【Python+Flask+Echarts 】可视化样题 --- 绘制各年份被淘汰的公司总数对比图形
Python+Flask+Echarts可视化
数据可视化的实现可以通过许多的方法,比如熟知的python就可以利用内置matplotlib库进行图形绘制,今天就来介绍一种Python+Flask+Echarts的联合方式进行数据可视化,下面是部分数据及截图,将会按照具体需求进行案例说明。
Flask工程基本结构
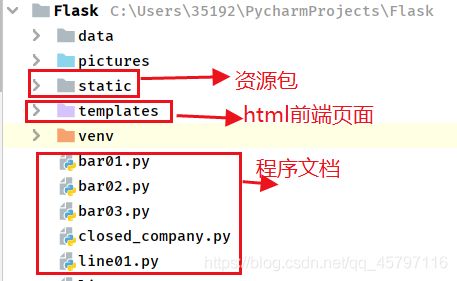
资源包主要指的就是要利用到的外部资源
![]()
基本步骤:
- 利用python的pandas读取数据集
- 按照题目要求提取有效数据,整合为新的数据集
- 将处理好的数据集转为List
- 创建Flask应用对象
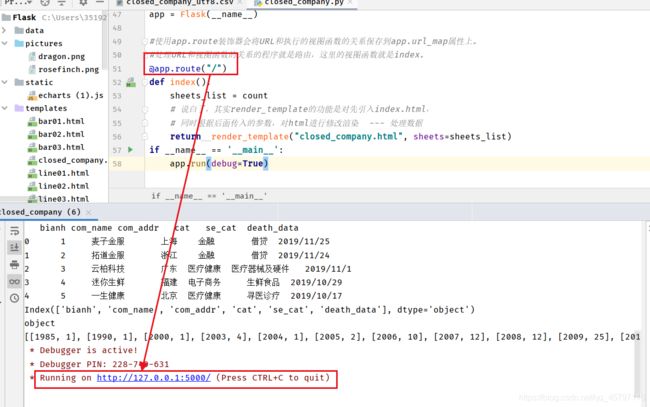
- 使用app.route装饰器会将URL和执行的视图函数的关系保存到app.url_map属性上。
处理URL和视图函数的关系的程序就是路由,这里的视图函数就是index。 - 编写前端页面获取数据绘图
- 运行应用程序


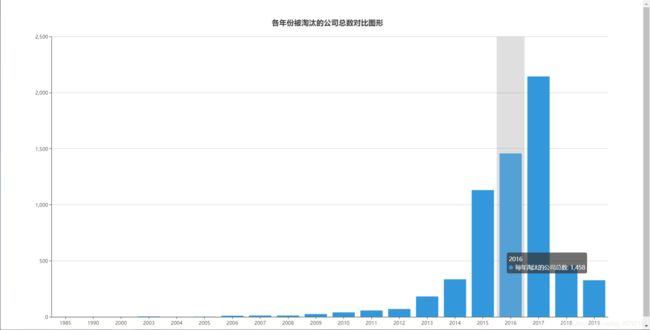
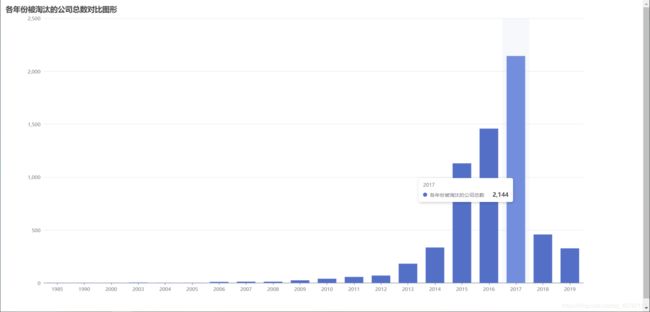
例1:根据数据集绘制各年份被淘汰的公司总数对比图形,用柱状图表示 ,并给出分析结论
# 1.读取信息
df = pd.read_csv("data/closed_company_utf8.csv",encoding="utf-8")
print(df.head()) # 查看数据前5行
print(df.columns)
# 2.数据清洗
# 去重
#print(df.duplicated().sum()) # 0
# 3.时间数据类型转换
print(df['death_data'].dtype) # object

第一步首先简单的读取数据文件,有pandas读获取的是DartaFrame类型的数据,会有index、columns。对于刚读取的数据集可以进行简单的清洗处理,比如去重、补null值、查找异常值等等。还有就是要查看数据集中列的数据类型,提前转换好对于后续的处理会做好铺垫,比如数值类型、时间类型、字符串类型等等。在这里由题干得知我们需要用到年份(日期列),所以首先查看原数集对应列的数据类型,发现是object,接下来就要进行转换。
# 3.时间数据类型转换
print(df['death_data'].dtype) # object
# 转换时间数据
df['death_data'] = pd.to_datetime(df['death_data'])
print(df['death_data'].dtype) # datetime64[ns]
# 提取日期信息
df['year'] = df['death_data'].apply(lambda datetime:datetime.year)
df['month'] = df['death_data'].apply(lambda datetime:datetime.month)
print(df)
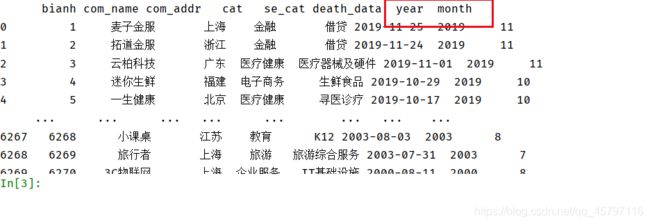
进行了日期类型的转换后,需要考虑到各年份的统计数,所以还要提取单独的年份、月份信息,可以通过计算每月的总和统计出一年的个数。
# 4.提取倒闭公司的年份并统计
count_year = df[['year','month']]
count = count_year.groupby(by="year").count().reset_index()
count.columns = ['年份','淘汰数目']
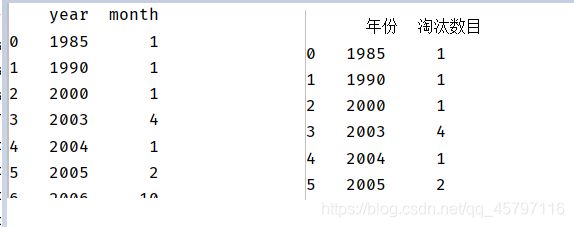
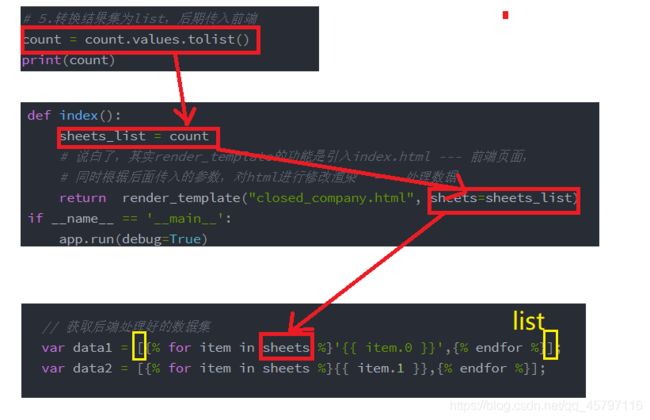
# 5.转换结果集为list,后期传入前端
count = count.values.tolist()
print(count)
![]()
这里将统计出来的DataFrame形式的数据集转化为list,便于前端的获取。
#6.创建flask应用对象
app = Flask(__name__)
#使用app.route装饰器会将URL和执行的视图函数的关系保存到app.url_map属性上。
#处理URL和视图函数的关系的程序就是路由,这里的视图函数就是index。
@app.route("/") # 默认5000
def index():
sheets_list = count
# 说白了,其实render_template的功能是引入index.html --- 前端页面,
# 同时根据后面传入的参数,对html进行修改渲染 --- 处理数据
return render_template("closed_company.html", sheets=sheets_list)
if __name__ == '__main__':
app.run(debug=True)
这部分便是创建Flask应用对象,通过简单的falsk框架,利用render_template将后端和前端连接,在前端利用echarts绘制图像。
完整代码:
# -*- coding: utf-8
# @Time : 2020/11/25 15:24
# @Author : ZYX
# @File : closed_company.py
# @software: PyCharm
import json
import pandas as pd
from flask import Flask,render_template
from flask_sqlalchemy import SQLAlchemy
# 1.读取信息
df = pd.read_csv("data/closed_company_utf8.csv",encoding="utf-8")
#print(df.head())
#print(df.columns)
# 2.数据清洗
# 去重
#print(df.duplicated().sum()) # 0
# 3.时间数据类型转换
print(df['death_data'].dtype) # object
# 转换时间数据
df['death_data'] = pd.to_datetime(df['death_data'])
# 提取日期信息
df['year'] = df['death_data'].apply(lambda datetime:datetime.year)
df['month'] = df['death_data'].apply(lambda datetime:datetime.month)
# 4.提取倒闭公司的年份数量
count_year = df[['year','month']]
count = count_year.groupby(by="year").count().reset_index()
count.columns = ['年份','淘汰数目']
# 5.转换结果集为list,后期传入前端
count = count.values.tolist()
print(count)
# 转换数据类型 --- 可以尝试转为json到前端去访问
# def to_json(df,orient='split'):
# df_json = df.to_json(orient = orient, force_ascii = False)
# return json.loads(df_json)
# 6.创建flask应用对象
app = Flask(__name__)
# 使用app.route装饰器会将URL和执行的视图函数的关系保存到app.url_map属性上。
# 处理URL和视图函数的关系的程序就是路由,这里的视图函数就是index。
@app.route("/")
def index():
sheets_list = count
# 说白了,其实render_template的功能是对先引入index.html,
# 同时根据后面传入的参数,对html进行修改渲染 --- 处理数据
return render_template("closed_company.html", sheets=sheets_list)
if __name__ == '__main__':
app.run(debug=True)
<!DOCTYPE html>
<html lang="en" style="height: 100%">
<head style="height: 100%">
<meta charset="UTF-8">
<title>Title</title>
</head>
<body style="height: 100%">
<div style="height: 100%" id="container"></div>
<script type="text/javascript" src="../static/echarts%20(1).js"></script>
<script type="text/javascript">
var dom = document.getElementById("container");
var myecharts = echarts.init(dom);
// 获取后端处理好的数据集
var data1 = [{
% for item in sheets %}'{
{ item.0 }}',{
% endfor %}];
var data2 = [{
% for item in sheets %}{
{
item.1 }},{
% endfor %}];
var option = null;
option = {
color:['#3398DB'], // 颜色
title:{
top:'4%',
right:'40%',
text:"各年份被淘汰的公司总数对比图形"
},
tooltip:{
// 提示框组件
show:true,
trigger:'axis', // 触发类型
axisPointer:{
// 坐标轴指示器配置项
type:'shadow'
}
},
grid:{
left:'5%',
right:'5%',
top:'10%',
bottom:'3%',
containLabel:true // grid 区域是否包含坐标轴的刻度标签
},
xAxis:[ // x轴
{
type: 'category', // 类型 --- 类别型
data:data1, // 数据
axisTick:{
// x轴刻度
alignWithLabel:true // 类目轴中在 boundaryGap 为 true 的时候有效,可以保证刻度线和标签对齐。
}
}
],
yAxis:[ // y轴
{
type:'value'
}
],
series:[ // 系列列表。每个系列通过 type 决定自己的图表类型
{
name:'每年淘汰的公司总数', // 系列名称,用于tooltip的显示,legend 的图例筛选,在 setOption 更新数据和配置项时用于指定对应的系列。
type:'bar', // 类型 --- 柱状图
data:data2,
borderWidth:'60%'
}
]
};
// 4.将配置的参数传递给echarts对象
if (option && typeof option == 'object'){
myecharts.setOption(option);
}
</script>
</body>
</html>
纠正(数据读取细节差别):
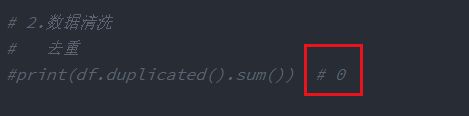
一做:
二做:

在之前做这道题目的时候又想到先去处理一下数据,但是打印了重复的条数为0;第二次去再做的时候,发现再次去重时,出现了微妙的变化,竟然有重复记录。

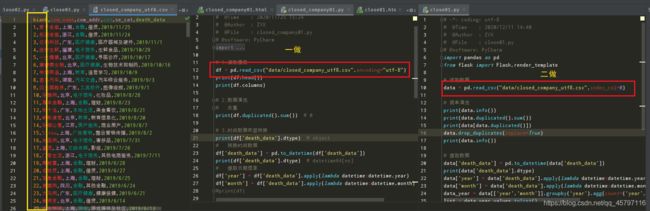
数据集本身没有错,读取路径也没有错,有点小绝望。。。
But,经过仔细比对,终于发现了不同之处,如上图所示,在读取数据的时候,第二次加了个参数index_col,没错就是它!
让我们来冷静分析一波:
加上index_col就将原本数据的第一列作为了行索引,数据比较去重时是将记录从原来的com_nam字段开始往后,逐行对比;如果没有设置该参数,那么情况就不一样了,在去重时按照了bianh字段开始往后,逐行对比,而bianh是累加的,怎么都不会有重复出现,所以两次的结果出现了差别。
所以,上述的案例过程没有问题,只是在读取的时候出了点小差错,后面的操作都可以照常进行,将以下部分重写即可,最终的统计结果会有细微的差别,这里我就将最后的结果图附在文章结尾。
# 读取数据
data = pd.read_csv("data/closed_company_utf8.csv",index_col=0)
# 简单清洗
print(data.info())
print(data.duplicated().sum())
print(data[data.duplicated()])
data.drop_duplicates(inplace=True)
print(data.info())
最终图:

下一篇:【Python+Flask+Echarts 】可视化样题 — 绘制 北京、上海、广东三个地区 不同行业被淘汰的公司总数对比图形