免OOM爆显存
训练完之后, 会在pointconv_pytorch/experiment/下保存训练日志和ckpt, 如下:
experiment/
└── pointconv_modelnet40_ModelNet40-2021-01-20_13-55/
├── checkpoints/
│ └── pointconv_modelnet40-0.919773-0096.pth
├── logs/
└── logstrain_pointconv_modelnet40_cls.txt
预测
下载训练权重
在本地新建终端, 通过scp将服务器上的pointconv_pytorch项目下载下来, 命令格式为:
scp -P ${__PORT__} -r ${__USER__}@${__IP__}:${__ONLINE_PATH__} ${__LOCAL_PATH__}
- ${__PORT__}为连接服务器的端口, 如果没有修改过的话默认为
22, - ${__USER__}为服务器上的用户名
- ${__IP__}为连接服务器的IP地址, 注意有分公网,局域网和内网IP
- ${__ONLINE_PATH__}为服务器上的项目路径
- ${__LOCAL_PATH__}为本地下载到的路径
预测
这里我们假设batch_size=12
在IDE中打开eval_cls_conv.py 文件, 这个文件是用来预测的. 但是如果直接按照README.md里面写的去执行, 不会有可视化的输出和保存, 因此我们需要修改一点
部分代码解析
为了使得输出能够可视化, 我们需要对部分代码做一个分析理解
eval_cls_conv.py中, 最重要的就是main(args)这个函数, 这是实现预测的主体框架. 我就不把整个函数贴出来了, 只贴出几段关键的代码, (我已经做了很多修改, 所以各位代码和我不一样也是正常的)
classifier = classifier.eval()
mean_correct = []
for batch_id, data in tqdm(enumerate(testDataLoader, 0), total=len(testDataLoader), smoothing=0.9):
pointcloud, target = data
target = target[:, 0]
points = pointcloud.permute(0, 2, 1)
n_points = points.cpu().numpy()
points, target = points.cuda(), target.cuda()
代码到这里, 已经成功把modelnet数据集解析成points(样本)和target(标签)了, 两者都是tensor类型, 两者的具体shape可能不同, 但points.shape[0]==target.shape[0]==batch_size==12
有了样本, 标签和权重, 自然就可以得到对应的预期:
with torch.no_grad():
pred = classifier(points[:, :3, :], points[:, 3:, :])
pred_choice = pred.data.max(1)[1]
pred是某个样本在modelnet40中属于各个分类的概率, 由于modelnet40总共有40个类, 因此pred.shape=(40,), 这是一个长度为40的一维数组. 而我们需要的是概率最大的那个分类, 即pred_choice
原作者的思路到这就结束了, 下面就开始计算准确率了. 并没有做可视化输出.
可视化输出
其实我们需要做的, 只是把每个batch中的12个样本, 用不同的颜色绘制出来即可.
思路是这样的:
- 总共有40个分类, 从
matplotlib中选取40种颜色备用, 每个颜色对应一个分类 - 对每一个
batch(包含12张样本), 绘制一个整体batch的三维点图 - 对
batch中的每个样本, 先用对应分类的颜色绘制三维点图, 再根据预测的分类, 再绘制一张
那么我们首先需要一个绘制三维点图, 还有颜色控制的函数, 如下:
def draw(x, y, z, name, file_dir, color=None):
"""
绘制单个样本的三维点图
"""
if color is None:
for i in range(len(x)):
ax = plt.subplot(projection='3d') # 创建一个三维的绘图工程
save_name = name+'-{}.png'.format(i)
save_name = file_dir.joinpath(save_name)
ax.scatter(x[i], y[i], z[i], c='r')
ax.set_zlabel('Z') # 坐标轴
ax.set_ylabel('Y')
ax.set_xlabel('X')
plt.draw()
plt.savefig(save_name)
# plt.show()
else:
colors = ['red', 'blue', 'green', 'yellow', 'orange', 'tan', 'orangered', 'lightgreen', 'coral', 'aqua', 'gold', 'plum', 'khaki', 'cyan', 'crimson', 'lawngreen', 'thistle', 'skyblue', 'lightblue', 'moccasin', 'pink', 'lightpink', 'fuchsia', 'chocolate', 'tomato', 'orchid', 'grey', 'plum', 'peru', 'purple', 'teal', 'sienna', 'turquoise', 'violet', 'wheat', 'yellowgreen', 'deeppink', 'azure', 'ivory', 'brown']
for i in range(len(x)):
ax = plt.subplot(projection='3d') # 创建一个三维的绘图工程
save_name = name + '-{}-{}.png'.format(i, color[i])
save_name = file_dir.joinpath(save_name)
ax.scatter(x[i], y[i], z[i], c=colors[color[i]])
ax.set_zlabel('Z') # 坐标轴
ax.set_ylabel('Y')
ax.set_xlabel('X')
plt.draw()
plt.savefig(save_name)
# plt.show()
def drawAllInOne(x, y, z, name, file_dir, color=None):
"""
绘制整个batch的三维点图
"""
if color is None:
ax = plt.subplot(projection='3d') # 创建一个三维的绘图工程
save_name = name + '.png'
save_name = file_dir.joinpath(save_name)
for i in range(len(x)):
ax.scatter(x[i], y[i], z[i], c='r')
ax.set_zlabel('Z') # 坐标轴
ax.set_ylabel('Y')
ax.set_xlabel('X')
plt.draw()
plt.savefig(save_name)
# plt.show()
else:
ax = plt.subplot(projection='3d') # 创建一个三维的绘图工程
save_name = name + '.png'
save_name = file_dir.joinpath(save_name)
colors = ['red', 'blue', 'green', 'yellow', 'orange', 'tan', 'orangered', 'lightgreen', 'coral', 'aqua','gold', 'plum', 'khaki', 'cyan', 'crimson', 'lawngreen', 'thistle', 'skyblue', 'lightblue', 'moccasin','pink', 'lightpink', 'fuchsia', 'chocolate', 'tomato', 'orchid', 'grey', 'plum', 'peru', 'purple','teal', 'sienna', 'turquoise', 'violet', 'wheat', 'yellowgreen', 'deeppink', 'azure', 'ivory', 'brown']
for i in range(len(x)):
ax.scatter(x[i], y[i], z[i], c=colors[color[i]])
ax.set_zlabel('Z') # 坐标轴
ax.set_ylabel('Y')
ax.set_xlabel('X')
plt.draw()
plt.savefig(save_name)
# plt.show()
有4处plt.show(), 如果不注释掉, 那每张图都会通过matplotlib的GUI显示出来, 然后保存. 如果注释掉的话, 那就只是保存, 不会显示出来. 我建议设置断点看个前几张就行了, 然后把4处都注释掉重新跑一遍. 不然每次都要手动去关闭GUI程序才能继续往下运行, 很烦人.
最后, 我们将main(args)里面的for循环改成这样:
for batch_id, data in tqdm(enumerate(testDataLoader, 0), total=len(testDataLoader), smoothing=0.9):
pointcloud, target = data
target = target[:, 0]
points = pointcloud.permute(0, 2, 1)
n_points = points.cpu().numpy() # 需要转换成numpy类型才能给matplotlib
points, target = points.cuda(), target.cuda()
with torch.no_grad():
pred = classifier(points[:, :3, :], points[:, 3:, :])
n_pred = pred.cpu().numpy() # 需要转换成numpy类型才能给matplotlib
pred_choice = pred.data.max(1)[1]
print('pred_choice: ', pred_choice)
print('target: ', target)
"""
以下几行是为了可视化加进去的
"""
save_name_prefix = 'input-{}'.format(batch_id)
draw(n_points[:, 0, :], n_points[:, 1, :], n_points[:, 2, :], save_name_prefix, file_dir, color=target)
drawAllInOne(n_points[:, 0, :], n_points[:, 1, :], n_points[:, 2, :], save_name_prefix, file_dir, color=target)
save_name_prefix = 'pred-{}'.format(batch_id)
draw(n_points[:, 0, :], n_points[:, 1, :], n_points[:, 2, :], save_name_prefix, file_dir, color=pred_choice)
drawAllInOne(n_points[:, 0, :], n_points[:, 1, :], n_points[:, 2, :], save_name_prefix, file_dir, color=pred_choice)
correct = pred_choice.eq(target.long().data).cpu().sum()
mean_correct.append(correct.item() / float(points.size()[0]))
print()
print()
运行预测
在本地终端执行:
python eval_cls_conv.py --checkpoint ${\__CKPT__} --normal --batch_size 12
其中 ${__CKPT__}为ckpt文件路径
会在pointconv_pytorch/eval_experiment/目录下保存运行日志和可视化的输出
eval_experiment/
└── pointconv_ModelNet40-2021-01-30_13-08/
├── checkpoints/
└── logs/
└── (非常多的png图像)
查看运行结果
进入文件夹, 可以看到保存下来的可视化结果
放大一点看
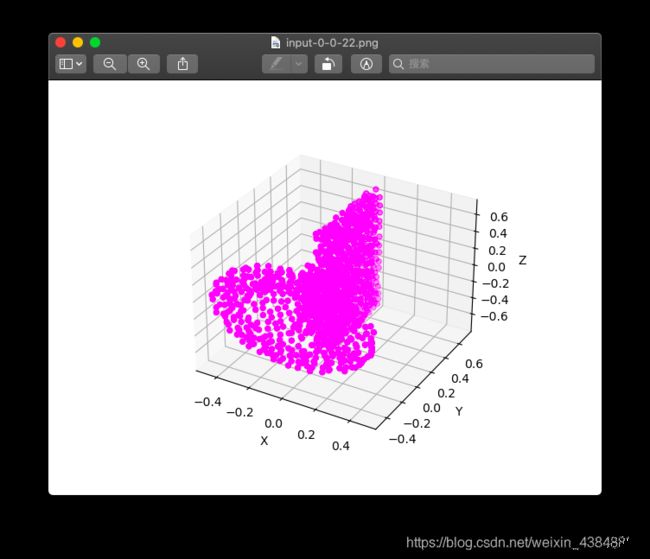
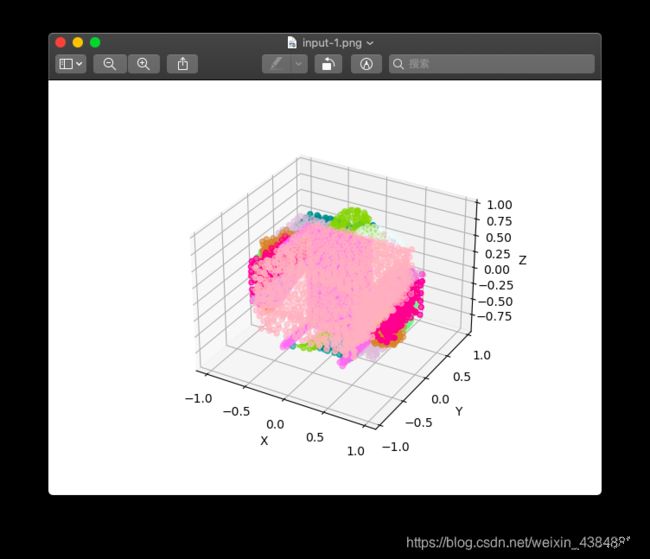
这里解释一下命名规则, 我是按照{1}-{2}-{3}-{4},png的格式命名的, 其中:
- 1处是
input,或者是pred,表示该图像是样本, 还是预测 - 2处表示
batch_id,也就是第几个batch - 如果命名到2处就结束了, 表示一整个
batch的图像, 比如上面的input-1.png. - 3处表示一个
batch里面的第几个样本, 比如batch_size=12的话, 3这里的取值是0到11 - 4处表示样本实际分类或者被预测的分类