Python语言程序设计基础 第二版(嵩天著)课后答案第六章
思考与练习:
P159
6.1 元组是不可变的。即你不能修改元组。元组通过圆括号中用逗号将元素分隔。 集合内的元素不能重复,只能是固定的数据类型,例如:整数、浮点数、字符串、元组等,列表,字典,和集合本身是可变数据类型,不能作为集合的元素出现。
元组和集合的相互转换:元组→集合:set(X),例:
t = ('a','p','p','l','e')
t = set(t) #转换成集合
print(t)
#运行结果:
#{'l', 'p', 'e', 'a'}
集合→元组:tuple(X),例:
t = {
'l', 'p', 'e', 'a'}
t = tuple(t) #转换成元组
print(t)
#运行结果:
#('l', 'a', 'p', 'e')
6.2
S1 = {
1,3,5,6}
S2 = {
2,5,6}
print(S1|S2 ) # {1, 2, 3, 5, 6}
print(S1&S2) # {5, 6}
print(S1^S2) # {1, 2, 3}
print(S1-S2) # {1, 3}
6.3 不知道 不会写,等有答案再来更
关于组合型数据类型的函数在一章中已经总结过了,这里就不再重复解释
P162
6.4
S1 = [1,3,2,4,6,5]
S1 = sorted(S1) #升序
print(S1)
S1 = sorted(S1,reverse=True) #降序
print(S1)
# sorted(iterable, cmp=None, key=None, reverse=False) 函数对所有可迭代的对象进行排序操作。
# iterable -- 可迭代对象。
# cmp -- 比较的函数,这个具有两个参数,参数的值都是从可迭代对象中取出,此函数必须遵守的规则为,大于则返回1,小于则返回-1,等于则返回0。
# key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
# reverse -- 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
#当然可以用sort(),他们两个的区别是,sort(),是将原来的列表正序排序,所以它是对原来的列表进行的操作,不会产生一个新列表,(sort 方法返回的是对已经存在的列表进行操作,无返回值)具体使用如下:
S1 = [1,3,2,4,6,5]
S1.sort()
print(S1)
S1.sort(reverse=True)
print(S1)
运行结果:
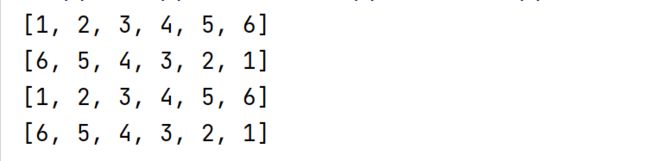
6.5
import operator #使用内置比较函数需要引入operator模块,如果是python2则可以直接使用cmp
ls1 = [30,1,2,0]
ls2 = [1,21,133]
print(operator.lt(ls1,ls2))#若ls1
#运行结果:
#False
# operator 其他内置函数:
# operator.lt(a, b) lt(a,b) 相当于 a
# operator.le(a, b) le(a,b)相当于a<=b
# operator.eq(a, b) eq(a,b)相当于a==b 字母完全一样,返回True,
# operator.ne(a, b) ne(a,b)相当于a!=b
# operator.ge(a, b) ge(a,b)相当于 a>=b
# operator.gt(a, b) gt(a,b)相当于a>b
# operator.__lt__(a, b)
# operator.__le__(a, b)
# operator.__eq__(a, b)
# operator.__ne__(a, b)
# operator.__ge__(a, b)
# operator.__gt__(a, b)
6.6
ls1 = [1,43]
ls2 = ls1
ls1[0] = 22 #ls1列表更新直接使ls2列表更新
print(ls1,ls2)
#运行结果:
#[22, 43] [22, 43]
6.7
ls = [[2,3,7],[[3,5],25],[0,9]]#[2,3,7],[[3,5],25],[0,9],以逗号间隔为一个
print(len(ls))
#运行结果:
#3
P165
6.8
20行代码改为:new = sorted(numbers,reverse=True)
from math import sqrt
def getNum():
nums = []
iNumStr = input("请输入数字(直接输入回车退出):")
while iNumStr != "":
nums.append(eval(iNumStr))
iNumStr = input("请输入数字(直接输入回车退出):")
return nums
def mean (numbers):
s = 0.0
for num in numbers:
s = s + num
return s / len(numbers)
def dev (numbers,mean):
sdev = 0.0
for num in numbers:
sdev = sdev + (num - mean) ** 2
return sqrt(sdev/(len(numbers)-1))
def median (numbers):
new = sorted(numbers,reverse=True)#倒序排列
size = len(numbers)
if size % 2==0:
med = (new[size//2-1]+new[size//2])/2
else:
med = new[size//2]
return med
n = getNum()
m = mean(n)
print("平均值:{},标准差:{:.2},中位数:{}".format(m,dev(n,m),median(n)))
6.9
from math import sqrt
def getNum():
nums = []
iNumStr = input("请输入数字(直接输入回车退出):")
while iNumStr != "":
nums.append(eval(iNumStr))
iNumStr = input("请输入数字(直接输入回车退出):")
return nums
def mean (numbers):
s = 0.0
for num in numbers:
s = s + num
return s / len(numbers)
def dev (numbers,mean):
sdev = 0.0
for num in numbers:
sdev = sdev + (num - mean) ** 2
return sqrt(sdev/(len(numbers)-1))
def median (numbers):
new = sorted(numbers)
size = len(numbers)
if size % 2==0:
med = (new[size//2-1]+new[size//2])/2
else:
med = new[size//2]
return med
def Max (number): #最大值
return max(number)
def Min (number): #最小值
return min(number)
n = getNum()
m = mean(n)
print("平均值:{},标准差:{:.2},中位数:{},最大值:{},最小值:{}".format(m,dev(n,m),median(n),Max(n),Min(n)))
#当然可以直接改为print("平均值:{},标准差:{:.2},中位数:{},最大值:{},最小值:{}".format(m,dev(n,m),median(n),max(n),min(n)))这样就可以不用增加函数,直接使用内置函数,当然上面本质也还是使用了序列类型的内置函数
6.10
中位数与其他统计指标的对比可以看出大概的贫富差距,为解决贫富差距问题思考解决办法,为贫困地区脱贫。(个人想法)
P168
6.11 错误
在字典里。一个键只对应一个值。
6.12
D = {
"张三":88,"李四":90,"王五":73,"赵六":82}
D["钱七"]=90#增加钱七
D["王五"] = 93#修改王五的值
D.pop("赵六")#删除赵六
print(D)
#运行结果:
#{'张三': 88, '李四': 90, '王五': 93, '钱七': 90}
6.13 ACDE
字典的key不能为列表的原因:字典里的key有一个原则,必须可哈希(有个函数hash()可以检测是否支持可哈希),因为字容典查找数据是通过哈希算法得到的,比元组,列表等的数组类型快很多,这本来也是字典的特性,字典里的key和value一一对应的。
而字典查找用的就是key,那么key就必须支持哈希算法,也就是前面说的可哈希。
列表,是一个可变对象,支持原处修改。
字典里存的数据,要通过key查找,如果key是一个可变对象,上一次查找的是这样,这一次查找key变了,就不能通过key查找value(前面说过,字典里的key和value是一一对应),成了另一个数据,但还是它自己,这就不符合规则啊,value也就无法查找出来了。
6.14 3
d = {
"abc":1,"qwe":3,"zxc":2}
print(len(d))
#运行结果:
#3
P171
jieba库的安装我按照课本上方法,用的pip,命令为:pip3 install jieba
6.15
import jieba
6.16
import jieba
print(jieba.lcut("中华人民共和国是一个伟大的国家"))
#运行结果:
#['中华人民共和国', '是', '一个', '伟大', '的', '国家']
6.17
直接分词好像跟预料中的不太一样
import jieba
print(jieba.lcut("打工人打工魂打工都是人上人"))
jieba.add_word("打工人")
jieba.add_word("打工魂")
jieba.add_word("人上人")
print(jieba.lcut("打工人打工魂打工都是人上人"))#增加了新词后,还有那么一点点像了
#运行结果:
#['打', '工人', '打工', '魂', '打工', '都', '是', '人', '上', '人']
#['打工人', '打工魂', '打工', '都', '是', '人上人']
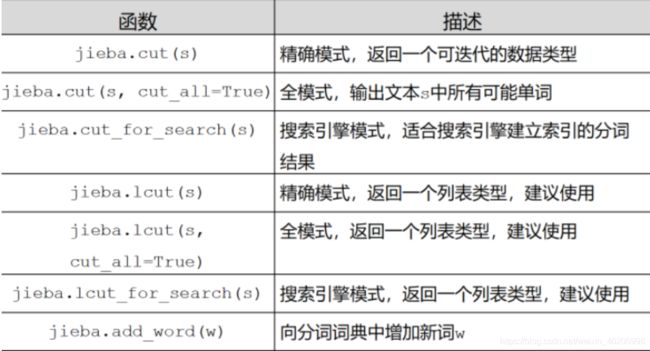
jieba库的常用分词函数:
P177
6.18
按照count的数值倒序排列
关于lambda的解释:细说lambda
6.19 对于实例代码10.1而言,是13行代码 :items = list (counts.items())
简单解释一下关于10.1的代码:
def getText():
txt = open("hamlet.txt", "r").read()
txt = txt.lower()
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~': txt = txt.replace(ch, " ") #将文本中特殊字符替换为空格
return txt
hamletTxt = getText()
words = hamletTxt.split() ##以默认空格来分割整个字符串,返回列表
counts = {
}#创建字典
for word in words:
counts[word] = counts.get(word,0) + 1#字典单词为键,已经有这个键的话就把相应的值加1,没有的话就取值为0,再加1
items = list(counts.items()) #将字典类型转换为list类型
items.sort(key=lambda x:x[1], reverse=True) #按照count的数值倒序排列
for i in range(10):
word, count = items[i]
print ("{0:<10}{1:>5}".format(word, count))
P179
6.20
1.可读性强,代码清晰明了
2.尽量减少嵌套层数,太多层次的嵌套,不容易被别人理解
3.捕获异常,尽可能的使代码完善无漏洞,不因错误而退出。
4.可以给出多种方案,比较不同方案之间的区别,找到最优方案(书上跟我想法不太一样,但这是我的答案,我做主)
5.逻辑简单明了,不要有太过复杂的逻辑(仍然是从可读性角度考虑)
6.21
对字典中键值进行填充,26个字母,键对应的值13位之后的字母。
对代码11.1的解释:
s = """Gur Mra bs Clguba, ol Gvz Crgref
Ornhgvshy vf orggre guna htyl.
Rkcyvpvg vf orggre guna vzcyvpvg.
Fvzcyr vf orggre guna pbzcyrk.
Pbzcyrk vf orggre guna pbzcygrq.
Syng vf orggre guna arfgrq.
Fcnefr vf orggre guna qrafr.
Ernqnovyvgl pbhagf.
Fcrpvny pnfrf nera'g fcrpvny rabhtu gb oernx gur ehyrf.
Nygubhtu cenpgyvgl orngf chevgl.
Reebef fubhyq arire cnff fvyragyl.
Hayrff rkcyvpvgyl fvyraprq.
Va gur snpr bs nzovthvgl,
ershfr gur grzcgngvba gb thrff.
Gurer fubhyq or bar-- naq cersrenoyl bayl bar --boivbhf jnl gb qb vg.
Nygubhtu gung jnl znl abg or boivbhf ng svefg hayrff lbh'er Qhgpu.
Abj vf orggre guna arire.
Nygubhtu arire vf bsgra orggre guna *evtug* abj.
Vs gur vzcyrzragngvba vf uneq gb rkcynva, vg'f n onq vqrn.
Vs gur vzcyrzragngvba vf rnfl gb rkcynva, vg znl or n tbbq vqrn.
Anzrfcnprf ner bar ubaxvat terng vqrn -- yrg'f qb zber bs gubfr!"""
d = {
} #创建字典
for c in (65, 97): #大写字母A到Z
for i in range(26):#循环26个字母
d[chr(i+c)] = chr((i+13) % 26 + c) #键对应的值13位之后的字母。
print("".join([d.get(c, c) for c in s])) #输出解密结果。结果就是P177页的python之禅
程序练习题:
6.1 随机密码生成。编写程序,在26个字母大小写和9和数字组成的列表中,随机生成一个10个8位密码。
import random
list = [] #字符列表
m = [] #密码列表
for i in range (10):
list.append(str(i)) #将int型转换成str,方便下边列表向str转换,如果列表中有int型不能直接转字符串
for i in range(65,91):#大写字母
list.append(chr(i)) #chr(i)可将数字与ASCII字符转换,ord(i)可将ASCII字符与数字进行转换
for i in range(97,123):#小写字母
list.append(chr(i))
for i in range(10): #10组密码
for j in range(8):#每组八个字符
m.append(random.choice(list)) #随机在列表中选择一个添加至密码列表中
print("".join(m)) #列表转字符串输出
m = [] #清空列表,生成下一组密码
运行结果:

6.2 重复元素判定。编写一程序,接收列表作为参数,如果一个元素在列表中出现了不止一次,则返回Ture,但不要改变原来列表的值。同时编写调用这个函数和测试结果的程序。
def find (list):
if len(list) != len(set(list)): #set会生成一个去掉相同元素的列表,若原列表与生成的列表长度相同则返回Ture,不同返回False
return False
else:
return True
list = []
list = input("请输入一些元素:")
while len(list) == 0:
list = input("输入为空,请再次输入一些元素:")
print(find(list))
#运行结果
#请输入一些元素:some
#True
# 请输入一些元素:summer
# False
6.3 重复元素判定续。利用集合的无重复性改变程序6.2的程序,获得一个更快更简洁的版本。
上一题的答案中,set()已经转换成集合类型,所以,本题代码同上。
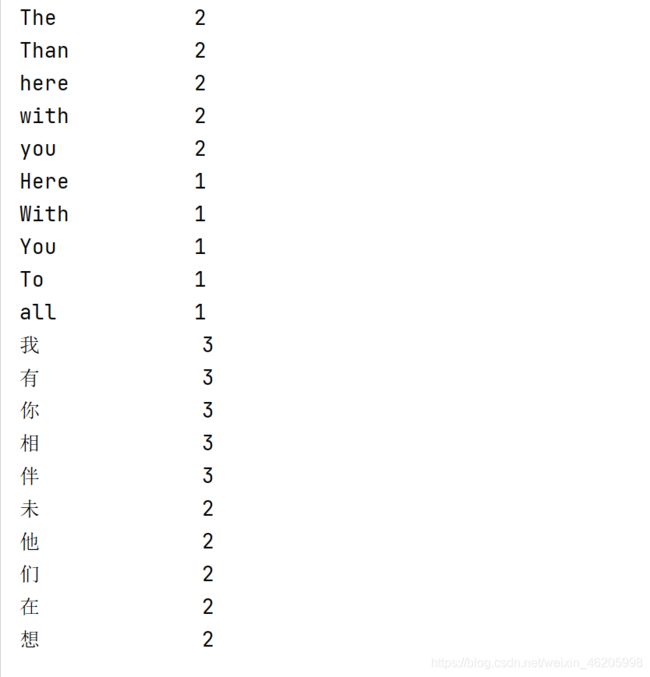
6.4 文本字符分析。编写程序接收字符串,按字符串出现频率的降序打印字符。分别尝试录入一些中英文文章片段,比较不同语言之间字符频率的差别。
改了改哈姆雷特的代码,也不知道改了个啥,就这吧(文本部分用了here with you的部分歌词,中文部分是对应的翻译)
def getText(str):
counts = {
}#创建字典
if '\u4E00'<=str<='\u9FFF':
str = str
else:
str = str.split()
for word in str:
counts[word] = counts.get(word,0) + 1#字典单词为键,已经有这个键的话就把相应的值加1,没有的话就取值为0,再加1
items = list(counts.items()) #将字典类型转换为list类型
items.sort(key=lambda x:x[1], reverse=True) #按照count的数值倒序排列
for i in range(10):
word, count = items[i]
print ("{0:<10}{1:>5}".format(word, count))
str = """
Here With You
To all my friends
The night is young
The music’s loud
They playing our song
Nowhere else that I belong
Than here with you
Than here with you
"""
getText(str)
str = """对我所有好友来讲夜未央乐未殇他们在我们喜爱的歌声里欢畅我只想和你在此相伴不想去任何其他地方有你相伴就是天堂有你相伴就是天堂
"""
getText(str)
运行结果:
6.5 生日悖论分析。生日悖论指如果一个房间里有23人或以上,那么至少有两个人的生日相同的概论大于50%。编写程序,输出在不同随机样本数量下,23个人中至少两人生日相同的概率。
import random
men=10000 #样本数
same = 0
birthday = []#生日列表
for i in range(men):
for j in range (23):
birthday.append(random.randint(1,365)) #从365天中选23天为23人的生日
if len(birthday) !=len(set(birthday)): #若23人中有人生日一样就加一
same = same +1
birthday = [] #一轮过后生日列表设为空
same = same/men#计算概率
print("23人中至少两人生日相同的概率是:{:.3}%".format(same*100))
#运行结果:
#23人中至少两人生日相同的概率是:51.2%
6.6 《红楼梦》人物统计。编写程序统计《红楼梦》中前20位出场最多的人物。
代码主要参考三国演义的例子很好改,就是排除无关词排除了半天
import jieba
excludes = {
"什么","一个","我们","那里","如今","你们","起来","这里","说道",
"众人","他们","出来","姑娘","知道","自己","一面","只见","两个",
"怎么","没有","不是","不知","这个","不知","听见","这样","进来",
"告诉","东西","就是","咱们","回来","大家","只是","所以","出去",
"不敢","这些","只得","丫头","不过","的话","一时","不好","回去",
"过来","不能","心里","如此","今日","银子","二人","几个","答应",
"还有","罢了","一回","说话","只管","这么","那边","这话","外头",
"打发","自然","那些","今儿","听说","小丫头","屋里","姐姐","奶奶",
"太太","如何","问道","妹妹","老爷","看见","不用","人家","媳妇",
"原来","不得","一声","一句","家里","进去","到底","这会子","姊妹"
}
txt = open("红楼梦.txt", "r", encoding='utf-8').read()
words = jieba.lcut(txt)
counts = {
}
for word in words:
if len(word) == 1:
continue
elif word == "老太太":
rword = "贾母"
elif word == "凤姐" or word == "凤姐儿":
rword = "王熙凤"
elif word == "黛玉":
rword = "林黛玉"
else:
rword = word
counts[rword] = counts.get(rword,0) + 1
for word in excludes:
del(counts[word])
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(20):
word, count = items[i]
print ("{0:<10}{1:>5}".format(word, count))
注:写博客只是为了当笔记看,有任何问题可以评论说,一起互相交流学习