基于pytorch的Bi-LSTM中文文本情感分类
基于pytorch的Bi-LSTM中文文本情感分类
目录
基于pytorch的Bi-LSTM中文文本情感分类
一、前言
二、数据集的准备与处理
2.1 数据集介绍
2.2 文本向量化
2.3 数据集处理
三、模型的构建
3.1 LSTM的介绍
3.2 Bi-LSTM+embedding+logsoftmax模型构建
四、模型训练与评估
五、小结与反思
参考文献
一、前言
情感分析(Sentiment Analysis),也称为情感分类,属于自然语言处理(Natural Language Processing,NLP)领域的一个分支任务,随着互联网的发展而兴起。多数情况下该任务分析一个文本所呈现的信息是正面、负面或者中性,也有一些研究会区分得更细,例如在正负极性中再进行分级,区分不同情感强度.
文本情感分析(Sentiment Analysis)是自然语言处理(NLP)方法中常见的应用,也是一个有趣的基本任务,尤其是以提炼文本情绪内容为目的的分类。它是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。
情感分析中的情感极性(倾向)分析。所谓情感极性分析,指的是对文本进行褒义、贬义、中性的判断。在大多应用场景下,只分为两类。例如对于“喜爱”和“厌恶”这两个词,就属于不同的情感倾向。
本文将采用LSTM模型,训练一个能够识别文本postive, negative情感的分类器。本文的数据集采用的2019年SMP - ECISA “拓尔思杯”中文隐式情感分析评测的官方公布的数据集,下载链接如下所示:
https://www.biendata.xyz/competition/smpecisa2019/Evaluation/
在本文中将该数据集中的中性情感删除,做成了一个二分类的问题(也可理解为回归问题),根据机器学习的经验,我的大致思路流程如下:
- 准备与处理数据集
- 构建模型
- 模型训练
- 模型评估
在此思路的基础上在2.2.1与2.2.2节讲解对于文本分词以及词向量化的相关内容,以及在2.3.2也具体讲解了文本序列化的内容,最后三四节简短的写了关于模型的构建,训练以及评估。(因为在我看来,这次实战最重要的就是对文本数据集的处理以及对模型的batch,输出以及输出的理解。)
二、数据集的准备与处理
2.1 数据集介绍
本次“拓尔思杯”中文隐式情感分析评测使用的数据集由山西大学提供,数据来源主要包括微博、旅游网站、产品论坛,主要领域/主题包括但不限于:春晚、雾霾、乐视、国考、旅游、端午节等。
本次评测中,我们将使用一个大规模情感词典,过滤掉所有包含显式情感词的文本。对这类不含显式情感词的数据进行标注,将数据标注为:褒义隐式情感、贬义隐式情感以及不含情感倾向的句子。评测数据以切分句子的篇章形式发布,保留了完整的上下文内容信息。
训练数据集包括篇章12664篇,其中标注数据14774句,褒义、贬义隐式情感句分别为3828、3957句,不含情感句为6989句。验证集包括篇章4391篇,其中标注数据5143句,褒义、贬义隐式情感句分别为1232、1358句,不含情感句为2553句。测试数据集包括篇章6380篇,其中标注数据3800句,褒义、贬义隐式情感句为919和979句,不含情感句为1902句。其余为混淆数据,混淆数据不作为测点,在最终结果评测时会预先去除。
数据集以xml格式发布,内容形式为:
红色加粗为标记句子,含有完整的上下文,标签为:0-不含情感,1-褒义隐式情感,2-贬义隐式情感[1]。
2.2 文本向量化
2.2.1 文本分词
1. 文本的tokenization
tokenization就是通常所说的分词,分出的每一个词语我们把它称为“token”
常见的分词工具很多,比如:
jieba分词:https://github.com/fxsjy/jieba
清华大学的分词工具THULAC:https://github.com/thunlp/THULAC-Python
在中文文本分词中有以下两种常用的分词方法:
把句子转化为词语
比如:“我爱深度学习” 可以分为[我,爱, 深度学习]
把句子转化为单个字
比如:“我爱深度学习”的token是[我,爱,深,度,学,习]
2. “N-garm”表示方法
其实句子不但可以用单个的字,词来表示,有的时候,我们也可以用2个、3个或者多个词来表示。这里就需要用到一种“N-gram”的表示方法。N-gram一组一组的词语,其中的N表示能够被一起使用的词的数量。
|
In [59]: text = "深度学习(英语:deep learning)是机器学习的分支,是一种以人工神经网络为架构,对数据进行表征学习的算法。" In [60]: cuted = jieba.lcut(text) In [61]: [cuted[i:i+2] for i in range(len(cuted)-1)] #N-gram 中n=2时 Out[61]:[['深度', '学习'], ['学习', '('],['(', '英语'],['英语', ':'],[':', 'deep'],['deep', ' '],[' ', 'learning'],['learning', ')'],[')', '是'],['是', '机器'],['机器', '学习'],['学习', '的'],['的', '分支'],['分支', ','],[',', '是'],['是', '一种'],['一种', '以'],['以', '人工神经网络'],['人工神经网络', '为'],['为', '架构'],['架构', ','],[',', '对'],['对', '数据'],['数据', '进行'],['进行', '表征'], ['表征', '学习'], ['学习', '的'],['的', '算法'],['算法', '。']] |
例如:
在传统的机器学习中,使用N-gram方法往往能够取得非常好的效果,但是在深度学习比如RNN中会自带N-gram的效果。
2.2.2 词向量化
我们知道中英文字词是不能够直接被模型计算的,所以需要将其转化为向量,才能在模型中进行计算。把文本转化为向量的常用方法有两种:
1. 转化为one-hot编码
2. 转化为word embedding
1. one-hot 编码
使用one-hot编码,就是将每一个token使用一个长度为N的向量表示,其中N表示词典的数量。即把待处理的文档进行分词或者是N-gram处理,然后进行去重得到一个二进制的词典。例如,我们有一个句子“深度学习”,那么进行one-hot处理后的结果如下:
| token |
one-hot encoding |
| 深 |
1000 |
| 度 |
0100 |
| 学 |
0010 |
| 习 |
0001 |
表 1 one-hot编码实例
2. word embedding
word embedding是深度学习中表示文本常用的一种方法。和one-hot编码不同,word embedding使用了浮点型的稠密矩阵来表示token。根据词典的大小,我们的向量通常使用不同的维度,例如100,256,300等。其中向量中的每一个值是一个参数,其初始值是随机生成的,之后会在训练的过程中进行学习而获得。
如果我们文本中有20000个词语,如果使用one-hot编码,那么我们会有20000*20000的矩阵,其中大多数的位置都为0,但是如果我们使用word embedding来表示的话,只需要20000\* 维度,比如20000\*300。例如:
| Token |
Num |
Vector |
| 词1 |
0 |
[w11,w12,w13...w1N]` ,其中N表示维度(dimension) |
| 词2 |
1 |
[w21,w22,w23...w2N] |
| 词3 |
2 |
[w31,w23,w33...w3N] |
| …… |
…… |
…… |
| 词m |
m |
[wm1,wm2,wm3...wmN]`,其中m表示词典的大小 |
表 2 embedding编码示例
在把所有的文本转化为向量的过程中间,我们会先把token使用数字来表示,再把数字使用向量来表示。流程即为:token---> num ---->vector。
|
embedding = nn.Embedding(vocab_size,300) #实例化 input_embeded = embedding(input) #进行embedding的操作 |
在pytorch中也有相对应的API,Embedding(num_embeddings,embedding_dim),其中参数num_embeddings表示词典的大小,embedding_dim表示词典的维度。使用方式举例如下[2]:
2.3 数据集处理
因为官方的数据集是xml格式的,本文中用最简单的方法是直接用EXCEL表打开并保存为csv文件,如下所示:

图 1 数据集的CSV表示
2.3.1 基础Dataset的准备
在实例化dataloader的过程中,我们需要考虑以下几个问题:
- 数据集给的是一个三分类的数据集,我们仅仅只需要正反的情绪;
- 在dataloader中每个batch 的 文本长度不同的问题;
- 如何将字转化为数字向量。
对于以上的问题,我们来一个个的解决。
|
首先我们需要对句子进行分析,其中需要过滤掉字母和数字以及各种标点符号,只对汉字进行分词,便于之后的文本向量化
然后,因为我们需要完成的是一个二分类的问题,于是这里将数据集中的中性情感标签和不带标签的句子进行删除,留下正反两种情绪的句子以及标签,处理如下:
|
|
接着,就要实例化dataloader,测试一下输出的数据,不过这里需要注意一个问题,关于自定义一个collate_fn,通过自定义collate_fn,我们才能得到最终我们所需要的效果,自定义collate_fn的函数如下:
最后通过测试我们可以得到需要的结果如下所示


图 2 dataset的数据集准备
2.3.2 文本序列化
在2.2.2中介绍word embedding的时候,我们说过,不会直接把文本转化为向量,而是先转化为数字,再把数字转化为向量,那么这个过程该如何实现呢?
这里我们可以考虑把文本中的每个词语和其对应的数字,使用字典保存,同时实现方法把句子通过字典映射为包含数字的列表。
实现文本序列化之前,考虑以下几点:
1. 如何使用字典把词语和数字进行对应
2. 不同的词语出现的次数不尽相同,是否需要对高频或者低频词语进行过滤,以及总的词语数量是否需要进行限制
3. 得到词典之后,如何把句子转化为数字序列,如何把数字序列转化为句子
4. 不同句子长度不相同,每个batch的句子如何构造成相同的长度(可以对短句子进行填充,填充特殊字符)
5. 对于新出现的词语在词典中没有出现怎么办(可以使用特殊字符代理)
思路分析:
1. 对所有句子进行分词
2. 词语存入字典,根据次数对词语进行过滤,并统计次数
3. 实现文本转数字序列的方法
4. 实现数字序列转文本方法
其中分词,在2.3.1中token函数已经实现,接着就是要实现剩下的几个方法,如下所示:
|
i. 词语存入字典,根据次数对词语进行过滤,并统计次数
|
ii. 实现文本转数字序列的方法
|
iii. 实现数字序列转文本方法
最后我们自定义一段文字来测试,文本序列化的效果如下:

图 3 文本序列化测试结果
其中88对应“我”,1197对应“爱”,其余的“UNK”和“PAD”作为填充数据,来填充词典的长度,从而使得文本进行向量化计算。
三、模型的构建
3.1 LSTM的介绍
假如现在有这样一个需求,根据现有文本预测下一个词语,比如天上的云朵漂浮在__,通过间隔不远的位置就可以预测出来词语是天上,但是对于其他一些句子,可能需要被预测的词语在前100个词语之前,那么此时由于间隔非常大,随着间隔的增加可能会导致真实的预测值对结果的影响变的非常小,而无法非常好的进行预测(RNN中的长期依赖问题(long-Term Dependencies))那么为了解决这个问题需要LSTM(Long Short-Term Memory网络)。LSTM是一种RNN特殊的类型,可以学习长期依赖信息。在很多问题上,LSTM都取得相当巨大的成功,并得到了广泛的应用。一个LSMT的单元就是下图中的一个绿色方框中的内容:
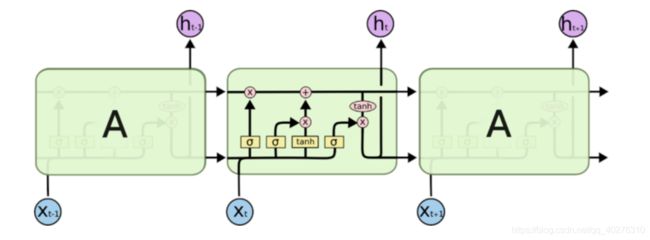
图 4 LSTM单元
LSTM的核心在于单元(细胞)中的状态,也就是上图中最上面的那根线。但是如果只有上面那一条线,那么没有办法实现信息的增加或者删除,所以在LSTM是通过一个叫做`门`的结构实现,门可以选择让信息通过或者不通过。
在理解LSTM时,我们需要理解遗忘门,输入门以及输出门的相关概念以及公式的说明和推导。
·遗忘门
遗忘门通过sigmoid函数来决定哪些信息会被遗忘在下图就是和进行合并(concat)之后乘上权重和偏置,通过sigmoid函数,输出0-1之间的一个值,这个值会和前一次的细胞状态()进行点乘,从而决定遗忘或者保留。
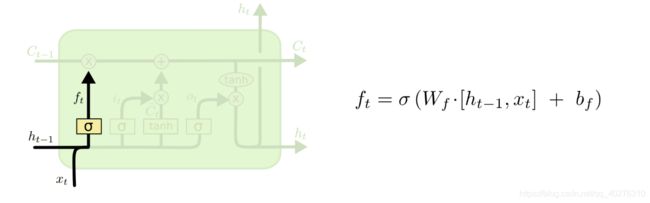
图 5 遗忘门
·输入门
下一步就是决定哪些新的信息会被保留,这个过程有两步:
1. 一个被称为`输入门`的sigmoid 层决定哪些信息会被更新
2. `tanh`会创造一个新的候选向量$\widetilde{C}_{t}$,后续可能会被添加到细胞状态中
例如:
`我昨天吃了苹果,今天我想吃菠萝`,在这个句子中,通过遗忘门可以遗忘`苹果`,同时更新新的主语为`菠萝`
现在就可以更新旧的细胞状态C_t-1新的C_t了。更新的构成简单说就是:
1. 旧的细胞状态和遗忘门的结果相乘
2. 然后加上 输入门和tanh相乘的结果
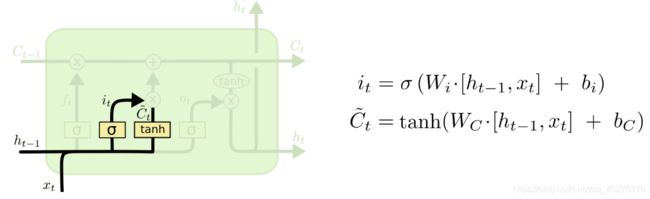
图 6 输入门1
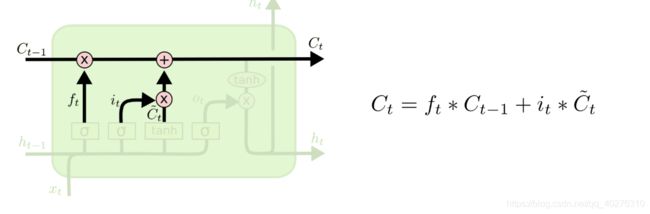
图 7 输入门2
·输出门
最后,我们需要决定什么信息会被输出,也是一样这个输出经过变换之后会通过sigmoid函数的结果来决定那些细胞状态会被输出。步骤如下:
1. 前一次的输出和当前时间步的输入的组合结果通过sigmoid函数进行处理得到O_t
2. 更新后的细胞状态C_t会经过tanh层的处理,把数据转化到(-1,1)的区间
3. tanh处理后的结果和O_t进行相乘,把结果输出同时传到下一个LSTM的单元
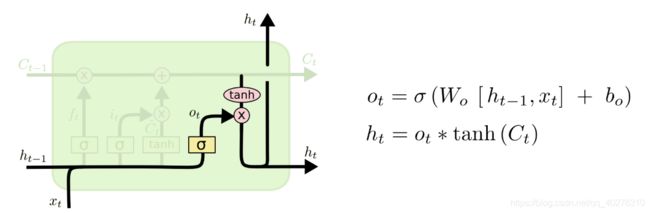
图 8 输出门
在本文中,采用的是双向的LSTM结构,因为单向的 RNN,是根据前面的信息推出后面的,但有时候只看前面的词是不够的,可能需要预测的词语和后面的内容也相关,那么此时需要一种机制,能够让模型不仅能够从前往后的具有记忆,还需要从后往前需要记忆。此时双向LSTM就可以帮助我们解决这个问题。
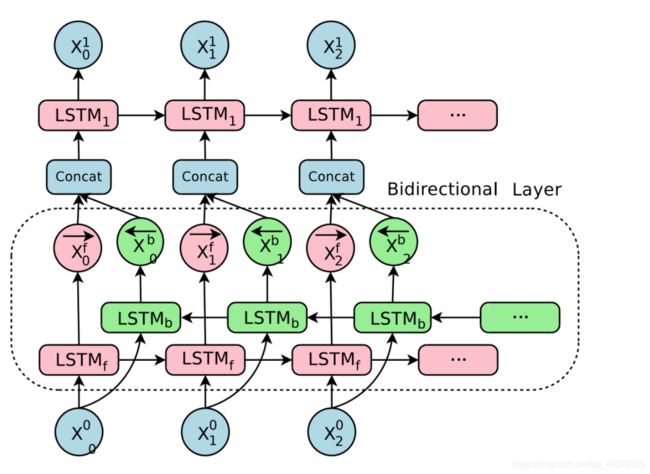
图 9 双向LSTM结构
3.2 Bi-LSTM+embedding+logsoftmax模型构建
在本文中采用Bi-LSTM+embedding+logsoftmax的结构来构建情感分类的模型处理,代码如下所示:
|
|
四、模型训练与评估
|
模型的训练函数如下所示:
模型的评估结果是以准确率的均值来判断模型对于分类结果的好坏,评估的结果如下图所示:

图 10 三次训练评估结果
五、小结与反思
在本次的情感分析的评测实战中,刚开始是碍于所选参考资料是用Keras完成,于是想偷懒自己移植到pytorch上来直接套用,但是发现对于整个模型的输出输出以及过程的不理解,发现这样根本不行,于是又找了一个基于pytorch的LSTM情感分析的实战课,但是因为数据集是英文的数据集,而且文本处理的方式也不太一样,于是在这里又卡住了,但是经过一晚上的通宵奋战,将书和视频吃透之后发现,英文与中文文本的处理都是殊途同归,最后都是要是的文本序列化,便于进行计算。所以一晚上将中文文本处理完之后,后面直接使用api进行模型的构建与训练就显得十分轻松了。
不过,此次任务中值得反思的是,因为还是贪图方便,就直接将这个三分类的问题当做二分类的问题来做,所以尽管在某种层度上说是熟悉了模型,但是实际上评测的任务也还是没有完成,所以需要就这个评测任务进一步进行学习和完善,比如换成GRU,或者textCNN。
最后,借上周战略管理课上讲的,任何事情只要投入,总会得到意想不到的结果,对于一个较难的任务,要实现短期收益,就是短时间投入加上目标分解。
参考文献
- SMP - ECISA “拓尔思杯”中文隐式情感分析评测 2019
https://www.biendata.xyz/competition/smpecisa2019/data/ 2019.07.15
- 黑马Python就业班15期.