HashMap底层实现原理你都不知道?不是吧不是吧!
HashMap底层实现原理你都不知道?不是吧不是吧!
hello大家好,这里是残月。今天我将给大家讲解一下HashMap底层实现原理和机制。相信大家不管在面试大公司还是小公司也好,都会经常被问道HashMap的实现原理,可能有的小伙伴上来就说:“啊,我知道!HashMap1.7是数组加链表,1.8是数组加链表加红黑树!”。。。然后。。。然后就没了。PS:对不起,出门右转自己下电梯(⁼̴̀д⁼̴́)。
其实要想搞懂HaspMap的底层实现原理其实很简单,对于有一定数据结构基础的小伙伴来说我们只需要知道他的扩容机制、hash算法就够了。但是对于基础差的小伙伴来说就会稍微难理解一点,希望在读这篇博客之前不懂什么是链表什么是红黑树的小伙伴补习一下数据结构꒰๑• ̫•๑꒱ ♡,这里我推荐的是B站上的某硅谷讲的,传送门
废话不多说,我们先了解一下他的大体过程。首先HashMap会通过DEFAULT_INITIAL_CAPACITY和MAXIMUM_CAPACITY这两个常量去定义他的初始桶数量和最大桶数量。
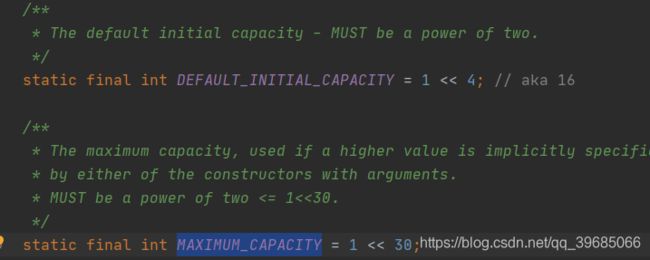
其次就是跟我们Hash桶扩容相关的负载因子相关的定义DEFAULT_LOAD_FACTOR

知道了这三个东西之后,我们可以开始一步一步往下讲了。
1.HashMap构造方法
首先第一个是我们的HashMap构造方法。对于没有看过源码的小伙伴来说,绝大多数应该只知道HashMap有一个默认的构造方法,但其实HashMap还有一个构造方法可以让我们自己去定义初始桶数量和负载因子。
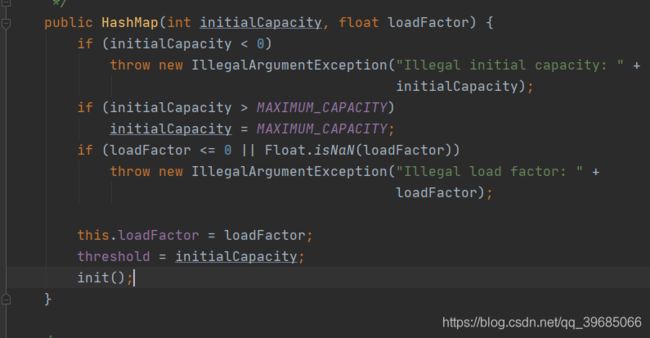
构造方法的源码很简单,有JAVA基础的同学肯定能看懂,他其实就是对你的桶数量和负载因子做一个判断,符合条件之后就会赋值给loadFactor和threshold,关于threshold我们一会将扩容机制的时候再对他进行一个讲解。
2.put方法详解
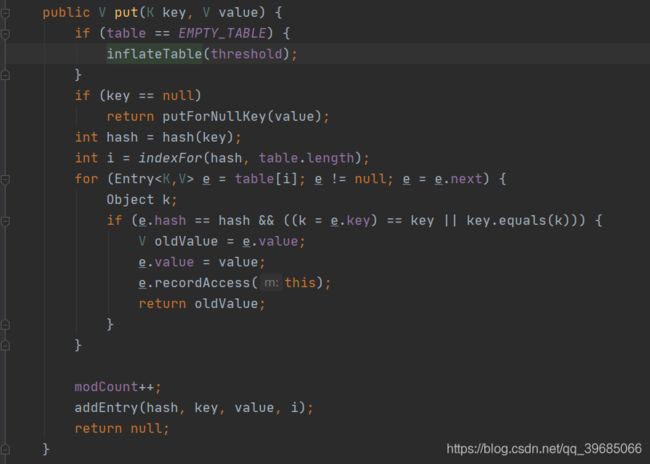
小朋友你是否有很多问号?
1) 初始化桶数量和扩容阈值
没关系,我们一行一行来看,首先看第一个if语句
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
首先他这里是判断你的table是否为空,如果为空就去初始化一个Hash桶,并将threshold传值过去,这个主要是在我们自己定义桶数量和负载因子的时候他会走进来这个if逻辑判断。具体怎么初始化的我们点进去inflateTable这个方法来一探究竟。
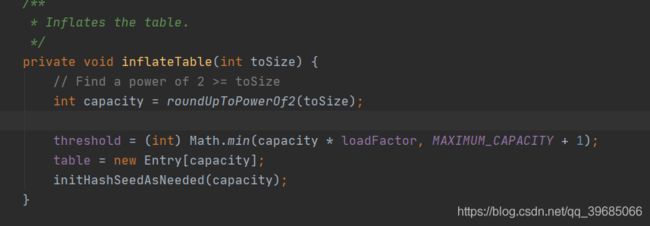
好我们来看第一行代码,他调用了roundUpToPowerOf2方法对我们自己定义的桶大小做了一次计算,并且必须是2的幂次。为什么要这样呢?这里先留一个悬念,一会我们再解释为什么要这样。那么接下来的代码大家应该也能看懂了,其实就是对我们的扩容阈值做一个赋值并且将我们的同做一个赋值,桶的大小数量根据他计算出来的capacity有关。
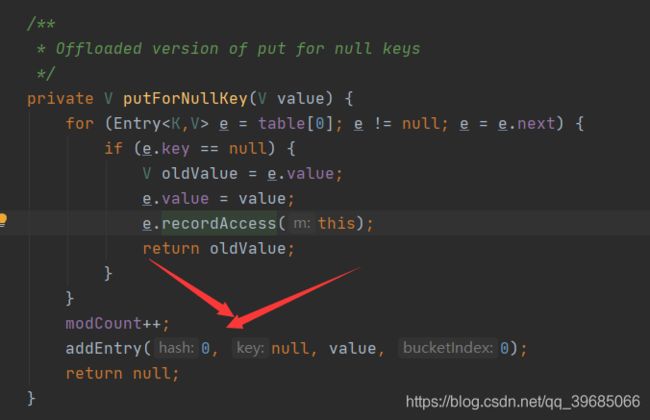
2) 对null的key做一个处理
if (key == null)
return putForNullKey(value);
注意,hashmap实际上是允许我们传key为null的值的,当我们传进来一个key值为null的东西之后,他会将这个数据存放在数组下标为0的桶中,并且这个桶只有这一个数据。
3) 对Key计算一个hash值
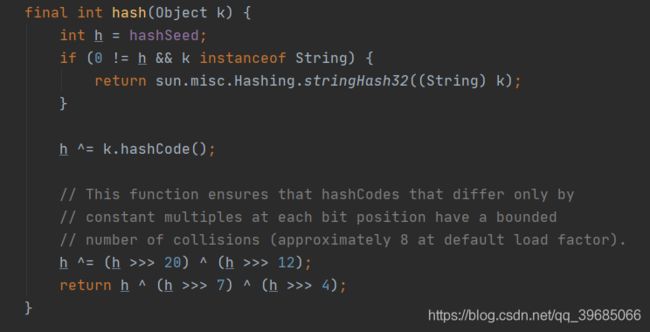
这里就有了我们第一个有趣的地方,有没有小伙伴会觉得为什么我们不直接通过k.hashCode()方法来获取hash值而是需要对hashcode在做一系列的位运算呢?
其实这里是HashMap开发人员考虑的一个问题,这个问题就是:在某些特殊场景下,我们需要重写HashCode方法,那么被我们重写过后的HashCode方法有可能散列性很差,导致某个桶的链表很长,对于get的效率来说就很差。因为在做查询的时候链表的时间复杂度是O(n),为了避免某一个桶中的链表过高,我们会对hashCode做一个重新的计算,使得它的散列性更好,保证链表长度在可控范围内。
4) 计算数组下标
int i = indexFor(hash, table.length);
我们都知道,实际上Hash桶就是由Entry数组组成的(1.8之后叫Node数组),那么我们在存放这个数据的时候是不是要先获取到这个hash的下标。在通常来说我们通过hash值获取桶的下标可以通过取模的方式,例如:int i = hash % table.length。实际上HashMap的底层并没有这么做,而是通过效率更高的方式:位运算,来获取我们桶的下标

到了这里,我就可以给大家解释一下为什么hash桶数量必须是2的幂次了。首先假如说我们的桶数量有16个,那么我们数组的索引就是从0-15对吧。那么我们的&符号的意思是什么呢,当我们两个数的二进制都为1时,他就为1.例如:
length为16的二进制:
0001 0000
length-1为15的二进制
0000 1111
HashCode的二进制:
0101 0101
通过按位与计算结果之后如下:
int h = 0000 0101
这样一来,不管我们的hashCode二进制到底是0101 0000 0101 还是其他的,都会将他的数组下标控制在15以内,但是这里有一个前提条件,你的length长度必须是2的幂次,这样你的length二进制则只会有1位为1,那么通过length-1之后才会得到类似于15这样的效果。同理,在计算hash值的时候,也是希望他的高位能够参与进来运算。搞清楚这一点之后,我们可以来看接下来的东西了
5) 遍历链表并判断是否有重复的key
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
通过数组下标我们可以取得当前桶中的链表。我们都知道hashmap实际上是不可以存放相同的key的,那么他就是通过遍历链表来查看老的数据里是否有和你新传进来的key相同的节点,如果有则会将新value赋值给老的value并且返回一个老的value。
6)添加数据并判断是否需要扩容
addEntry(hash, key, value, i);
那么对于这一行代码大家就很好,新增加一个数据嘛。但是他的addEntry里有一个判断是否需要扩容的逻辑,也是面试HashMap的重灾区。我们跟到addEntry方法里面去一探究竟!

对于最后一行代码我想不比我去解释,实际上就是添加一个新的数据进去。我们的重点放在一开始的if判断上。
首先size就是我们hashMap里面所有数据的一个总和,如果size>=threshold也就是扩容阈值并且这个桶中的链表不为空,那么就会执行我们的扩容机制(jdk1.8中会在插入数据后在执行扩容机制,而在jdk1,7中是在插入数据前)
resize方法就是我们要穿进去的一个新的值,并且值必须是我们原来桶数量的2倍,具体为什么刚刚已经解释过了大家想想就能明白为什么一定是两倍。
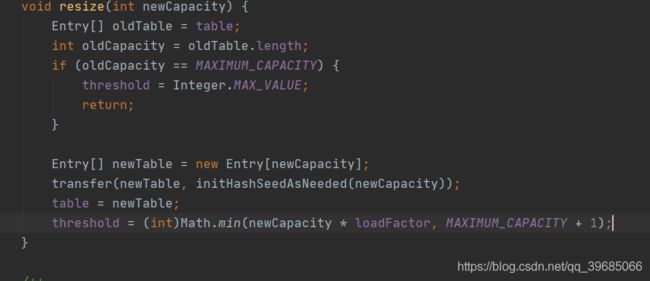
我们都知道,数组必须是连续的内存空间,那当我们数组大小发生改变了之后,我们必须要重新申请一块内存空间用来存放我们数组中的数据,那这个时候他就会把老数组里的数据转移到扩容后新数组里免去,并重新计算一个扩容阈值赋值给变量threshold。
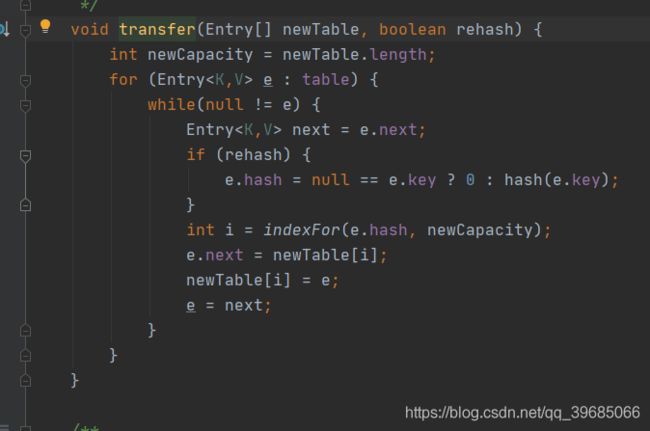
而在transfer中,我们可以看到我们的链表使用的是头插法,那么它在多线程的环境下就会造成循环链表从而造成一个死循环,所以在jdk1.8中我们的头插法被改成了尾插法!
7)为什么需要扩容?
如果你是对数据结构很了解的小伙伴肯定知道,对于链表来说,我们查询的时间复杂度是O(n),那么当我们的链表长度很长的时候实际上我们get方法的执行效率会很差,所以我们需要将链表控制在一定的长度,也就是所谓的空间复杂度来换时间复杂度。在jdk1.8中我们使用了红黑树也是因为这个道理,在数据量达到一定程度的时候由于数的特性,右边的值一定大于父节点,左边的值一定小于父节点。那么通过我们的二分查找可以很快的就get出我们需要的数据。
好啦,今天的文章就到这里~喜欢的话记得转发点赞收藏哦^^