cesium坡度坡向分析_【教程】利用Logistic回归模型做土地利用变化的驱动力分析...
如何利用Logistic回归模型做土地利用变化的驱动力分析?

今天介绍一下如何利用软件并运用二元Logistic回归模型做土地利用变化的驱动力分析,结合自己最近的探索和感触分享一些这方面的经验,希望对大家有所帮助。
做土地利用变化或者景观格局分析研究时,我们知道一种地类或景观的分布与变化往往是多种因素共同作用导致,所以这个时候我们常会对此做驱动力分析。通过查阅文献发现,人们常用二元Logistic回归模型来做土地利用驱动力研究,好了话不多说直接看教程吧。
01
用到的软件
ArcGIS 10.2、CLUE-S、SPSS 25
(文末有软件获取方式)
(注:以上软件是我所用到的软件版本,根据自己的实际情况不一定非得跟我的版本一样)
02
数据准备
①:某一年的土地利用数据
②:驱动因子数据
接下来我将详细介绍数据的处理与准备。
1.土地利用数据
首先土地利用数据需要进行重分类,分别将各地类单独提取出来(这里以提取耕地为例,打开【ArcMap10.2】—【ArcToolbox】—【空间分析(Spatial Analyst)工具】—【重分类】—【重分类】工具,弹出如下图所示对话框:

输入土地利用栅格数据后

点击上图【分类】按钮弹出下图对话框,这里类别选2(这里分两类,耕地为一类,非耕地为一类) ,然后点确定。

假如我的土地利用类型有6种,1、2…6分别代表6种地类,其中1代表耕地,那在这里我就将1赋值为1,其他都赋值为0,这样就得到耕地的重分类图像。

同理,通过重分类将其他几种地类依次提取出来。
至此,得到6种地类的重分类图像数据。
2.驱动因子数据
这里以常用驱动力因子数据为例(变化的驱动因子可以很多,一般列举不完,以常用且典型的为例)。选驱动因子时比较常用的是一般从自然、社会经济和交通区位(也有说可达性)三方面来选。
自然因素:高程(DEM)、坡度、坡向
社会经济因素:人口、GDP
交通区位因素:距居民点距离、距公路距离、距铁路距离、距水系距离。
(高程数据来源:地理空间数据云,坡度和坡向由DEM分析而来,这里不在叙述;社会经济因素来源于统计年鉴经栅格化后实现;交通区位因素首先要有各因素的矢量数据,矢量数据来源可以参考这个网站:http://www.webmap.cn/commres.do?method=result100W,得到矢量数据后进行【欧氏距离】分析得来)
格式要求:
所有的栅格数据(地类重分类数据和驱动因子数据)都采用统一的坐标系、投影、空间范围和空间分辨率,并且所有的栅格数据统一转为浮点型数据,这个很重要,要不然之后操作会报错。(这里涉及到坐标系及坐标转换方面,后期会专门出一期介绍这方面的内容)
至此,我们总共有15个栅格数据(6个地类和9个驱动因素)
03
格式转换
将以上15种栅格数据转为ASCII文本文件(【ArcToolbox】-【转换工具】-【由栅格转出】-【栅格转ASCII】),注意输出的名字,以免后续搞混。将转换完的数据进行重命名并同时进行文件格式转换,具体如下:
(耕地ASCII文件)—cov0.asc
(林地ASCII文件)—cov1.asc
…
(未利用地的ASCII文件)—cov5.asc
(DEM的ASCII文件)—sc1gr0.fil
(坡度的ASCII文件)—sc1gr1.fil
…
(距水系距离的ASCII文件)—sc1gr8.fil
注:
1.括号代表你刚才转为ASCII文件的数据
2.“—”右侧为你对应数据的命名和格式
3.“.asc”和“.fil”为文件的格式
4.并不一定非得跟上面命名完全一致,但是我这样命名没有出错。
5.为什么从0开始命名,因为CLUE-S只能从0开始识别
6.“sc1gr*”中,字母c后面是数字1而不是字母l,这点注意。
7.上面的ASCII文件其实就是文本文件,用记事本打开就行;然后用记事本另存为就能对名字和格式进行变换。
8.注意每一个名字所代表的数据名称,如cov0.asc代表耕地二值型文件,cov5.asc代表未利用地二值型文件,sc1gr1.fil代表的是坡度等等,最好用笔记在本子上,这样最后得出logistic回归结果的时候也知道啥代表着啥,要不然容易搞混。
将以上重命名完的15个数据复制到桌面一个新的文件夹里(我是这么做的,这样比较好找)。
04
单一记录文件制作
意思就是将每种地类文件和所有的驱动因子文件转换成一个单一记录文件,这点如果经常看这方面的论文的话应该不会感到陌生。注意:有多少种地类最终就得有多少单一记录文件,比如这里我有6种地类,那么最后就得有6个单一记录文件。
步骤如下:
打开CLUE-S软件包,为什么说它是包呢?因为这个软件所有的东西都是在一个文件夹里,它跟别的软件不一样,一般软件都是需要安装到电脑里,这个软件不需要安装,因为它就是在一个文件夹里,包括利用CLUE-S模型做土地利用变化模拟也都是在这里实现的,刚开始我也纳闷,这应该是个软件啊,怎么只有一个文件夹,这算啥软件嘛!但是后来发现,它就是这样的,所以不要感到奇怪,我们所有的操作都是在这个文件夹中实现。打开文件夹之后你会看到如下图的一些文件:
首先,我们要先将里面sc1gr0.fil、sc1gr1.fil、…、sc1gr12.fil这些自带的文件都删除,因为我们刚才已经制作了我们自己的驱动文件,所以要将它自带的这些文件删除(注意:不该删的不要删)
删除之后将我们刚才制作的那15个命名好的文件复制到这个软件的文件夹中,只要你刚才删了那些自带的数据,那么就不会弹出替换的窗口。
复制完之后然后找到下面这个文件并打开
![]()
打开之后如图所示,将这两行字母删除

我们手动输入如下字母:
cov0.asc
sc1gr0.fil
sc1gr1.fil
sc1gr2.fil
sc1gr3.fil
sc1gr4.fil
sc1gr5.fil
sc1gr6.fil
sc1gr7.fil
sc1gr8.fil
可以发现,第一行的cov0.asc其实就代表我们的第一种地类,第二行及其之后的就代表所有的驱动因子文件,这就是我之前说的要做单一记录文件的初始输入过程。输入完成后保存。
然后打开下图所示程序(鼠标左键双击即可)
![]()
弹出下图所示窗口

然后点击Start conversion开始运行,如果之前所有的数据都没有问题,则运行结束后会在文件夹里生成一个名字为“stat”的文本文档,如下图所示
![]()
然后用excel打开这个文档并另存到其他地方如桌面(这里最好是新建一个文件夹专门用来存放单一记录文件),打开另存为后的excel,会发现如下图所示的文件,这里打开的是我之前做的结果,可以看到第一列就是代表着第一种地类,第二列及其之后的列就代表各驱动因子;而行就代表着一个像元,以图中第二行为例,第一列第二行值为0就代表着该像元不是耕地的像元,是非耕地的像元,如果是耕地的像元则值会是1,后面几列的第二行数据就代表着对象像元的值,比如图中第二列第二行的值为595,就代表该像元的高程为595米,其他同理,后面几列的数值代表该像元距离那些设施的距离,如公路、铁路等。

至此,耕地的单一记录文件就制作好了,它是一个excel,因为后面的logistic回归分析是对数值进行分析而不是栅格数据,所有我们之前所做的都是在为进行logistic回顾分析做准备。
在做完耕地的单一记录文件之后同理将剩下几种地类也分别可以做出来,只不过注意的是,下一个地类的名字为cov1.asc,我们需要打开names,将cov0.asc改成cov1.asc(简单来说就是把0改为1,后面同理将1做完后改为2、3、…、5)然后保存,接着打开下面的程序:
![]()
然后点击Start conversion开始运行,得到第二个地类的单一记录文件,同样也是用excel打开并另存为excel文件。这样林地的单一记录文件也制作完成。
经过6次转换之后,我们就得到了6个地类的单一记录文件(excel格式)。
05
二元Logistic回归分析
打开spss 25 软件,打开耕地的单一记录文件,接着按下图所示打开二元logistic回归.
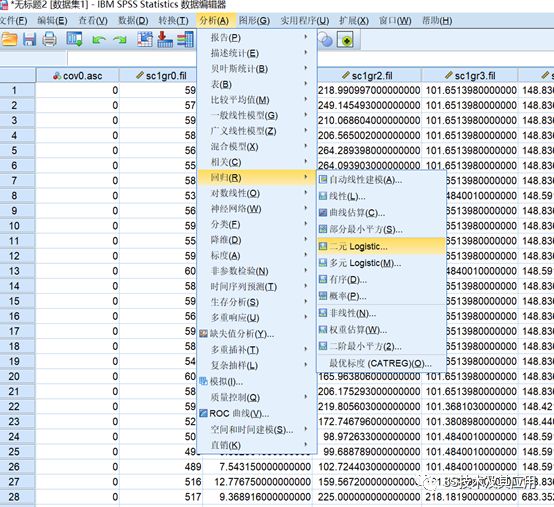

①:因变量选择地类cov0.asc
②:协变量为所有驱动因子数据
③:点击【保存】按钮,出现下图,将概率勾选
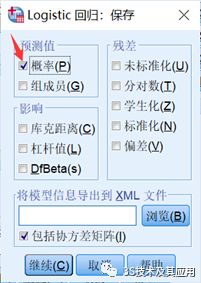
④:点击【选项】后,按下图所示选择
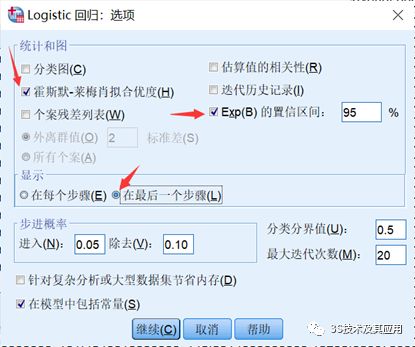
⑤:方法选择【向前:LR】。(向前:LR法是基于最大似然估计的向前逐步回归法,结果相对可靠,但最终模型的选择还需要获得专业理论的支持。)
所有设置完成后点【确定】,得到耕地的logistic回归结果,具体的回归结果怎么看,哪些具有统计学意义,哪些显著性是否小于0.05等等这里就不再叙述,不知道的可以搜一下相关logistic回归分析教程。
至此,耕地的logistic回归结果就出来了,同理,依次得到其他几个地类的logistic回归结果。具体的哪些驱动因子是主要的影响因素,那就要根据具体的数值结果进行具体分析,这里不再叙述。
好了,本次的基于二元logistic回归模型做驱动力分析的操作过程大致就是这样,不能说百分百完全正确,至少我通过分析得出的结果还是可以的,与君共赏,希望对大家有所帮助,我们下期再会。
注:本内容为原创,转载请注明来源。
软件获取方式【软件】CLUE-S模型
ArcGIS10.2安装包
SPSS 25:链接:https://pan.baidu.com/s/1U2dwa1siPklJdMALzDixDw
提取码:1mtu
END


点个“好看”你懂得!