Python实战案例:金庸的功夫流派、人物关系的分析案例(下)
Python实战案例:金庸的功夫流派、人物关系的分析案例(下)
前面关于金庸小说的门派、功夫、人物及小说正文已经从网站上面下载到了本地,后面就需要通过一些金庸小说中武侠江湖的数据分析。
四、射雕郭靖黄蓉的关系分析
对于《射雕英雄传》这个剧本来说,郭靖和黄蓉无疑是读者关注的主人公。现在爬取的小说正文已准备就绪,可以通过jieba分词的自定义词典把小说中的人物加载,load_userdict方法可以帮助我们把jieba分词中装入《射雕英雄传》的一些人名,其目的在进行文章分词切分的时候会把这些中文词语当成人名使用。人名的文件已爬取后存成rewu.txt,这里可以打开这个文件,逐行读取每一个《射雕英雄传》的人名,把读取的人添加到定义好的空列表names中。代码如下。
import os
import jieba
filelist=os.listdir("book/射雕英雄传")
names=[]
with open("renwu/射雕英雄传.txt","r",encoding="utf8") as f:
with open("renwu.txt","a",encoding="utf8") as fa:
for line in f.readlines():
line=line.strip()
print(line)
fa.write(line+"\t"+"n"+"\t"+"5"+"\n")
names.append(line)
she_str=""
jieba.load_userdict("renwu.txt")
注意代码中文件的路径,可能出现不同的文件路径。
接下来,读取小说文本文件,对小说中的每一行进行人名的过滤,如果有郭靖和黄蓉在这一行中出现,就意味着郭靖和黄蓉有对话,爱恨情仇都在这一行文字中。针对每一行文字进行jieba分词,jieba分词后会形成形如“出刀 断水”这样的形式,就是词和词之间有空格隔开。把所有的词连接在一起。代码如下。
for file in filelist:
if file.find("章")>=0:
with open("book/射雕英雄传/"+file,"r",encoding="utf8") as f:
for line in f.readlines():
if line.find("郭靖")>=0 and line.find("黄蓉")>=0:
line_str=" ".join(jieba.cut(line))
she_str+=line_str+" "
stopwords=[]
with open("stopwords.txt","r",encoding="utf8") as f:
for line in f.readlines():
stopwords.append(line)
对文本中每一段郭靖和黄蓉jieba分词后的文本,做split(“ ”)分成列表,再做移除关键词,把一些非中文的内容去除掉,去除掉词后再拼接成“词”+“ ”,读取背景图片,调用wordcloud词云方法,词云模块WordCloud中传入一些参数就可以创建词云模块。
background_color="white"是背景颜色
max_font_size=150 最大的字体字号
min_font_size=50 最小的字体字号
max_words=100 词云显示的最大词汇数
random_state=50 随机状态有50个
font_path="华康俪金黑W8.TTF" 字体名称
mask=background_img mask是将字体形成的词云显示在背景图片上
对于每个词的generate_from_text()方法把词云显示到了图片上。
最后把这个words输出一个图片即可看出郭靖黄蓉之间的关系。
word.to_file("郭靖黄蓉.png")就可以把导出最终的关系图片。
对于每个词的generatefromtext()方法把词云显示到了图片上。
最后把这个words输出一个图片即可看出郭靖黄蓉之间的关系。
word.to_file("郭靖黄蓉.png")就可以把导出最终的关系图片。
全部代码如下。
for file in filelist:
if file.find("章")>=0:
with open("book/射雕英雄传/"+file,"r",encoding="utf8") as f:
for line in f.readlines():
if line.find("郭靖")>=0 and line.find("黄蓉")>=0:
line_str=" ".join(jieba.cut(line))
she_str+=line_str+" "
stopwords=[]
with open("stopwords.txt","r",encoding="utf8") as f:
for line in f.readlines():
stopwords.append(line)
对文本中每一段郭靖和黄蓉jieba分词后的文本,做split(“ ”)分成列表,再做移除关键词,把一些非中文的内容去除掉,去除掉词后再拼接成“词”+“ ”,读取背景图片,调用wordcloud词云方法,词云模块WordCloud中传入一些参数就可以创建词云模块。
background_color="white"是背景颜色
max_font_size=150 最大的字体字号
min_font_size=50 最小的字体字号
max_words=100 词云显示的最大词汇数
random_state=50 随机状态有50个
font_path="华康俪金黑W8.TTF" 字体名称
mask=background_img mask是将字体形成的词云显示在背景图片上
对于每个词的generate_from_text()方法把词云显示到了图片上。
最后把这个words输出一个图片即可看出郭靖黄蓉之间的关系。
word.to_file("郭靖黄蓉.png")就可以把导出最终的关系图片。
全部代码如下。
import os
import jieba
from wordcloud import WordCloud
from matplotlib import pyplot
filelist=os.listdir("book/射雕英雄传")
names=[]
with open("renwu/射雕英雄传.txt","r",encoding="utf8") as f:
with open("renwu.txt","a",encoding="utf8") as fa:
for line in f.readlines():
line=line.strip()
print(line)
fa.write(line+"\t"+"n"+"\t"+"5"+"\n")
names.append(line)
she_str=""
jieba.load_userdict("renwu.txt")
for file in filelist:
if file.find("章")>=0:
with open("book/射雕英雄传/"+file,"r",encoding="utf8") as f:
for line in f.readlines():
if line.find("郭靖")>=0 and line.find("黄蓉")>=0:
line_str=" ".join(jieba.cut(line))
she_str+=line_str+" "
stopwords=[]
with open("stopwords.txt","r",encoding="utf8") as f:
for line in f.readlines():
stopwords.append(line)
she_arr=she_str.split(" ")
for she in she_arr:
if she in stopwords or she in names or len(she)==1 and not '\u4e00' <= she <= '\u9fff':
she_arr.remove(she)
word_str=""
for she in she_arr:
word_str+=she+" "
background_img=pyplot.imread("rocket.jpg")
word=WordCloud(
background_color="white",
max_font_size=150,
min_font_size=50,
max_words=100,
random_state=50,
font_path="华康俪金黑W8.TTF",
mask=background_img
)
print(word_str)
word.generate_from_text(word_str)
word.to_file("郭靖黄蓉.png")
代码的最终运行结果如下图所示。

从结果图中可以看出,黄蓉跟郭靖间的称呼:靖哥哥,与之有关系的人物:欧阳峰、洪七公等。
五、杨过小龙女关系分析
对于《神雕侠侣》这个剧本来说,杨过和小龙女无疑是读者关注的主人公。现在爬取的小说正文已准备就绪,可以通过jieba分词的自定义词典把小说中的人物加载,load_userdict方法可以帮助我们把jieba分词中装入《神雕侠侣》的一些人名,然后再对《神雕侠侣》的小说文本进行读取,把每一段中出现杨过及小龙女的段落进行jieba分词,然后去除停用词,用WordCloud画词云。这里的思路与郭靖黄蓉的分析都是一样的。
代码如下。
import os
import jieba
from wordcloud import WordCloud
from matplotlib import pyplot
filelist=os.listdir("book/神雕侠侣")
names=[]
with open("renwu/神雕侠侣.txt","r",encoding="utf8") as f:
with open("renwu1.txt","a",encoding="utf8") as fa:
for line in f.readlines():
line=line.strip()
print(line)
fa.write(line+"\t"+"n"+"\t"+"5"+"\n")
names.append(line)
she_str=""
jieba.load_userdict("renwu1.txt")
for file in filelist:
print(file)
with open("book/神雕侠侣/"+file,"r",encoding="utf8") as f:
for line in f.readlines():
if line.find("杨过")>=0 and line.find("小龙女")>=0:
line_str=" ".join(jieba.cut(line))
she_str+=line_str+" "
print(she_str)
stopwords=[]
with open("stopwords.txt","r",encoding="utf8") as f:
for line in f.readlines():
stopwords.append(line)
she_arr=she_str.split(" ")
for she in she_arr:
if she in stopwords or she in names or len(she)==1 and not '\u4e00' <= she <= '\u9fff':
she_arr.remove(she)
word_str=""
for she in she_arr:
word_str+=she+" "
background_img=pyplot.imread("rocket.jpg")
word=WordCloud(
background_color="white",
max_font_size=150,
min_font_size=50,
max_words=100,
random_state=50,
font_path="华康俪金黑W8.TTF",
mask=background_img
)
print(word_str)
word.generate_from_text(word_str)
word.to_file("杨过小龙女.png")
代码的最终运行结果如下图所示。

六、金庸小说人物关系字典
前面爬取过金庸的人物,也爬取过金庸的书,现在把所有的人物读取建立所有的人物列表,这个就把爬取到renwu文件夹下的所有文本读取,定义一个空字典和空集,空集合中存储出现的每一个人物,空集合中以字典中的人物为键,与其他人之间的关系为值,对里面的每个人先初始化关系型字典。代码如下。
import os
mypersons=os.listdir("renwu")
person_list={}
persons=[]
for person in mypersons:
with open("renwu/"+person,"r",encoding="utf8") as f:
for line in f.readlines():
if person_list.get(line) is None:
name_line=line.strip()
person_list[name_line]={}
persons.append(name_line)
接下来,打开爬取的书的文件夹,根据文件夹中的书的内容进行每行的读取,同时嵌套遍历人物集合中的每个人,如果两次遍历是一个人就跳过本次循环,继续下次,如果两次遍历不是一个人,就在当前读取的行中找一下,看是不是有这两个人的文本,如果存在这两个人的文本,就把人物初始化字典中记上1次的人物关系,再读取小说其他行时,如果还有两个人的关系,在原来的关系上再加1次。
不断读取金庸小说的文本,不断在文本读取的每一行两次遍历英雄列表中的每一英雄,不断进行两个英雄在小说行间的匹配检测,不断累加两个英雄在小说间的关系匹配和。
最后把人物关系匹配的字典形成json数据写到文件中。代码如下。
import os
mypersons=os.listdir("renwu")
person_list={}
persons=[]
for person in mypersons:
with open("renwu/"+person,"r",encoding="utf8") as f:
for line in f.readlines():
if person_list.get(line) is None:
name_line=line.strip()
person_list[name_line]={}
persons.append(name_line)
mylist=os.listdir("book")
for mydir in mylist:
mybooks=os.listdir("book/"+mydir)
for mybook in mybooks:
print(mybook)
with open("book/"+mydir+"/"+mybook,"r",encoding="utf8") as f:
for line in f.readlines():
for name1 in persons:
for name2 in persons:
if line.find(name1)>=0 and line.find(name2)>=0:
if name1==name2:
continue
if person_list[name1].get(name2) is None:
person_list[name1][name2]=1
else:
person_list[name1][name2]+=1
with open('person_list.json',"w",encoding="utf8") as f:
f.write(str(person_list))
最终形成文件中的截图如下图所示:

七、人物关系图的绘制
现在有了人物关系字典,可以画出一个人物网状关系图,不过这里要注意,人物太多,如果把人物全部画出来,就会密密麻麻,所以可以画出前50或前100的关系图。
要绘制人物关系图,就需要使用networkx模块,调用networkx中的Graph类。
networkx支持创建简单无向图、有向图和多重图;内置许多标准的图论算法,节点可为任意数据;支持任意的边值维度,功能丰富,简单易用。其作用是利用networkx可以以标准化和非标准化的数据格式存储网络、生成多种随机网络和经典网络、分析网络结构、建立网络模型、设计新的网络算法、进行网络绘制等。Graph是用点和线来刻画离散事物集合中的每对事物间以某种方式相联系的数学模型。网络作为图的一个重要领域。
networkx的使用方法,可以实例化一下Graph,addnode是添加一个节点,addedge是添加一个边,不过直接添加的话,点会画得比较大,如下面的代码。
import networkx
import json
from matplotlib import pyplot
g=networkx.Graph()
g.add_node("李一")
g.add_edge("李二","李三")
networkx.draw(g)
pyplot.show()
上面代码的运行结果如图所示。

从图中可以看到,画出的点和线都比较大,很不好看,可以把networkx.draw(g)注释掉,不进行这句代码的执行,这样addnode和addedge就不会画到屏幕上,首先设定一个布局,springlayout表示一个布局管理器,通过该布局管理器可以获取组件或容器的约束对象。然后在springlayout上使用networkx.drawnetworkxnodes在布局管理器上画点,drawnetworkxnodes的格式:
draw_networkx_nodes(g,pos,nodelist=["李一","李二","李三"],node_color="r",node_size=50)
在这个格式参数中,g是network的Graph画布,pos就是定义的springlayout布局管理器,nodelist就是结点的名称,nodecolor是节点的颜色,nodesize就是节点的大小,可以控制的节点大小。
画完了点,再去画边。
networkx.drawnetworkxedges就是画边,drawnetworkxedges的格式。
networkx.draw_networkx_edges(g,pos,edgelist=[("李一","李二"),("李二","李三")],edge_color="b",width=1)
第一个参数g是Graph画布,第二个参数pos还是springlayout的布局管理器,edgelist是两个边的起始点,edge_color是边的颜色,“b”是蓝色,width是边的粗细。
边和点在Graph的管理器上画好之后,就需要画标注,networkx.drawnetworkxlabels
是画标注,drawnetworkxlabels的格式如下。
networkx.draw_networkx_labels(g,pos,font_size=20,font_color="k",font_family='SimHei')
第一个参数g是Graph画布,第二个参数pos还是springlayout的布局管理器,fontsize是字体大小,fontcolor是字体颜色,font_family字体的名称。
最后调用 matplotlib里的pyplot.show()显示结果。
现在可以在Graph上面的springlayout管理器中,全部代码如下。
import networkx
import json
from matplotlib import pyplot
g=networkx.Graph()
g.add_node("李一")
g.add_edge("李二","李三")
pos=networkx.spring_layout(g)
networkx.draw_networkx_nodes(g,pos,nodelist=["李一","李二","李三"],node_color="r",node_size=50)
networkx.draw_networkx_edges(g,pos,edgelist=[("李一","李二"),("李二","李三")],edge_color="b",width=1)
networkx.draw_networkx_labels(g,pos,font_size=20,font_color="k",font_family='SimHei')
#networkx.draw(g)
pyplot.show()
代码执行后的结果如图所示.

八、人物关系图的绘制
前面构建的人物关系字典到这一步就可以利用人物关系字典结合,打开前面构建的人物关系字典json数据文件,用eval方法转成json数据,对于json数据中的每个人物,对其值字典类型的人物进行遍历,建立两个人之间的名字和出现次数的元组,准备根据名字和出现次数的元组进行排序,找出频率最高的前50人或者前100人进行networkx画关系图准备.代码如下.
import networkx
import json
from matplotlib import pyplot
g=networkx.Graph()
with open("person_list.json","r",encoding="utf8") as f:
str=f.read()
datas=eval(str)
nodelists=set({})
for data in datas.items():
sub_values=data[1]
sub_values=dict(sub_values)
if sub_values=={}:
continue
for sub_value in sub_values.items():
nodelists.add((data[0],sub_value[0],sub_value[1]))
print(nodelists)
print(len(nodelists))
nodelists=sorted(nodelists,key=lambda x:x[2],reverse=True)
在建立排过序的人物元素中,可能存在这样的情况,如(郭靖,黄蓉,1644),(黄蓉,郭靖,1644)这两个元组实际上是一个意思,在画图的时候,只要一条边即可,但这种情况在人与人之间的关系统计时是没有对这种相互之间的关连作去除处理的.处理这种逻辑,需要遍历两遍得到的人物关系次数的元组列表,然后发现交叉人名元素相同的就删除其中的一个数据.代码如下.
for node1 in nodelists:
for node2 in nodelists:
if node1==node2:
continue
if node1[0]==node2[1] and node1[1]==node2[0]:
nodelists.remove(node2)
continue
print(nodelists)
分析人物关系的最后就需要画边和点,需要建立数据点的列表和边的列表,把这个元组中的人物元素就是点,两个人物元素间的连线就是边,边和点的列表建立成功后就可以调用drawnetworkxnodes方法画点,drawnetworkxedges方法画边,drawnetworkxlabels方法画标签.最后调用pyplot.savefig方法保存成最终图像,保存图像的时候可以用dpi去定义分辩率.代码如下.
import networkx
import json
from matplotlib import pyplot
g=networkx.Graph()
with open("person_list.json","r",encoding="utf8") as f:
str=f.read()
datas=eval(str)
nodelists=set({})
for data in datas.items():
sub_values=data[1]
sub_values=dict(sub_values)
if sub_values=={}:
continue
for sub_value in sub_values.items():
nodelists.add((data[0],sub_value[0],sub_value[1]))
print(nodelists)
print(len(nodelists))
nodelists=sorted(nodelists,key=lambda x:x[2],reverse=True)
for node1 in nodelists:
for node2 in nodelists:
if node1==node2:
continue
if node1[0]==node2[1] and node1[1]==node2[0]:
nodelists.remove(node2)
continue
print(nodelists)
print(len(nodelists))
arrlist=nodelists[:100]
nodelist=[]
edgelist=[]
for data in arrlist:
g.add_node(data[0])
g.add_node(data[1])
nodelist.append(data[0])
nodelist.append(data[1])
g.add_edge(data[0],sub_value[0])
edgelist.append((data[0],data[1]))
pos=networkx.shell_layout(g)
networkx.draw_networkx_nodes(g,pos,nodelist=nodelist,node_color="r",node_size=50)
networkx.draw_networkx_edges(g,pos,edgelist=edgelist,edge_color="b",width=1)
networkx.draw_networkx_labels(g,pos,font_size=10,font_color="k",font_family='SimHei')
pyplot.savefig("graph1.png", dpi=1000)
代码的最终执行结果
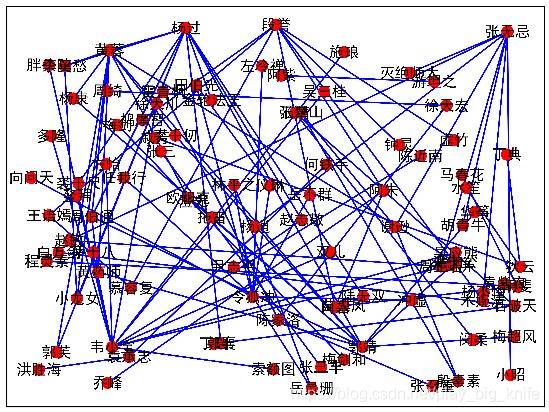
从图中也可以看出一些有意思的事情,比如郭靖和黄蓉之间有线,黄蓉和郭芙之间有线,而郭靖和郭芙之间没线,可能在文章中郭靖和郭芙没有说过话,但郭靖和郭芙却是父女关系,这也给数据分析带来乐趣吧.
代码的github地址:https://github.com/wawacode/jinyong_kongfu_style_analyse