PostgreSQL进程结构
文章目录
-
- 一、PostgreSQL进程分类
- 二、进程介绍
-
- 2.1 主进程postmaster
- 2.2 Logger系统日志进程
- 2.3 BgWriter后台写进程
- 2.4 WalWriter预写日志进程
- 2.5 PgArch归档进程
- 2.6 AutoVacuum自动清理进程
- 2.7 PgStat统计数据收集进程
- 2.8 CheckPoint(检查点)进程
一、PostgreSQL进程分类
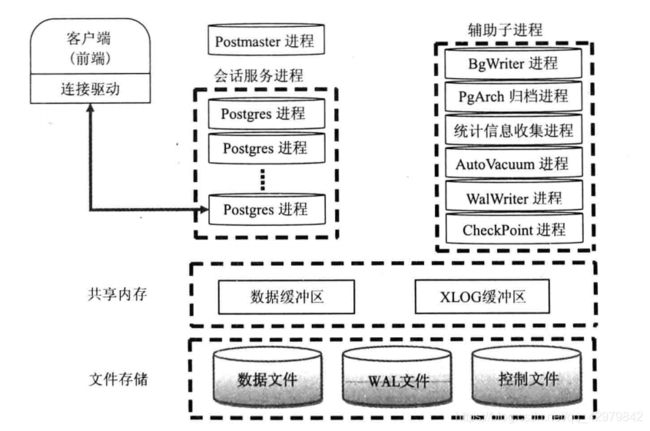
- 主进程Postmaster
- 辅助子进程Logger(系统日志)进程
- 辅助子进程BgWriter(后台写)进程
- 辅助子进程WalWriter(预写日志)进程
- 辅助子进程PgArch(归档)进程
- 辅助子进程AutoVacuum(系统自动清理)进程
- 辅助子进程PgStat(统计信息收集)进程
- 辅助子进程CheckPoint(检查点)进程
二、进程介绍
2.1 主进程postmaster
主进程postmaster是数据库实例的总控进程,负责启停数据库,同时会fork出一些辅助子进程,这些辅助子进程各自负责一部分功能;postgres为postmaster 的软链接,pg_ctl就是封装了postgres命令。
-rwxr-xr-x 1 postgres postgres 36M Sep 3 22:58 postgres
lrwxrwxrwx 1 postgres postgres 8 Sep 3 22:58 postmaster -> postgres
用户连接时,会先与postmaster进程建立连接,进行身份校验,之后fork出服务子进程。pg_stat_activity表中PID就为这些连接进程的PID。
postgres=# select * from pg_stat_activity;
+-[ RECORD 1 ]-----+---------------------------------+
| datid | |
| datname | |
| pid | 27436 |
| usesysid | 10 |
| usename | postgres |
| application_name | |
| client_addr | |
| client_hostname | |
| client_port | |
| backend_start | 2020-12-20 11:38:11.58027+08 |
| xact_start | |
| query_start | |
| state_change | |
| wait_event_type | Activity |
| wait_event | LogicalLauncherMain |
| state | |
| backend_xid | |
| backend_xmin | |
| query | |
| backend_type | logical replication launcher |
2.2 Logger系统日志进程
Logger系统日志进程通过postmaster进程、服务进程和其余辅助进程收集所有的stderr输出,并记录到日志文件中。相关参数如下:
logging_collector = on
log_directory = 'pg_log'
log_filename = 'postgresql-%a.log'
log_truncate_on_rotation = on
log_rotation_age = 1d
log_rotation_size = 0
#log_destination:配置日志输出目标,根据不同的运行平台会设置不同的值,Linux下默认为stderr。
#logging_collector:是否开启日志收集器,当设置为on时启动日志功能;否则,系统将不产生系统日志辅助进程。
#log_directory:配置日志输出文件夹。
#log_filename:配置日志文件名称命名规则。
#log_rotation_size:配置日志文件大小,当前日志文件达到这个大小时会被关闭,然后创建一个新的文件来作为当前日志文件。
2.3 BgWriter后台写进程
BgWriter进程负责把共享内存中的脏页写到磁盘上。为了提高性能,我们可能并不需要每次进行持久化,如果刷新频率过快会导致频繁的IO,如果刷新频率过慢会导致新查询缺少内存空间;因此PostgreSQL通过以下SQL进行管理:
bgwriter_delay = 200ms # 10-10000ms between rounds
bgwriter_lru_maxpages = 100 # max buffers written/round, 0 disables
bgwriter_lru_multiplier = 2.0 # 0-10.0 multiplier on buffers scanned/round
bgwriter_flush_after = 1024kB # measured in pages, 0 disables
#bgwriter_delay:backgroud writer进程连续两次flush数据之间的时间的间隔。默认值是200,单位是毫秒。
#bgwriter_lru_maxpages:backgroud writer进程每次写的最多数据量,默认值是100,单位buffers。如果脏数据量小于该数值时,写操作全部由backgroud writer进程完成;反之,大于该值时,大于的部分将有server process进程完成。设置该值为0时表示禁用backgroud writer写进程,完全有server process来完成;配置为-1时表示所有脏数据都由backgroud writer来完成。(这里不包括checkpoint操作)
#bgwriter_lru_multiplier:这个参数表示每次往磁盘写数据块的数量,当然该值必须小于bgwriter_lru_maxpages。设置太小时需要写入的脏数据量大于每次写入的数据量,这样剩余需要写入磁盘的工作需要server process进程来完成,将会降低性能;值配置太大说明写入的脏数据量多于当时所需buffer的数量,方便了后面再次申请buffer工作,同时可能出现IO的浪费。该参数的默认值是2.0。
bgwriter的最大数据量计算方式:
1000/bgwriter_delay*bgwriter_lru_maxpages*8K=最大数据量
#bgwriter_flush_after:数据页大小达到bgwriter_flush_after时触发BgWriter,默认是512KB。
2.4 WalWriter预写日志进程
预写日志可以保证数据的完整性;在修改数据之前,数据库会将修改操作记录到磁盘中。这样就不必担心数据未持久化到磁盘导致数据丢失。如果数据库宕机,重启后数据库会读取WAL日志最后一部分重新执行,将数据库恢复为宕机时的状态。WAL日志保存在pg_xlog下,xlog文件的默认大小为16MB,在xlog目录下会保存多个日志,来保证未持久化的数据可以恢复,不需要的日志会自动被覆盖。相关参数如下:
#wal_level = minimal # minimal, replica, orlogical
# (changerequires restart)
#fsync = on # flush data to disk for crash safety
# (turningthis off can cause
# unrecoverable datacorruption)
#synchronous_commit =on # synchronization level;
# off, local,remote_write, remote_apply
,or on
#wal_sync_method =fsync # the default is thefirst option
# supported by theoperating system:
# open_datasync
# fdatasync (default on Linux)
# fsync
# fsync_writethrough
# open_sync
full_page_writes =on # recover from partial page writes
#wal_compression =off # enable compression of full-pagewrites
#wal_log_hints =off # also do full pagewrites of non-critical updates
#wal_buffers = -1 # min 32kB, -1 sets basedon shared_buffers
#wal_writer_delay = 200ms # 1-10000 milliseconds
#wal_writer_flush_after= 1MB # 0 disables
#commit_delay = 0 # range 0-100000, inmicroseconds
#commit_siblings =5 # range 1-1000
# - Checkpoints -
#checkpoint_timeout =5min # range 30s-1d
#max_wal_size = 1GB
#min_wal_size = 80MB
#checkpoint_completion_target= 0.5 # checkpoint target duration,0.0 - 1.0
#checkpoint_flush_after= 0 # 0 disables #default is 256kB on linux, 0 otherwise
#checkpoint_warning =30s # 0 disables
wal_level:控制wal存储的级别。wal_level决定有多少信息被写入到WAL中。默认值是最小的(minimal),其中只写入从崩溃或立即关机中恢复的所需信息。replica 增加 wal 归档信息同时包括只读服务器需要的信息。(9.6 中新增,将之前版本的 archive 和 hot_standby合并)
fsync:该参数直接控制日志是否先写入磁盘。默认值是ON(先写入)。开启该值时表明,更新数据写入磁盘时系统必须等待WAL的写入完成。可以配置该参数为OFF,更新数据写入磁盘完全不用等待WAL的写入完成,没有了等待的时间,显然接下来的工作能够更早的去做,节省了时间,提高了性能。其直接隐患是无法保证在系统崩溃时最近的事务能够得到恢复,也就无法保证相关数据的真实与正确性。
synchronous_commit:该参数表明是否等待WAL完成后才返回给用户事务的状态信息。默认值是ON,表明必须等待WAL完成后才返回事务状态信息。配置OFF值能够更快的反馈回事务状态。因参数只是控制事务的状态反馈,因此对于数据的一致性不存在风险。但事务的状态信息影响着数据库的整个状态。该参数可以灵活的配置,对于业务没有严谨要求的事务可以配置为OFF,能够为系统的性能带来不小的提升。
wal_sync_method:WAL 写入磁盘的控制方式,默认值是fsync。可选用值:open_datasync,fdatasync,fsync_writethrough,fsync,open_sync。一般采用默认值即可,对于裸设备或文件系统的可选配置,在实际的使用中所带来的方便相对fsync很有限。
full_page_writes:参数表明是否将整个page写入WAL。postgresql中数据处理过程中的数据只保存在内存和WAL中,在内存中的整个page中包含更新提交和没有提交的,如果不将整个page写入WAL中,在介质恢复的时候WAL中记录的数据不足以实现完整的恢复(说白了就是无法实现介质恢复时事务的回滚)。
wal_buffers:用于存放WAL数据的内存空间,最小32K。
wal_writer_delay: WAL writer进程的间歇时间。默认值是200ms。准确的配置应该根据自身系统的运行状况。如果时间过长可能造成WAL buffer的内存不足;反之过小将会引起WAL的不断的写入,对磁盘的IO也是很大考验。
wal_writer_flush_after wal write的字节数超过配置的阈值(wal_writer_flush_after)时,触发fsync,默认值为1MB,如果设置为0,关闭该特性(9.6版本新增的参数)
commit_delay:表示一个已经提交的数据在WAL buffer中存放的时间,单位ms,默认值是0,不用延迟。非0值表示可能存在多个事务的WAL同时写入磁盘。如果设置为非0,表明了某个事务执行 commit后不会立即写入WAL中,而仍存放在WAL buffer中,这样对于后面的事务申请WAL buffer时非常不利,尤其是提交事务较多的高峰期,可能引起WAL buffer内存不足。如果内存足够大,可以尽量延长该参数值,能够使数据集中写入这样降低了系统的IO,提高了性能。同样如果此时崩溃数据面临着丢失的危险。
commit_siblings该参数还决定了commit_delay的有效性。系统默认值是5。表示当一个事务发出提交请求,此时数据库中正在执行的事务数量大于5,则该事务将等待一段时间(commit_delay的值),反之,该事务则直接写入WAL。
min_wal_size :最小的wal 空间
2.5 PgArch归档进程
WAL日志被循环使用,老的日志会被覆盖;PgArch进程会在日志被覆盖前备份出来。结合全备数据加上之后的WAL日志即可把数据库前滚到全量后的任意时间点。相关参数:
archive_mode = on # enables archiving; off, on, or always
#archive_command = '' # command to use to archive a logfile segment
# placeholders: %p = path of file to archive
# e.g. 'test ! -f /mnt/server/archivedir/%f && cp %p /mnt/server/archivedir/%f'
#archive_timeout = 0 # force a logfile segment switch after this
#archive_mode:表示是否进行归档操作,可选择为off(关闭)、on(启动)和always(总是开启),默认值为off(关闭)。
#archive_command:由管理员设置的用于归档WAL日志的命令。在用于归档的命令中,预定义变量“%p”用来指代需要归档的WAL全路径文件名,“%f”表示不带路径的文件名(这里的路径都是相对于当前工作目录的路径)。每个WAL段文件归档时将调用archive_command所指定的命令。当归档命令返回0时,PostgreSQL就会认为文件被成功归档,然后就会删除或循环使用该WAL段文件。否则,如果返回一个非零值,PostgreSQL会认为文件没有被成功归档,便会周期性地重试直到成功。
#archive_timeout:表示归档周期,在超过该参数设定的时间时强制切换WAL段,默认值为0(表示禁用该功能)。
2.6 AutoVacuum自动清理进程
在PostgreSQL中,对数据进行UPDATE或者DELETE操作后,数据库不会立即删除旧版本的数据,而是标记为删除状态。当事务提交后,旧版本的数据已经没有价值了,数据库需要清理垃圾数据腾出空间,而清理工作就是AutoVacuum进程进行的。相关参数如下:
#autovacuum_work_mem = -1 # min 1MB, or -1 to use maintenance_work_mem
#autovacuum = on # Enable autovacuum subprocess? 'on'
#log_autovacuum_min_duration = -1 # -1 disables, 0 logs all actions and
#autovacuum_max_workers = 3 # max number of autovacuum subprocesses
#autovacuum_naptime = 1min # time between autovacuum runs
#autovacuum_vacuum_threshold = 50 # min number of row updates before
#autovacuum_analyze_threshold = 50 # min number of row updates before
#autovacuum_vacuum_scale_factor = 0.2 # fraction of table size before vacuum
#autovacuum_analyze_scale_factor = 0.1 # fraction of table size before analyze
#autovacuum_freeze_max_age = 200000000 # maximum XID age before forced vacuum
#autovacuum_multixact_freeze_max_age = 400000000 # maximum multixact age
#autovacuum_vacuum_cost_delay = 2ms # default vacuum cost delay for
# autovacuum, in milliseconds;
#autovacuum_vacuum_cost_limit = -1 # default vacuum cost limit for
# autovacuum, -1 means use
#autovacuum:是否启动系统自动清理功能,默认值为on。
#log_autovacuum_min_duration:这个参数用来记录 autovacuum 的执行时间,当 autovaccum 的执行时间超过 log_autovacuum_min_duration参数设置时,则autovacuum信息记录到日志里,默认为 "-1", 表示不记录。
#autovacuum_max_workers:设置系统自动清理工作进程的最大数量。
#autovacuum_naptime:设置两次系统自动清理操作之间的间隔时间。
#autovacuum_vacuum_threshold和autovacuum_analyze_threshold:设置当表上被更新的元组数的阈值超过这些阈值时分别需要执行vacuum和analyze。
#autovacuum_vacuum_scale_factor和autovacuum_analyze_scale_factor:设置表大小的缩放系数。
#autovacuum_freeze_max_age:设置需要强制对数据库进行清理的XID上限值。
#autovacuum_vacuum_cost_delay:当autovacuum进程即将执行时,对 vacuum 执行 cost 进行评估,如果超过 autovacuum_vacuum_cost_limit设置值时,则延迟,这个延迟的时间即为 autovacuum_vacuum_cost_delay。如果值为 -1, 表示使用autovacuum_vacuum_cost_delay 值,默认值为 20 ms。
#autovacuum_vacuum_cost_limit:这个值为 autovacuum 进程的评估阀值, 默认为 -1, 表示使用 "vacuum_cost_limit " 值,如果在执行autovacuum 进程期间评估的cost 超过 autovacuum_vacuum_cost_limit, 则 autovacuum 进程则会休眠。
2.7 PgStat统计数据收集进程
PgStat进程是PostgreSQL数据库的统计信息收集器,用来收集数据库运行期间的统计信息,如表的增删改次数,数据块的个数,索引的变化等等。收集统计信息主要是为了让优化器做出正确的判断,选择最佳的执行计划。如下
#track_commit_timestamp = off # collect timestamp of transaction commit
#track_activities = on
#track_counts = on
#track_io_timing = off
#track_functions = none # none, pl, all
#track_activity_query_size = 1024 # (change requires restart)
# requires track_counts to also be on.
#track_activities:表示是否对会话中当前执行的命令开启统计信息收集功能,该参数只对超级用户和会话所有者可见,默认值为on(开启)。
#track_counts:表示是否对数据库活动开启统计信息收集功能,由于在AutoVacuum自动清理进程中选择清理的数据库时,需要数据库的统计信息,因此该参数默认值为on。
#track_io_timing:定时调用数据块I/O,默认是off,因为设置为开启状态会反复的调用数据库时间,这给数据库增加了很多开销。只有超级用户可以设置
#track_functions:表示是否开启函数的调用次数和调用耗时统计。
#track_activity_query_size:设置用于跟踪每一个活动会话的当前执行命令的字节数,默认值为1024,只能在数据库启动后设置。
#stats_temp_directory:统计信息的临时存储路径。路径可以是相对路径或者绝对路径,参数默认为pg_stat_tmp,设置此参数可以减少数据库的物理I/O,提高性能。此参数只能在postgresql.conf文件或者服务器命令行中修改。
2.8 CheckPoint(检查点)进程
检查点是系统设置的事务序列点,设置检查点保证检查点前的日志信息刷到磁盘中。相关参数如下:
#checkpoint_timeout = 5min # range 30s-1d
#max_wal_size = 1GB
#min_wal_size = 80MB
#checkpoint_completion_target = 0.5 # checkpoint target duration, 0.0 - 1.0
#checkpoint_flush_after = 256kB # measured in pages, 0 disables
#checkpoint_warning = 30s # 0 disables
#checkpoint_timeout :生成检查点的最大的间隔时间。
#checkpoint_completion_target 参数表示checkpoint的完成目标,系统默认值是0.5,也就是说每个checkpoint需要在checkpoints间隔时间的50%内完成。
PostgreSQL 9.5 废弃了checkpoint_segments 参数, 并引入max_wal_size 和 min_wal_size 参数, 通过max_wal_size和checkpoint_completion_target参数来控制产生多少个XLOG后触发检查点, 通过min_wal_size和max_wal_size参数来控制哪些XLOG可以循环使用.