常用数据结构
算法图解
二分查找
1.对于有序的集合可以使用
2.从中间开始查找
def binary_search(list,item):
low = 0
high = len(list) - 1
while low <= high:
mid = (low+high)//2
guess = list[mid]
if guess == item:
return mid
if guess > item:
high = mid-1
else:
low = mid+1
return None
print(binary_search([1,3,4,5,6,7,8,9],4))
3.只适合有顺序的集合
大O表示法
1.大O表示法指的并非以秒为单位的速度。大O表示法让你能够比较操作数,它指出了算法运行时间的增速。
2.常见大O表示时间:
2.1 O(log n),也叫对数时间,这样的算法包括二分查找。
2.2 O(n),也叫线性时间,这样的算法包括简单查找。
2.3 O(n * log n),这样的算法包括第4章将介绍的快速排序——一种速度较快的排序算法。
2.4 O(n**2),这样的算法包括第2章将介绍的选择排序——一种速度较慢的排序算法。
2.5 O(n!),这样的算法包括接下来将介绍的旅行商问题的解决方案——一种非常慢的算法
数组和链表的区别
数组:在内存中元素都是需要相连的。一旦添加的元素,超过获取到的内存就需要扩充,然后重新分配空间。如果提前准备好大量的空间又会照成空间的浪费。所以数组不适合添加元素O(n)。数组也有很大的优点,查找元素时可以直接查找出来,复杂度为O(1)
链表:不会照成空间的浪费。只要哪里有位置,都可以存储,需要一个元素标记着下一个元素的位置O(1)。但搜索的时候,只能从头开始一步一步的查看,时间为O(n)
选择排序
1.大O表示法:O(n**2)
1.假如给了一个无序数组,对这个数组进行排序,首先数组循环n次找出最小的,然后放到一个新的数组中,然后继续在循环n次找到第二小的,一直循环,直至拍好顺序,所以时间复杂度O(n**2)
def findSmallest(arr):
smallest = arr[0]
smallest_index = 0
for i in range(1,len(arr)):
if arr[i] < smallest:
smallest = arr[i]
smallest_index = i
return smallest_index
def selectionSort(arr):
newArr = []
for i in range(len(arr)):
smallest = findSmallest(arr)
newArr.append(arr.pop(smallest))
return newArr
print(selectionSort([5,3,6,2,10]))
递归
栈
和队列的差别就在:队列是先进先出,栈是先进后出。就像洗盘子,洗的第一个盘子放在最下面。用的时候是从最上面拿,也就是最后放进去的盘子。
函数中称为调用栈。
递归调用栈
例如求出某一个数的阶乘,最简单的递归使用:
def fact(x):
if x == 1:
return x
else:
return x * fact(x-1)
快速排序(快排)
快排主要是把一个数组,按照随机的一个数字,分为大于这个数字的和小于这个数字的两组,然后使用递归,进行排序
快排简要步骤:
(1) 选择基准值。
(2) 将数组分成两个子数组:小于基准值的元素和大于基准值的元素。
(3) 对这两个子数组进行快速排序。
例如对一个队列进行排序:
def quicksort(array):
#基线条件必须设置,不然会出现无止尽的调用
if len(array) < 2:
return array
else:
pivot = array[0]
less = [i for i in array[1:] if i <= pivot]
greater = [i for i in array[1:] if i>= pivot]
return quicksort(less) + [pivot] + quicksort(greater)
散列表
1.在python中称为字典,在ruby中称为哈希,例:{‘name’:‘Lisi’}
散列函数
1.散列函数“将输入映射到数字”。
2.散列函数并不是没有规律的,相反散列函数必须要满足一定的要求,才能称得上合格的散列函数。简单要求:
它必须是一致的。例如,假设你输入apple时得到的是4,那么每次输入apple时,得到的都
必须为4。如果不是这样,散列表将毫无用处。
它应将不同的输入映射到不同的数字。例如,如果一个散列函数不管输入是什么都返回1,它就不是好的散列函数。最理想的情况是,将不同的输入映射到不同的数字。
广度优先搜索
简单介绍:
假如你要找一个卖水果的商人,你准备在你的朋友中寻找。

首先找自己的第一层朋友关系。如果没有再寻找自己的的朋友的朋友。第一层朋友成为一度关系,往后一次累加,二层关系、三层关系等等。
一层关系权重最高,优先寻找,然后一层一层寻找。
这就被成为广度优先搜索。
简单实现这种案例:
#创建朋友关系
friend = {
}
friend["you"] = ["alice", "bob", "claire"]
friend["bob"] = ["anuj", "peggy"]
friend["alice"] = ["peggy"]
friend["claire"] = ["thom", "jonny"]
friend["anuj"] = []
friend["peggy"] = []
friend["thom"] = []
friend["jonny"] = []
#创建一个队列
from collections import deque
def search_shuiguo():
search_queue = deque()
search_queue += friend["you"]
while search_queue:
#抛出队列左边的值
person = search_queue.popleft()
if person_is_shuiguo(person):
print(person + "是水果销售商")
return True
else:
search_queue += friend[person]
return False
def person_is_shuiguo(name):
return name[-1] == "m"
队列是先进先出,很适合用于广度优先搜索。
狄克斯特拉算法
简单介绍:
狄克斯特拉算法简单来说就是广度优先搜索加上了权重。
例如:

如图,你要计算双子峰到金门大桥的距离。可以使用广度优先搜索。
先计算离自己第一步的,在计算离自己两步的,在计算三步的。可以计算出最近距离。但是这种没有考虑到,每个距离的长短不同,工具不同,时间也会有差距。这个时候就可以使用狄克斯特拉算法。
例:
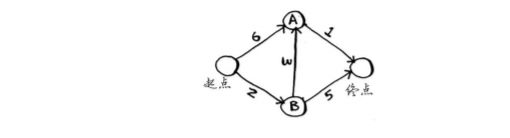
狄克斯特拉算法包含四个步骤:
(1) 找出“最便宜”的节点,即可在最短时间内到达的节点。
(2) 更新该节点的邻居的开销,其含义将稍后介绍。
(3) 重复这个过程,直到对图中的每个节点都这样做了。
(4) 计算最终路径。
创建三个hash表

#创建与邻居的距离hash
graph = {
}
graph["start"] = {
}
graph["start"]["a"] = 6
graph["start"]["b"] = 2
graph["a"] = {
}
graph["a"]["fin"] = 1
graph["b"] = {
}
graph["b"]["a"] = 3
graph["b"]["fin"] = 5
graph["fin"] = {
}
#创建起点到各个地点的开销表
#表示无穷大
infinity = float("inf")
costs = {
}
costs["a"] = 6
costs["b"] = 2
#因为不是自己邻居,不知道会有多远,所以设置无穷大
costs["fin"] = infinity
#存储父节点的哈希
parents = {
}
parents["a"] = "start"
parents["b"] = "start"
parents["fin"] = None
#创建数组用于记录处理过的节点
processed = []
#找出开销最小的节点
def find_lowest_cost_node(costs):
lowest_cost = float("inf")
lowest_cost_node = None
for node in costs:
cost = costs[node]
if cost < lowest_cost and node not in processed:
lowest_cost = cost
lowest_cost_node = node
return lowest_cost_node
#未处理的节点中寻找开销最小的节点
node = find_lowest_cost_node(costs)
while node is not None:
cost = costs[node]
neighbors = graph[node]
for n in neighbors.keys():
new_cost = cost + neighbors[n]
if costs[n] > new_cost:
parents[n] = node
processed.append(node)
node = find_lowest_cost_node(costs)
贪婪算法
贪婪算法是一种非常简单我的问题解决策略。它求出的很大可能不是最优解。但是也是一种解法。是一种很方便很快速的解法,它旨在求出一种解,不管是不是最优解
例:假设你办了个广播节目,要让全美50个州的听众都收听得到。为此,你需要决定在哪些广播台播出。在每个广播台播出都需要支付费用,因此你力图在尽可能少的广播台播出。
贪婪算法解法:
(1) 选出这样一个广播台,即它覆盖了最多的未覆盖州。即便这个广播台覆盖了一些已覆盖
的州,也没有关系。
(2) 重复第一步,直到覆盖了所有的州。
def find_states():
# 要覆盖的州
states_needed = set(["mt", "wa", "or", "id", "nv", "ut", "ca", "az"])
# 广播台清单
stations = {
}
stations["kone"] = set(["id", "nv", "ut"])
stations["ktwo"] = set(["wa", "id", "mt"])
stations["kthree"] = set(["or", "nv", "ca"])
stations["kfour"] = set(["nv", "ut"])
stations["kfive"] = set(["ca", "az"])
final_stations = set()
while states_needed:
best_station = None
states_covered = set()
for station,states in stations.items():
covered = states & states_needed
if len(covered) > len(states_covered):
best_station = station
states_covered = covered
states_needed -= states_covered
final_stations.add(best_station)
return final_stations
print(find_states())