信息论、最大熵模型
七月在线4月机器学习算法班课程笔记——No.8
1. 统计学习基础回顾
1.1 先验概率与后验概率
先验概率:根据以往经验和分析得到的概率,如全概率公式,它往往作为”由因求果”问题中的”因”出现。
后验概率:依据得到”结果”信息所计算出的最有可能是那种事件发生,如贝叶斯公式中的,是”执果寻因”问题中的”因”。后验概率可以根据通过贝叶斯公式,用先验概率和似然函数计算出来。
贝叶斯定理:假设 B1,B2,...,Bn 互斥且构成一个完全事件,已知它们的概率 P(Bi),i=1,2,...,n ,现观察到某事件A与 B1,B2,...,Bn 相伴随机出现,且已知条件概率 P(A|Bi) ,求 P(Bi|A) 。
【举例分析】一个医疗诊断问题,有两种可能的假设:(1)病人有癌症。(2)病人无癌症。样本数据来自某
化验测试,它也有两种可能的结果:阳性和阴性。假设我们已经有先验知识:在所有人口中只有0.008的人
患病。此外,化验测试对有病的患者有98%的可能返回阳性结果,对无病患者有97%的可能返回阴性结果。
上面的数据可以用以下概率式子表示:
P(cancer)=0.008,P(无cancer)=0.992
P(阳性|cancer)=0.98,P(阴性|cancer)=0.02
P(阳性|无cancer)=0.03,P(阴性|无cancer)=0.97
假设现在有一个新病人,化验测试返回阳性,是否将病人断定为有癌症呢?我们可以来计算极大后验假设:
P(阳性|cancer)p(cancer)=0.98*0.008 = 0.0078
P(阳性|无cancer)*p(无cancer)=0.03*0.992 = 0.0298
因此,应该判断为无癌症。
确切的后验概率可将上面的结果归一化以使它们的和为1
P(canner|+)=0.0078/(0.0078+0.0298)=0.2
P(cancer|-)=0.79
1.2 极大似然估计(MLE)
极大似然估计:已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次试验,观察其结果,利用结果推出参数的大概值。最大似然估计是建立在这样的思想上:已知某个参数能使这个样本出现的概率最大,我们当然不会再去选择其他小概率的样本,所以干脆就把这个参数作为估计的真实值。
定义:设总体分布为 f(x,θ) , x1,x2,...,xn 为该总体采用得到的样本。因为 x1,x2,...,xn 独立同分布,于是,它们的联合密度函数为:
这里, θ 被看作固定但未知的参数;反过来,因为样本已经存在,可以看成 x1,x2,...,xn 是固定的。 L(x,θ) 是关于 θ 的函数,即似然函数。求参数 θ 的值,使得似然函数取最大值,这种方法就是极大似然估计。
求最大似然函数估计值的一般 步骤:
1) 写出似然函数;
2) 对似然函数取对数,得到对数似然函数;
3) 若对数似然函数可导,求导,解方程组 logL(θ1,θ2,...,θk)=∑ni=1f(xi;θ1,θ2,...,θk) ,得到驻点;
4) 分析驻点是极大值点。
举例:10次抛硬币的结果是:正正反正正正反反正正,假设P是每次抛硬币结果为正的概率。则得到这样的实验结果的概率是:
最优解是: p=0.7
2. 信息论基础
2.1 信息与熵
信息: i(x)=−log(p(x)) 如果说概率p是对确定性的度量,那么信息就是对不确定性的度量。
独立事件的信息:如果两个事件X和Y独立,即p(xy)=p(x)p(y) ,假定X和y的信息量分别为i(x)和i(y),则二者同时发生的信息量应该为i(x^y)=i(x)+i(y)。
。
熵:是对随机变量平均不确定性的度量。1948年,香农Claude E. Shannon引入信息(熵),将其定义为离散随机事件的出现概率。一个系统越是有序,信息熵就越低;反之,一个系统越是混乱,信息熵就越高。所以说,信息熵可以被认为是系统有序化程度的一个度量。不确定性越大,熵值越大;若随机变量退化成定值,熵为0。熵是自信息的期望。
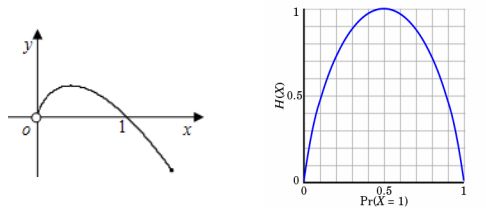
熵其实是定义了一个函数(概率分布函数)到一个值(信息熵)的映射。下图左边表示的是一元函数 −xlog(x) 熵的图像,右边是二元函数 −xlog(x)−(1−x)log(1−x) 熵的图像:
互信息:i(y,x)=i(y)-i(y|x)=log(p(y|x)/p(y)) 收信者收到信息x后,对信源发Y的不确定性的消除。
互信息具有对称性:
i(y,x)=i(y)-i(y|x)=log(p(y|x)/p(y))
=log(p(yx)/(p(y)p(x)))
=log(p(x|y)/p(x))
=i(x)-i(x|y)=i(x,y)
=i(先验事件)-i(后验事件)
平均互信息:决策树中的“信息增益”其实就是平均互信息
I(X,Y)。
信息论与机器学习的关系:
| 信息论视角 | 机器学习视角 |
|---|---|
| 接受信号 | 特征 |
| 信源 | 标签 |
| 平均互信息 | 特征有效性分析 |
| 最大熵模型 | 极大似然法 |
| 交叉熵 | 逻辑回归损失函数 |
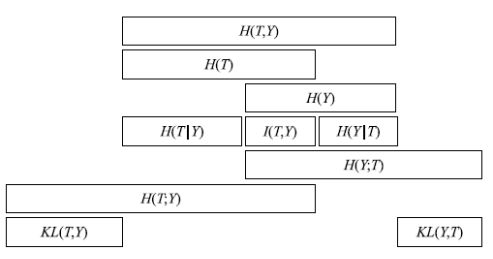
2.2 熵之间的关系
联合熵:两个随机变量X,Y的联合分布,可以形成联合熵Joint Entropy,用H(X,Y)表示。不能做误差衡量。
条件熵:在随机变量X发生的前提下,随机变量Y发生所新带来的熵定义为Y的条件熵,用H(Y|X)表示,用来衡量在已知随机变量X的条件下随机变量Y的不确定性。可用来计算交叉熵。H(Y|X)=H(X,Y)-H(X),表示(X,Y)发生所包含的熵减去X单独发生包含的熵。
平均互信息:I(X;Y) 衡量相似性。
交叉熵:H(T;Y)。衡量两个概率分布的差异性。逻辑回归中的代价函数用到了交叉熵。
相对熵:KL散度,也是衡量两个概率分布的差异性。
各个熵之间的关系:图中T即上述公式中的X,条状长短代表值的范围。

3. 最大熵模型
3.1 最大熵原理
最大熵理论:在无外力作用下,事物总是朝着最混乱的方向发展。事物是约束和自由的统一体。事物总是在约束下争取最大的自由权,这其实也是自然界的根本原则。在已知条件下,熵最大的事物,最可能接近它的真实状态。最大熵原理的一个基本假设就是:认为已知的事物是一种约束,未知的条件是均匀分布且没有偏见的。
最大熵原理进行机器学习:比如用最大条件熵求最大条件概率。
1. 定义条件熵:最大熵的目标是定义一个熵,条件熵实际上就是要找的模型。最大化的条件熵得到的结果是要找到一个条件概率对应的分布,条件概率的分布就是要求的模型,所以,要求的就是条件概率,可以用条件熵定义目标函数。条件熵最大的时候对应的条件概率就是要求的条件概率。公式中x表示特征,y表示标签。
2. 模型目的:找到条件熵。公式中P*表示理想概率,公式表示最大化条件熵对应的自变量。
3. 定义特征函数:把其他约束条件写成期望相等的形式。
4. 约束条件:定义如下
其中,
E˜(fi)=∑(x,y)∈zp˜(x,y)fi(x,y)=1N∑(x,y)∈Tfi(x,y)N=|T|
E(fi)=∑(x,y)∈zp(x,y)fi(x,y)=∑(x,y)∈zp(x)p(y|x)fi(x,y)
如何理解约束条件呢?
举个栗子:
已知:
a.“学习”可能是动词,也可能是名词。
b.“学习”可以被标注为主语、谓语、宾语、定语……
令x1、x2分别表示“学习”是动词和名词,用y1、y2、y3和y4分别表示“学习”是主语、谓语、宾语和定语。
根据无偏原则可以得到p(x1)=p(x2)=0.5,p(y1)=p(y2)=p(y3)=p(y4)=0.25
若又已知c:“学习”被定义为定语的可能性很小,p(y4)=0.05,那么坚持无偏原
则有p(y1)=p(y2)=p(y3)=0.95/3
又已知d:当“学习”被标作动词的时候,它被标作谓语的概率是0.95,p(y2|x1)=0.95。
那么,上述问题就构成了模型:计算X和Y的分布,使H(Y|X)达到最大值,并且满足条件:
p(x1)+p(x2)=1
p(y1)+p(y2)+p(y3)+p(y4)=1
p(y4)=0.05
p(y2|x1)=0.95
3.2 最大熵模型
最大熵模型的一般式:
这实际上是一个等式条件约束下的最大化问题。 P¯¯¯(f) 是特征f在样本中的期望值, p(f) 是特征f在模型中的期望值, P¯¯¯(f)=P(f)
凸优化理论求解Maxent:由于凸优化经常用来求最小值,这里的最大值可以转换一下:
引入拉格朗日乘子 w0,w1,...,wn ,定义拉格朗日函数L(P,w):
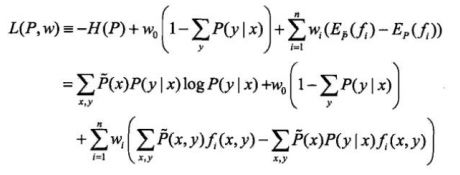
原始问题是求一个凸函数的最小值,对偶问题是求对偶问题的最大值。对于一般的函数而言,原始问题的最小值>对偶问题的最大值;对于凸函数,原始问题的最小值=对偶问题的最大值,所以可以求解对偶问题的最大值。那么,如何转化为对偶问题呢?——泛函的方法。
MLE与最大熵模型:条件概率的对数似然函数 LP˜(Pw) ,对偶函数为 ψ(w) 当条件概率分布是最大熵模型时:
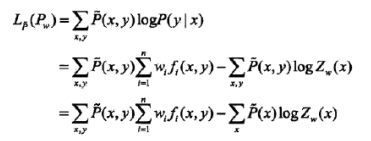
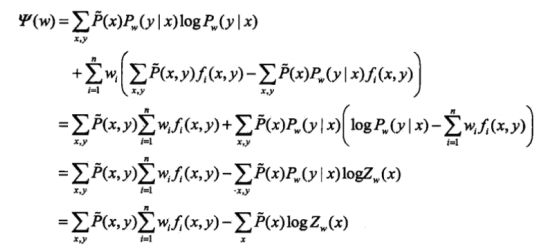
LP˜(Pw)=ψ(w) 证明了最大熵模型学习中的对偶函数极大化问题等价于最大熵模型的极大似然估计。
最大熵统计建模:是以最大熵理论为基础的方法,即从符合条件的分布中选择熵最大的分布作为最优秀的分布。
最大熵模型有两个基本的任务:特征选择和模型选择。
1)特征选择:选择一个能表达随机过程的统计特征的特征集合。
2)模型选择:即模型估计或者参数估计,就是为每个入选的特征估计权重λ。
最大熵模型的应用:词性标注、短语识别、指代消解、语法分析、机器翻译、文本分类、问题回答、语言模型等。
4. EM算法
4.1 GMM实例
GMM问题举例:
随机挑选10000位志愿者,测量他们的身高。
样本中存在男性和女性,身高分别服从N(μ1,σ1)和N(μ2,σ2)的分布。μ1,σ1,μ2,σ2未知,根据身高,判断
其属于男性还是女性。
为了求解这个问题,先求对数似然函数:
由于在对数函数里面又有加和,我们没法直接用求导解方程的办法求极大值,所以就分成两步来解。
第一步:估算数据来自哪个组份。估计数据由每个组生成的概率,对于每一个样本Xi,它由第k个组份生成的概率为:
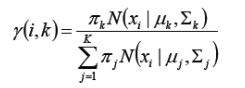
γ(i,k) 可看成组份k在生成数据xi时所做的贡献。
第二步:估计每个组份的参数。对于所有的样本点,对于组份k而言,可看作生成了 γ(i,k)xi|i=1,2,...,N 这些点。组份k是一个标准的高斯分布,利用中间变量 λ 求平均值和方差。
4.2 EM(expectation maximization)算法
EM算法是机器学习十大算法之一,EM这个问题感觉真的不太好用通俗的语言去说明白,因为它很简单,又很复杂。简单在于它的思想,简单在于其仅包含了两个步骤就能完成强大的功能,复杂在于它的数学推理涉及到比较繁杂的概率公式等。
算法整体框架:
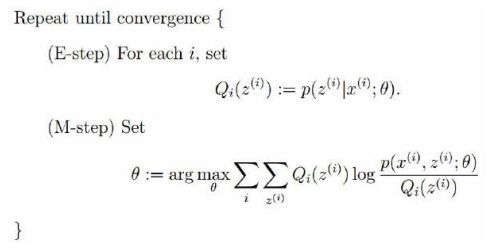
E步骤:根据参数初始值或上一次迭代的模型参数来计算出隐性变量的后验概率,其实就是隐性变量的期望。作为隐藏变量的现估计值:
M步骤:将似然函数最大化以获得新的参数值:
这个不断的迭代,就可以得到使似然函数L(θ)最大化的参数θ了。
More
- 最大熵模型中的数学推导
- 机器学习算法班学习视频及PPT下载
- EM算法