数据挖掘-数据离散化 python实现
"""
Author: Thinkgamer
Desc:
代码4-2 基于信息熵的数据离散化
"""
import numpy as np
import math
class DiscreteByEntropy:
def __init__(self, group, threshold):
self.maxGroup = group
self.minInfoThreshold = threshold
self.result = dict()
def loadData(self):
data = np.array(
[
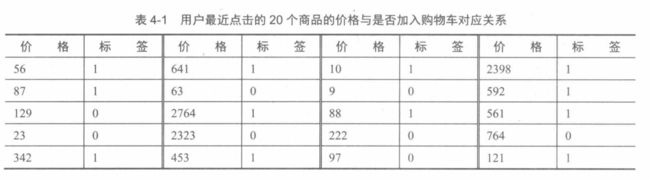
[56, 1], [87, 1], [129, 0], [23, 0], [342, 1],
[641, 1], [63, 0], [2764, 1], [2323, 0], [453, 1],
[10, 1], [9, 0], [88, 1], [222, 0], [97, 0],
[2398, 1], [592, 1], [561, 1], [764, 0], [121, 1],
]
)
return data
def calEntropy(self, data):
numData = len(data)
labelCounts = {
}
for feature in data:
oneLabel = feature[-1]
labelCounts.setdefault(oneLabel, 0)
labelCounts[oneLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key]) / numData
shannonEnt -= prob * math.log(prob, 2)
return shannonEnt
def split(self, data):
minEntropy = np.inf
index = -1
sortData = data[np.argsort(data[:, 0])]
lastE1, lastE2 = -1, -1
S1 = dict()
S2 = dict()
for i in range(len(sortData)):
splitData1, splitData2 = sortData[: i + 1], sortData[i + 1 :]
entropy1, entropy2 = (
self.calEntropy(splitData1),
self.calEntropy(splitData2),
)
entropy = entropy1 * len(splitData1) / len(sortData) + \
entropy2 * len( splitData2) / len(sortData)
if entropy < minEntropy:
minEntropy = entropy
index = i
lastE1 = entropy1
lastE2 = entropy2
S1["entropy"] = lastE1
S1["data"] = sortData[: index + 1]
S2["entropy"] = lastE2
S2["data"] = sortData[index + 1 :]
return S1, S2, entropy
def train(self, data):
needSplitKey = [0]
self.result.setdefault(0, {
})
self.result[0]["entropy"] = np.inf
self.result[0]["data"] = data
group = 1
for key in needSplitKey:
S1, S2, entropy = self.split(self.result[key]["data"])
if entropy > self.minInfoThreshold and group < self.maxGroup:
self.result[key] = S1
newKey = max(self.result.keys()) + 1
self.result[newKey] = S2
needSplitKey.extend([key])
needSplitKey.extend([newKey])
group += 1
else:
break
if __name__ == "__main__":
dbe = DiscreteByEntropy(group=6, threshold=0.5)
data = dbe.loadData()
dbe.train(data)
print("result is {}".format(dbe.result))
result is {
0: {
'entropy': 0.0, 'data': array([[9, 0]])}, 1: {
'entropy': 0.0, 'data': array([[342, 1],
[453, 1],
[561, 1],
[592, 1],
[641, 1]])}, 2: {
'entropy': 0.0, 'data': array([[129, 0],
[222, 0]])}, 3: {
'entropy': 1.0, 'data': array([[ 764, 0],
[2323, 0],
[2398, 1],
[2764, 1]])}, 4: {
'entropy': 0.9544340029249649, 'data': array([[ 10, 1],
[ 23, 0],
[ 56, 1],
[ 63, 0],
[ 87, 1],
[ 88, 1],
[ 97, 0],
[121, 1]])}}
Process finished with exit code 0