Python3爬取知网文章
分析
首先,我们看一下入口的网站,在输入关键词搜索之前和之后它的网址并没有什么变化,所以我们不能通过直接请求它来得到文章。
搜索前
搜索后
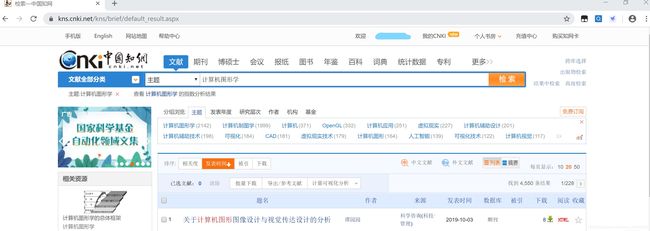
所以,我们应该换一种思路。打开开发者工具后,我们可以看到如下的内容
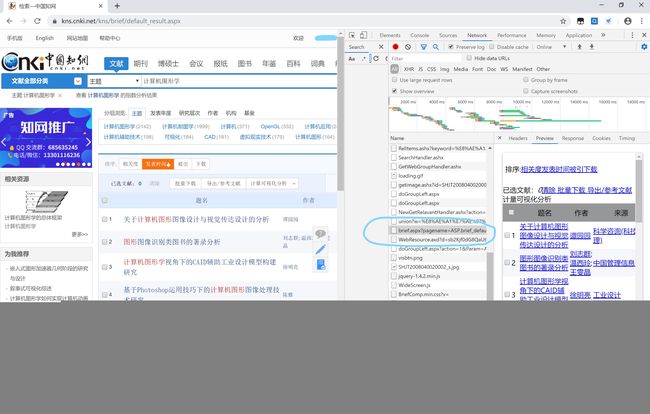
通过对比,我们可以基本上确定这个网址就是我们要爬取的网站了。它的url是
https://kns.cnki.net/kns/brief/brief.aspx?pagename=ASP.brief_default_result_aspx&isinEn=1&dbPrefix=SCDB&dbCatalog=%e4%b8%ad%e5%9b%bd%e5%ad%a6%e6%9c%af%e6%96%87%e7%8c%ae%e7%bd%91%e7%bb%9c%e5%87%ba%e7%89%88%e6%80%bb%e5%ba%93&ConfigFile=SCDBINDEX.xml&research=off&t=1572329280069&keyValue=%E8%AE%A1%E7%AE%97%E6%9C%BA%E5%9B%BE%E5%BD%A2%E5%AD%A6&S=1&sorttype=
参数如下
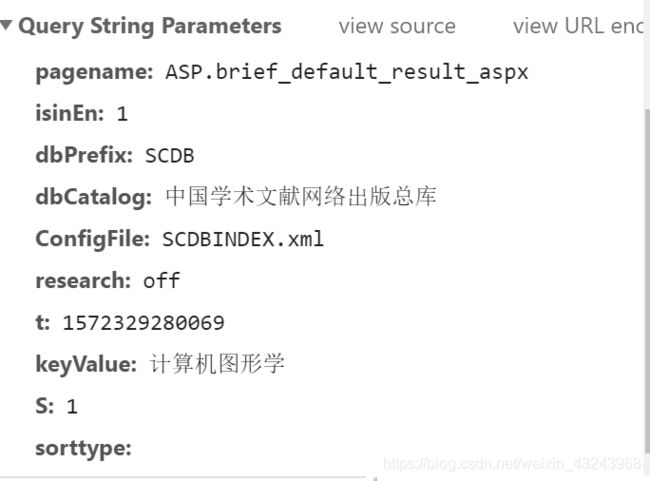
那我们是不是通过构造这些参数就可以访问了我们要的文章呢?这并不一定,点击刚才的链接,我们可能会得到这样的信息

而要想通过访问链接就直接得到内容的话,你就需要像正常访问知网一样,输入关键词进行搜索。这时,知网的服务器才会认为服务器上存在了用户,才会给你数据。那这样的话,我们就应该找POST方法,并向它传递包括关键词在内的一系列参数就可以了。同样在开发者工具下,我们找到了这样的内容
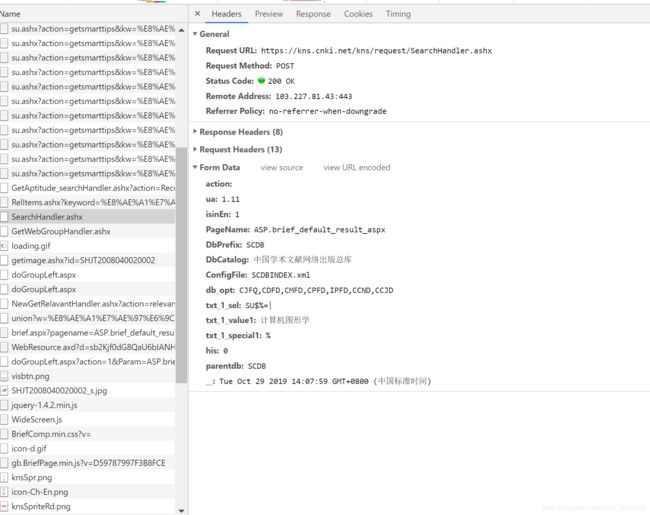
通过名字以及传输的字段我们可以很清楚地知道这个就是我们要进行post的网址了。
代码实现
1. 发送post请求
知网的formdata
zhiwangFormdata={
'action':'',
'ua': '1.11',
'isinEn': '1',
'PageName': 'ASP.brief_default_result_aspx',
'DbPrefix': 'SCDB',
'DbCatalog': '中国学术文献网络出版总库',
'ConfigFile': 'SCDBINDEX.xml',
'db_opt': 'CJFQ,CDFD,CMFD,CPFD,IPFD,CCND,CCJD',
'txt_1_sel': 'SU$%=|',
'txt_1_value1': '',
'txt_1_special1':'%',
'his': '0'
}
发送POST
session=requests.session()
post_url='https://kns.cnki.net/kns/request/SearchHandler.ashx'
zhiwangFormdata['txt_1_value1']=keyWord
response=session.post(post_url,data=zhiwangFormdata)
2. 通过Requests获得首页文章信息
注:这里的pq用的是pyquery
url='https://kns.cnki.net/kns/brief/brief.aspx?pagename='+response.text+'&keyValue='+quote(keyWord)+'&S=1&sorttype='
response=session.get(url)
html=pq(response.text)
totalNumber=html.find('div.pageBar_min>div.pagerTitleCell').text().replace('找到','').replace('条结果','').strip()
#没有论文
if totalNumber=='0':
print('没有找到')
return
print('正在爬取第1页')
get_detail(html)
获得文章详细信息
def get_detail(html):
allItems=html.find('table.GridTableContent>tr').items()
count=0
for item in allItems:
if count==0:
count=1
continue
n_l=item('td:nth-child(2)>a')
#获取文章名字及链接
dict={
'name':n_l.text().replace('\n',''),
'link':'https://kns.cnki.net'+n_l.attr('href').replace('/kns','/KCMS')
}
print(dict)
3.构造剩余页面url并爬取
在爬取到第一页后,得到的源代码中还有下一页的链接,通过提取以及构造,我们就可以一直爬取下去
#找出总的页数
totalPage = html.find('span.countPageMark').text().split('/')[1]
totalPage=int(totalPage)
#现在从第二页开始爬,一直爬到totalPage就行
count=2
#获得通用的link
nextUrl='https://kns.cnki.net/kns/brief/brief.aspx'+html.find('div.TitleLeftCell>a').attr('href')
while count<=totalPage:
print('正在爬取第'+str(count)+'页')
#构造URL
trueUrl=nextUrl.replace('curpage=2','curpage='+str(count))
response=session.get(trueUrl)
#出现验证码,对验证码进行处理
if response.url!=trueUrl:
yanzhenma(session,response.url)
continue
html=pq(response.text)
get_detail(html)
count += 1
4. 验证码处理
在爬取知网的过程中,我们还要对付验证码。这个地方我选择的是把验证码图片下载下来,在本地进行识别(我使用的是百度的智能云),在之后在向服务器发送一个带有识别结果的POST请求就行。
获取验证码图片,我们通过构造一个含有一个随机数的网址,发送请求,获得图片
而知网的POST验证码POST网页构造比较简单,直接将验证码网址加上你识别出来的结果就是你要请求网址了
#验证码处理函数
def yanzhenma(session,url):
print('识别验证码中......')
session.get(url)
response = session.get('https://kns.cnki.net/kns/checkcode.aspx?t=' + quote("'" + str(random())))
image = open('image.jpg', 'wb')
image.write(response.content)
image.close()
result =verify('image.jpg').lower()
#或者查看image.jpg手动输入
#result=input().lower()
print('验证码为'+result)
requestUrl=url+'&vericode='+quote(result)
session.get(requestUrl)
验证码识别函数
def convertimg(path):
img = Image.open(path)
width, height = img.size
while(width*height > 4000000): # 该数值压缩后的图片大约 两百多k
width = width // 2
height = height // 2
new_img=img.resize((width, height),Image.BILINEAR)
format=path.split('.')[1]
new_img.convert('RGB').save('temp.'+format)
def baiduOCR(path):
APP_ID = '你的APP_ID'
API_KEY = '你的API_KEY'
SECRECT_KEY = '你的SECRECT_KEY'
client = AipOcr(APP_ID, API_KEY, SECRECT_KEY)
format = path.split('.')[1]
i = open('temp.'+format, 'rb')
img = i.read()
message = client.basicGeneral(img) # 通用文字识别,每天 50 000 次免费
#message = client.basicAccurate(img) # 通用文字高精度识别,每天 800 次免费
i.close()
if len(message.get('words_result'))==0:
return ''
return message.get('words_result')[0]["words"]
def verify(path):
convertimg(path)
result=baiduOCR(path)
return result
最后,附上完整代码
#知网
from pyquery import PyQuery as pq
from urllib.parse import quote
from random import random
from aip import AipOcr
from PIL import Image
import requests
import settings
zhiwangFormdata={
'action':'',
'ua': '1.11',
'isinEn': '1',
'PageName': 'ASP.brief_default_result_aspx',
'DbPrefix': 'SCDB',
'DbCatalog': '中国学术文献网络出版总库',
'ConfigFile': 'SCDBINDEX.xml',
'db_opt': 'CJFQ,CDFD,CMFD,CPFD,IPFD,CCND,CCJD',
'txt_1_sel': 'SU$%=|',
'txt_1_value1': '',
'txt_1_special1':'%',
'his': '0'
}
def convertimg(path):
img = Image.open(path)
width, height = img.size
while(width*height > 4000000): # 该数值压缩后的图片大约 两百多k
width = width // 2
height = height // 2
new_img=img.resize((width, height),Image.BILINEAR)
format=path.split('.')[1]
new_img.convert('RGB').save('temp.'+format)
def baiduOCR(path):
APP_ID = '你的APP_ID'
API_KEY = '你的API_KEY'
SECRECT_KEY = '你的SECRECT_KEY'
client = AipOcr(APP_ID, API_KEY, SECRECT_KEY)
format = path.split('.')[1]
i = open('temp.'+format, 'rb')
img = i.read()
message = client.basicGeneral(img) # 通用文字识别,每天 50 000 次免费
#message = client.basicAccurate(img) # 通用文字高精度识别,每天 800 次免费
i.close()
if len(message.get('words_result'))==0:
return ''
return message.get('words_result')[0]["words"]
def verify(path):
convertimg(path)
result=baiduOCR(path)
return result
def get_all(keyWord):
session=requests.session()
post_url='https://kns.cnki.net/kns/request/SearchHandler.ashx'
settings.zhiwangFormdata['txt_1_value1']=keyWord
response=session.post(post_url,data=zhiwangFormdata)
url='https://kns.cnki.net/kns/brief/brief.aspx?pagename='+response.text+'&keyValue='+quote(keyWord)+'&S=1&sorttype='
response=session.get(url)
html=pq(response.text)
totalNumber=html.find('div.pageBar_min>div.pagerTitleCell').text().replace('找到','').replace('条结果','').strip()
#没有论文
if totalNumber=='0':
print('没有找到')
return
print('正在爬取第1页')
get_detail(html)
totalPage = html.find('span.countPageMark').text().split('/')[1]
totalPage=int(totalPage)
#现在从第二页开始爬,一直爬到totalPage就行
count=2
#获得通用的link
nextUrl='https://kns.cnki.net/kns/brief/brief.aspx'+html.find('div.TitleLeftCell>a').attr('href')
while count<=totalPage:
print('正在爬取第'+str(count)+'页')
#构造URL
trueUrl=nextUrl.replace('curpage=2','curpage='+str(count))
response=session.get(trueUrl)
if response.url!=trueUrl:
yanzhenma(session,response.url)
continue
html=pq(response.text)
get_detail(html)
count += 1
def yanzhenma(session,url):
print('识别验证码中......')
session.get(url)
response = session.get('https://kns.cnki.net/kns/checkcode.aspx?t=' + quote("'" + str(random())))
image = open('image.jpg', 'wb')
image.write(response.content)
image.close()
#result =yanzhen.verify('image.jpg').lower()
# 或者查看image.jpg手动输入
result=input().lower()
print('验证码为'+result)
requestUrl=url+'&vericode='+quote(result)
session.get(requestUrl)
def get_detail(html):
allItems=html.find('table.GridTableContent>tr').items()
count=0
for item in allItems:
if count==0:
count=1
continue
n_l=item('td:nth-child(2)>a')
dict={
'name':n_l.text().replace('\n',''),
'link':'https://kns.cnki.net'+n_l.attr('href').replace('/kns','/KCMS')
}
print(dict)
def run():
keyWord=input('请输入搜索词')
get_all(keyWord)
run()