Redis基础入门及实战案例
Redis
1.NoSQL简介
NoSQL,泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在处理web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,出现了很多难以克服的问题,如商品网站中商品数据频繁查询、对热搜商品的排行统计、订单超时问题、微信朋友圈音频、视频的存储等,非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,特别是大数据应用难题。
RDBMS:关系型数据库,sql语句
NoSQL:Not only Sql 不仅仅是sql 非关系型数据库
2.NoSQL四大分类
2.1 键值(key-value)存储数据库
全称Key-Value,这应该是我们都熟悉就像Map一样。代表数据库就是redis,redis的value还分了很多结构,例如:list、set、sorted set、hash、string等。
它是存储在内存中的,所以速度快常用来作为缓存服务器。 而且因为它的结构导致有些操作比关系型数据库简单。
举个例子例如List的[LPUSHX key value]操作,将一个值插入到已存在的列表头部,列表是有序的,如果在关系型数据库中得怎么办,插入一条数据,并且将控制位置的那个字段例如叫index,设为1。那是不是还得修改本来的那些数据,把后面所有行的index值都加一,这样才能控制有序,之后删除哪条数据,还得维护修改index。操作是比较麻烦的。
但是它ACID事务只支持I和C也就是隔离性和一致性,不支持原子性和持久性。所以在一些对事务要求的情况下就不适合了。
2.2 列存储数据库
也就是按列来存储数据,关系型是按行存储。
按行存储的好处是业务可以简单的获取一行也就是多个列的数据,因为按行存储数据都是连续的,所以磁盘一次操作就读取所有列的数据。
但是按列的话,因为列的存储是不连续的,所以磁盘读取效率比行低
按行存储写如果操作也是一行一起的,保证的所有列的数据要么都成功写入,要么的失败。
如果是按列的话就有可能有些列成功,有些列失败。
但是在大数据统计的时候,一般就统计某一列或者某几列的数据。如果这时候是按行存储的话,那么每次从磁盘读取到内存时都会读取整行数据导致IO过大和资源的浪费。
所以节省I/O就采用按列存储,这样每次只需要拿想要的列进行统计。
代表的数据库是HBase,多用于离线的大数据分析和统计。为啥离线?上面说了写的操作可能会有问题,并且整行读的效率低,所以一般都是线上数据拷过来弄成列数据库,专门用户数据分析。
2.3 文档型数据库
这个类型它的结构没有约束,可以存储任意结构,因为是文档嘛。啥意思呢,就是例如关系型数据库中规定这个表字段就两个,一个id,一个name。如果你想存个sex字段你就得修改表结构。那文档型不用,因为文档型存储的数据格式一般都是Json,Json里面的字段我任意填,无拘无束
而且这种类型的数据库容易存复杂的结构,因为Json是一种强大的描述语言,可以清楚的描述复杂的数据结构。如果复杂的数据结构放到关系型数据中那可能就得分很多表。例如我用户基本信息一个表、用户爱好的电影一个表,用户爱好的音乐一个表、用户爱好的游戏一个表,巴拉巴拉的,这些Json就能一次性搞定不需要分这么多表。
代表的数据库有MongoDB。3.2之前的版本不支持join操作,之后出了个lookup来实现join操作。4.0版本之前是不支持事务的,之后虽说支持事务,但是业界还是很少用它来保证事务的。
2.4 图形数据库
图数据库允许我们将数据以图的方式储存。实体会被作为顶点,而实体之间的关系则会被作为边。比如我们有三个实体,Steve Jobs、Apple和Next,则会有两个“Founded by”的边将Apple和Next连接到Steve Jobs。
代表的数据库有Neo4J、Infinite Graph、OrientDB。它适合在在一些关系性强的数据中,以及推荐引擎。如果我们将数据以图的形式表现,那么将会非常有益于推荐的制定。它不适合数据模型。图数据库的适用范围很小,因为很少有操作涉及到整个图。
3.什么是Redis
Redis是一个开源的、遵循BSD的内存数据存储,常用作数据库、缓存、消息中间件
Redis数据存在内存中,所以读写快,机制:持久化机制 内存数据定期写入磁盘中
Redis是一个内存型数据库
4.Redis特点
- 高性能的key-value内存型数据库
- 支持丰富的数据类型
- 支持持久化、内存数据持久化到硬盘中
- Redis是单进程、多线程的(实现分布式锁)
- Synchronized在单个jvm上可以解决线程安全,但是在多个jvm上,无法跨机器解决线程安全
5.Redis下载和安装
# 联网情况下,执行如下命令进行下载
wget http://download.redis.io/releases/redis-6.0.10.tar.gz
# 一般都在usr下创建一个目录,方便管理
mkdir /usr/local/src/redis
# 切换到下载的目录,进行解压缩
tar -zxvf redis-4.0.2.tar.gz
# 将解压缩的redis移到到/usr/local/src/redis
mv redis-6.0.10 /usr/local/src/redis
# 进入文件夹内,进行编译并安装
make
make install
# 启动redis
redis-server
# 连接redis
redis-cli
6.Redis的基本操作
7.Redis持久化机制
7.1 RDB机制
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘。也是默认的持久化方式,这种方式是就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb。
可以通过配置设置自动做快照持久化的方式。我们可以配置redis在n秒内如果超过m个key被修改就自动做快照,下面是默认的快照保存配置
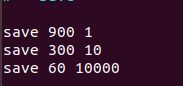
900秒内超过1个key被修改,则发起快照保存
300秒内超过10个key被修改,则发起快照保存
(1)RDB文件保存过程
- redis调用fork,现在有了子进程和父进程。
- 父进程继续处理client请求,子进程负责将内存内容写入到临时文件。由于os的写时复制机制(copy on write)父子进程会共享相同的物理页面,当父进程处理写请求时os会为父进程要修改的页面创建副本,而不是写共享的页面。所以子进程的地址空间内的数据是fork时刻整个数据库的一个快照。
- 当子进程将快照写入临时文件完毕后,用临时文件替换原来的快照文件,然后子进程退出。
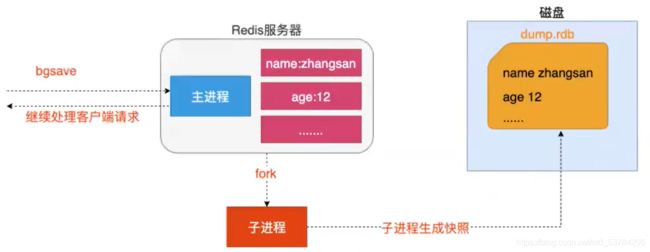
client 也可以使用save或者bgsave命令通知redis做一次快照持久化。save操作是在主线程中保存快照的,由于redis是用一个主线程来处理所有 client的请求,这种方式会阻塞所有client请求。所以不推荐使用。
另一点需要注意的是,每次快照持久化都是将内存数据完整写入到磁盘一次,并不 是增量的只同步脏数据。如果数据量大的话,而且写操作比较多,必然会引起大量的磁盘io操作,可能会严重影响性能。
(2)优势
- 一旦采用该方式,那么你的整个Redis数据库将只包含一个文件,这样非常方便进行备份。比如你可能打算没1天归档一些数据。
- 方便备份,我们可以很容易的将一个一个RDB文件移动到其他的存储介质上
- RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
- RDB 可以最大化 Redis 的性能:父进程在保存 RDB 文件时唯一要做的就是 fork 出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘 I/O 操作。
(3)劣势
- 如果你需要尽量避免在服务器故障时丢失数据,那么 RDB 不适合你。 虽然 Redis 允许你设置不同的保存点(save point)来控制保存 RDB 文件的频率, 但是, 因为RDB 文件需要保存整个数据集的状态, 所以它并不是一个轻松的操作。 因此你可能会至少 5 分钟才保存一次 RDB 文件。 在这种情况下, 一旦发生故障停机, 你就可能会丢失好几分钟的数据。
- 每次保存 RDB 的时候,Redis 都要 fork() 出一个子进程,并由子进程来进行实际的持久化工作。 在数据集比较庞大时, fork() 可能会非常耗时,造成服务器在某某毫秒内停止处理客户端; 如果数据集非常巨大,并且 CPU 时间非常紧张的话,那么这种停止时间甚至可能会长达整整一秒。 虽然 AOF 重写也需要进行 fork() ,但无论 AOF 重写的执行间隔有多长,数据的耐久性都不会有任何损失。
7.2 AOF机制
redis会将每一个收到的写命令都通过write函数追加到文件中(默认是 appendonly.aof)。
当redis重启时会通过重新执行文件中保存的写命令来在内存中重建整个数据库的内容。当然由于os会在内核中缓存 write做的修改,所以可能不是立即写到磁盘上。这样aof方式的持久化也还是有可能会丢失部分修改。不过我们可以通过配置文件告诉redis我们想要 通过fsync函数强制os写入到磁盘的时机。有三种方式如下(默认是:每秒fsync一次)
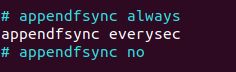
aof 的方式也同时带来了另一个问题。持久化文件会变的越来越大。例如我们调用incr test命令100次,文件中必须保存全部的100条命令,其实有99条都是多余的。因为要恢复数据库的状态其实文件中保存一条set test 100就够了。
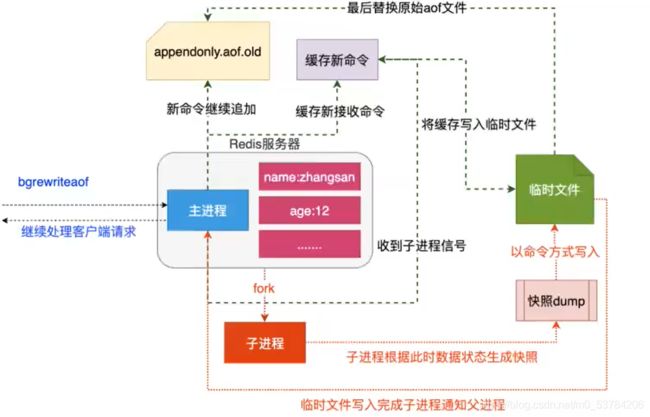
为了压缩aof的持久化文件。redis提供了bgrewriteaof命令。收到此命令redis将使用与快照类似的方式将内存中的数据 以命令的方式保存到临时文件中,最后替换原来的文件。
(1)AOF机制保存过程
- redis调用fork ,现在有父子两个进程
- 子进程根据内存中的数据库快照,往临时文件中写入重建数据库状态的命令
- 父进程继续处理client请求,除了把写命令写入到原来的aof文件中。同时把收到的写命令缓存起来。这样就能保证如果子进程重写失败的话并不会出问题。
- 当子进程把快照内容写入已命令方式写到临时文件中后,子进程发信号通知父进程。然后父进程把缓存的写命令也写入到临时文件。
- 现在父进程可以使用临时文件替换老的aof文件,并重命名,后面收到的写命令也开始往新的aof文件中追加。
需要注意到是重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似。
(2)优势
- 使用 AOF 持久化会让 Redis 变得非常耐久(much more durable):你可以设置不同的 fsync 策略,比如无 fsync ,每秒钟一次 fsync ,或者每次执行写入命令时 fsync 。 AOF 的默认策略为每秒钟 fsync 一次,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据( fsync 会在后台线程执行,所以主线程可以继续努力地处理命令请求)。
- AOF 文件是一个只进行追加操作的日志文件(append only log), 因此对 AOF 文件的写入不需要进行 seek , 即使日志因为某些原因而包含了未写入完整的命令(比如写入时磁盘已满,写入中途停机,等等), redis-check-aof 工具也可以轻易地修复这种问题。
Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。 - AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。 导出(export) AOF 文件也非常简单: 举个例子, 如果你不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态。
(3)劣势
- 对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
- 根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。 在一般情况下, 每秒 fsync 的性能依然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。 不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)。
- AOF 在过去曾经发生过这样的 bug : 因为个别命令的原因,导致 AOF 文件在重新载入时,无法将数据集恢复成保存时的原样。 (举个例子,阻塞命令 BRPOPLPUSH 就曾经引起过这样的 bug 。) 测试套件里为这种情况添加了测试: 它们会自动生成随机的、复杂的数据集, 并通过重新载入这些数据来确保一切正常。 虽然这种 bug 在 AOF 文件中并不常见, 但是对比来说, RDB 几乎是不可能出现这种 bug 的。
8.SpringBoot整合Redis
配置Redis的redis.conf
## 确保客户端可以访问到redis
bind 0.0.0.0
protected-mode no
daemonize yes
SpringBoot中关于redis的配置
# redis配置
Spring:
redis:
host: Redis所在的ip地址
port: 端口号
database: 选择的数据库
具体操作如下:
@SpringBootTest
class Boot06RedisApplicationTests {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Autowired
private RedisTemplate redisTemplate;
@Test
// 操作stringRedisTemplate字符串
void test1() {
//对于key、value都是String时,可以使用StringRedisTemplate
stringRedisTemplate.opsForValue().set("age", "32");
stringRedisTemplate.opsForValue().set("name", "李哥");
stringRedisTemplate.opsForList().leftPushAll("lists", "java", "python", "golang", "c++");
stringRedisTemplate.opsForHash().put("mainKey", "secondKey", "value");
stringRedisTemplate.opsForSet().add("city", "beijing", "xian", "shanghai");
stringRedisTemplate.opsForZSet().add("score", "lige", 100);
}
@Test
// 操作redisTemplate字符串
void test2() {
// 将key和hashKey的序列化方式设置位String,防止乱码,默认是JdkSerializationRedisSerializer
// 对于key、value存在对象时,可以使用RedisTemplate
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.opsForValue().set("user", new User(1, "lige", "陕西省"));
// 其余操作都类似于StringRedisTemplate
redisTemplate.opsForValue().set("age", "32");
redisTemplate.opsForList().leftPushAll("lists", "java", "python", "golang", "c++");
redisTemplate.opsForHash().put("mainKey", "secondKey", "value");
redisTemplate.opsForSet().add("city", "beijing", "xian", "shanghai");
redisTemplate.opsForZSet().add("score", "lige", 100);
}
@Test
// 对同一个key多次操作时,可以使用boundXxxOps绑定一个key
void test3() {
BoundValueOperations name = redisTemplate.boundValueOps("name");
name.set("changed lige");
name.append("zhenshuai");
}
}
9.实战应用
9.1 Redis实现分布式缓存
(1)什么是缓存?
缓存就是计算机内存中的一段数据
(2)内存中数据特点
读写快、断电立即丢失
(3)缓存解决了什么问题?
- 提高网站吞(处理请求)吐(作出响应)量提高网站运行效率、
- 减轻数据库的访问压力
(4)注意点
使用缓存时一定是数据库中数据极少发生修改,更多用于查询的操作
(5)本地缓存和分布式缓存区别?
本地缓存:存在应用服务器内存中的数据称之为本地缓存
分布式缓存:存储在当前应用服务器内存之外的数据称之为分布式缓存
集群:将同一种服务的多个节点放在一起共同对系统提供服务过程称之为集群
分布式:有多个不同服务集群功能对系统提供服务这个系统称之为分布式系统
1.利用mybatis自身本地缓存结合redis实现分布式缓存
- mybatis中应用级缓存(二级缓存) SqlSession级别缓存 所有会话共享
- 开启二级缓存
- xxxMapper.xml中加入
标签 - cache标签底层默认使用org.apache.ibatis.cache.impl.PerpetualCache
- xxxMapper.xml中加入
- 将缓存的type属性更改自定义RedisCache
- 通过mybatis默认cache源码可知,可以使用自定义cache类实现Cache接口,并对其方法进行实现
自定义Cache类:
@SuppressWarnings("all")
public class RedisCache implements Cache {
private RedisTemplate redisTemplate;
// id:对应mapper的namespace="com.atlige.boot.mapper.UserMapper"
private final String id;
public RedisCache(String id){
this.id = id;
}
@Override
public String getId() {
return this.id;
}
@Override
public void putObject(Object key, Object value) {
// 使用redis里的hash类型作为缓存存储模型,key -- id, hashkey--当前方法key, value -- value
getRedisTemplate(redisTemplate).opsForHash().put(id.toString(), getKeyToMD5(key.toString()), value);
}
@Override
public Object getObject(Object key) {
// 根据key从redis的hash类型中获取数据
return getRedisTemplate(redisTemplate).opsForHash().get(id.toString(), getKeyToMD5(key.toString()));
}
/**
* 根据指定的key删除缓存
* @param key
* @return
*/
@Override
public Object removeObject(Object key) {
return null;
}
/**
* 清空缓存
*/
@Override
public void clear() {
// 清空namespace
getRedisTemplate(redisTemplate).delete(id.toString());
}
/**
* 计算缓存数量
* @return 缓存数量
*/
@Override
public int getSize() {
// 获取hash中的key、value的数量
return getRedisTemplate(redisTemplate).opsForHash().size(id.toString()).intValue();
}
public RedisTemplate getRedisTemplate(RedisTemplate redisTemplate){
if (redisTemplate == null){
redisTemplate = (RedisTemplate) ApplicationContextUtils.getBean("redisTemplate");
}
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
return redisTemplate;
}
private String getKeyToMD5(String key){
return DigestUtils.md5DigestAsHex(key.getBytes());
}
}
注意点:
- 自定义的RedisCache不是由spring的beanFactory实例化的,而所以不能使用自动注入
@Autowired - 编写一个可以获取beanFactory的工具类
ApplicationContextUtils来获取
/**
* @author Jeremy Li
* @data 2021/1/22 - 22:39
* 用来获取springboot创建好的工厂
*/
@Component
public class ApplicationContextUtils implements ApplicationContextAware {
//保留下来的工厂
@Autowired
private static ApplicationContext applicationContext;
// 将创建好的工厂以参数的形式传递给这个类
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
ApplicationContextUtils.applicationContext = applicationContext;
}
// 提供在工厂中获取对象的方法
public static <T> T getBean(String beanName, Class<T> requiredType){
return (T) applicationContext.getBean(beanName);
}
}
-
增删改操作都会进入RedisCache的clear()中,进行清空该id下的缓存
- 在与别的查询表没有关联的情况下,这种缓存方式没有问题
- 在多表连接查询时,这种缓存会出现问题?(在更改连接表中信息后,会出现主表在缓存中的信息没有修改)
<cache-ref namespace="com.atlige.boot.mapper.UserMapper"/> -
优化:对放入redis的key进行优化,key的长度不能太长
- 使用MD5处理,加密
2.面试相关
(1)缓存穿透/击穿
客户端查询一个数据库中没有的数据记录导致缓存在这种情况下无法使用
mybatis中cache解决了缓存穿透:将数据库中没有查询到的结果也进行了缓存
(2)缓存雪崩
在系统运行的某一个时刻,突然系统中缓存突然失效,恰好在这一时刻涌来大量的客户端请求,导致所有模块缓存无法使用,大量请求涌向数据库导致极端情况,数据库阻塞或挂起。
缓存存储时:业务系统非常大,模块多,业务数据不同。不同模块放入缓存时,都会设置不同的缓存超时时间
解决方案:1.缓存永久存储(不推荐)2.不同模块放入缓存时,都会设置不同的缓存超时时间
9.2 Redis主从复制架构
主从复制架构仅仅用来解决数据的冗余备份,从节点仅仅用来同步数据
无法解决:1.master节点出现故障的自动故障转移
### master 7001
bind 0.0.0.0
port:7001
daemonize yes
protected-mode no
### slave1 7002
bind 0.0.0.0
port:7002
daemonize yes
protected-mode no
replicaof 192.168.152.128 7001
### slave2 7003
bind 0.0.0.0
port:7003
daemonize yes
protected-mode no
replicaof 192.168.152.128 7001
实现数据共享,但是从节点只能进行read操作
9.3 Redis哨兵机制
Sentinel是Redis的高可用性能解决方法:由一个或多个Sentinel实例组成的Sentinel系统可以监视任意多个主服务器以及这些主服务器下的从服务器,并在被监视的主服务器进行下线状态时,自动将从服务器升级为新的主服务器。
哨兵就是带有自动故障转移的主从架构
无法解决:1.单节点并发压力问题 2.单节点内存和磁盘物理上限问题
创建一个sentinel文件夹并创建一个sentinel.conf
sentinel monitor [主从架构名称:mymaster] [主服务器的ip:192.168.152.128] [端口号:7003] [设置哨兵的数量:1]
使用redis/bin/下的redis-sentinel 加载配置文件并启动哨兵即可
9.4 Redis集群
(1)集群细节
- 所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽
- 节点的fail是通过集群中超过半数的节点检测失效时才生效
- 客户端与redis节点直连,不需要中间proxy层,客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
- redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster负责维护node<—>slot<—>value
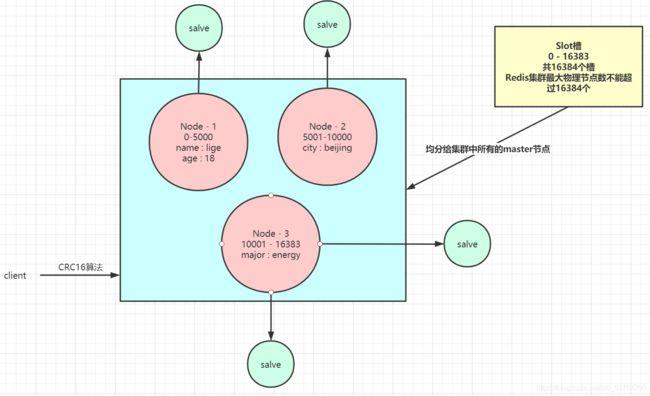
CRC16算法:
- 对集群模式下的所有key进行CRC16计算,计算的结果始终在0-16383之间
- 对客户端的key进行CRC计算时,同一个key多次经过CRC16计算结果始终一致
- 对客户端的不同key进行CRC16计算,计算的结果会出现不同的key结果一致
相关的linux命令:
# 对每一个redis.conf进行修改
bind 0.0.0.0
port xxxx
daemonize yes
pidfile redis_xxxx.pid
logfile redis_xxxx.log
appendonly yes
cluster-enabled yes
cluster-config-file nodes-xxxx.conf
cluster-node-timeout 5000
cluster-slave-validity-factor 10
cluster-migration-barrier 1
cluster-require-full-coverage yes
# 构建集群
redis-cli --cluster create 192.168.152.128:8000 192.168.152.128:8001 192.168.152.128:8002 192.168.152.128:8003 192.168.152.128:8004 192.168.152.128:8005 --cluster-replicas 1
# 查看集群状态
redis-cli --cluster check 192.168.152.128:8001
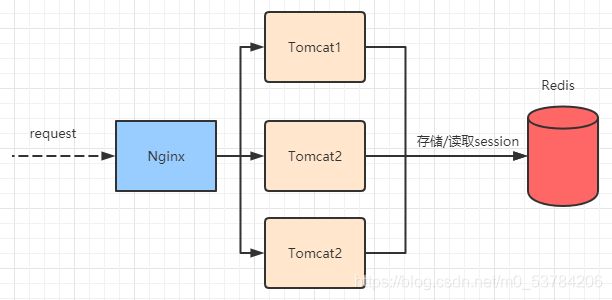
9.5 Redis分布式Session管理
redis的session管理是利用spring提供的session管理解决方案,将一个应用session交给redis存储,整个应用中所有的session的请求都会去redis中获取相应的session数据
-
MSM:Memcached Session Manager
- 整合:1.tamcat lib目录引入Memcached整合jar 2.tomcat conf context.xml配置tomcat整合Memcached
- 原理:通过Memcached整合tomcat应用服务,将应用服务中所有部署应用的session全部交给Memcache进行管理
-
RSM:Redis Session Manager
- 整合:基于某个应用的整合
- 原理:基于应用方式session管理
步骤:
- 引入依赖
<!--springboot-redis-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--spring-data-redis session管理-->
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
- 编写配置类
@Configuration
@EnableRedisHttpSession // 将整个应用中使用session的数据全部交给redis处理
public class RedisSessionManager {
}
- 进行测试
@Controller
@RequestMapping("test")
public class TestController {
@RequestMapping("test")
public void test(HttpServletRequest request, HttpServletResponse response) throws IOException {
List<String> list = (List<String>) request.getSession().getAttribute("list");
if (list == null){
list = new ArrayList<>();
// request.getSession().setAttribute("list", list);
}
list.add("xxxx");
request.getSession().setAttribute("list", list); // 每次session变化都要同步session
response.getWriter().write("size: " + list.size() + "\n");
response.getWriter().write("sessionId: " + request.getSession().getId());
}
@RequestMapping("logout")
public void testLogout(HttpServletRequest request){
request.getSession().invalidate();
}
}
== null){
list = new ArrayList<>();
// request.getSession().setAttribute(“list”, list);
}
list.add("xxxx");
request.getSession().setAttribute("list", list); // 每次session变化都要同步session
response.getWriter().write("size: " + list.size() + "\n");
response.getWriter().write("sessionId: " + request.getSession().getId());
}
@RequestMapping("logout")
public void testLogout(HttpServletRequest request){
request.getSession().invalidate();
}
}