Reading Note: Gated Self-Matching Networks for Reading Comprehension and Question Answering
Abstract
Authors present the gated self-matching networks for reading comprehension style question answering, which aims to answer questions from a given passage.
Firstly, math the question and passage with gated attention-based recurrent networks to obtatin the question-aware passage representation.
Then, utilize a self-matching attention mechanism to refine the presentation by matching the passage against itself.
Finally, employ the pointer networks to locate the positions of answers from the passage.
Introduction
This model (R-Net) consists of four parts:
1. the recurrent network encoder (to build representation for questions and passage separately)
2. the gated matching layer (to match the question and passage)
3. the self-matching layer (to aggregate information from the whole passage)
4. the pointer network layer (to predict the answer boundary)
Three-fold key contributions:
1. propose a gated attention-based recurrent network, assigning different levels of importance to passage parts depending on their relevance to the question
2. introduce a self-matching mechanism, effectively aggregating evidence from the whole passage to infer the answer and dynamically refining passage representation with information from the whole passage
3. yield state-of-the-art results against strong baselines
Task Description
Given a passage P P and a question Q Q , predict an answer A A to question Q Q based on information in P P
Methods
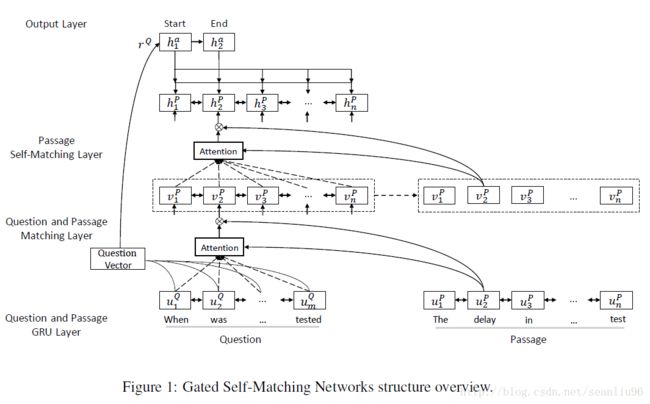

Question and Passage Encoder
Consider a question Q={wQt}mt=1 Q = { w t Q } t = 1 m and a passage P={ wPt}nt=1 P = { w t P } t = 1 n , firstly convert words to word-level embeddings ( { eQt}mt=1 { e t Q } t = 1 m and { ePt}nt=1 { e t P } t = 1 n ) and character-level embeddings ( { cQt}mt=1 { c t Q } t = 1 m and { cPt}nt=1 { c t P } t = 1 n ) which are generated by taking final hidden states of a bi-directional recurrent neural network applied to embeddings of characters in the token. Such character-level embeddings have been shown to be helpful to deal with out-of-vocab tokens.
Then use a bi-directional RNN to produce new representation { uQt}mt=1 { u t Q } t = 1 m and { uPt}nt=1 { u t P } t = 1 n .
Here, use Gated Recurent Unit (GRU) because it is computationally cheaper.
Gated Attention-based Recurrent Networks
Utilize a gated attention-based recurrent network (a variant of attention-based recurrent networks) to incorporate question information into passage representation.
Given { uQt}mt=1 { u t Q } t = 1 m and { uPt}nt=1 { u t P } t = 1 n , generate question-aware passage representation { vPt}nt=1 { v t P } t = 1 n via soft-alignment of words
where [uPt,ct]∗ [ u t P , c t ] ∗ is another gate to the input ([u^P_t, c_t]) of RNN:
ct=att(uQ,[uPt,uPt−1]) c t = a t t ( u Q , [ u t P , u t − 1 P ] ) is an attention-pooling vector of the whole question uQ u Q which focuses on the relation between the question and the current passage word:
where the vector wT w T and all matrices W∗ W ∗ contain weights to be learned.
Self-matching Attention
The self-matching attention is aim to solve the presentation with limited knowledge of context. It dynamically
1. coleects evidence from the whole passage words
2. encodes the evidence relevant to the current passage word and its matching question information into the passage representation hPt h t P :
where [vPt,ct]∗ [ v t P , c t ] ∗ is another gate to the input ([v^P_t, c_t]) of RNN,
ct=att(vP,vPt]) c t = a t t ( v P , v t P ] ) is an attention-pooling vector of the whole question uQ u Q which focuses on the relation between the question and the current passage word:
where the vector wT w T and all matrices W∗ W ∗ contain weights to be learned.
After the original self-matching layer of the passage, authors utilize bi-directional GRU to deeply integrate the matching results before feeding them into answer pointer layer. It helps to further propagate the information aggregated by self-matching of the passage.
Output Layer
Use an attention-polling over the question representation to generate the initial hidden vector for the pointer network to predict the start and end position of the answer.
Given a passage representation { hPt}nt=1 { h t P } t = 1 n , the attention mechanism is utilized as a pointer to select the start position p1 p 1 and end position p2 p 2 :
where hat−1 h t − 1 a represents the last hidden state of the pointer network,
hat h t a is the attention-pooling vector based on current predicted probability at a t :
And authors utilize the question vector rQ r Q as the initial state of the pointer network, where rQ=att(uQ,VQr) r Q = att ( u Q , V r Q ) is an attention-pooling vector of the question based on the parameter VQr V r Q :
Objective Function
To train the network, minimize the objective function:
Implementation Details
- Use the tokenizer from Stanford CoreNLP to preprocess each passage and question
- Use the Gated Recurrent Unit
- Use GloVe embeddings for questions and passages and fix embeddings
- Use zero vectors to prepresent all out-of-vocab words
- Use 1 layer of bi-directional GRU to compute character-level embeddings and 3 layers of bi-directional GRU to encode questions and passages
- Use bi-directional gated attention-based recurrent network
- Set hidden vector length to 75 for all layers
- Set hidden size to 75 for attention scores
- Set dropout rate to 0.2
- Use AdaDelta (an initial learning rate of 1 1 , the decay rate ρ ρ of 0.95 0.95 , constant ϵ ϵ of 1e−6 1 e − 6 )