2021-02-08/09 大数据课程笔记 day19day20 某大型网站日志分析离线系统

@R星校长
某大型网站日志分析离线系统
项目需求分析
概述
该部分的主要目标就是描述本次项目最终七个分析模块的界面展示。
工作流
在我们的 demo 展示中,我们使用 jquery+echarts 的方式调用程序后台提供的 rest api 接口,获取 json 数据,然后通过 jquery+css 的方式进行数据展示。工作流程如下:
分析
总述
在本次项目中我们分别从七个大的角度来进行分析,分别为:
用户基本信息分析模块
浏览器信息分析模块
地域信息分析模块
用户浏览深度分析模块
外链数据分析模块
订单分析模块
事件分析模块
下面就每个模块进行最终展示的分析。
注意几个概念:
- 用户/访客:表示同一个浏览器代表的用户。唯一标示用户
- 会员:表示网站的一个正常的会员用户。
- 会话:一段时间内的连续操作,就是一个会话中的所有操作。
- PV:访问页面的数量 pageview
- 在本次项目中,所有的计数都是去重过的。比如:活跃用户/访客,计算 uuid 的去重后的个数。
用户基本信息分析模块
用户基本信息分析模块主要是从用户/访客和会员两个主要角度分析浏览相关信息,包括但不限于新增用户,活跃用户,总用户,新增会员,活跃会员,总会员以及会话分析等。下面就各个不同的用户信息角度来进行分析:
用户分析
该分析主要分析新增用户、活跃用户以及总用户的相关信息。
新访客:老访客(活跃访客中) = 1:7~10
活跃用户,是相对于“流失用户”的一个概念,是指那些会时不时地光顾下网站,并为网站带来一些价值的用户。
简单理解就是经常访问该网站的用户,如浏览商品了,下单了,收藏了等行为。
新访客数:一天的独立访客中,历史第一次访问您网站的访客数;老访客数:今日之前有过访问,且今日再次访问的访客,记为老访客。
会员分析
该分析主要分析新增会员、活跃会员以及总会员的相关信息。
会话分析
该分析主要分析会话个数、会话长度和平均会话长度相关的信息。
Hourly分析
该分析主要分析每天每小时的用户、会话个数以及会话长度的相关信息。
浏览器信息分析模块
在用户基本信息分析的基础上添加一个浏览器这个维度信息。
浏览器用户分析
同用户分析。
浏览器会员分析
同会员分析。
浏览器会话分析
同会话分析。
浏览器 PV 分析
分析各个浏览器的 pv 值。
地域信息分析模块
主要分析各个不同省份的用户和会员情况。
活跃访客地域分析
分析各个不同地域的活跃访客数量。
跳出率分析
分析各个不同地域的跳出率情况。
一个网站在某一段时间内有 1000 不同访客从这个链接进入,同时这些访客中有 50 个人没有二次浏览行为,直接退出网站,那么针对这个入口网址的跳出率就是 50/1000=5%。
用户访问深度分析模块
该模块主要分析用户的访问记录的深度,用户在一个会话中访问页面的数量。
网站访问深度就是用户在一次浏览你的网站的过程中浏览了你的网站的页数。如果用户一次性的浏览了你的网站的页数越多,那么就基本上可以认定,你的网站有他感兴趣的东西。用户访问网站的深度用数据可以理解为网站平均访问的页面数,就是 PV 和 uv 的比值,这个比值越大,用户体验度越好,网站的粘性也越高。
此处 UV 可以理解为 cookie 中的 UUID 数量。
外链数据分析模块
主要分析各个不同外链端带来的用户访问量数据。
外链就是指在别的网站导入自己网站的链接。导入链接对于网站优化来说是非常重要的一个过程。导入链接的质量(即导入链接所在页面的权重)间接影响了我们的网站在搜索引擎中的权重。
意义在于要不要做这个外链推广。
外链偏好分析
分析各个外链带来的活跃访客数量。
外链会话(跳出率)分析
分析会话相关信息,并计算相关会话跳出率的情况。
订单数据分析模块
主要分析订单的相关情况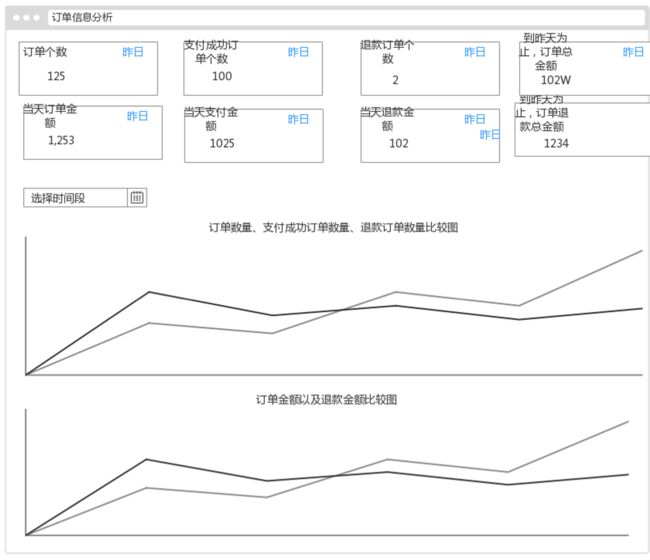
事件分析模块
在本次项目中,只选用一个事件案例进行分析,就是订单相关的一个事件分析。
预留模块。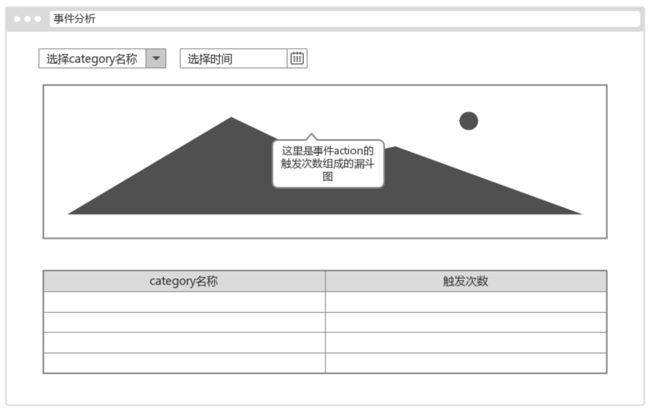
系统架构: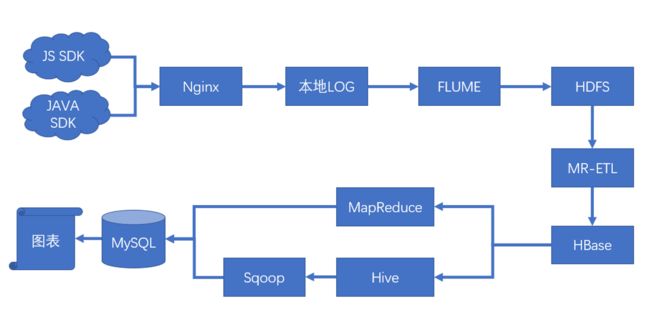
虚拟机分配:
| node1 | hadoop,hbase,mysql-server,nginx,flume |
|---|---|
| node2 | hadoop,hbase,zookeeper,hiveserver2 |
| node3 | hadoop,hbase,zookeeper,hiveserver2,sqoop, |
| node4 | hadoop,hbase,zookeeper,beeline |
JS SDK
概述
该文档的主要作用是为了开发人员参考可以参考本文档,了解 js sdk 的集成方式以及提供的各种不同的 api。
注意:不采用 ip 来标示用户的唯一性,我们通过在 cookie 中填充一个 uuid 来标示用户的唯一性。
埋点:
初级埋点:在产品流程关键部位植相关统计代码,用来追踪每次用户的行为,统计关键流程的使用程度。
中级埋点:植入多段动作代码,追踪用户在该模块每个界面上的系列行为,事件之间相互独立
高级埋点:联合公司工程、ETL 采集分析用户全量行为,建立用户画像,还原用户行为模型,作为产品分析、优化的基础。
Js sdk 执行工作流
在我们的 js sdk 中按照收集数据的不同分为不同的事件,比如 pageview 事件等。Js sdk 的执行流程如下: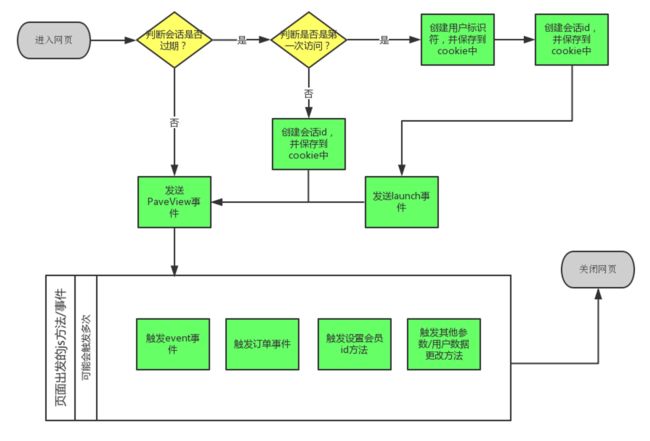
数据参数说明
在各个不同事件中收集不同的数据发送到 nginx 服务器,但是实际上这些收集到的数据还是有一些共性的。下面将所用可能用到的参数描述如下:
| 参数名称 | 类型 | 描述 |
|---|---|---|
| en | string | 事件名称, eg: e_pv |
| ver | string | 版本号, eg: 0.0.1 |
| pl | string | 平台, eg: website,iso,android |
| sdk | string | Sdk类型, eg: js java |
| b_rst | string | 浏览器分辨率,eg: 1800*678 |
| b_iev | string | 浏览器信息useragent 火狐控制台输入:window.navigator.userAgent"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:76.0) Gecko/20100101 Firefox/76.0" |
| u_ud | string | 用户/访客唯一标识符 |
| l | string | 客户端语言 |
| u_mid | string | 会员id,和业务系统一致 |
| u_sd | string | 会话id |
| c_time | string | 客户端时间 |
| p_url | string | 当前页面的url |
| p_ref | string | 上一个页面的url |
| tt | string | 当前页面的标题 |
| ca | string | Event事件的Category名称 |
| ac | string | Event事件的action名称 |
| kv_* | string | Event事件的自定义属性 |
| du | string | Event事件的持续时间 |
| oid | string | 订单id |
| on | string | 订单名称 |
| cua | string | 支付金额 |
| cut | string | 支付货币类型 |
| pt | string | 支付方式 |
PC 端事件分析
针对我们最终的不同分析模块,我们需要不同的数据,接下来分别从各个模块分析,每个模块需要的数据。
用户基本信息就是用户的浏览行为信息分析,也就是我们只需要 pageview 事件就可以了;
浏览器信息分析以及地域信息分析其实就是在用户基本信息分析的基础上添加浏览器和地域这个维度信息,其中浏览器信息我们可以通过浏览器的window.navigator.userAgent来进行分析,
地域信息可以通过 nginx 服务器来收集用户的 ip 地址来进行分析,也就是说 pageview 事件也可以满足这两个模块的分析。
外链数据分析以及用户浏览深度分析我们可以在 pageview 事件中添加访问页面的当前 url 和前一个页面的 url 来进行处理分析,也就是说 pageview 事件也可以满足这两个模块的分析。
订单信息分析要求 pc 端发送一个订单产生的事件,那么对应这个模块的分析,我们需要一个新的事件 chargeRequest。
对于事件分析我们也需要一个 pc 端发送一个新的事件数据,我们可以定义为 event。除此之外,我们还需要设置一个 launch 事件来记录新用户的访问。
pc 端的各种不同事件发送的数据 url 格式如下,其中 url 中后面的参数就是我们收集到的数据:http://bjsxt.com/bjsxt.gif?requestdata

Launch 事件
当用户第一次访问网站的时候触发该事件,不提供对外调用的接口,只实现该事件的数据收集。
Pageview 事件
当用户访问页面/刷新页面的时候触发该事件。该事件会自动调用,也可以让程序员手动调用。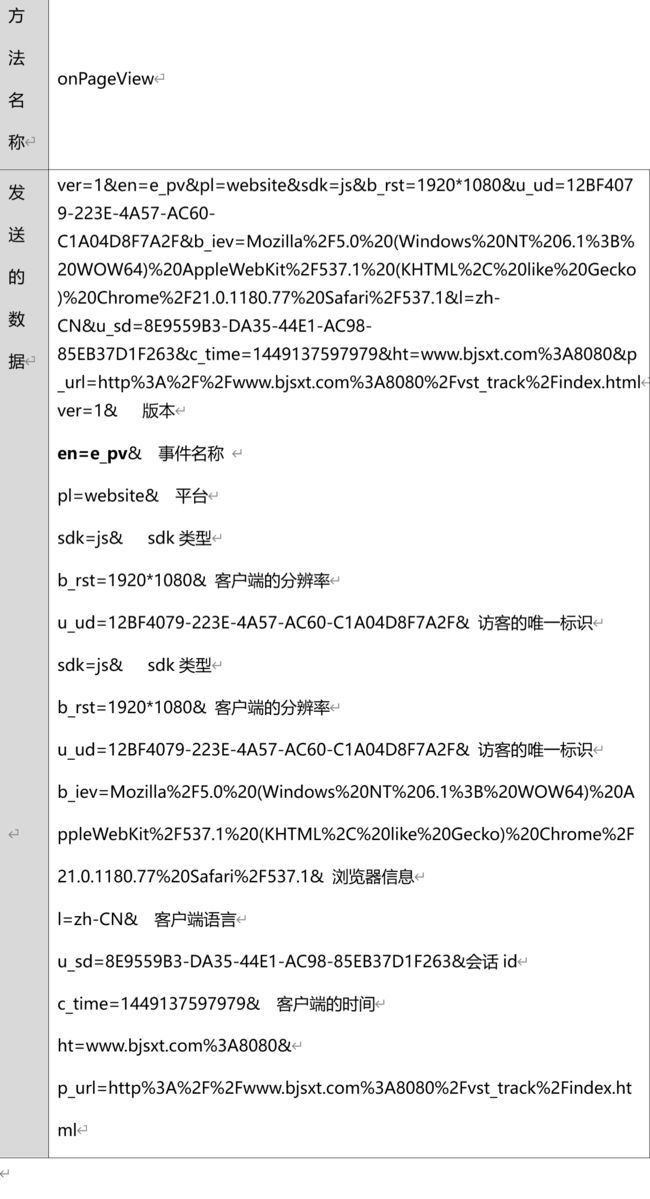
chargeRequest 事件
当用户下订单的时候触发该事件,该事件需要程序主动调用。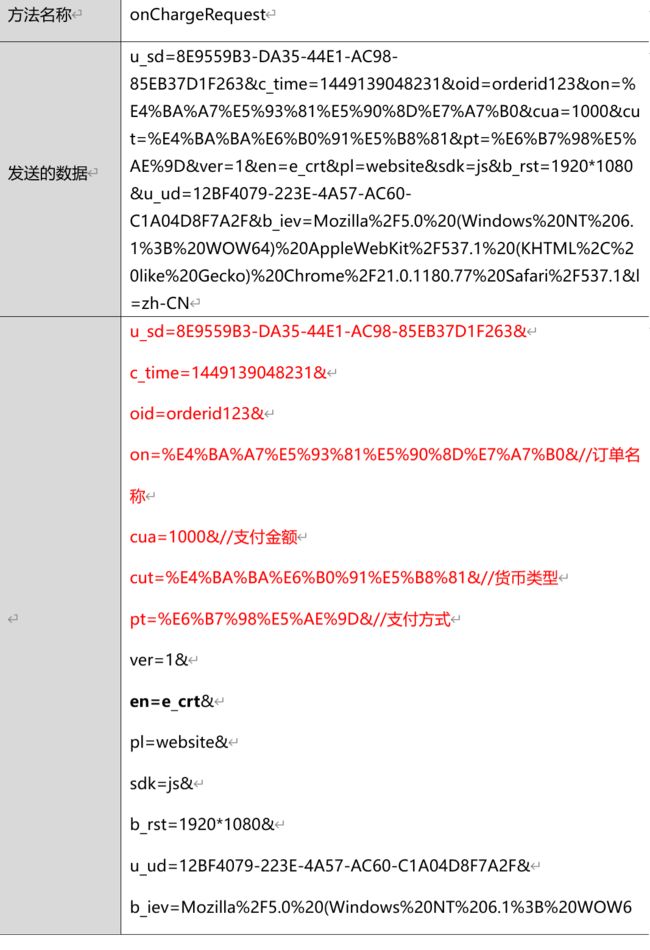

Event 事件
当访客/用户触发业务定义的事件后,前端程序调用该方法。
其他 api 方法
在这里只介绍设置会员 id 的方法,其他的辅助方法到时候编写js的时候再介绍。
设置会员 id
JAVA SDK
概述
该文档的主要作用是为了开发人员参考可以参考本文档,了解 java sdk 的集成方式以及提供的各种不同的方法。注意:由于在本次项目中 java sdk 的作用主要就是发送支付成功/退款成功的信息给 nginx 服务器,所有我们这里提供的是一个简单版本的 java sdk。
Java sdk 执行工作流
订单支付成功的工作流如下所示:(订单退款类似) Controller(比如:servlet)调用该方法

程序后台事件分析
本项目中在程序后台只会触发 chargeSuccess 事件,本事件的主要作用是发送订单成功的信息给 nginx 服务器。发送格式同 pc 端发送方式, 也是访问同一个 url 来进行数据的传输。格式为:
http://bjsxt.com/bjsxt.jpg?requestdata e_crt

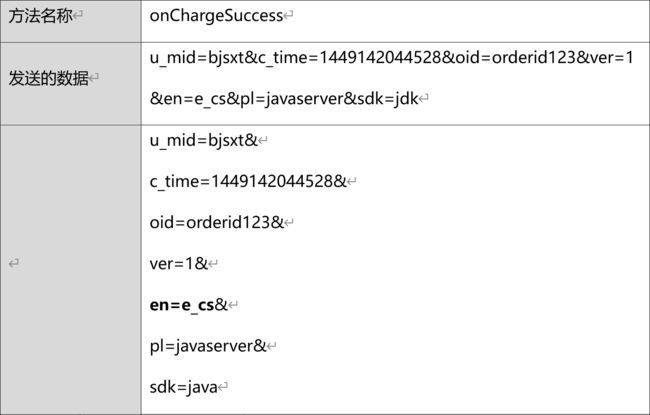
chargeSuccess 事件
当会员最终支付成功的时候触发该事件,该事件需要程序主动调用。
| 参数 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
| orderId | string | 是 | 订单id |
| memberId | string | 是 | 会员id |
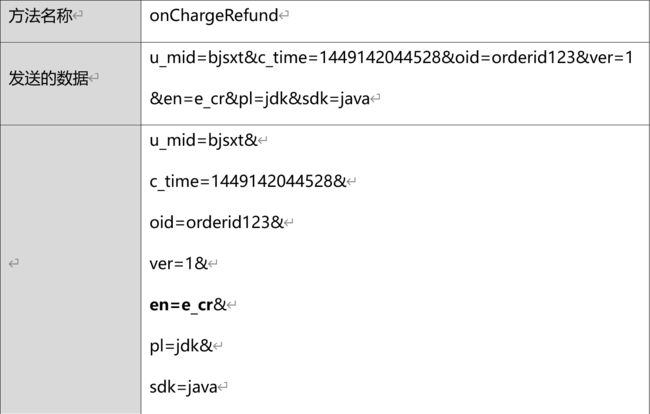
4.3.2 chargeRefund 事件
当会员进行退款操作的时候触发该事件,该事件需要程序主动调用。

集成方式
直接将 java 的 sdk 引入到项目中即可,或者添加到 classpath 中。
数据参数说明
参数描述如下:
| 参数名称 | 类型 | 描述 |
|---|---|---|
| en | string | 事件名称, eg: e_cs |
| ver | string | 版本号, eg: 0.0.1 |
| pl | string | 平台, eg: website,javaweb,php |
| sdk | string | Sdk类型, eg: java,js |
| u_mid | string | 会员id,和业务系统一致 |
| c_time | string | 客户端时间 |
| oid | string | 订单id |
数据来源设计
项目搭建
- 新建一个空项目:

输入项目名称:
创建Module:
选择 JavaEE 版本:

File->Project Stucture->Modules-> + ->Web
- 解压:
big_data_log2.zip,并将对应的内容拷贝到刚刚创建的 Module 中
A. 将 com 包拷贝到 src 目录下。
B. 向将 web 目录下内容清空,然后将提供代码的 web 目录下的所有内容拷贝到 web 目录下。
C. 选择 lib 文件夹,右键 Add as Library…
D. 最终效果入右图所示:
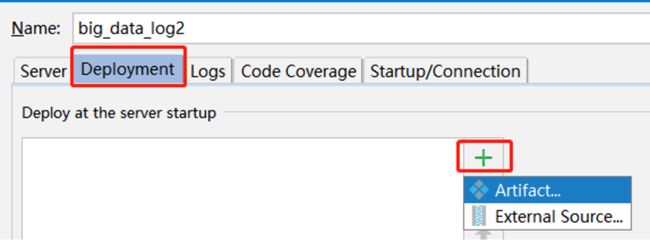
配置 tomcat
- 将
apache-tomcat-7.0.69.zip解压到 D:\devsoft - 配置 tomcat




- 启动项目

代码分析
(function(){…})()
先看js/analytics.js,很可能(function(){....})()看不懂,接下来先讲解它:
- 创建 my.js,在 index.jsp 中通过 script 标签引入:
<script type="text/javascript" src="./js/my.js"></script>
- 编辑 my.js
function load() {
alert("hello js");
}
load();
(function load2() {
alert("hello js load2");
})();
(function() {
alert("hello js function no name");
})();
三种方式逐步递进,演示后面的时候,需要将前面的内容注释掉。
- 然后阅读 analytics.js 的 CookieUtil ,编写代码学习:
将 my.js 的其它代码都注释掉,并添加以下代码:
(function() {
var myJson={
name:"zhangsan",
age:25,
say:function () {
alert("大家好,我是"+this.name+",我今年"+this.age+"岁了");
}
};
//打印myJson的name属性
alert(myJson.name);
//调用闭包
myJson.say();
})();
然后测试。CookieUtil 具体的代码先不用研究。
4. var tracker 分析
columns : {
// 发送到服务器的列名称
eventName : "en",//事件名称, eg: e_pv
version : "ver",//版本号, eg: 0.0.1
platform : "pl",//平台, eg: website,iso,android
sdk : "sdk",//Sdk类型, eg: js java
uuid : "u_ud",//浏览器分辨率,eg: 1800*678
memberId : "u_mid",//会员id,和业务系统一致
sessionId : "u_sd",//会话id
clientTime : "c_time",//客户端时间
language : "l",//客户端语言
userAgent : "b_iev",//浏览器信息useragent
resolution : "b_rst",//浏览器分辨率,eg: 1800*678
currentUrl : "p_url",//当前页面的url
referrerUrl : "p_ref",//上一个页面的url
title : "tt",//当前页面的标题
orderId : "oid",//订单id
orderName : "on",//订单名称
currencyAmount : "cua",//支付金额
currencyType : "cut",//支付货币类型
paymentType : "pt",//支付方式
category : "ca",//Event事件的Category名称
action : "ac",//Event事件的action名称
kv : "kv_",//Event事件的自定义属性
duration : "du"//Event事件的持续时间
},
- window.AE
- autoLoad()阅读相关的代码,onLaunch事件、onPageView事件会自动触发。
- onChargeRequest事件在demo2.jsp中点击按钮触发
- onEventDuration事件在demo3.jsp中点击按钮触发
Java代码分析
AnalyticsEngineSDK、SendDataMonitor 看明白之后,运行 Test 类看控制台信息。
nginx 本地存储日志
安装 nginx 或者 tengine
- 安装依赖
gcc openssl-devel pcre-devel zlib-devel
安装:yum install gcc openssl-devel pcre-devel zlib-devel -y - 上传与解压
- 配置 Nginx
./configure - 编译与安装
make && make install
默认安装目录:
/usr/local/nginx
配置 nginx 的 init 启动服务
- 在/etc/init.d/目录新建nginx,编辑如下内容:
[root@node1 tengine-2.1.0]# cd /etc/init.d/
[root@node1 init.d]# vim nginx
#!/bin/bash
#
# nginx - this script starts and stops the nginx daemon
#
# chkconfig: - 85 15
# description: Nginx is an HTTP(S) server, HTTP(S) reverse \
# proxy and IMAP/POP3 proxy server
# processname: nginx
# config: /etc/nginx/nginx.conf
# config: /etc/sysconfig/nginx
# pidfile: /var/run/nginx.pid
# Source function library.
. /etc/rc.d/init.d/functions
# Source networking configuration.
. /etc/sysconfig/network
# Check that networking is up.
[ "$NETWORKING" = "no" ] && exit 0
nginx="/usr/local/nginx/sbin/nginx"
prog=$(basename $nginx)
NGINX_CONF_FILE="/usr/local/nginx/conf/nginx.conf"
[ -f /etc/sysconfig/nginx ] && . /etc/sysconfig/nginx
lockfile=/var/lock/subsys/nginx
make_dirs() {
# make required directories
user=`nginx -V 2>&1 | grep "configure arguments:" | sed 's/[^*]*--user=\([^ ]*\).*/\1/g' -`
options=`$nginx -V 2>&1 | grep 'configure arguments:'`
for opt in $options; do
if [ `echo $opt | grep '.*-temp-path'` ]; then
value=`echo $opt | cut -d "=" -f 2`
if [ ! -d "$value" ]; then
# echo "creating" $value
mkdir -p $value && chown -R $user $value
fi
fi
done
}
start() {
[ -x $nginx ] || exit 5
[ -f $NGINX_CONF_FILE ] || exit 6
make_dirs
echo -n $"Starting $prog: "
daemon $nginx -c $NGINX_CONF_FILE
retval=$?
echo
[ $retval -eq 0 ] && touch $lockfile
return $retval
}
stop() {
echo -n $"Stopping $prog: "
killproc $prog -QUIT
retval=$?
echo
[ $retval -eq 0 ] && rm -f $lockfile
return $retval
}
restart() {
configtest || return $?
stop
sleep 1
start
}
reload() {
configtest || return $?
echo -n $"Reloading $prog: "
killproc $nginx -HUP
RETVAL=$?
echo
}
force_reload() {
restart
}
configtest() {
$nginx -t -c $NGINX_CONF_FILE
}
rh_status() {
status $prog
}
rh_status_q() {
rh_status >/dev/null 2>&1
}
case "$1" in
start)
rh_status_q && exit 0
$1
;;
stop)
rh_status_q || exit 0
$1
;;
restart|configtest)
$1
;;
reload)
rh_status_q || exit 7
$1
;;
force-reload)
force_reload
;;
status)
rh_status
;;
condrestart|try-restart)
rh_status_q || exit 0
;;
*)
echo $"Usage: $0 {start|stop|status|restart|condrestart|try-restart|reload|force-reload|configtest}"
exit 2
esac
- 并赋予可执行权限:
[root@node1 init.d]# chmod +x nginx
- 添加该文件到系统服务中去
[root@node1 init.d]# chkconfig --add nginx
- 查看是否添加成功
[root@node1 init.d]# chkconfig --list nginx
- 启动,停止,重新装载
service nginx start|stop|restart
- 设置开机启动 nginx
[root@node1 init.d]# chkconfig nginx on
- 测试,打开浏览器,输入:http://192.168.20.71/ 出现 tengine 欢迎页面表示安装配置成功
日志定义
查看默认记录的日志
[root@node1 init.d]# whereis nginx
nginx: /usr/local/nginx
[root@node1 init.d]# cd /usr/local/nginx/
[root@node1 nginx]# ls
client_body_temp html modules scgi_temp
conf include proxy_temp uwsgi_temp
fastcgi_temp logs sbin
[root@node1 nginx]# ls logs/
access.log error.log nginx.pid
[root@node1 nginx]# cd logs/
[root@node1 logs]# pwd
/usr/local/nginx/logs
[root@node1 logs]# tail -f access.log
192.168.20.1 - - [15/May/2020:22:48:32 +0800] "GET / HTTP/1.1" 200 555 "-" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36"
配置 tengine 的日志格式
官方文档地址:
http://tengine.taobao.org/nginx_docs/cn/docs/http/ngx_http_log_module.html
http://tengine.taobao.org/nginx_docs/cn/docs/http/ngx_http_core_module.html#variables
http_host 显示服务器所在的地址
编辑 nginx.conf 文件:
[root@node1 conf]# pwd
/usr/local/nginx/conf
[root@node1 conf]# vim nginx.conf
log_format my_format '$remote_addr^A$msec^A$http_host^A$request_uri';
#http://node1/log.gif?fdsafdsa
location /log.gif {
default_type image/gif;
access_log /opt/data/access.log my_format;
}
重启加载 nginx
[root@node1 conf]# service nginx reload
the configuration file /usr/local/nginx/conf/nginx.conf syntax is ok
configuration file /usr/local/nginx/conf/nginx.conf test is successful
Reloading nginx: 【ok】
测试
- 查看新指定的日志目录和日志文件是否新建成功
[root@node1 conf]# cd /opt/
[root@node1 opt]# ls
apps data hadoop-2.6.5 hbase-0.98
[root@node1 opt]# cd data/
[root@node1 data]# ls
access.log
- 测试日志是否记录:
http://node1/log.gif
404 解决办法,在/usr/local/nginx/html目录下上传一张 log.gif 图片:
[root@node1 html]# pwd
/usr/local/nginx/html
[root@node1 html]# ls
50x.html index.html log.gif
[root@node1 data]# tail -f access.log
192.168.20.1^A1589556277.121^Anode1^A/log.gif
- 测试日志是否记录:
http://localhost:8080/demo2.jsp
访问页面发现日志没有记录,修改analytics.js: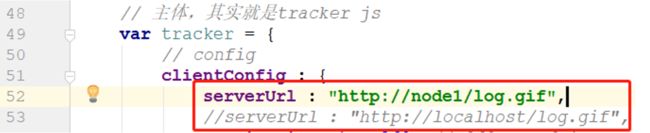
- 查看日志信息是否完成:
192.168.20.1^A1589557481.745^Anode1^A/log.gif?en=e_pv&p_url=http%3A%2F%2Flocalhost%3A8080%2Fdemo4.jsp&p_ref=http%3A%2F%2Flocalhost%3A8080%2Fdemo2.jsp&tt=%E6%B5%8B%E8%AF%95%E9%A1%B5%E9%9D%A24&ver=1&pl=%E5%A4%A7234470100&sdk=js&u_ud=46D00DCD-187C-4BA8-8014-358F8DE85474&u_mid=zhangsan&u_sd=E96DC9DE-2590-4E95-B6C3-3E74BCFD88EF&c_time=1589557480505&l=zh-CN&b_iev=Mozilla%2F5.0%20(Windows%20NT%2010.0%3B%20Win64%3B%20x64%3B%20rv%3A76.0)%20Gecko%2F20100101%20Firefox%2F76.0&b_rst=1920*1080
- Java 测试
运行\com\sxt\log\test\Test.java,查看日志文件,能够记录下来。
Flume 读取 nginx 的本地 log
Flume概述:
介绍
官网地址:http://flume.apache.org
本课程选择版本对应的官方文档:
http://flume.apache.org/releases/content/1.6.0/FlumeUserGuide.html
官方介绍:
- Apache Flume 是一个分布式、可靠和可用的系统,用于有效地收集、聚合和将大量日志数据从许多不同的来源转移到集中式数据存储。
- Apache Flume 的使用不仅限于日志数据聚合。 由于数据源是可定制的,Flume可以用来传输大量的事件数据,包括但不限于网络流量数据、社交媒体生成的数据、电子邮件消息和几乎任何可能的数据源。
- Apache Flume 是 Apache 软件基金会的顶级项目。
系统需求
java 环境 - java 1.6 或更高版本(推荐 Java 1.7)
内存 - sources、channels 和 sinks 所用的足够的内存
磁盘空间 - channels 和 sinks 用到的足够的磁盘空间
目录权限 - flume 的 agent 用到的目录读写权限
Data flow model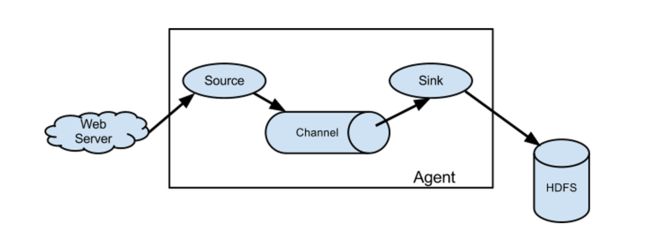
安装与配置
- 上传
apache-flume-1.6.0-bin.tar.gz到node1/opt/apps目录下 - 解压并重命名
[root@node1 apps]# tar -zxvf apache-flume-1.6.0-bin.tar.gz -C /opt/
[root@node1 apps]# cd /opt
[root@node1 opt]# mv apache-flume-1.6.0-bin/ flume
- 删除 docs 目录
[root@node1 opt]# ls
apps data flume hadoop-2.6.5 hbase-0.98
[root@node1 opt]# cd flume/
[root@node1 flume]# ls
bin CHANGELOG conf DEVNOTES docs lib LICENSE NOTICE README RELEASE-NOTES tools
[root@node1 flume]# rm -rf docs/
- 修改配置
[root@node1 conf]# mv flume-env.sh.template flume-env.sh
[root@node1 conf]# vim flume-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_221-amd64
- 配置 flume 环境变量,并让配置文件生效
[root@node1 ~]# vim /etc/profile
export FLUME_HOME=/opt/flume
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$FLUME_HOME/bin
[root@node1 ~]# source /etc/profile
- 验证安装是否成功
[root@node1 ~]# flume-ng version
Flume 1.6.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: 2561a23240a71ba20bf288c7c2cda88f443c2080
Compiled by hshreedharan on Mon May 11 11:15:44 PDT 2015
From source with checksum b29e416802ce9ece3269d34233baf43f
- A simple example
在这里,我们给出一个示例配置文件,描述一个单节点Flume部署。 此配置允许用户生成事件并随后将其记录到控制台。
[root@node1 ~]# vim option.properties
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = node1
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory #内存
a1.channels.c1.capacity = 1000 #容量1000条
a1.channels.c1.transactionCapacity = 100 #每次传输100条
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 #将source和channel连接
a1.sinks.k1.channel = c1 #量sink和channel连接
配置时不带中文注释。
- 查看帮助
[root@node1 conf]# flume-ng help
Usage: /opt/flume/bin/flume-ng <command> [options]...
-Dproperty=value sets a Java system property value指定java的系统属性值
-Xproperty=value sets a Java -X option
agent options:
--name,-n <name> the name of this agent (required)指定代理的名称
--conf-file,-f <file> specify a config file (required if -z missing)如果不指定-z选项,则必须指定配置文件
--zkConnString,-z <str> specify the ZooKeeper connection to use
- 启动
[root@node1 ~]#flume-ng agent -n a1 --conf-file option.properties -Dflume.root.logger=INFO,console

测试
- 打开一个连接 node2 的 xshell 终端,安装 telnet
[root@node2 ~]# yum install telnet -y
[root@node2 ~]# telnet node1 44444
Trying 192.168.20.71...
Connected to node1.
Escape character is '^]'.
OK
A
hello gtjin
OK
- 查看 node1 的变化
20/05/16 16:12:22 INFO sink.LoggerSink: Event: {
headers:{
} body: 41 0D A. }
20/05/16 16:02:23 INFO sink.LoggerSink: Event: {
headers:{
} body: 68 65 6C 6C 6F 20 67 74 6A 69 6E 0D hello gtjin. }
Setting multi-agent flow串联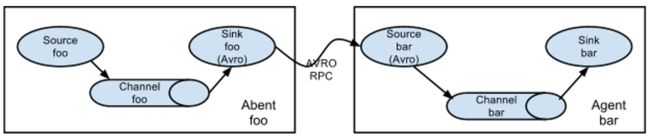
- Ctrl+c 关闭 node1 的 flume,并将安装包远程拷贝到 node3
[root@node1 ~]# cd /opt/
[root@node1 opt]# ls
apps data flume hadoop-2.6.5 hbase-0.98
[root@node1 opt]# scp -r flume/ node3:/opt/
- node3 上配置环境变量
[root@node3 ~]# vim /etc/profile
export FLUME_HOME=/opt/flume
export
PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$HBASE_HOME/bin:$FLUME_HOME/bin
[root@node3 ~]# source /etc/profile
- 将 node1 上配置文件 option.properties 拷贝一份 option1.properties ,并修改:
参考参数:
http://flume.apache.org/releases/content/1.6.0/FlumeUserGuide.html#avro-sink
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = node1
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node3
a1.sinks.k1.port = 10086
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 将 node1 上的 option.properties 拷贝到 node3 上,并修改
参考官网:
http://flume.apache.org/releases/content/1.6.0/FlumeUserGuide.html#avro-source
node1上操作
[root@node1 ~]# scp option.properties node3:/root
option.properties 100% 541 0.5KB/s 00:00
node3 上操作
[root@node3 ~]# mv option.properties option3.properties
[root@node3 ~]# vim option3.properties
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.bind = node3
a1.sources.r1.port = 10086
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 启动 node3 上的 flume (由于 node1 发送给 node3 所以先启动 node3)
flume-ng agent -n a1 --conf-file option3.properties -Dflume.root.logger=INFO,console
再复制一个 xshell 终端:
[root@node3 ~]# ss -nal
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 :::22 :::*
LISTEN 0 128 *:22 *:*
LISTEN 0 100 ::1:25 :::*
LISTEN 0 100 127.0.0.1:25 *:*
LISTEN 0 50 ::ffff:192.168.20.73:10086 :::*
- 启动 node1 上的 flume
flume-ng agent -n a1 --conf-file option1.properties -Dflume.root.logger=INFO,console
- Node2 上发消息给 node1
[root@node2 ~]# telnet node1 44444
Trying 192.168.20.71...
Connected to node1.
Escape character is '^]'.
a
OK
b
OK
c
OK
- Node1 上没有显示信息,而是 node3 上显示信息,这是因为 node1 接收到消息后,传递给了 node3
20/05/16 18:41:01 INFO sink.LoggerSink: Event: {
headers:{
} body: 61 0D a. }
20/05/16 18:41:01 INFO sink.LoggerSink: Event: {
headers:{
} body: 62 0D b. }
20/05/16 18:41:01 INFO sink.LoggerSink: Event: {
headers:{
} body: 63 0D c. }
- 为什么需要串联呢?
日志收集中一个非常常见的场景是大量的日志生成客户端向连接到存储子系统的几个消费代理发送数据。 例如,从数百个 Web 服务器收集的日志发送给十几个写入 HDFS 集群的代理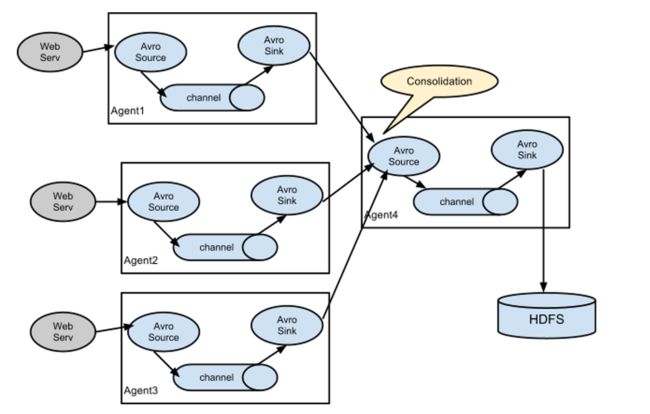
Flume 支持将事件流复用到一个或多个目的地。 这是通过定义一个可以复制或选择性地将事件路由到一个或多个通道的流复用器来实现的
source 种类
- Avro Source
- Thrift Source
- Exec Source
- Spooling Directory Source
- Kafka Source
- NetCat Source
exec source 案例
Exec source runs a given Unix command on start-up and expects that process to continuously produce data on standard out (stderr is simply discarded, unless property logStdErr is set to true). If the process exits for any reason, the source also exits and will produce no further data. This means configurations such as cat [named pipe] or tail -F [file] are going to produce the desired results where as datewill probably not - the former two commands produce streams of data where as the latter produces a single event and exits.
Exec source 在启动时运行给定的 Unix 命令,并期望该进程继续在标准输出上生成数据(stderr 被简单地丢弃,除非属性日志 Std Err 设置为 true)。 如果进程出于任何原因退出,源也将退出,不会产生进一步的数据。 这意味着配置,如 cat[命名管道] 或 tail-F[文件] 将产生所需的结果,其中 as date 可能不会-前两个命令产生数据流,其中后者产生单个事件并退出。
Example for agent named a1:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /var/log/secure
a1.sources.r1.channels = c1
具体实现步骤:
- 先停掉 node1 和 node3 上的 flume
- 将 node1 上的 option.properties 拷贝 option_exec.properties ,并修改:
[root@node1 ~]# cp option.properties option_exec.properties
[root@node1 ~]# vim option_exec.properties
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/log.txt
# Describe the sink
- 启动 node1 上的 flume
flume-ng agent -n a1 --conf-file option_exec.properties -Dflume.root.logger=INFO,console
- 复制一个 node1 连接的 xshell 终端
[root@node1 ~]# echo "hello bjsxt" >> log.txt
[root@node1 ~]# echo "hello" >> log.txt
- 然后在启动 flume 的终端中查看信息
20/05/16 21:29:37 INFO sink.LoggerSink: Event: {
headers:{
} body: 68 65 6C 6C 6F 20 62 6A 73 78 74 hello bjsxt }
20/05/16 21:29:59 INFO sink.LoggerSink: Event: {
headers:{
} body: 68 65 6C 6C 6F hello }
Spooling Directory Source 案例
此源可以通过将要摄取的文件放入磁盘上的“假脱机”目录中来摄取数据。 此源将监视新文件的指定目录,并将在出现新文件时从新文件中解析事件。 事件解析逻辑可插拔… 在一个给定的文件被完全读入通道后,它被重命名以指示完成(或可选地删除)
Example for an agent named agent-1:
a1.channels = ch-1
a1.sources = src-1
a1.sources.src-1.type = spooldir
a1.sources.src-1.channels = ch-1
a1.sources.src-1.spoolDir = /var/log/apache/flumeSpool
a1.sources.src-1.fileHeader = true
fileHeader 值为 true 表示显示信息从哪个文件中读取的,false 不显示。
具体配置步骤:
- 先停掉node1上的flume(ctrl+c)
- 将node1上的
option.properties拷贝option_sdir.properties,并修改:
[root@node1 ~]# cp option.properties option_sdir.properties
[root@node1 ~]# vim option_sdir.properties
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/log
a1.sources.r1.fileHeader = true
# Describe the sink
- 启动 node1 上的 flume
flume-ng agent -n a1 --conf-file option_sdir.properties -Dflume.root.logger=INFO,console
启动后抛出以下异常:
java.lang.IllegalStateException: Directory does not exist: /root/log
这是因为目录没有创建,创建目录后再次启动,则解决了。
[root@node1 ~]# mkdir log
[root@node1 ~]# flume-ng agent -n a1 --conf-file option_sdir.properties -Dflume.root.logger=INFO,console
- 复制一个 node1 连接的 xshell 终端,/root/log 目录下拷贝文本文件
[root@node1 ~]# cp log.txt log/
- 然后在启动 flume 的终端中查看信息
20/05/16 22:07:24 INFO sink.LoggerSink: Event: {
headers:{
file=/root/log/log.txt} body: 68 65 6C 6C 6F 20 62 6A 73 78 74 hello bjsxt }
20/05/16 22:07:24 INFO sink.LoggerSink: Event: {
headers:{
file=/root/log/log.txt} body: 68 65 6C 6C 6F hello }
20/05/16 22:07:24 INFO avro.ReliableSpoolingFileEventReader: Last read took us just up to a file boundary. Rolling to the next file, if there is one.
20/05/16 22:07:24 INFO avro.ReliableSpoolingFileEventReader: Preparing to move file /root/log/log.txt to /root/log/log.txt.COMPLETED
- 然后 cd 到 /root/log 目录下查看信息
[root@node1 ~]# cd log/
[root@node1 log]# ls
install.log.COMPLETED log.txt.COMPLETED
- 先停掉 node1 上的 flume(ctrl+c)
- 修改
option_sdir.properties:
[root@node1 ~]# cp option.properties option_sdir.properties
[root@node1 ~]# vim option_sdir.properties
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/log
a1.sources.r1.fileHeader = true
a1.sources.r1.fileSuffix = .sxt
# Describe the sink
- 启动 node1 上的 flume
flume-ng agent -n a1 --conf-file option_sdir.properties -Dflume.root.logger=INFO,console
文件又被重新加载了依次。
- 进入 /root/log 目录查看
[root@node1 log]# ls
install.log.COMPLETED.sxt log.txt.COMPLETED.sxt
flume sinks
HDFS Sink (使用较多)
参考网址:
http://flume.apache.org/releases/content/1.6.0/FlumeUserGuide.html#flume-sinks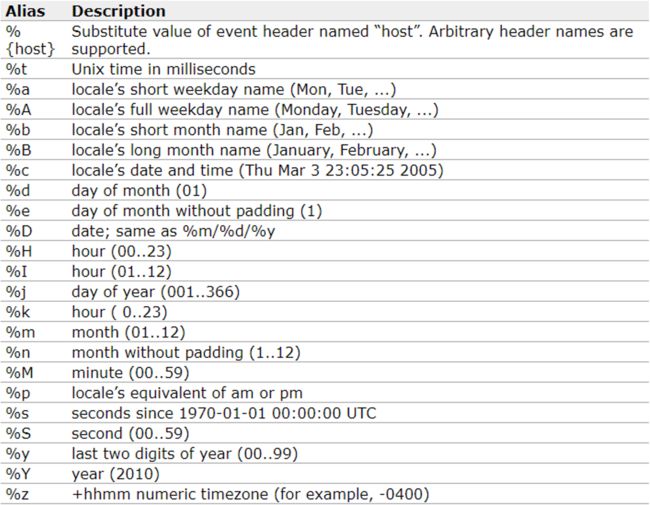
支持的逃逸字符:
| 别名 | 描述 |
|---|---|
| %t | Unix时间戳,毫秒 |
| %{host} | 替换名为"host"的事件header的值。支持任意标题名称。 |
| %a | 星期几的短名,即Mon, Tue, … |
| %A | 星期几的全名,即Monday, Tuesday, … |
| %b | 月份短名,即Jan, Feb, … |
| %B | 月份全名,即January, February, … |
| %c | 时间和日期,即Thu Mar 3 23:05:25 2005 |
| %d | day of month (01) |
| %e | day of month without padding (1) |
| %D | date; same as %m/%d/%y |
| %H | hour (00…23) |
| %I | hour (01…12) |
| %j | day of year (001…366) |
| %k | 小时 ( 0…23) |
| %m | 月份 (01…12) |
| %n | 不加前缀的月份 (1…12) |
| %M | 分钟(00…59) |
| %p | locale’s equivalent of am or pm |
| %s | seconds since 1970-01-01 00:00:00 UTC |
| %S | second (00…59) |
| %y | 年份最后两位 (00…99) |
| %Y | year (2010) |
| %z | +hhmm数字时区 (for example, -0400) |
| 属性名称 | 默认值 | 说明 |
|---|---|---|
| channel | - | |
| type | - | 组件类型名称,必须是 hdfs |
| hdfs.path | - | HDFS路径,如hdfs://mycluster/flume/mydata |
| hdfs.filePrefix | FlumeData | flume在hdfs目录中创建文件的前缀 |
| hdfs.fileSuffix | - | flume在hdfs目录中创建文件的后缀。 |
| hdfs.inUsePrefix | - | flume正在写入的临时文件的前缀 |
| hdfs.inUseSuffix | .tmp | flume正在写入的临时文件的后缀 |
| hdfs.rollInterval | 30 | 多长时间写一个新的文件 (0 = 不写新的文件),单位秒 |
| hdfs.rollSize | 1024 | 文件多大写新文件单位字节(0: 不基于文件大小写新文件) |
| hdfs.rollCount | 10 | 当写一个新的文件之前要求当前文件写入多少事件(0 = 不基于事件数写新文件) |
| hdfs.idleTimeout | 0 | 多长时间没有新增事件则关闭文件(0 = 不自动关闭文件)单位为秒 |
| hdfs.batchSize | 100 | 写多少个事件开始向HDFS刷数据 |
| hdfs.codeC | - | 压缩格式:gzip, bzip2, lzo, lzop, snappy |
| hdfs.fileType | SequenceFile | 当前支持三个值:SequenceFile,DataStream,CompressedStream。(1)DataStream不压缩输出文件,不要设置codeC (2)CompressedStream 必须设置codeC |
| hdfs.maxOpenFiles | 5000 | 最大打开多少个文件。如果数量超了则关闭最旧的文件 |
| hdfs.minBlockReplicas | - | 对每个hdfs的block设置最小副本数。如果不指定,则使用hadoop的配置的值。1 |
| hdfs.writeFormat | - | 对于sequence file记录的类型。Text或者Writable(默认值) |
| hdfs.callTimeout | 10000 | 为HDFS操作如open、write、flush、close准备的时间。如果HDFS操作很慢,则可以设置这个值大一点儿。单位毫秒 |
| hdfs.threadsPoolSize | 10 | 每个HDFS sink的用于HDFS io操作的线程数 (open, write, etc.) |
| hdfs.rollTimerPoolSize | 1 | 每个HDFS sink使用几个线程用于调度计时文件滚动。 |
| hdfs.round | false | 支持文件夹滚动的属性。是否需要新建文件夹。如果设置为true,则会影响所有的基于时间的逃逸字符,除了%t。 |
| hdfs.roundValue | 1 | 该值与roundUnit一起指定文件夹滚动的时长,会四舍五入 |
| hdfs.roundUnit | second | 控制文件夹个数。多长时间生成新文件夹。可以设置为- second, minute 或者 hour. |
| hdfs.timeZone | Local Time | Name of the timezone that should be used for resolving the directory path, e.g. America/Los_Angeles. |
| hdfs.useLocalTimeStamp | false | 一般设置为true,使用本地时间。如果不使用本地时间,要求flume发送的事件header中带有时间戳。该时间用于替换逃逸字符 |
案例1:每 5 秒在 hdfs 上创建一个新的文件夹
- 启动 hadoop 集群上的 hdfs
- 先停掉 node1 上的 flume(ctrl+c)
- 将 node1 上的 option_sdir.properties 拷贝 option_hdfs1.properties,并修改:
[root@node1 ~]# cp option_sdir.properties option_hdfs1.properties
[root@node1 ~]# vim option_hdfs1.properties
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/log
a1.sources.r1.fileHeader = true
a1.sources.r1.fileSuffix = .sxt
# Describe the sink
a1.sinks.k1.type = hdfs
# 时间会四舍五入
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/%S
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 5
a1.sinks.k1.hdfs.roundUnit = second
a1.sinks.k1.hdfs.useLocalTimeStamp=true
# Use a channel which buffers events in memory
.....
如果不配置a1.sinks.k1.hdfs.useLocalTimeStamp=true,flume在启动(存在未被处理的文件时)或执行步骤6的时候抛以下异常: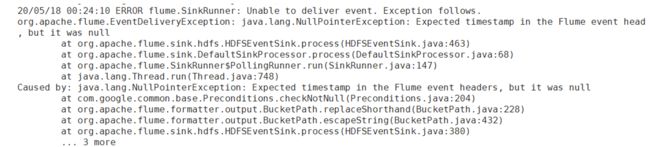
- 启动 node1 上的 flume
flume-ng agent -n a1 --conf-file option_hdfs1.properties -Dflume.root.logger=INFO,console
- 通过浏览器
node2:50070访问 hdfs 目录,发现 /flume 并不存在。 - 复制一个 node1 连接的 xshell 终端,/root/log 目录下拷贝文本文件
[root@node1 ~]# cp log.txt log/
[root@node1 ~]# cp hh.txt log/
[root@node1 ~]# cp wc.txt log/
- 然后在启动 flume 的终端中查看信息

- 通过浏览器
node2:50070访问 hdfs 目录,发现 /flume 出现了

注意:如果你的电脑比较慢可以添加一个属性:
a1.sinks.k1.hdfs.callTimeout=60000
案例2:每100条记录写到一个文件中
# Describe the sink
a1.sinks.k1.type = hdfs
# 时间会四舍五入
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.rollInterval=0
a1.sinks.k1.hdfs.rollSize=0
# 10个记录写到一个文件中,然后滚动输出
a1.sinks.k1.hdfs.rollCount=10
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 2
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.useLocalTimeStamp=true
a1.sinks.k1.hdfs.callTimeout=60000
# Use a channel which buffers events in memory
......
案例3:五秒写入到一个文件中
.....
# Describe the sink
a1.sinks.k1.type = hdfs
# 时间会四舍五入
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.rollInterval=5
a1.sinks.k1.hdfs.rollSize=0
a1.sinks.k1.hdfs.rollCount=0
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 2
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.useLocalTimeStamp=true
a1.sinks.k1.hdfs.callTimeout=60000
# Use a channel which buffers events in memory
......
Hive Sink (使用较多)
| 属性名 | 默认值 | 说明 |
|---|---|---|
| channel | - | |
| type | - | 组件类型名称,必须是 hive |
| hive.metastore | - | 元数据仓库地址,如 thrift://node3:9083 |
| hive.database | - | 数据库名称 |
| hive.table | - | 表名 |
| hive.partition | - | 逗号分割的分区值,标识写到哪个分区 可以包含逃逸字符 如果表分区字段为:(continent: string, country :string, time : string) 则"Asia,India,2020-05-26-01-21"表continent为Asia country为India,time是2020-05-26-01-21 |
| callTimeout | 10000 | Hive和HDFS的IO操作超时时间,比如openTxn,write,commit,abort等操作。单位毫秒 |
| batchSize | 15000 | 一个hive的事务允许写的事件最大数量。 |
| roundUnit | minute | 控制多长时间生成一个文件夹的单位:second,minute,hour |
HBase Sink (使用较多)
| 属性名称 | 默认值 | 描述 |
|---|---|---|
| channel | - | |
| type | - | 组件类型名称,必须是hbase |
| table | - | hbase的表名 |
| columnFamily | - | 列族的名称 |
| zookeeperQuorum | - | 对应于hbase-site.xml中hbase.zookeeper.quorum的值,指定zookeeper集群地址列表。 |
其它 Sink
- Logger Sink
- Avro Sink(使用较多)
- Thrift Sink(使用较多)
a1.sinks.k1.type=thrift
a1.sinks.k1.hostname=node3 连谁?
a1.sinks.k1.port=8888 对方端口
- File Roll Sink
- ElasticSearchSink(使用较多)
- Kafka Sink(使用较多)
flume channel
- Memory Channel
a1.channels = c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 10000
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
- JDBC Channel
a1.channels = c1
a1.channels.c1.type = jdbc
- File Channel
磁盘上的某个文件,速度较慢。 - Kafka Channel
思考:
1、flume 如何收集 java 请求数据?
2、项目当中如何来做? 日志存放 /log/ 目录下 以 yyyyMMdd 为子目录 分别存放每天的数据
flume 应用在项目中的配置
- node1 上创建配置文件 project
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/data/access.log
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /log/%Y%m%d
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.rollSize = 10240000
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.callTimeout = 60000
#防止sequence file的前缀字符,修改为DataStream
a1.sinks.k1.hdfs.fileType = DataStream
# 10s关闭hdfs连接。
a1.sinks.k1.hdfs.idleTimeout = 10
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 启动 node1 上 flume
flume-ng agent -n a1 --conf-file project -Dflume.root.logger=INFO,console
- 查看日志收集结果 node2:50070

- 将文件下载,打开查看
a1.sinks.k1.hdfs.fileType = DataStream参数配置,文件内容没有默认多余的内容了。 - 然后运行项目,访问网页,点击链接产生日志,然后再 node2:50070 查看。
flume 如何收集 java 请求数据
演示步骤:
- 解压 flume 包拷贝 lib 下的所有 jar 包到项目的 lib 文件夹下
- 选择 Idea 项目中 lib 文件夹–>右键–>Add as Library
- 将
com/sxt/log/test/AvroClient.java类中的注释去掉,并修改端口
client.init(“node3”, 10086);
代码分析 AvroClient - 启动 node3 上的 flume:
flume-ng agent -n a1 --conf-file option3.properties -Dflume.root.logger=INFO,console
- 运行AvroClient.java类
- 查看node3上flume日志
ETL
解析思路:
- 通过^A进行拆分,不足四部分的数据不符合要求,过滤掉。
- ?后面的内容按照 & 进行拆分,参数en的值如果不是6种事件类型的过滤掉。
192.168.100.1^A1574736498.958^Anode1
192.168.100.1^A1574736498.958^Anode1^A/log.gif?en=e_e&ca=event%E7%9A%84category%E5%90%8D%E7 %A7%B0&ac=event%E7%9A%84action%E5%90%8D%E7%A7%B0&kv_key1=value1&kv_key2=value2&du=1245&ver= 1&pl=website&sdk=js&u_ud=8D4F0D4B-7623-4DB2-A17B-83AD72C2CCB3&u_mid=zhangsan&u_sd=9C7C0951- DCD3-47F9-AD8F-B937F023611B&c_time=1574736499827&l=zh-CN&b_iev=Mozilla%2F5.0%20(Windows%20N T%2010.0%3B%20Win64%3B%20x64)%20AppleWebKit%2F537.36%20(KHTML%2C%20like%20Gecko)%20Chrome%2 F78.0.3904.108%20Safari%2F537.36&b_rst=1360*768
================================================
192.168.100.1 换算成地域
1574736498.958 时间
浏览器相关信息提取处理
项目搭建
- 将代码 /big_data_etl.zip 解压到项目 logpro 目录下
- 使用已存在的 big_data_etl 创建 Module。
解析IP地址到地域
用于解析IP地址到地域。
http://ip.taobao.com/index.html
qqwry.dat 保存了 ip 地址到地域的对应关系。
第三方的工具类直接用:
com.sxt.etl.util.IPSeekerExt
public RegionInfo analyticIp(String ip) {
......}
运行big_data_etl\test\com\sxt\test\TestIPSeeker.java:
分析 IPSeeker 类。
运行big_data_etl\test\com\sxt\test\TestIPSeekerExt.java:
分析 IPSeekerExt 类。
浏览器相关信息
解析浏览器的相关信息 user agent , 使用的类 com.sxt.etl.util.UserAgentUtil:UserAgentInfo analyticUserAgent(String userAgent)
使用到的 jar 包:uasparser-0.6.1.jar
修改big_data_etl\test\com\sxt\test\TestUserAgentUtil
1. public class TestUserAgentUtil {
2. public static void main(String[] args) {
3. String userAgent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.71 Safari/537.36";
4. UserAgentInfo info = UserAgentUtil.analyticUserAgent(userAgent);
5. System.out.println(info);
6. userAgent = "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; GWX:QUALIFIED; rv:11.0) like Gecko";
7. info = UserAgentUtil.analyticUserAgent(userAgent);
8. System.out.println(info);
9. userAgent = "Mozilla/5.0 (Windows NT 6.3; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0";
10. info = UserAgentUtil.analyticUserAgent(userAgent);
11. System.out.println(info);
12. }
13. }
运行: 分析 UserAgentUtil、UserAgentInfo 类。
分析 UserAgentUtil、UserAgentInfo 类。
ETL 代码讲解
准备工作:
启动hadoop高可用集群:startha.sh
启动hbase服务器:start-hbase.sh
创建hbase客户端:hbase shell
创建hbase表:create ‘eventlog’,’log’;
common 公共包(主要定义一些常亮)
util 工具类
AnalyserLogDataRunner
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.log4j.Logger;
import com.sxt.common.EventLogConstants;
import com.sxt.common.GlobalConstants;
import com.sxt.util.TimeUtil;
/**
* 编写mapreduce的runner类
*
* @author root
*
*/
public class AnalyserLogDataRunner implements Tool {
private static final Logger logger = Logger
.getLogger(AnalyserLogDataRunner.class);
private Configuration conf = null;
public static void main(String[] args) {
try {
ToolRunner.run(new Configuration(true), new AnalyserLogDataRunner(), args);
} catch (Exception e) {
logger.error("执行日志解析job异常", e);
throw new RuntimeException(e);
}
}
@Override
public void setConf(Configuration conf) {
conf.set("fs.defaultFS", "hdfs://node2:8020");
// conf.set("yarn.resourcemanager.hostname", "node3");
conf.set("hbase.zookeeper.quorum", "node2,node3,node4");
this.conf = HBaseConfiguration.create(conf);
}
@Override
public Configuration getConf() {
return this.conf;
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = this.getConf();
this.processArgs(conf, args);
Job job = Job.getInstance(conf, "analyser_logdata");
// 设置本地提交job,集群运行,需要代码
// File jarFile = EJob.createTempJar("target/classes");
// ((JobConf) job.getConfiguration()).setJar(jarFile.toString());
// 设置本地提交job,集群运行,需要代码结束
job.setJarByClass(AnalyserLogDataRunner.class);
job.setMapperClass(AnalyserLogDataMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Put.class);
// 设置reducer配置
// 1. 集群上运行,打成jar运行(要求addDependencyJars参数为true,默认就是true)
// TableMapReduceUtil.initTableReducerJob(EventLogConstants.HBASE_NAME_EVENT_LOGS,
// null, job);
// 2. 本地运行,要求参数addDependencyJars为false
TableMapReduceUtil.initTableReducerJob(
EventLogConstants.HBASE_NAME_EVENT_LOGS,
null,
job,
null,
null,
null, null, false);
job.setNumReduceTasks(0);
// 设置输入路径
this.setJobInputPaths(job);
return job.waitForCompletion(true) ? 0 : -1;
}
/**
* 处理参数
*
* @param conf
* @param args -a hello -d 2020-04-26
*/
private void processArgs(Configuration conf, String[] args) {
String date = null;
for (int i = 0; i < args.length; i++) {
if ("-d".equals(args[i])) {
if (i + 1 < args.length) {
date = args[++i];
break;
}
}
}
System.out.println("-----" + date);
// 要求date格式为: yyyy-MM-dd
if (StringUtils.isBlank(date) || !TimeUtil.isValidateRunningDate(date)) {
// date是一个无效时间数据
date = TimeUtil.getYesterday(); // 默认时间是昨天
System.out.println(date);
}
conf.set(GlobalConstants.RUNNING_DATE_PARAMES, date);
}
/**
* 设置job的输入路径
*
* @param job
*/
private void setJobInputPaths(Job job) {
Configuration conf = job.getConfiguration();
FileSystem fs = null;
try {
fs = FileSystem.get(conf);
String date = conf.get(GlobalConstants.RUNNING_DATE_PARAMES);
// Path inputPath = new Path("/flume/" +
// TimeUtil.parseLong2String(TimeUtil.parseString2Long(date),
// "MM/dd/"));
Path inputPath = new Path("/log/"
+ TimeUtil.parseLong2String(
TimeUtil.parseString2Long(date), "yyyyMMdd")
+ "/");
if (fs.exists(inputPath)) {
FileInputFormat.addInputPath(job, inputPath);
} else {
throw new RuntimeException("文件不存在:" + inputPath);
}
} catch (IOException e) {
throw new RuntimeException("设置job的mapreduce输入路径出现异常", e);
} finally {
if (fs != null) {
try {
fs.close();
} catch (IOException e) {
// nothing
}
}
}
}
}
直接运行AnalyserLogDataRunner,出现异常,提示RuntimeException: 文件不存在:/log/20200519。
访问:http://node1:50070/ 参考 hdfs 的 /log 目录下有哪天的日志数据
设置参数运行: 
运行依然抛出相同的异常,日期格式不正确,默认还是访问处理昨天的,依然不存在。
再次修改参数: 
运行程序,数据插入到 hbase 中了。
课后作业
实现 Runner 和 Mapper 类。
新增用户数据处理
思路分析
比如统计学生人数?
统计维度:
男生
女生
戴眼镜
不戴眼镜
男生
女生
戴眼镜
不带眼睛
戴眼镜男生
不戴眼镜男生
戴眼镜女生
不戴眼镜女生
数据:
张三 男 戴眼镜
李四 男 不戴眼镜
map:(将输入的值变成 KV 格式的数据:K: 维度组合,V: 唯一标识的值)
男生 张三
戴眼镜 张三
戴眼镜男生 张三
男生 李四
不戴眼镜 李四
不戴眼镜男生 李四
reduce:(将相同 key 的数据聚合到一起,做去重累加操作)
男生 张三 2
男生 李四
戴眼镜 张三 1
不戴眼镜 李四 1
戴眼镜男生 张三 1
不戴眼镜男生 李四 1
统计新增用户,两个模块:
- 用户基本信息模块:(时间)
- 浏览器新增用户分析模块:(时间,浏览器信息)
数据:
zhangsan 2020-07-01 firefox-48
lisi 2020-07-01 firefox-53
map: (将输入的数据变成 KV 格式数据,k: 时间和浏览器的维度组合,V: 用户唯一标识)
2020-07-01 zhangsan
2020-07-01,firefox-48 zhangsan
2020-07-01,firefox-all zhangsan
2020-07-01 lisi
2020-07-01,firefox-53 lisi
2020-07-01,firefox-all lisi
reduce: (将相同 key 的数据汇聚到一起,对 value 的值进行去重累加)
2020-07-01 zhangsan 2
2020-07-01 lisi
2020-07-01,firefox-48 zhangsan 1
2020-07-01,firefox-53 lisi 1
2020-07-01,firefox-all zhangsan 2
2020-07-01,firefox-all lisi
为了方便的将结果存入到不同的 MySQL 表中,将模块名称也当作其中一个维度进行统计
zhangsan www.bjsxt.com 2020-07-01 firefox-48
lisi www.bjsxt.com 2020-07-01 firefox-53
(时间,user)
(时间,浏览器,browser)
map:
2020-07-01,user zhangsan
2020-07-01,firefox-48,browser zhangsan
2020-07-01,firefox-all,browser zhangsan
2020-07-01,user lisi
2020-07-01,firefox-53,browser lisi
2020-07-01,firefox-all,browser lisi
reduce:
2020-07-01,user zhangsan 2
2020-07-01,user lisi
2020-07-01,firefox-48,browser zhangsan 1
2020-07-01,firefox-all,browser zhangsan 2
2020-07-01,firefox-all,browser lisi
2020-07-01,firefox-53,browser lisi 1
当需要添加额外的其他维度的时候,怎么处理
zhangsan 2020-07-01 firefox-48 website
lisi 2020-07-01 firefox-53 website
维度:
时间,所有平台,user
时间,平台,user
时间,浏览器,平台,browser
时间,浏览器,所有平台,browser
map:
2020-07-01,all,user zhangsan
2020-07-01,website,user zhangsan
2020-07-01,firefox-48,website,browser zhangsan
2020-07-01,firefox-all,website,browser zhangsan
2020-07-01,firefox-48,all,browser zhangsan
2020-07-01,firefox-all,all,browser zhangsan
2020-07-01,all,user lisi
2020-07-01,website,user lisi
2020-07-01,firefox-53,website,browser lisi
2020-07-01,firefox-all,website,browser lisi
2020-07-01,firefox-53,all,browser lisi
2020-07-01,firefox-all,all,browser lisi
reduce:
2020-07-01,all,user zhangsan 2
2020-07-01,all,user lisi
2020-07-01,website,user zhangsan 2
2020-07-01,website,user lisi
2020-07-01,firefox-48,website,browser zhangsan 1
2020-07-01,firefox-all,website,browser zhangsan 2
2020-07-01,firefox-all,website,browser lisi
2020-07-01,firefox-48,all,browser zhangsan 1
2020-07-01,firefox-all,all,browser zhangsan 2
2020-07-01,firefox-all,all,browser lisi
2020-07-01,firefox-53,website,browser lisi 1
2020-07-01,firefox-53,all,browser lisi 1
创建数据库 result_db , 然后将《mysql_表设计.sql》导入到该数据库下: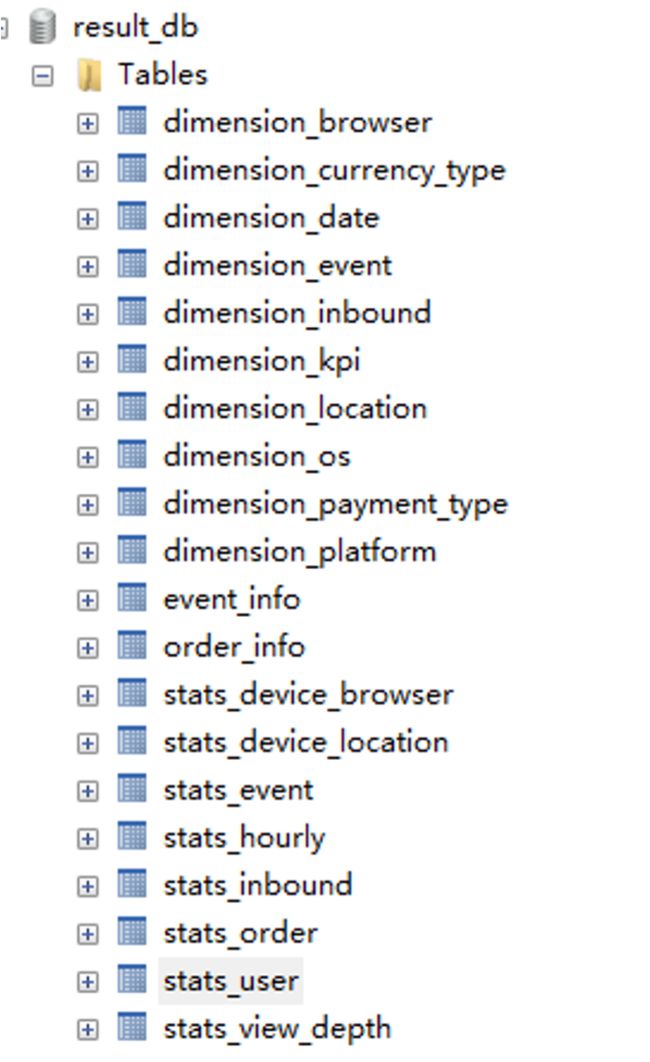
时间维度
浏览器维度
平台维度
KPI一个工具维度
通过以上四个维度的各种组合,计算它的新增用户指标
hbase
uuid,servertime,browser,platform,kpi
事件 lanuch en=e_l
时间
平台
kpi 模块 new_install_user,browser_new_install_user
浏览器
维度组合的类图: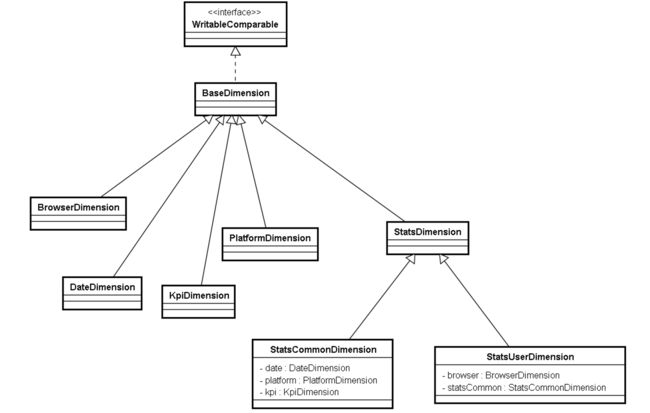
map
数据裂变
纬度组合
reduce
汇聚统计
1、 从hbase读取数据
2、 Mapper纬度的组合
3、 Reducer聚合
4、 数据放MySQL
a) TableMapReduceUtil.initTableReducerJob();
b) 自己实现向 MySQL 存数据的 OutputFormat
新增用户指标 Runner 开发
package com.sxt.transformer.mr.nu;
import com.sxt.transformer.model.dim.StatsUserDimension;
import com.sxt.transformer.model.value.map.TimeOutputValue;
import com.sxt.transformer.model.value.reduce.MapWritableValue;
import com.sxt.transformer.mr.TransformerOutputFormat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.log4j.Logger;
import java.util.List;
public class NewUserRunner implements Tool {
private static final Logger logger = Logger.getLogger(NewUserRunner.class);
private Configuration conf=null;
@Override
public void setConf(Configuration configuration) {
configuration.set("hbase.zookeeper.quorum","node2,node3,node4");
//添加配置文件
configuration.addResource("output-collector.xml");
configuration.addResource("query-mapping.xml");
configuration.addResource("transformer-env.xml");
//使用传入过来的configuration赋值给conf
this.conf = HBaseConfiguration.create(configuration);
//this.conf = configuration;
}
@Override
public Configuration getConf() {
return this.conf;
}
public static void main(String[] args) {
try {
ToolRunner.run(new Configuration(),new NewUserRunner(),args);
} catch (Exception e) {
logger.error("运行 new_user_runner抛出异常",e);
}
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = this.getConf();
Job job = Job.getInstance(conf,"new_install_user");
job.setJarByClass(NewUserRunner.class);
//从Hbase取数据 本地运行
TableMapReduceUtil.initTableMapperJob(
getScans(conf),
NewUserMapper.class,
StatsUserDimension.class,
TimeOutputValue.class,
job,
false
);
//设置reduce
job.setReducerClass(NewUserReducer.class);
job.setOutputValueClass(StatsUserDimension.class);
job.setOutputValueClass(MapWritableValue.class);
//向mysql中输出的类的类型
job.setOutputFormatClass(TransformerOutputFormat.class);
return job.waitForCompletion(true)?0:1;
}
private List<Scan> getScans(Configuration conf) {
return null;
}
}
1、scan 添加过滤器 , startKey stopKey
2、指定 en=e_l 的事件条件
3、指定要获取的列名
MultipleColumnPrefixFilter
4、指定表名
scan.setAttribute(Scan.SCAN_ATTRIUBTES_TABLE_NAME, EventLogContants.HBASE_NAME_EVENT_LOGS.getBytes());
TestDataMaker用于生成hbase的数据。
service.impl修改连接MySQL的字符串
transformer-env.xml中修改连接MySQL的字符串
com.sxt.transformer.service.impl.DimensionConverterImpl修改连接数据库字符串
新增用户指标 mapper 开发
四个纬度:时间、浏览器、平台、模块
需要对 LAUNCH_EVENT 数据过滤
组合四个纬度,向输出外键值对信息。
维度组合有多少种?
各个维度的种类相乘得到结果
package com.sxt.transformer.mr.nu;
import java.io.IOException;
import java.util.List;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.log4j.Logger;
import com.sxt.common.DateEnum;
import com.sxt.common.EventLogConstants;
import com.sxt.common.KpiType;
import com.sxt.transformer.model.dim.StatsCommonDimension;
import com.sxt.transformer.model.dim.StatsUserDimension;
import com.sxt.transformer.model.dim.base.BrowserDimension;
import com.sxt.transformer.model.dim.base.DateDimension;
import com.sxt.transformer.model.dim.base.KpiDimension;
import com.sxt.transformer.model.dim.base.PlatformDimension;
import com.sxt.transformer.model.value.map.TimeOutputValue;
/**
* 自定义的计算新用户的mapper类
*
* @author root
*
*/
public class NewInstallUserMapper extends TableMapper<StatsUserDimension, TimeOutputValue> {
//每个分析条件(由各个维度组成的)作为key,uuid作为value
private static final Logger logger = Logger.getLogger(NewInstallUserMapper.class);
private StatsUserDimension statsUserDimension = new StatsUserDimension();
private TimeOutputValue timeOutputValue = new TimeOutputValue();
private byte[] family = Bytes.toBytes(EventLogConstants.EVENT_LOGS_FAMILY_NAME);
//代表用户分析模块的统计
private KpiDimension newInstallUserKpi = new KpiDimension(KpiType.NEW_INSTALL_USER.name);
//浏览器分析模块的统计
private KpiDimension newInstallUserOfBrowserKpi = new KpiDimension(KpiType.BROWSER_NEW_INSTALL_USER.name);
/**
* map 读取hbase中的数据,输入数据为:hbase表中每一行。
* 输出key类型:StatsUserDimension
* value类型:TimeOutputValue
*/
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context)
throws IOException, InterruptedException {
String uuid = Bytes.toString(value.getValue(family, Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_UUID)));
String serverTime = Bytes.toString(value.getValue(family, Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_SERVER_TIME)));
String platform = Bytes.toString(value.getValue(family, Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_PLATFORM)));
System.out.println(uuid + "-" + serverTime + "-" + platform);
if (StringUtils.isBlank(uuid) || StringUtils.isBlank(serverTime) || StringUtils.isBlank(platform)) {
logger.warn("uuid&servertime&platform不能为空");
return;
}
long longOfTime = Long.valueOf(serverTime.trim());
timeOutputValue.setId(uuid); // 设置id为uuid
timeOutputValue.setTime(longOfTime); // 设置时间为服务器时间
DateDimension dateDimension = DateDimension.buildDate(longOfTime, DateEnum.DAY);
// 设置date维度
StatsCommonDimension statsCommonDimension = this.statsUserDimension.getStatsCommon();
statsCommonDimension.setDate(dateDimension);
List<PlatformDimension> platformDimensions = PlatformDimension.buildList(platform);
// browser相关的数据
String browserName = Bytes.toString(value.getValue(family, Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_BROWSER_NAME)));
String browserVersion = Bytes.toString(value.getValue(family, Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_BROWSER_VERSION)));
List<BrowserDimension> browserDimensions = BrowserDimension.buildList(browserName, browserVersion);
//空浏览器维度,不考虑浏览器维度
BrowserDimension defaultBrowser = new BrowserDimension("", "");
for (PlatformDimension pf : platformDimensions) {
statsUserDimension.setBrowser(defaultBrowser);
statsCommonDimension.setKpi(newInstallUserKpi);
statsCommonDimension.setPlatform(pf);
context.write(statsUserDimension, timeOutputValue);
for (BrowserDimension br : browserDimensions) {
statsCommonDimension.setKpi(newInstallUserOfBrowserKpi);
statsUserDimension.setBrowser(br);
context.write(statsUserDimension, timeOutputValue);
}
}
}
}
新增用户指标 reducer 开发
由于统计的是用户的数量,需要对 log 进行 uuid 的过滤,因为同一个人有可能点击了多次。
package com.sxt.transformer.mr.nu;
import com.sxt.common.KpiType;
import com.sxt.transformer.model.dim.StatsUserDimension;
import com.sxt.transformer.model.value.map.TimeOutputValue;
import com.sxt.transformer.model.value.reduce.MapWritableValue;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.MapWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.HashSet;
import java.util.Set;
/**reduce:将相同的key的数据汇聚到一起,得到最终的结果
* 输入:key statsUserDimenion
* value timeOutputValue(uuid)
* 输出:key statsUserDimenion
* value MapWritableValue
*
*/
public class NewUserReducer extends Reducer<StatsUserDimension,TimeOutputValue,StatsUserDimension,MapWritableValue> {
//创建reduce端输出的value对象
MapWritableValue mapWritableValue = new MapWritableValue();
//创建出重的集合对象set
Set<String> unique = new HashSet<String>();
@Override
protected void reduce(StatsUserDimension key, Iterable<TimeOutputValue> values, Context context) throws IOException, InterruptedException {
//清空unique集合,防止上一个迭代器残留下值产生的影响
this.unique.clear();
//遍历迭代器 将set集合的大小作为最终的统计结果
for (TimeOutputValue timeOutputValue : values) {
this.unique.add(timeOutputValue.getId());
}
//存放最终的计算结果,map的key是一个唯一标识,方便取值,value是集合的大小,最终的统计结果
MapWritable map = new MapWritable();
map.put(new IntWritable(-1),new IntWritable(this.unique.size()));
//将map结果放到到reduce输出的value对象中
mapWritableValue.setValue(map);
//获取模块维度名称
String kpiName = key.getStatsCommon().getKpi().getKpiName();
//将KpiType设置到reduce端输出的对象中
if(KpiType.NEW_INSTALL_USER.name.equals(kpiName)){
mapWritableValue.setKpi(KpiType.NEW_INSTALL_USER);
}else if(KpiType.BROWSER_NEW_INSTALL_USER.name.equals(kpiName)){
mapWritableValue.setKpi(KpiType.BROWSER_NEW_INSTALL_USER);
}
//输出
context.write(key,mapWritableValue);
}
}
新增用户指标 Runner 二次开发
完整版本:
package com.sxt.transformer.mr.nu;
import com.sxt.common.EventLogConstants;
import com.sxt.common.GlobalConstants;
import com.sxt.transformer.model.dim.StatsUserDimension;
import com.sxt.transformer.model.value.map.TimeOutputValue;
import com.sxt.transformer.model.value.reduce.MapWritableValue;
import com.sxt.transformer.mr.TransformerOutputFormat;
import com.sxt.util.TimeUtil;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.*;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.log4j.Logger;
import java.util.Arrays;
import java.util.List;
public class NewUserRunner implements Tool {
private static final Logger logger = Logger.getLogger(NewUserRunner.class);
private Configuration conf=null;
@Override
public int run(String[] args) throws Exception {
Configuration conf = this.getConf();
//解析参数
this.processArgs(conf,args);
Job job = Job.getInstance(conf,"new_install_user");
......
}
/**解析日期参数
* 参数格式 -d 2020-05-20
* @param conf:配置文件对象
* @param args 参数数组
*/
private void processArgs(Configuration conf, String[] args) {
String date = null;
for (int i = 0;i<args.length;i++) {
if("-d".equals(args[i])){
if(i+1<args.length){
date = args[++i];
}
}
}
if(StringUtils.isBlank(date)|| !TimeUtil.isValidateRunningDate(date)){
date = TimeUtil.getYesterday();
}
conf.set(GlobalConstants.RUNNING_DATE_PARAMES,date);
}
/**从hbase中获取符合条件的数据
* 条件:
* 1.时间范围
* 2.事件类型(en=e_l)
* 3.获取部分列
*/
private List<Scan> getScans(Configuration conf) {
//获取时间
String date = conf.get(GlobalConstants.RUNNING_DATE_PARAMES);
Scan scan = new Scan();
long time = TimeUtil.parseString2Long(date);//"yyyy-MM-dd"
String startRow = String.valueOf(time);
String stopRow = String.valueOf(time + GlobalConstants.DAY_OF_MILLISECONDS);
scan.setStartRow(startRow.getBytes());
scan.setStopRow(stopRow.getBytes());
//单一列值过滤器
SingleColumnValueFilter singleFilter = new SingleColumnValueFilter(
EventLogConstants.EVENT_LOGS_FAMILY_NAME.getBytes(),
EventLogConstants.LOG_COLUMN_NAME_EVENT_NAME.getBytes(),
CompareFilter.CompareOp.EQUAL,
Bytes.toBytes(EventLogConstants.EventEnum.LAUNCH.alias)//e_l
);
FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL);
//过滤数据,只分析launch事件
filterList.addFilter(singleFilter);
//定义mapper中需要的列
String[] columns = new String[]{
EventLogConstants.LOG_COLUMN_NAME_EVENT_NAME,
EventLogConstants.LOG_COLUMN_NAME_UUID,
EventLogConstants.LOG_COLUMN_NAME_SERVER_TIME,
EventLogConstants.LOG_COLUMN_NAME_PLATFORM,
EventLogConstants.LOG_COLUMN_NAME_BROWSER_NAME,
EventLogConstants.LOG_COLUMN_NAME_BROWSER_VERSION
};
//添加获取哪些列过滤器
filterList.addFilter(this.getColumnFilter(columns));
scan.setFilter(filterList);
//指定查询的表
scan.setAttribute(Scan.SCAN_ATTRIBUTES_TABLE_NAME,
EventLogConstants.HBASE_NAME_EVENT_LOGS.getBytes());
return Arrays.asList(scan);
}
/**获取某些指定的列
* @param columns 列名数组
* @return
*/
private Filter getColumnFilter(String[] columns) {
int length = columns.length;
byte[][] arrays = new byte[length][];
for(int i = 0;i<length;i++){
arrays[i] = columns[i].getBytes();
}
return new MultipleColumnPrefixFilter(arrays);
}
......
}
生成测试数据
- 先将原来的数据情况
hbase(main):002:0> truncate 'eventlog'
Truncating 'eventlog' table (it may take a while):
- Disabling table...
- Truncating table...
0 row(s) in 1.9260 seconds
hbase(main):003:0> count 'eventlog'
0 row(s) in 0.0800 seconds
- 打开 test 包下
com.sxt.test.TestDataMaker,修改 59 行的日期
运行程序。 - 查看数据是否添加成功:
hbase(main):007:0> count 'eventlog'
Current count: 1000, row: 1590249521000_61395304
1000 row(s) in 0.1630 seconds
=> 1000
- 修改日期
运行程序 ,同样的方法,可以多添加几天的数据。
- 修改
com.sxt.transformer.service.impl.DimensionConverterImpl
private static final String URL = "jdbc:mysql://node1:3306/result_db"
private static final String PASSWORD = "123456";
- 修改
transformer-env.xml
<property>
<name>mysql.report.url</name>
<value>jdbc:mysql://node1:3306/result_db?useUnicode=true&characterEncoding=utf8</value>
</property>
<property>
<name>mysql.report.password</name>
<value>123456</value>
</property>
- 运行
NewUserRunner类,并查看表中的数据:
dimension_browse、dimension_platform、stats_user、stats_device_browser
MapReduce 结果存 MySQL
OutputFormat
TransformOutputFormat extends OutputFormat
RecordWriter getRecordWriter()
TransformRecordWriter extends RecordWriter
write(key:维度组合对象,value:mapWritableValue):当reducer类中调用context.write()方法是被调用。向mysql中插入数据。
1. 获取数据库连接
2. Sql 以及为占位符赋值
3. executeUpdate
close()
mysql 表分为两类:
- 基本维度表:id(自增),其它值字段
- 结果表:联合主键(包含多个单一维度的 id 值),其它字段的统计结果。
先插入基本数据表中,获取 id 后,再添加到结果表中。
TransformerOutputFormat类中的RecordWriter用于向MySQL输出。
package com.sxt.transformer.mr;
import java.io.IOException;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.OutputCommitter;
import org.apache.hadoop.mapreduce.OutputFormat;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.log4j.Logger;
import com.sxt.common.GlobalConstants;
import com.sxt.common.KpiType;
import com.sxt.transformer.model.dim.base.BaseDimension;
import com.sxt.transformer.model.value.BaseStatsValueWritable;
import com.sxt.transformer.service.IDimensionConverter;
import com.sxt.transformer.service.impl.DimensionConverterImpl;
import com.sxt.util.JdbcManager;
/**
* 自定义输出到mysql的outputformat类
* BaseDimension:reducer输出的key
* BaseStatsValueWritable:reducer输出的value
* @author root
*
*/
public class TransformerOutputFormat extends OutputFormat<BaseDimension, BaseStatsValueWritable> {
private static final Logger logger = Logger.getLogger(TransformerOutputFormat.class);
/**
* 定义每条数据的输出格式,一条数据就是reducer任务每次执行write方法输出的数据。
*/
@Override
public RecordWriter<BaseDimension, BaseStatsValueWritable> getRecordWriter(TaskAttemptContext context) throws IOException, InterruptedException {
Configuration conf = context.getConfiguration();
Connection conn = null;
IDimensionConverter converter = new DimensionConverterImpl();
try {
conn = JdbcManager.getConnection(conf, GlobalConstants.WAREHOUSE_OF_REPORT);
conn.setAutoCommit(false);
} catch (SQLException e) {
logger.error("获取数据库连接失败", e);
throw new IOException("获取数据库连接失败", e);
}
return new TransformerRecordWriter(conn, conf, converter);
}
@Override
public void checkOutputSpecs(JobContext context) throws IOException, InterruptedException {
// 检测输出空间,输出到mysql不用检测
}
@Override
public OutputCommitter getOutputCommitter(TaskAttemptContext context) throws IOException, InterruptedException {
return new FileOutputCommitter(FileOutputFormat.getOutputPath(context), context);
}
/**
* 自定义具体数据输出writer
*
* @author root
*
*/
public class TransformerRecordWriter extends RecordWriter<BaseDimension, BaseStatsValueWritable> {
private Connection conn = null;
private Configuration conf = null;
private IDimensionConverter converter = null;
private Map<KpiType, PreparedStatement> map = new HashMap<KpiType, PreparedStatement>();
private Map<KpiType, Integer> batch = new HashMap<KpiType, Integer>();
public TransformerRecordWriter(Connection conn, Configuration conf, IDimensionConverter converter) {
super();
this.conn = conn;
this.conf = conf;
this.converter = converter;
}
@Override
/**
* 当reduce任务输出数据是,由计算框架自动调用。把reducer输出的数据写到mysql中
*/
public void write(BaseDimension key, BaseStatsValueWritable value) throws IOException, InterruptedException {
if (key == null || value == null) {
return;
}
try {
KpiType kpi = value.getKpi();
PreparedStatement pstmt = null;//每一个pstmt对象对应一个sql语句
int count = 1;//sql语句的批处理,一次执行10
if (map.get(kpi) == null) {
// 使用kpi进行区分,返回sql保存到config中
pstmt = this.conn.prepareStatement(conf.get(kpi.name));
map.put(kpi, pstmt);
} else {
pstmt = map.get(kpi);
count = batch.get(kpi);
count++;
}
batch.put(kpi, count); // 批量次数的存储
String collectorName = conf.get(GlobalConstants.OUTPUT_COLLECTOR_KEY_PREFIX + kpi.name);
Class<?> clazz = Class.forName(collectorName);
IOutputCollector collector = (IOutputCollector) clazz.newInstance();//把value插入到mysql的方法。由于kpi维度不一样。插入到不能表里面。
collector.collect(conf, key, value, pstmt, converter);
if (count % Integer.valueOf(conf.get(GlobalConstants.JDBC_BATCH_NUMBER, GlobalConstants.DEFAULT_JDBC_BATCH_NUMBER)) == 0) {
pstmt.executeBatch();
conn.commit();
batch.put(kpi, 0); // 对应批量计算删除
}
} catch (Throwable e) {
logger.error("在writer中写数据出现异常", e);
throw new IOException(e);
}
}
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
try {
for (Map.Entry<KpiType, PreparedStatement> entry : this.map.entrySet()) {
entry.getValue().executeBatch();
}
} catch (SQLException e) {
logger.error("执行executeUpdate方法异常", e);
throw new IOException(e);
} finally {
try {
if (conn != null) {
conn.commit(); // 进行connection的提交动作
}
} catch (Exception e) {
// nothing
} finally {
for (Map.Entry<KpiType, PreparedStatement> entry : this.map.entrySet()) {
try {
entry.getValue().close();
} catch (SQLException e) {
// nothing
}
}
if (conn != null)
try {
conn.close();
} catch (Exception e) {
// nothing
}
}
}
}
}
}
- com.sxt.transformer.mr.nu.NewUserReducer
context.write(key,mapWritableValue); //Ctrl+点击 - org.apache.hadoop.mapreduce.TaskInputOutputContext
void write(KEYOUT var1, VALUEOUT var2) throws IOException, InterruptedException; //Ctrl+Alt+B
选择org.apache.hadoop.mapreduce.lib.chain.ChainReduceContextImpl - org.apache.hadoop.mapreduce.lib.chain.ChainReduceContextImpl
private final RecordWriter<KEYOUT, VALUEOUT> rw;
public ChainReduceContextImpl(ReduceContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> base, RecordWriter<KEYOUT, VALUEOUT> output, Configuration conf) {
this.base = base;
this.rw = output;
this.conf = conf;
}
public void write(KEYOUT key, VALUEOUT value) throws IOException, InterruptedException {
this.rw.write(key, value);//Ctrl+单击
}
- org.apache.hadoop.mapreduce.RecordWriter
public abstract class RecordWriter<K, V> {
public RecordWriter() {
}
public abstract void write(K var1, V var2) throws IOException, InterruptedException;//Ctrl+Alt+B
public abstract void close(TaskAttemptContext var1) throws IOException, InterruptedException;
}
- com.sxt.transformer.mr.TransformerOutputFormat
找到了我们自定义类的write方法了。
活跃用户数据处理
什么是活跃用户?
时间、平台、kpi
时间、平台、浏览器、kpi
事件类型:en=e_pv
活跃用户指标ActiveUserRunner开发
package com.sxt.transformer.mr.au;
import com.sxt.transformer.model.dim.StatsUserDimension;
import com.sxt.transformer.model.value.map.TimeOutputValue;
import com.sxt.transformer.model.value.reduce.MapWritableValue;
import com.sxt.transformer.mr.TransformerOutputFormat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.util.List;
public class ActiveUserRunner implements Tool {
private Configuration conf;
@Override
public int run(String[] args) throws Exception {
//Configuration conf = this.getConf();
this.processArgs(args);
Job job = Job.getInstance(conf,"active_user");
job.setJarByClass(ActiveUserRunner.class);
TableMapReduceUtil.initTableMapperJob(
getScans(conf),
ActiveUserMapper.class,
StatsUserDimension.class,
TimeOutputValue.class,
job,
false
);
job.setReducerClass(ActiveUserReducer.class);
job.setOutputKeyClass(StatsUserDimension.class);
job.setOutputValueClass(MapWritableValue.class);
job.setOutputFormatClass(TransformerOutputFormat.class);
return job.waitForCompletion(true)?0:1;
}
private void processArgs(String[] args) {
}
private List<Scan> getScans(Configuration conf) {
return null;
}
@Override
public void setConf(Configuration configuration) {
configuration.set("hbase.zookeeper.quorum","node2,node3,node4");
configuration.addResource("output-collector.xml");
configuration.addResource("query-mapping.xml");
configuration.addResource("transformer-env.xml");
this.conf = HBaseConfiguration.create(configuration);
}
@Override
public Configuration getConf() {
return this.conf;
}
public static void main(String[] args) {
try {
ToolRunner.run(new Configuration(),new ActiveUserRunner(),args);
} catch (Exception e) {
e.printStackTrace();
}
}
}
活用户用户指标 Mapper 开发
package com.sxt.transformer.mr.au;
import com.sxt.common.DateEnum;
import com.sxt.common.EventLogConstants;
import com.sxt.common.KpiType;
import com.sxt.transformer.model.dim.StatsCommonDimension;
import com.sxt.transformer.model.dim.StatsUserDimension;
import com.sxt.transformer.model.dim.base.BrowserDimension;
import com.sxt.transformer.model.dim.base.DateDimension;
import com.sxt.transformer.model.dim.base.KpiDimension;
import com.sxt.transformer.model.dim.base.PlatformDimension;
import com.sxt.transformer.model.value.map.TimeOutputValue;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
import java.util.List;
public class ActiveUserMapper extends TableMapper<StatsUserDimension,TimeOutputValue> {
//定义列族
byte[] famliy = Bytes.toBytes(EventLogConstants.EVENT_LOGS_FAMILY_NAME);
//map端输出的key对象
StatsUserDimension statsUserDimension = new StatsUserDimension();
//map端输出的value对象
TimeOutputValue timeOutputValue = new TimeOutputValue();
//模块维度
KpiDimension activeUser = new KpiDimension(KpiType.ACTIVE_USER.name);
KpiDimension activeUserOfBrower = new KpiDimension(KpiType.BROWSER_ACTIVE_USER.name);
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {
//获取时间
String date = Bytes.toString(CellUtil.cloneValue(value.getColumnLatestCell(famliy,EventLogConstants.LOG_COLUMN_NAME_SERVER_TIME.getBytes())));
//浏览器名称
String browerName = Bytes.toString(CellUtil.cloneValue(value.getColumnLatestCell(famliy,EventLogConstants.LOG_COLUMN_NAME_BROWSER_NAME.getBytes())));
//浏览器版本
String browerVersion = Bytes.toString(CellUtil.cloneValue(value.getColumnLatestCell(famliy,EventLogConstants.LOG_COLUMN_NAME_BROWSER_VERSION.getBytes())));
//用户id
String uuid = Bytes.toString(CellUtil.cloneValue(value.getColumnLatestCell(famliy,EventLogConstants.LOG_COLUMN_NAME_UUID.getBytes())));
//平台
String platform = Bytes.toString(CellUtil.cloneValue(value.getColumnLatestCell(famliy,EventLogConstants.LOG_COLUMN_NAME_PLATFORM.getBytes())));
long time = Long.valueOf(date);
//构建单一维度对象
DateDimension dateDimension = DateDimension.buildDate(time,DateEnum.DAY);
List<BrowserDimension> browserDimensions = BrowserDimension.buildList(browerName,browerVersion);
List<PlatformDimension> platformDimensions = PlatformDimension.buildList(platform);
//设置map端输出的值
timeOutputValue.setId(uuid);
timeOutputValue.setTime(time);
//构建组合维度对象
StatsCommonDimension statsCommonDimension = statsUserDimension.getStatsCommon();
statsCommonDimension.setDate(dateDimension);
BrowserDimension defaultBrower = new BrowserDimension("","");
for (PlatformDimension platformDimension : platformDimensions) {
statsCommonDimension.setKpi(activeUser);
statsCommonDimension.setPlatform(platformDimension);
statsUserDimension.setBrowser(defaultBrower);
context.write(statsUserDimension,timeOutputValue);
for(BrowserDimension browserDimension : browserDimensions){
statsCommonDimension.setKpi(activeUserOfBrower);
statsUserDimension.setBrowser(browserDimension);
context.write(statsUserDimension,timeOutputValue);
}
}
}
}
活用户用户指标 Reducer 开发
package com.sxt.transformer.mr.au;
import com.sxt.common.KpiType;
import com.sxt.transformer.model.dim.StatsUserDimension;
import com.sxt.transformer.model.value.map.TimeOutputValue;
import com.sxt.transformer.model.value.reduce.MapWritableValue;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.MapWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.HashSet;
import java.util.Set;
public class ActiveUserReducer extends Reducer<StatsUserDimension,TimeOutputValue,StatsUserDimension,MapWritableValue> {
//创建reduce端输出的value对象
MapWritableValue outValue = new MapWritableValue();
//去重,定义set集合
Set<String> unique = new HashSet<String>();
@Override
protected void reduce(StatsUserDimension key, Iterable<TimeOutputValue> values, Context context) throws IOException, InterruptedException {
//清空unique集合,排除上次结果的干扰
this.unique.clear();
//将values迭代器中的数据添加到unique集合中
for (TimeOutputValue timeOutputValue : values) {
this.unique.add(timeOutputValue.getId());
}
MapWritable map = new MapWritable();
map.put(new IntWritable(-1),new IntWritable(this.unique.size()));
outValue.setValue(map);
String kpiName = key.getStatsCommon().getKpi().getKpiName();
KpiType kpi = KpiType.valueOfName(kpiName);
outValue.setKpi(kpi);
context.write(key,outValue);
}
}
活用户用户指标 Runner 二次开发
package com.sxt.transformer.mr.au;
import com.sxt.common.EventLogConstants;
import com.sxt.common.GlobalConstants;
import com.sxt.transformer.model.dim.StatsUserDimension;
import com.sxt.transformer.model.value.map.TimeOutputValue;
import com.sxt.transformer.model.value.reduce.MapWritableValue;
import com.sxt.transformer.mr.TransformerOutputFormat;
import com.sxt.util.TimeUtil;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.*;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.protobuf.generated.FilterProtos;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.awt.*;
import java.util.Arrays;
import java.util.List;
public class ActiveUserRunner implements Tool {
......
private void processArgs(String[] args) {
String date = null;
for (int i = 0;i<args.length;i++) {
if("-d".equals(args[i])){
if(i+1<args.length){
date = args[++i];
}
}
}
if(StringUtils.isBlank(date)||!TimeUtil.isValidateRunningDate(date)){
date = TimeUtil.getYesterday();
}
conf.set(GlobalConstants.RUNNING_DATE_PARAMES,date);
}
private List<Scan> getScans(Configuration conf) {
String date = conf.get(GlobalConstants.RUNNING_DATE_PARAMES);
long startTime = TimeUtil.parseString2Long(date);
long endTime = startTime + GlobalConstants.DAY_OF_MILLISECONDS;
Scan scan = new Scan();
scan.setStartRow(String.valueOf(startTime).getBytes());
scan.setStopRow(String.valueOf(endTime).getBytes());
//定义过滤器
FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL);
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(
EventLogConstants.EVENT_LOGS_FAMILY_NAME.getBytes(),
EventLogConstants.LOG_COLUMN_NAME_EVENT_NAME.getBytes(),
CompareFilter.CompareOp.EQUAL,
EventLogConstants.EventEnum.PAGEVIEW.alias.getBytes()
);
filterList.addFilter(singleColumnValueFilter);
String[] columns = new String[]{
EventLogConstants.LOG_COLUMN_NAME_EVENT_NAME,
EventLogConstants.LOG_COLUMN_NAME_SERVER_TIME,
EventLogConstants.LOG_COLUMN_NAME_BROWSER_NAME,
EventLogConstants.LOG_COLUMN_NAME_BROWSER_VERSION,
EventLogConstants.LOG_COLUMN_NAME_PLATFORM,
EventLogConstants.LOG_COLUMN_NAME_UUID
};
filterList.addFilter(getFilter(columns));
scan.setFilter(filterList);
scan.setAttribute(Scan.SCAN_ATTRIBUTES_TABLE_NAME,EventLogConstants.HBASE_NAME_EVENT_LOGS.getBytes());
return Arrays.asList(scan);
}
private Filter getFilter(String[] columns) {
int length = columns.length;
byte[][] bts = new byte[length][];
for (int i = 0;i<length;i++){
bts[i] = columns[i].getBytes();
}
return new MultipleColumnPrefixFilter(bts);
}
......
}
启动hadoop和hbase集群
startha.sh
start-hbase.sh
配置执行Runner时传递的参数:
开发其他模块
当需要添加其他模块信息的时候,需要如何修改项目?
- 添加额外的单一维度对象
- 添加维度对象的组合
- 添加对应的 collector 类
- 修改配置文件:
(1) query-mapping.xml添加对应的sql语句
(2) output-collector.xml:添加对应的反射映射。 - 编写 runner,mapper,reducer 类
Hive 和 Hbase 整合
整合配置
https://cwiki.apache.org/confluence/display/Hive/HBaseIntegration
注意事项:
版本信息
Avro Data Stored in HBase Columns
As of Hive 0.9.0 the HBase integration requires at least HBase 0.92, earlier versions of Hive were working with HBase 0.89/0.90
Hive 0.9.0与HBase 0.92兼容。
版本信息
Hive 1.x will remain compatible with HBase 0.98.x and lower versions. Hive 2.x will be compatible with HBase 1.x and higher. (See HIVE-10990 for details.) Consumers wanting to work with HBase 1.x using Hive 1.x will need to compile Hive 1.x stream code themselves.
Hive 1.x仍然和HBase 0.98.x兼容。
HIVE-705 提出的原生支持的 Hive 和 HBase 的整合。可以使用 Hive SQL 语句访问 HBase 的表,包括 SELECT 和 INSERT。甚至让 hive 做 Hive 表和 HBase 表的 join 操作和 union 操作。
需要 jar 包(hive 自带)
hive-hbase-handler-x.y.z.jar
在 hive 的服务端 node2 和 node3 上修改 hive-site.xml 文件:
<property>
<name>hbase.zookeeper.quorum</name>
<value>node2,node3,node4</value>
</property>
然后 node2 和 node3 启动 hive:hiveserver2
启动客户端 CLI:
[root@node4 ~]#beeline
beeline>!connect jdbc:hive2://node2,node3,node4/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk root 123
创建表
要在 hive 中操作 hbase 的表,需要对列进行映射。
CREATE [external] TABLE hbase_table_1(key string, value string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:val")
TBLPROPERTIES ("hbase.table.name" = "xyz",
"hbase.mapred.output.outputtable" = "xyz");
必须指定hbase.columns.mapping属性。
hbase.table.name属性可选,用于指定 hbase 中对应的表名,允许在hive表中使用不同的表名。上例中,hive 中表名为 hbase_table_1,hbase 中表名为 xyz。如果不指定,hive 中的表名与 hbase 中的表名一致。
hbase.mapred.output.outputtable属性可选,向表中插入数据的时候是必须的。该属性的值传递给了hbase.mapreduce.TableOutputFormat使用。
在 hive 表定义中的映射hbase.columns.mapping中的 cf1:val 在创建完表之后, hbase 中只显示 cf1,并不显示 val,因为 val 是行级别的,cf1 才是 hbase 中表级别的元数据。
内部表创建具体操作:
Node4 的 hive 客户端上创建一个表:
CREATE TABLE hbasetbl(key int, value string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:val")
TBLPROPERTIES ("hbase.table.name" = "xyz", "hbase.mapred.output.outputtable" = "xyz");
node1 上连接 hbase shell:
hbase(main):002:0> list
TABLE
......
xyz
hbase(main):006:0> desc "xyz"
Table xyz is ENABLED
xyz
COLUMN FAMILIES DESCRIPTION
{NAME => 'cf1', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'F
ALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', B
LOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
1 row(s) in 0.1210 seconds
hbase 操作:
hbase(main):007:0> put 'xyz','1111','cf1:name','zhangsan'
0 row(s) in 0.1240 seconds
hbase(main):009:0> scan 'xyz'
ROW COLUMN+CELL
1111 column=cf1:name, timestamp=1591109665882, value=zhangsan
1 row(s) in 0.0290 seconds
hive 操作:
0: jdbc:hive2://node2,node3,node4/> select * from hbasetbl;
+---------------+-----------------+--+
| hbasetbl.key | hbasetbl.value |
+---------------+-----------------+--+
+---------------+-----------------+--+
hbase 操作:
hbase(main):010:0> put 'xyz','1111','cf1:val','java'
0 row(s) in 0.0140 seconds
hbase(main):011:0> scan 'xyz'
ROW COLUMN+CELL
1111 column=cf1:name, timestamp=1591109665882, value=zhangsan
1111 column=cf1:val, timestamp=1591109897051, value=java
1 row(s) in 0.0230 seconds
hive 操作:
0: jdbc:hive2://node2,node3,node4/> select * from hbasetbl;
+---------------+-----------------+--+
| hbasetbl.key | hbasetbl.value |
+---------------+-----------------+--+
| 1111 | java |
+---------------+-----------------+--+
hive 操作:
0: jdbc:hive2://node2,node3,node4/> insert into hbasetbl values(2222,'bigdata');
0: jdbc:hive2://node2,node3,node4/> select * from hbasetbl;
+---------------+-----------------+--+
| hbasetbl.key | hbasetbl.value |
+---------------+-----------------+--+
| 1111 | java |
| 2222 | bigdata |
+---------------+-----------------+--+
hbase 操作:
hbase(main):012:0> scan 'xyz'
ROW COLUMN+CELL
1111 column=cf1:name, timestamp=1591109665882, value=zhangsan
1111 column=cf1:val, timestamp=1591109897051, value=java
2222 column=cf1:val, timestamp=1591110155269, value=bigdata
2 row(s) in 0.0540 seconds
http://node2:50070/explorer.html#/hbase_ha/data/default/xyz/d84a55034b6360babbce393733dd9a05/cf1
http://node2:50070/explorer.html#/user/hive_ha/warehouse/hbasetbl
Hbase 操作:
hbase(main):013:0> flush 'xyz'
0 row(s) in 0.2090 seconds
http://node2:50070/explorer.html#/hbase_ha/data/default/xyz/d84a55034b6360babbce393733dd9a05/cf1 http://node2:50070/explorer.html#/user/hive_ha/warehouse/hbasetbl
http://node2:50070/explorer.html#/user/hive_ha/warehouse/hbasetbl
外部表创建
Hive 建立外部表要求 hbase 中必须有表对应,否则抛错
Error: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:MetaException(message:HBase table t_order doesn't exist while the table is declared as an external table.)
hbase 操作
hbase(main):001:0> create 't_order', 'order'
hbase(main):002:0> list
TABLE
......
t_order
Hive 操作:
0: jdbc:hive2://node2,node3,node4/>CREATE EXTERNAL TABLE tmp_order
(key string, id string, user_id string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,order:order_id,order:user_id")
TBLPROPERTIES ("hbase.table.name" = "t_order");
0: jdbc:hive2://node2,node3,node4/> show tables;
+------------+--+
| tab_name |
+------------+--+
| hbasetbl |
| psn |
| tmp_order |
+------------+--+
hbase 操作:
hbase(main):003:0> put 't_order','1','order:order_id','1'
0 row(s) in 0.1480 seconds
hbase(main):004:0> put 't_order','1','order:user_id','101'
0 row(s) in 0.0110 seconds
Hive 操作:
0: jdbc:hive2://node2,node3,node4/> select * from tmp_order;
+----------------+---------------+--------------------+--+
| tmp_order.key | tmp_order.id | tmp_order.user_id |
+----------------+---------------+--------------------+--+
| 1 | 1 | 101 |
+----------------+---------------+--------------------+--+
Hive 操作:
0: jdbc:hive2://node2,node3,node4/> insert into tmp_order values(2,2,102);
......
INFO : MapReduce Total cumulative CPU time: 2 seconds 100 msec
INFO : Ended Job = job_1591154119210_0001
No rows affected (21.495 seconds)
0: jdbc:hive2://node2,node3,node4/> select * from tmp_order;
+----------------+---------------+--------------------+--+
| tmp_order.key | tmp_order.id | tmp_order.user_id |
+----------------+---------------+--------------------+--+
| 1 | 1 | 101 |
| 2 | 2 | 102 |
+----------------+---------------+--------------------+--+
hbase 操作:
hbase(main):005:0> scan 't_order'
ROW COLUMN+CELL
1 column=order:order_id, timestamp=1591155126602, value=1
1 column=order:user_id, timestamp=1591155189515, value=101
2 column=order:order_id, timestamp=1591158641361, value=2
2 column=order:user_id, timestamp=1591158641361, value=102
2 row(s) in 0.0580 seconds
总结:
1、 创建 hive 的内部表,要求 hbase 中不能有对应的表
2、 创建 hive 的外部表,要求 hbase 中一定要有对应的表
3、 映射关系通过
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf:id,cf:username,cf:age")
with serdeproperties
4、 stored by 指定 hive 中存储数据的时候,由该类来处理,该类会将数据放到 hbase 的存储中,同时在 hive 读取数据的时候,由该类负责处理 hbase 的数据和 hive 的对应关系
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
5、指定 hive 表和 hbase 中的哪张表对应,outputtable 负责当 hive insert 数据的时候将数据写到 hbase 的哪张表。
tblproperties ("hbase.table.name" = "my_table",
"hbase.mapred.output.outputtable" = "my_table");
6、如果 hbase 中的表名和 hive 中的表名一致,则可以不指定 tblproperties。
sqoop 介绍+安装+数据导入
Sqoop:将关系数据库(oracle、mysql、sqlserver等)数据与 hadoop 数据进行转换的工具
官网:http://sqoop.apache.org/
版本:(两个版本完全不兼容,sqoop1 使用最多)
sqoop1:1.4.x
sqoop2:1.99.x
同类产品
DataX:阿里顶级数据交换工具
sqoop 架构非常简单,是 hadoop 生态系统的架构最简单的框架。
sqoop1 由 client 端直接接入 hadoop,任务通过解析生成对应的 maprecue 执行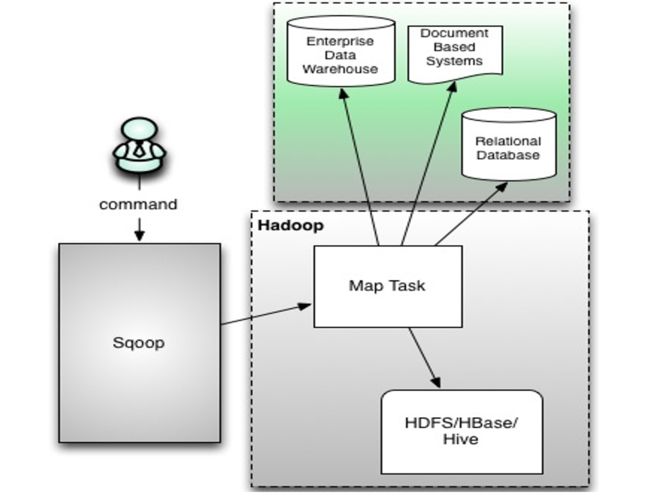
MR 中通过 InputFormat 和 OutputFormat 配置 MR 的输入和输出
sqoop 导入和导出原理:
导入: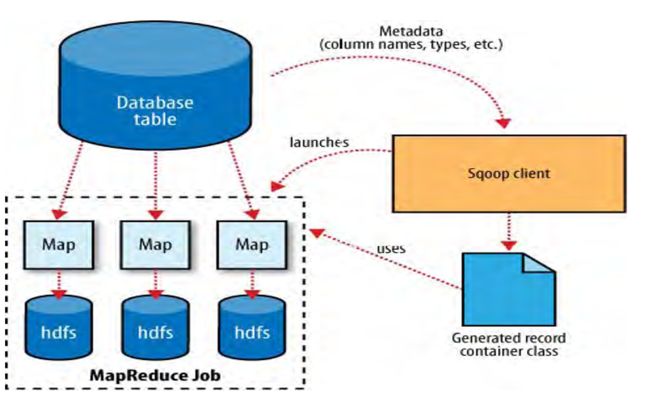
sqoop 导出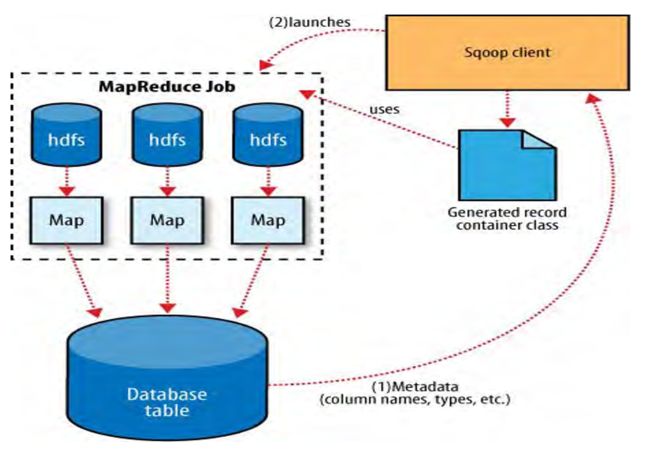
sqoop 安装和测试
选择一台服务器(上面安装过 hive 的服务器 node2,node3 都可以)这里我们选择 node3 安装 sqoop.
- 上传:将 sqoop 安装包上传到 node3 的 /opt/apps 目录
- 解压并改名
[root@node3 opt]# tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /opt/
[root@node3 opt]# ls
apps hadoop-2.6.5 hive-1.2.1 sqoop-1.4.6.bin__hadoop-2.0.4-alpha zookeeper.out
data hbase-0.98 protobuf-2.5.0 zookeeper-3.4.6
[root@node3 opt]# mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha sqoop-1.4.6
- 配置环境变量
[root@node3 opt]# vim /etc/profile
export SQOOP_HOME=/opt/sqoop-1.4.6
export PATH=$PATH:......:$SQOOP_HOME/bin
[root@node3 opt]# source /etc/profile
- 配置
sqoop-env.sh不需要修改
[root@node3 sqoop-1.4.6]# cd conf/
[root@node3 conf]# ls
oraoop-site-template.xml sqoop-env-template.sh sqoop-site.xml
sqoop-env-template.cmd sqoop-site-template.xml
[root@node3 conf]# cp sqoop-env-template.sh sqoop-env.sh
[root@node3 conf]# sqoop version
Warning: /opt/sqoop-1.4.6/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /opt/sqoop-1.4.6/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
20/06/03 12:57:33 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
Sqoop 1.4.6
git commit id c0c5a81723759fa575844a0a1eae8f510fa32c25
Compiled by root on Mon Apr 27 14:38:36 CST 2015
注释掉bin/configure-sqoop中的第134-147行以关闭不必要的警告信息。
测试
[root@node3 bin]# sqoop version
20/06/03 13:05:41 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
Sqoop 1.4.6
git commit id c0c5a81723759fa575844a0a1eae8f510fa32c25
Compiled by root on Mon Apr 27 14:38:36 CST 2015
命令帮助:
[root@node3 bin]# sqoop help
20/06/03 13:07:11 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
usage: sqoop COMMAND [ARGS]
Available commands:
codegen Generate code to interact with database records
create-hive-table Import a table definition into Hive
eval Evaluate a SQL statement and display the results
export Export an HDFS directory to a database table
help List available commands
import Import a table from a database to HDFS
import-all-tables Import tables from a database to HDFS
import-mainframe Import datasets from a mainframe server to HDFS
job Work with saved jobs
list-databases List available databases on a server
list-tables List available tables in a database
merge Merge results of incremental imports
metastore Run a standalone Sqoop metastore
version Display version information
See 'sqoop help COMMAND' for information on a specific command.
sqoop help command
- 添加数据库驱动包
mysql-connector-java-5.1.26-bin.jar
将它上传到node4:/opt/sqoop-1.4.6/lib - 通过 sqoop 命令查询对应 mysql 数据下所有的数据库实例:
查看list-databases对应的选项:
[root@node3 sqoop-1.4.6]# sqoop help list-databases
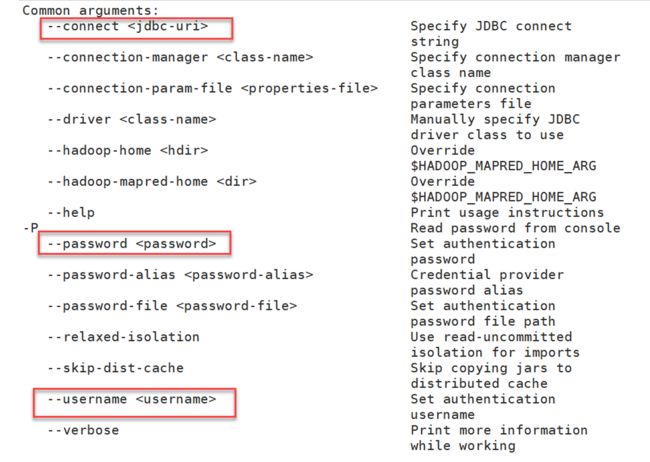
[root@node3 bin]# sqoop list-databases --connect jdbc:mysql://node1:3306/ --username root --password 123456
20/06/03 13:23:19 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
20/06/03 13:23:19 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
20/06/03 13:23:19 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
information_schema
hive
hive_ha
hive_remote
mysql
mytest
performance_schema
result_db
sys
说明已经可以访问 mysql 了。
将sqoop的命令放到文件中:sqoop1.txt
[root@node3 ~]# vim sqoop1.txt
######################
list-databases
--connect
jdbc:mysql://node1:3306
--username
Root
--password
123456
######################
命令行执行:
[root@node3 ~]#sqoop --options-file sqoop1.txt
Sqoop常用操作
命令行导入:
http://sqoop.apache.org/
Table 1. Common arguments
| Argument | Description |
|---|---|
| –connect |
Specify JDBC connect string |
| –connection-manager |
Specify connection manager class to use |
| –driver |
Manually specify JDBC driver class to use |
| –hadoop-mapred-home |
Override $HADOOP_MAPRED_HOME |
| –help | Print usage instructions |
| –password-file | Set path for a file containing the authentication password |
| -P | Read password from console |
| –password |
Set authentication password |
| –username |
Set authentication username |
| –verbose | Print more information while working |
| –connection-param-file |
Optional properties file that provides connection parameters |
| –relaxed-isolation | Set connection transaction isolation to read uncommitted for the mappers. |
Table 3. Import control arguments:
| Argument | Description |
|---|---|
| –append | Append data to an existing dataset in HDFS |
| –as-avrodatafile | Imports data to Avro Data Files |
| –as-sequencefile | Imports data to SequenceFiles |
| –as-textfile | Imports data as plain text (default) |
| –as-parquetfile | Imports data to Parquet Files |
| –boundary-query |
Boundary query to use for creating splits |
| –columns |
Columns to import from table |
| –delete-target-dir | Delete the import target directory if it exists |
| –direct | Use direct connector if exists for the database |
| –fetch-size |
Number of entries to read from database at once. |
| –inline-lob-limit |
Set the maximum size for an inline LOB |
| -m,–num-mappers |
Use n map tasks to import in parallel |
| -e,–query |
Import the results of statement. |
| –split-by |
Column of the table used to split work units. Cannot be used with–autoreset-to-one-mapper option. |
| –autoreset-to-one-mapper | Import should use one mapper if a table has no primary key and no split-by column is provided. Cannot be used with --split-by |
| –table |
Table to read |
| –target-dir |
HDFS destination dir |
| –warehouse-dir |
HDFS parent for table destination |
| –where |
WHERE clause to use during import |
| -z,–compress | Enable compression |
| –compression-codec |
Use Hadoop codec (default gzip) |
| –null-string |
The string to be written for a null value for string columns |
| –null-non-string |
The string to be written for a null value for non-string columns |
从 MySQL 导数据到 HDFS,导入:
[root@node3 ~]#sqoop import \
--connect jdbc:mysql://node1/result_db \
--username root \
--password 123456 \
--as-textfile \
--table dimension_browser \
--columns id,browser_name,browser_version \
--target-dir /sqoop/command \
--delete-target-dir \
-m 1
将语句写入文件并运行:
vim sqoop2.txt
import
--connect
jdbc:mysql://node1/result_db
--username
root
--password
123456
--as-textfile
--table
dimension_browser
--columns
id,browser_name,browser_version
--target-dir
/sqoop/file2
--delete-target-dir
-m
1
命令行:
sqoop --options-file sqoop2.txt
可以指定 SQL 执行导入:
[root@node3 ~]# cp sqoop2.txt sqoop3.txt
[root@node3 ~]# vim sqoop3.txt
sqoop3.txt
import
--connect
jdbc:mysql://node1/result_db
--username
root
--password
123456
--as-textfile
--target-dir
/sqoop/file3
--delete-target-dir
-m
1
-e
select id,browser_name,browser_version from dimension_browser
命令行:
sqoop --options-file sqoop3.txt
抛出错误:
IOException: Query [select id,browser_name,browser_version from dimension_browser] must contain '$CONDITIONS' in WHERE clause
修改sqoop3.txt文件,在指定的 sql 语句后面添加where $CONDITIONS
......
select id,browser_name,browser_version from dimension_browser where $CONDITIONS
命令行:
sqoop --options-file sqoop3.txt
指定导出文件的分隔符:
[root@node3 ~]# cp sqoop3.txt sqoop4.txt
[root@node3 ~]# vim sqoop4.txt
import
--connect
jdbc:mysql://node1/result_db
--username
root
--password
123456
--as-textfile
--target-dir
/sqoop/file4
--delete-target-dir
-m
1
-e
select id,browser_name,browser_version from dimension_browser where $CONDITIONS
--fields-terminated-by
\t
命令行:
[root@node3 ~]#sqoop --options-file sqoop4.txt
[root@node3 ~]#hdfs dfs -cat /sqoop/file4/part-m-00000
1 360 0
2 360 1
3 360 2
......
导入到 HIVE 创建表
Table 8. Hive arguments:
| Argument | Description |
|---|---|
| –hive-home |
Override $HIVE_HOME |
| –hive-import | Import tables into Hive (Uses Hive’s default delimiters if none are set.) |
| –hive-overwrite | Overwrite existing data in the Hive table. |
| –create-hive-table | If set, then the job will fail if the target hive table exits. By default this property is false. |
| –hive-table |
Sets the table name to use when importing to Hive. |
| –hive-drop-import-delims | Drops \n, \r, and \01 from string fields when importing to Hive. |
| –hive-delims-replacement | Replace \n, \r, and \01 from string fields with user defined string when importing to Hive. |
| –hive-partition-key | Name of a hive field to partition are sharded on |
| –hive-partition-value |
String-value that serves as partition key for this imported into hive in this job. |
| –map-column-hive | Override default mapping from SQL type to Hive type for configured columns. |
默认字段的分隔符就是逗号,可以不指定逗号
sqoop5.txt
import
--connect
jdbc:mysql://node1/result_db
--username
root
--password
123456
--as-textfile
-m
1
-e
select id, browser_name, browser_version from dimension_browser where $CONDITIONS and id>20
--hive-import
--create-hive-table
--hive-table
hive_browser_dim
--target-dir
/my/tmp
--delete-target-dir
--fields-terminated-by
,
Node2 和 node3 启动 hiveserver2 执行:
nohup hiveserver2 &
node3 命令行:
sqoop --options-file sqoop5.txt
node4:
beeline
!connect jdbc:hive2://node2,node3,node4/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk root 123
0: jdbc:hive2://node2,node3,node4/> dfs -cat /user/hive_ha/warehouse/hive_browser_dim/*;
+-----------------+--+
| DFS Output |
+-----------------+--+
| 21,FireFox,0 |
| 22,FireFox,1 |
| 23,FireFox,2 |
| 24,FireFox,3 |
| 25,FireFox,4 |
注意:如果写成命令行的行,其中 sql 语句要使用单引号。
sqoop import --connect jdbc:mysql://node1/result_db --username root --password 123456 --as-textfile -m 1 -e 'select id, browser_name, browser_version from dimension_browser where $CONDITIONS and id<=20' --hive-import --create-hive-table --hive-table hive_browser_dim --target-dir /my/tmp --delete-target-dir --fields-terminated-by '\t'
导出数据到 mysql:
http://sqoop.apache.org/docs/1.4.6/SqoopUserGuide.html#_literal_sqoop_export_literal
vim sqoop6.txt
export
--connect
jdbc:mysql://node1:3306/test
--username
root
--password
123456
-m
1
--columns
id,browser_name,browser_version
--export-dir
/user/hive_ha/warehouse/hive_browser_dim
--table
hive_browser_dim
[root@node3 ~]# sqoop --options-file sqoop6.txt
rorException: Table 'test.hive_browser_dim' doesn't exist
com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Table 'test.hive_browser_dim' doesn't exist
创建表
create table `test`.`hive_browser_dim`(
`id` int ,
`browser_name` varchar(100) ,
`browser_version` varchar(100)
);
[root@node3 ~]# sqoop --options-file sqoop6.txt
由于文件默认使用,分割各个字段,sqoop 导出的时候默认也是使用,分割。逗号不需要指定分隔符。
默认的 hive 分隔符:
默认的 hive 分隔符也需要在 sqoop 文件中指定分隔符 \001。
删除 test 库下的 hive_browser_dim 表中的所有数据:
TRUNCATE hive_browser_dim;
vim sqoop7.txt
export
--connect
jdbc:mysql://node1/test
--username
root
--password
123456
-m
1
--columns
id,browser_name,browser_version
--export-dir
/user/hive_ha/warehouse/hive_browser_dim
--table
hive_browser_dim
--input-fields-terminated-by
\001
[root@node3 ~]# sqoop --options-file sqoop7.txt
用户浏览深度 SQL 分析
需求:
将用户访问 e_pv 日志按照平台、日期、u_ud 进行分组,每组有多少个p_url?
MySQL 中的stat_view_depth表![]()
分析需要的字段: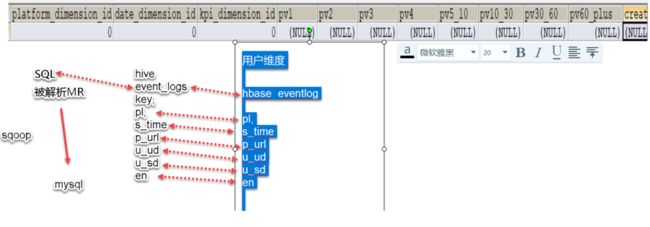
在 hive 中创建 hbase 的 eventlog 对应表
CREATE EXTERNAL TABLE event_logs(
key string, pl string, en string, s_time bigint, p_url string, u_ud string, u_sd string
) ROW FORMAT SERDE 'org.apache.hadoop.hive.hbase.HBaseSerDe'
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties('hbase.columns.mapping'=':key,log:pl,log:en,log:s_time,log:p_url,log:u_ud,log:u_sd')
tblproperties('hbase.table.name'='eventlog');
0: jdbc:hive2://node2,node3,node4/> select * from event_logs;
4,000 rows selected (3.312 seconds)
站在统计用户的角度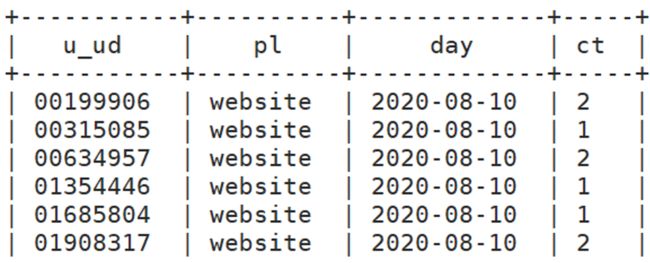
select u_ud,pl,from_unixtime(cast(s_time/1000 as bigint),'yyyy-MM-dd') day ,count(p_url) ct
from event_logs
where en = 'e_pv'
and p_url is not null
and pl is not null
and s_time >=unix_timestamp('2020-08-10','yyyy-MM-dd')*1000
and s_time < unix_timestamp('2020-08-11','yyyy-MM-dd')*1000
group by pl,u_ud,from_unixtime(cast(s_time/1000 as bigint),'yyyy-MM-dd');
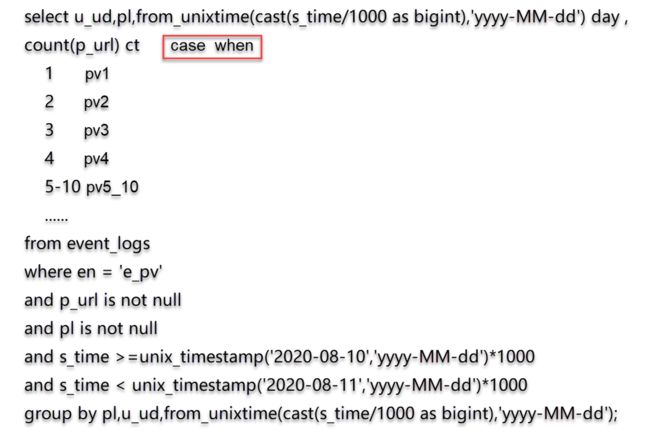
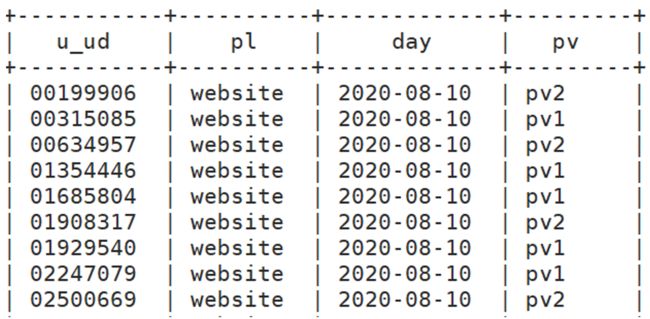
select
pl, from_unixtime(cast(s_time/1000 as bigint),'yyyy-MM-dd') as day, u_ud,
(case when count(p_url) = 1 then "pv1"
when count(p_url) = 2 then "pv2"
when count(p_url) = 3 then "pv3"
when count(p_url) = 4 then "pv4"
when count(p_url) >= 5 and count(p_url) <10 then "pv5_10"
when count(p_url) >= 10 and count(p_url) <30 then "pv10_30"
when count(p_url) >=30 and count(p_url) <60 then "pv30_60"
else 'pv60_plus' end) as pv
from event_logs
where
en='e_pv'
and p_url is not null
and pl is not null
and s_time >= unix_timestamp('2020-08-10','yyyy-MM-dd')*1000
and s_time < unix_timestamp('2020-08-11','yyyy-MM-dd')*1000
group by
pl, from_unixtime(cast(s_time/1000 as bigint),'yyyy-MM-dd'), u_ud;
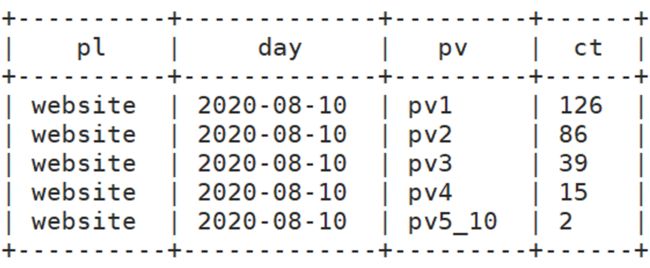
select pl,day,pv,count(u_ud) as ct
from (
select
pl, from_unixtime(cast(s_time/1000 as bigint),'yyyy-MM-dd') as day, u_ud,
(case when count(p_url) = 1 then "pv1"
when count(p_url) = 2 then "pv2"
when count(p_url) = 3 then "pv3"
when count(p_url) = 4 then "pv4"
when count(p_url) >= 5 and count(p_url) <10 then "pv5_10"
when count(p_url) >= 10 and count(p_url) <30 then "pv10_30"
when count(p_url) >=30 and count(p_url) <60 then "pv30_60"
else 'pv60_plus' end) as pv
from event_logs
where
en='e_pv'
and p_url is not null
and pl is not null
and s_time >= unix_timestamp('2020-08-10','yyyy-MM-dd')*1000
and s_time < unix_timestamp('2020-08-11','yyyy-MM-dd')*1000
group by
pl, from_unixtime(cast(s_time/1000 as bigint),'yyyy-MM-dd'), u_ud) tmp
where u_ud is not null group by pl,day,pv;
在 hive 中创建 mysql 的对应表
hive 中的表,执行 HQL 之后分析的结果保存该表,然后通过 sqoop 工具导出到 mysql
CREATE TABLE `stats_view_depth` (
`platform_dimension_id` bigint ,
`date_dimension_id` bigint ,
`kpi_dimension_id` bigint ,
`pv1` bigint ,
`pv2` bigint ,
`pv3` bigint ,
`pv4` bigint ,
`pv5_10` bigint ,
`pv10_30` bigint ,
`pv30_60` bigint ,
`pv60_plus` bigint ,
`created` string
) row format delimited fields terminated by '\t';
hive 创建临时表
把 hql 分析之后的中间结果存放到当前的临时表。
CREATE TABLE `stats_view_depth_tmp`(`pl` string, `date` string, `col` string, `ct` bigint);
pl平台
date日期
col列,值对应于mysql表中的列:pv1,pv2,pv4….
ct对应于每列的值
col对应mysql中的pv前缀列。
from (
select
pl, from_unixtime(cast(s_time/1000 as bigint),'yyyy-MM-dd') as day, u_ud,
(case when count(p_url) = 1 then "pv1"
when count(p_url) = 2 then "pv2"
when count(p_url) = 3 then "pv3"
when count(p_url) = 4 then "pv4"
when count(p_url) >= 5 and count(p_url) <10 then "pv5_10"
when count(p_url) >= 10 and count(p_url) <30 then "pv10_30"
when count(p_url) >=30 and count(p_url) <60 then "pv30_60"
else 'pv60_plus' end) as pv
from event_logs
where
en='e_pv'
and p_url is not null
and pl is not null
and s_time >= unix_timestamp('2020-08-10','yyyy-MM-dd')*1000
and s_time < unix_timestamp('2020-08-11','yyyy-MM-dd')*1000
group by
pl, from_unixtime(cast(s_time/1000 as bigint),'yyyy-MM-dd'), u_ud
) as tmp
insert overwrite table stats_view_depth_tmp
select pl,day,pv,count(u_ud) as ct where u_ud is not null group by pl,day,pv;
select pl,`date`,col,ct from stats_view_depth_tmp;
注意:date 是关键字避免出错加上了反引号。
如何将表stats_view_depth_tmp中的数据添加到stats_view_depth表,需要用到行转列。
hql 编写(统计用户角度的浏览深度)<注意:时间为外部给定>
行转列 -> 结果
–把临时表的多行数据,转换一行
| std | prj | score |
|---|---|---|
| S1 | M | 100 |
| S1 | E | 98 |
| S1 | Z | 80 |
| S2 | M | 87 |
| S2 | E | 88 |
| S2 | Z | 89 |
转换后:
| std | M | E | Z |
|---|---|---|---|
| S1 | 100 | 98 | 80 |
| S2 | 87 | 88 | 89 |
采用 join 方式:
select std, score as M from my_score where prj='M';
select std, score as E from my_score where prj='E';
select std, score as Z from my_score where prj='Z';
select t1.std, t1.score, t2.score, t3.score from t1 join t2 on t1.std=t2.std
join t3 on t1.std=t3.std;
SELECT t1.std, t1.score, t2.score, t3.score
from
(select std, score from my_score where prj='M') t1
join
(select std, score from my_score where prj='E') t2
on t1.std=t2.std
join (select std, score from my_score where prj='Z') t3
on t1.std=t3.std;
采用 union all 的方式:
select tmp.std, sum(tmp.M), sum(tmp.E), sum(tmp.Z) from (
select std, score as 'M', 0 as 'E', 0 as 'Z' from tb_score where prj='M' UNION ALL
select std, 0 as 'M', score as 'E', 0 as 'Z' from tb_score where prj='E' UNION ALL
select std, 0 as 'M', 0 as 'E', score as 'Z' from tb_score where prj='Z'
) tmp group by tmp.std;
S1 100 0 0
S1 0 98 0
S1 0 0 80
S1 100 98 80

pl date pv1 pv2 pv3 pv4 pv5_10 pv10_30 pv30_60 pv60_plus
website 2020-08-10 126 0 0 0 0 0 0
website 2020-08-10 0 86 0 0 0 0 0
website 2020-08-10 0 0 39 0 0 0 0
website 2020-08-10 0 0 0 15 0 0 0
website 2020-08-10 0 0 0 0 2 0 0
all 2020-08-10 126 0 0 0 0 0 0
all 2020-08-10 0 86 0 0 0 0 0
all 2020-08-10 0 0 39 0 0 0 0
all 2020-08-10 0 0 0 15 0 0 0
all 2020-08-10 0 0 0 0 2 0 0
with tmp as
(
select pl,`date` as date1,ct as pv1,0 as pv2,0 as pv3,0 as pv4,0 as pv5_10,0 as pv10_30,0 as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv1' union all
select pl,`date` as date1,0 as pv1,ct as pv2,0 as pv3,0 as pv4,0 as pv5_10,0 as pv10_30,0 as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv2' union all
select pl,`date` as date1,0 as pv1,0 as pv2,ct as pv3,0 as pv4,0 as pv5_10,0 as pv10_30,0 as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv3' union all
select pl,`date` as date1,0 as pv1,0 as pv2,0 as pv3,ct as pv4,0 as pv5_10,0 as pv10_30,0 as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv4' union all
select pl,`date` as date1,0 as pv1,0 as pv2,0 as pv3,0 as pv4,ct as pv5_10,0 as pv10_30,0 as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv5_10' union all
select pl,`date` as date1,0 as pv1,0 as pv2,0 as pv3,0 as pv4,0 as pv5_10,ct as pv10_30,0 as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv10_30' union all
select pl,`date` as date1,0 as pv1,0 as pv2,0 as pv3,0 as pv4,0 as pv5_10,0 as pv10_30,ct as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv30_60' union all
select pl,`date` as date1,0 as pv1,0 as pv2,0 as pv3,0 as pv4,0 as pv5_10,0 as pv10_30,0 as pv30_60,ct as pv60_plus from stats_view_depth_tmp where col='pv60_plus' union all
select 'all' as pl,`date` as date1,ct as pv1,0 as pv2,0 as pv3,0 as pv4,0 as pv5_10,0 as pv10_30,0 as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv1' union all
select 'all' as pl,`date` as date1,0 as pv1,ct as pv2,0 as pv3,0 as pv4,0 as pv5_10,0 as pv10_30,0 as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv2' union all
select 'all' as pl,`date` as date1,0 as pv1,0 as pv2,ct as pv3,0 as pv4,0 as pv5_10,0 as pv10_30,0 as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv3' union all
select 'all' as pl,`date` as date1,0 as pv1,0 as pv2,0 as pv3,ct as pv4,0 as pv5_10,0 as pv10_30,0 as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv4' union all
select 'all' as pl,`date` as date1,0 as pv1,0 as pv2,0 as pv3,0 as pv4,ct as pv5_10,0 as pv10_30,0 as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv5_10' union all
select 'all' as pl,`date` as date1,0 as pv1,0 as pv2,0 as pv3,0 as pv4,0 as pv5_10,ct as pv10_30,0 as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv10_30' union all
select 'all' as pl,`date` as date1,0 as pv1,0 as pv2,0 as pv3,0 as pv4,0 as pv5_10,0 as pv10_30,ct as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv30_60' union all
select 'all' as pl,`date` as date1,0 as pv1,0 as pv2,0 as pv3,0 as pv4,0 as pv5_10,0 as pv10_30,0 as pv30_60,ct as pv60_plus from stats_view_depth_tmp where col='pv60_plus'
)
from tmp
insert overwrite table stats_view_depth
select 2,3,1,sum(pv1),sum(pv2),sum(pv3),sum(pv4),sum(pv5_10),sum(pv10_30),sum(pv30_60),sum(pv60_plus),'2020-08-10' group by pl,date1;
编写 UDF 获取 2,3,1 的值,2,3,1 是一个假的数据。
编写 UDF
(datedimension & platformdimension )两个维度
package com.sxt.transformer.hive;
import java.io.IOException;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import com.sxt.common.DateEnum;
import com.sxt.transformer.model.dim.base.DateDimension;
import com.sxt.transformer.service.IDimensionConverter;
import com.sxt.transformer.service.impl.DimensionConverterImpl;
import com.sxt.util.TimeUtil;
/**操作日期dimension 相关的udf
* @author root
*/
public class DateDimensionUDF extends UDF {
private IDimensionConverter converter = new DimensionConverterImpl();
/**
* 根据给定的日期(格式为:yyyy-MM-dd)至返回id
* @param day
* @return
*/
public IntWritable evaluate(Text day) {
DateDimension dimension = DateDimension.buildDate(TimeUtil.parseString2Long(day.toString()), DateEnum.DAY);
try {
int id = this.converter.getDimensionIdByValue(dimension);
System.out.println(day.toString());
System.out.println(id);
return new IntWritable(id);
} catch (IOException e) {
throw new RuntimeException("获取id异常" + day.toString());
}
}
}
package com.sxt.transformer.hive;
import com.sxt.common.DateEnum;
import com.sxt.transformer.model.dim.base.DateDimension;
import com.sxt.transformer.model.dim.base.PlatformDimension;
import com.sxt.transformer.service.IDimensionConverter;
import com.sxt.transformer.service.impl.DimensionConverterImpl;
import com.sxt.util.TimeUtil;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import java.io.IOException;
/**
* 操作平台dimension 相关的udf
* @author root
*/
public class PlatformDimensionUDF extends UDF {
private IDimensionConverter converter = new DimensionConverterImpl();
/**
* 根据给定的platform名称返回id
* @param platform
* @return
*/
public IntWritable evaluate(Text platform) {
PlatformDimension dimension = new PlatformDimension(platform.toString());
try {
int id = this.converter.getDimensionIdByValue(dimension);
return new IntWritable(id);
} catch (IOException e) {
throw new RuntimeException("获取id异常");
}
}
}
上传
打包
hivejar.jar 上传到 hdfs 的 /sxt/transformer 文件夹中
创建 hive 的 function
create function dateFunc as 'com.sxt.transformer.hive.DateDimensionUDF' using jar 'hdfs://mycluster/sxt/transformer/hivejar.jar';
3-> dateFunc(date1)
create function platformFunc as 'com.sxt.transformer.hive.PlatformDimensionUDF' using jar 'hdfs://mycluster/sxt/transformer/hivejar.jar';
2-> platformFunc(pl)
清空 hive 中的 stats_view_depth 表中的数据:
truncate table stats_view_depth;
然后再执行替换后的 sql 语句。
sqoop 脚本编写(统计用户角度)
[root@node3 ~]# cp sqoop8.txt sqoopD1
[root@node3 ~]# vim sqoopD1
export
--connect
jdbc:mysql://node1/result_db
--username
root
--password
123456
-m
1
--columns
platform_dimension_id,date_dimension_id,kpi_dimension_id,pv1,pv2,pv3,pv4,pv5_10,pv10_30,pv30_60,pv60_plus,created
--export-dir
/user/hive_ha/warehouse/stats_view_depth
--table
stats_view_depth
执行:
sqoop --options-file sqoopD1
抛错:
Caused by: java.lang.RuntimeException: Can't parse input data: '2 3 6 128 85 40 18 3 0 0 0 2020-08-10'
这是因为 hive 的 stats_view_depth 表的分隔符使用的 \t , 需要指定一下,修改sqoopD1 文件:
[root@node3 ~]# vim sqoopD1
export
--connect
jdbc:mysql://node1/result_db
--username
root
--password
123456
-m
1
--columns
platform_dimension_id,date_dimension_id,kpi_dimension_id,pv1,pv2,pv3,pv4,pv5_10,pv10_30,pv30_60,pv60_plus,created
--table
stats_view_depth
--export-dir
/user/hive_ha/warehouse/stats_view_depth
--input-fields-terminated-by
\t
站在会话角度的浏览深度
hql 编写(统计会话角度的浏览深度) <注意:时间为外部给定>
from (
select pl, from_unixtime(cast(s_time/1000 as bigint),'yyyy-MM-dd') as day, u_sd,
(case when count(p_url) = 1 then "pv1"
when count(p_url) = 2 then "pv2"
when count(p_url) = 3 then "pv3"
when count(p_url) = 4 then "pv4"
when count(p_url) >= 5 and count(p_url) <10 then "pv5_10"
when count(p_url) >= 10 and count(p_url) <30 then "pv10_30"
when count(p_url) >=30 and count(p_url) <60 then "pv30_60"
else 'pv60_plus' end) as pv
from event_logs
where en='e_pv' and p_url is not null and pl is not null and s_time >= unix_timestamp('2020-09-10','yyyy-MM-dd')*1000 and s_time < unix_timestamp('2020-09-11','yyyy-MM-dd')*1000
group by pl, from_unixtime(cast(s_time/1000 as bigint),'yyyy-MM-dd'), u_sd
) as tmp
insert overwrite table stats_view_depth_tmp
select pl,day,pv,count(distinct u_sd) as ct where u_sd is not null group by pl,day,pv;
with tmp as
(
select pl,date,ct as pv1,0 as pv2,0 as pv3,0 as pv4,0 as pv5_10,0 as pv10_30,0 as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv1' union all
select pl,date,0 as pv1,ct as pv2,0 as pv3,0 as pv4,0 as pv5_10,0 as pv10_30,0 as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv2' union all
select pl,date,0 as pv1,0 as pv2,ct as pv3,0 as pv4,0 as pv5_10,0 as pv10_30,0 as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv3' union all
select pl,date,0 as pv1,0 as pv2,0 as pv3,ct as pv4,0 as pv5_10,0 as pv10_30,0 as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv4' union all
select pl,date,0 as pv1,0 as pv2,0 as pv3,0 as pv4,ct as pv5_10,0 as pv10_30,0 as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv5_10' union all
select pl,date,0 as pv1,0 as pv2,0 as pv3,0 as pv4,0 as pv5_10,ct as pv10_30,0 as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv10_30' union all
select pl,date,0 as pv1,0 as pv2,0 as pv3,0 as pv4,0 as pv5_10,0 as pv10_30,ct as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv30_60' union all
select pl,date,0 as pv1,0 as pv2,0 as pv3,0 as pv4,0 as pv5_10,0 as pv10_30,0 as pv30_60,ct as pv60_plus from stats_view_depth_tmp where col='pv60_plus' union all
select 'all' as pl,date,ct as pv1,0 as pv2,0 as pv3,0 as pv4,0 as pv5_10,0 as pv10_30,0 as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv1' union all
select 'all' as pl,date,0 as pv1,ct as pv2,0 as pv3,0 as pv4,0 as pv5_10,0 as pv10_30,0 as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv2' union all
select 'all' as pl,date,0 as pv1,0 as pv2,ct as pv3,0 as pv4,0 as pv5_10,0 as pv10_30,0 as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv3' union all
select 'all' as pl,date,0 as pv1,0 as pv2,0 as pv3,ct as pv4,0 as pv5_10,0 as pv10_30,0 as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv4' union all
select 'all' as pl,date,0 as pv1,0 as pv2,0 as pv3,0 as pv4,ct as pv5_10,0 as pv10_30,0 as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv5_10' union all
select 'all' as pl,date,0 as pv1,0 as pv2,0 as pv3,0 as pv4,0 as pv5_10,ct as pv10_30,0 as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv10_30' union all
select 'all' as pl,date,0 as pv1,0 as pv2,0 as pv3,0 as pv4,0 as pv5_10,0 as pv10_30,ct as pv30_60,0 as pv60_plus from stats_view_depth_tmp where col='pv30_60' union all
select 'all' as pl,date,0 as pv1,0 as pv2,0 as pv3,0 as pv4,0 as pv5_10,0 as pv10_30,0 as pv30_60,ct as pv60_plus from stats_view_depth_tmp where col='pv60_plus'
)
from tmp
insert overwrite table stats_view_depth
select platformFunc(pl),dateFunc(`date`),2,sum(pv1),sum(pv2),sum(pv3),sum(pv4),sum(pv5_10),sum(pv10_30),sum(pv30_60),sum(pv60_plus),'2020-09-10' group by pl,date;
编写 sqoop 脚本将 hive 中 stats_view_depth 表中的数据导出到 mysql 数据的stats_view_depth。
shell 脚本编写
view_depth_run.sh
项目优化
调优的目的
充分的利用机器的性能,更快的完成 mr 程序的计算任务。甚至是在有限的机器条件下,能够支持运行足够多的 mr 程序。
调优的总体概述
从 mr 程序的内部运行机制,我们可以了解到一个 mr 程序由 mapper 和 reducer 两个阶段组成,其中 mapper 阶段包括数据的读取、map 处理以及写出操作(排序和合并/sort&merge),而 reducer 阶段包含 mapper 输出数据的获取、数据合并(sort & merge)、reduce 处理以及写出操作。那么在这七个子阶段中,能够进行较大力度的进行调优的就是 map 输出、reducer 数据合并以及 reducer 个数这三个方面的调优操作。也就是说虽然性能调优包括 cpu、内存、磁盘 io 以及网络这四个大方面,但是从 mr 程序的执行流程中,我们可以知道主要有调优的是内存、磁盘 io 以及网络。在 mr 程序中调优,主要考虑的就是减少网络传输和减少磁盘 IO 操作,故本次课程的 mr 调优主要包括服务器调优、代码调优、mapper 调优、reducer 调优以及 runner 调优这五个方面。
服务器调优
服务器调优主要包括服务器参数调优和 jvm 调优。在本次项目中,由于我们使用 hbase 作为我们分析数据的原始数据存储表,所以对于 hbase 我们也需要进行一些调优操作。除了参数调优之外,和其他一般的 java 程序一样,还需要进行一些 jvm 调优。
hdfs 调优
1. dfs.datanode.failed.volumes.tolerated: 允许发生磁盘错误的磁盘数量,默认为0,表示不允许datanode发生磁盘异常。当挂载多个磁盘的时候,可以修改该值。
2. dfs.replication: 复制因子,默认3
3. dfs.namenode.handler.count: namenode节点并发线程量,默认10
4. dfs.datanode.handler.count:datanode之间的并发线程量,默认10。
5. dfs.datanode.max.transfer.threads:datanode提供的数据流操作的并发线程量,默认4096。
一般将其设置为linux系统的文件句柄数的85%~90%之间,查看文件句柄数语句ulimit -a,修改vim /etc/security/limits.conf, 不能设置太大
文件末尾,添加
* soft nofile 65535
* hard nofile 65535
注意:句柄数不能够太大,可以设置为1000000以下的所有数值,一般不设置为-1。
异常处理:当设置句柄数较大的时候,重新登录可能出现unable load session的提示信息,这个时候采用单用户模式进行修改操作即可。
单用户模式:
启动的时候按'a'键,进入选择界面,然后按'e'键进入kernel修改界面,然后选择第二行'kernel...',按'e'键进行修改,在最后添加空格+single即可,按回车键回到修改界面,最后按'b'键进行单用户模式启动,当启动成功后,还原文件后保存,最后退出(exit)重启系统即可。
6. io.file.buffer.size: 读取/写出数据的buffer大小,默认4096,一般不用设置,推荐设置为4096的整数倍(物理页面的整数倍大小)。
hbase 调优
1. 设置 regionserver 的内存大小,默认为 1g,推荐设置为 4g。
修改conf/hbase-env.sh中的HBASE_HEAPSIZE=4g
2. hbase.regionserver.handler.count: 修改客户端并发线程数,默认为10。设置规则为,当put和scans操作比较的多的时候,将其设置为比较小的值;当get和delete操作比较多的时候,将其设置为比较大的值。原因是防止频繁GC操作导致内存异常。
3. 自定义hbase的分割和紧缩操作,默认情况下hbase的分割机制是当region大小达到hbase.hregion.max.filesize(10g)的时候进行自动分割,推荐每个regionserver的region个数在20~500个为最佳。hbase的紧缩机制是hbase的一个非常重要的管理机制,hbase的紧缩操作是非常消耗内存和cpu的,所以一般机器压力比较大的话,推荐将其关闭,改为手动控制。
4. hbase.balancer.period: 设置hbase的负载均衡时间,默认为300000(5分钟),在负载比较高的集群上,将其值可以适当的改大。
5. hfile.block.cache.size:修改hflie文件块在内存的占比,默认0.4。在读应用比较多的系统中,可以适当的增大该值,在写应用比较多的系统中,可以适当的减少该值,不过不推荐修改为0。
6. hbase.regionserver.global.memstore.upperLimit:修改memstore的内存占用比率上限,默认0.4,当达到该值的时候,会进行flush操作将内容写的磁盘中。
7. hbase.regionserver.global.memstore.lowerLimit: 修改memstore的内存占用比率下限,默认0.38,进行flush操作后,memstore占用的内存比率必须不大于该值。
8. hbase.hregion.memstore.flush.size: 当memstore的值大于该值的时候,进行flush操作。默认134217728(128M)。
9. hbase.hregion.memstore.block.multiplier: 修改memstore阻塞块大小比率值,默认为4。也就是说在memstore的大小超过4*hbase.hregion.memstore.flush.size的时候就会触发写阻塞操作。
mapreduce 调优
1. mapreduce.task.io.sort.factor: mr程序进行合并排序的时候,打开的文件数量,默认为10个.
2. mapreduce.task.io.sort.mb: mr程序进行合并排序操作的时候或者mapper写数据的时候,内存大小,默认100M
3. mapreduce.map.sort.spill.percent: mr程序进行flush操作的阀值,默认0.80。
4. mapreduce.reduce.shuffle.parallelcopies:mr程序reducer copy数据的线程数,默认5。
5. mapreduce.reduce.shuffle.input.buffer.percent: reduce复制map数据的时候指定的内存堆大小百分比,默认为0.70,适当的增加该值可以减少map数据的磁盘溢出,能够提高系统性能。
6. mapreduce.reduce.shuffle.merge.percent:reduce进行shuffle的时候,用于启动合并输出和磁盘溢写的过程的阀值,默认为0.66。如果允许,适当增大其比例能够减少磁盘溢写次数,提高系统性能。同mapreduce.reduce.shuffle.input.buffer.percent一起使用。
7. mapreduce.task.timeout:mr程序的task执行情况汇报过期时间,默认600000(10分钟),设置为0表示不进行该值的判断。
代码调优
代码调优,主要是mapper和reducer中,针对多次创建的对象,进行代码提出操作。这个和一般的java程序的代码调优一样。
mapper 调优
mapper调优主要就是就一个目标:减少输出量。我们可以通过增加combine阶段以及对输出进行压缩设置进行mapper调优。
combine介绍:
实现自定义combine要求继承reducer类,特点:
以map的输出key/value键值对作为输入输出键值对,作用是减少网络输出,在map节点上就合并一部分数据。
比较适合,map的输出是数值型的,方便进行统计。
压缩设置:
在提交job的时候分别设置启动压缩和指定压缩方式。
reducer 调优
reducer调优主要是通过参数调优和设置reducer的个数来完成。
reducer个数调优:
要求:一个reducer和多个reducer的执行结果一致,不能因为多个reducer导致执行结果异常。
规则:一般要求在hadoop集群中的执行mr程序,map执行完成100%后,尽量早的看到reducer执行到33%,可以通过命令hadoop job -status job_id或者web页面来查看。
原因: map的执行process数是通过inputformat返回recordread来定义的;而reducer是有三部分构成的,分别为读取mapper输出数据、合并所有输出数据以及reduce处理,其中第一步要依赖map的执行,所以在数据量比较大的情况下,一个reducer无法满足性能要求的情况下,我们可以通过调高reducer的个数来解决该问题。
优点:充分利用集群的优势。
缺点:有些mr程序没法利用多reducer的优点,比如获取top n的mr程序。
runner 调优
runner调优其实就是在提交job的时候设置job参数,一般都可以通过代码和xml文件两种方式进行设置。
1~8详见ActiveUserRunner(before和configure方法),9详解TransformerBaseRunner(initScans方法)
1. mapred.child.java.opts: 修改childyard进程执行的jvm参数,针对map和reducer均有效,默认:-Xmx200m
2. mapreduce.map.java.opts: 需改map阶段的childyard进程执行jvm参数,默认为空,当为空的时候,使用mapred.child.java.opts。
3. mapreduce.reduce.java.opts:修改reducer阶段的childyard进程执行jvm参数,默认为空,当为空的时候,使用mapred.child.java.opts。
4. mapreduce.job.reduces: 修改reducer的个数,默认为1。可以通过job.setNumReduceTasks方法来进行更改。
5. mapreduce.map.speculative:是否启动map阶段的推测执行,默认为true。其实一般情况设置为false比较好。可通过方法job.setMapSpeculativeExecution来设置。
6. mapreduce.reduce.speculative:是否需要启动reduce阶段的推测执行,默认为true,其实一般情况设置为fase比较好。可通过方法job.setReduceSpeculativeExecution来设置。
7. mapreduce.map.output.compress:设置是否启动map输出的压缩机制,默认为false。在需要减少网络传输的时候,可以设置为true。
8. mapreduce.map.output.compress.codec:设置map输出压缩机制,默认为org.apache.hadoop.io.compress.DefaultCodec,推荐使用SnappyCodec(在之前版本中需要进行安装操作,现在版本不太清楚,安装参数:http://www.cnblogs.com/chengxin1982/p/3862309.html)
9. hbase参数设置
由于hbase默认是一条一条数据拿取的,在mapper节点上执行的时候是每处理一条数据后就从hbase中获取下一条数据,通过设置cache值可以一次获取多条数据,减少网络数据传输。
架构设计与项目总结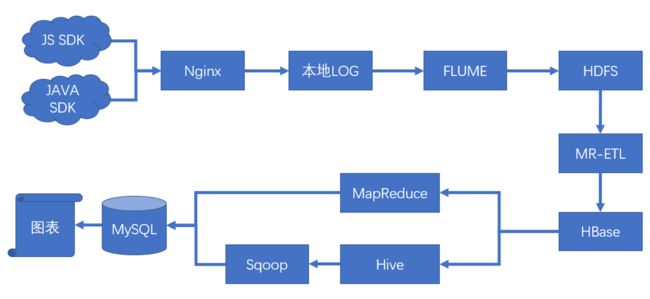
项目流程
模块细节
模块的计算方式
问题
如何解决的