YOLOv4结构以及用到的tricks与创新总结
YOLOv4结构以及用到的tricks与创新总结
本文参考了几位大佬的文章,然后作了下总结。(文中用到的图大部分来源于他们的文章,还有各算法对应的论文)文末参考链接附有这几位大佬的博客地址。
先放上YOLOv3和YOLOv4的结构图,好有个大致的思路:
YOLOv3:

YOLOv4:
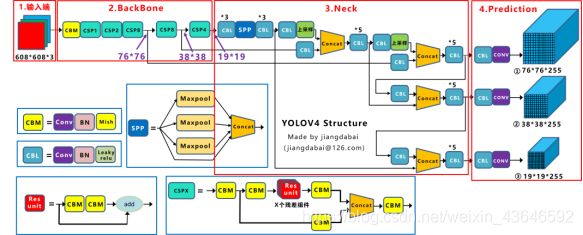
图中的说明:
1. Concat:张量拼接,会扩充两个张量的维度,例如2626256和2626512两个张量拼接,结果是2626768。Concat和cfg文件中的route功能一样。
2. add:张量相加,张量直接相加,不会扩充维度,例如104104128和104104128相加,结果还是104104128。add和cfg文件中的shortcut功能一样。
讲YOLOv4之前先来简单说下YOLOv3:
YOLOv3改进之处:
1. 多尺度预测:引入FPN,结合了3个尺度进行特征融合。
2. 更好的基础分类网络Darknet-53,类似ResNet引入了残差结构。
3. Softmax层被替换成一个1x1的卷积层+logistic激活函数的结构。
分类损失采用binary cross-entropy loss(二分类交叉损失熵)
4. Tiny-YOLOv3主要区别就是:只结合2个尺度进行特征融合。
YOLOv4改进之处:
YOLOv4的特点是集大成者,用到了相当多的tricks。
文章将目前主流的目标检测器框架进行拆分:input、backbone、neck 和 head.
总结一下YOLOv4框架:
Backbone:CSPDarknet53
Neck:SPP,FPN+PAN
Head:YOLOv3
YOLOv4 = CSPDarknet53 + SPP + (FPN+PAN) + YOLOv3
本文主要从以上4个部分对YoloV4的创新之处进行讲解,让大家一目了然。
(各部分有超链接直接点击即可跳到文中相应位置)
- 输入端:这里指的创新主要是训练时对输入端的改进,主要包括Mosaic数据增强、cmBN、SAT自对抗训练
- BackBone主干网络:将各种新的方式结合起来,包括:CSPDarknet53、Mish激活函数、Dropblock
- Neck:目标检测网络在BackBone和最后的输出层之间往往会插入一些层,比如Yolov4中的SPP模块、FPN+PAN结构
- 预测端:输出层的锚框机制和Yolov3相同,主要改进的是训练时的损失函数CIOU_Loss,以及预测框筛选的nms变为DIOU_nms
Mosaic数据增强(输入端部分):
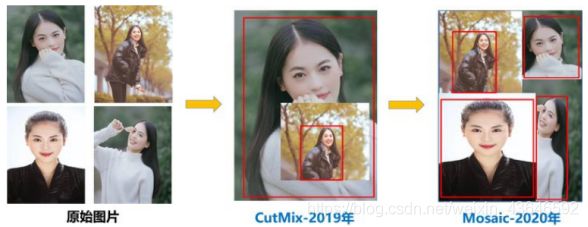
Yolov4中使用的Mosaic是参考2019年底提出的CutMix数据增强的方式,但CutMix只使用了两张图片进行拼接,而Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接。
使用原因:
在平时项目训练时,小目标的AP一般比中目标和大目标低很多。而Coco数据集中也包含大量的小目标,但比较麻烦的是小目标的分布并不均匀。所以为了平衡小、中、大目标的占比数量。
优点:
1.扩充了数据集:随机使用4张图片随机拼接,且通过随机缩放可以获得很多小目标,让网络的鲁棒性更好。
2.减少GPU:因为使用Mosaic增强进行训练时,4张图片被整合成一张图片,这样一来可以使mini-batch大小并不用很大,这样一个GPU就能达到比较好的效果。
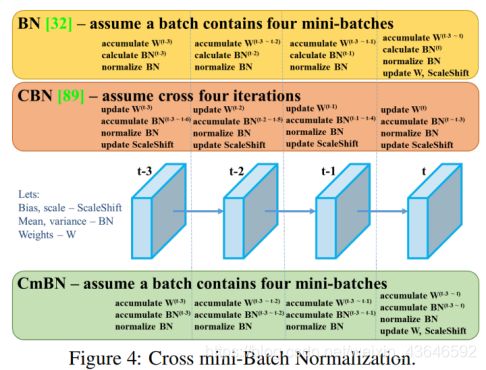
CmBN交叉小批量标准化(输入端部分):

上图为BN的处理过程,BN是对当前mini-batch进行归一化。
CBN则是对当前及其前3个batch的结果进行归一化。且利用了泰勒多项式对前3次统计数据进行了补偿(因为每个batch都更新了一次参数,所以这4个batch的使用的是不同网络参数,所以这里才做补偿)。
CmBN是CBN的改进,其区别在于其区别在于权重更新时间点不同。CBN是针对batch来说的,因为同一个batch内权重参数一样,因此计算不需要进行补偿。而CmBN是针对mini-batch来说的,其仅仅收集单个batch中的mini-batch之间的统计数据。(这里不太确定,应该是这样吧?)
SAT,Self-adversarial-training自对抗训练(输入端部分):
自对抗训练(SAT)也是一种新的数据增强方法,它包括两步。
1.利用原始图像生成对抗样本。
2.通过在原有的模型训练过程中注入对抗样本,从而提升模型对于微小扰动的鲁棒性。
Mish激活函数(backbone主干网络部分):
Mish:x * tanh(ln(1+e^x))

ReLU和Mish的对比,Mish的梯度更平滑。相比之下,Mish能更好地保持准确性,这可能是因为它能更好地传播信息。平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化。(具体的可以看mish论文)
作者只在Backbone中采用了Mish激活函数,网络后面仍然采用Leaky_relu激活函数。
CSPDarknet53(backbone主干网络部分):

我们先来看看CSP论文里的图,它是对比了DenseNet和CSPDenseNet。
Yolov4在Backbone部分的一个主要改进点就是在ResBlock部分采用了CSP,相比较于原始的ResBlock,CSP将输入的特征图按照channel进行了切割,只使用原特征图的一半输入到残差网络中进行前向传播,另一半在最后与残差网络的输出结果直接进行按channel拼接(concatenate),这样做的好处在于:
1、输入只有一半参与了计算,可以大大减少计算量和内存消耗;
2、反向传播过程中,增加了一条完全独立的梯度传播路径,梯度信息不存在重复利用,如下图所示:
下图为YOLOv4中的CSP块:

可以看到一半经过残差模块的路径。一半直接于残差网络的输出结果进行channel拼接cancat。
下面对比一下darknet53(YOLOv3中采用),CSPdarknet53(YOLOv4中采用):

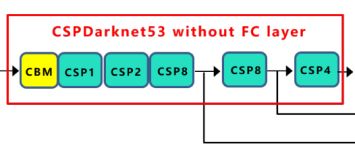
说明一下:关于图中各模块的解释看最上面的YOLOv4总结构图。
注意:YOLO V4使用时删去了最后的池化层、全连接层以及Softmax层
CSPdarknet53优点:
1.增强CNN的学习能力,使得在轻量化的同时保持准确性。
2.优点二:降低计算瓶颈
3.优点三:降低内存成本
Dropblock(backbone主干网络部分):
dropout的主要问题就是随机drop特征,这一点在FC层是有效的,但在卷积层是无效的效果并不好,因为卷积层的特征是空间相关的。当特征相关时,即使有dropout,信息仍能传送到下一层,导致过拟合。
DropBlock是dropout的一种结构化形式。在DropBlock中,特征在一个block中,例如一个feature map中的连续区域会一起被drop掉(因为连续的区域它们之间的信息密切相关,删除连续的区域可以删除某些语义信息)。当DropBlock抛弃掉相关区域的特征时,为了拟合数据网络就不得不往别处寻找新的特征。(具体实现可以看dropblock论文)

SPP模块(Neck部分):
YOLOv4中的SPP是在backbone和prediction之间的neck部分。neck部分是为了更好地提取融合特征,提升模型性能。
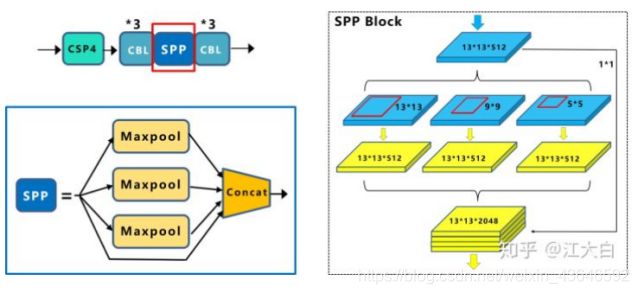
作者在SPP模块中,使用k={11,55,99,1313}的最大池化的方式,再将不同尺度的特征图进行Concat操作(即channels堆叠)。
注意:这里最大池化采用padding操作,移动的步长为1,比如13×13的输入特征图,使用5×5大小的池化核池化,padding=2,因此池化后的特征图仍然是13×13大小。
采用SPP模块的方式,比单纯的使用k*k最大池化的方式,更有效的增加主干特征的接收范围,显著的分离了最重要的上下文特征。
FPN+PAN模块(Neck部分):
FPN其实就是不同尺度特征融合预测,PAN是借鉴图像分割领域的PANet的创新点。Alexey将其拆分应用到Yolov4中,进一步提高特征提取的能力。。
FPN结构我在我的另一篇博客有讲:FPN (feature pyramid network)特征金字塔网络,
这里直接根据YOLOv4中的FPN分析。再来看看YOLOv4的图:

可以看到经过几次下采样(CSPDarknet53中讲到,每个CSP模块前面的卷积核都是33大小,步长为2,相当于下采样操作),三个紫色箭头指向的地方,输出分别是7676、3838、1919。
以及最后的Prediction中用于预测的三个特征图①1919255、②3838255、③7676255。[注:255表示80类别(1+4+80)×3=255]
我们将Neck部分用立体图画出来,更直观的看下两部分之间是如何通过FPN+PAN结构融合的。
(左:特征正常传递路径,中:FPN,右:引入了PAN(图中有两处用了PAN结构))
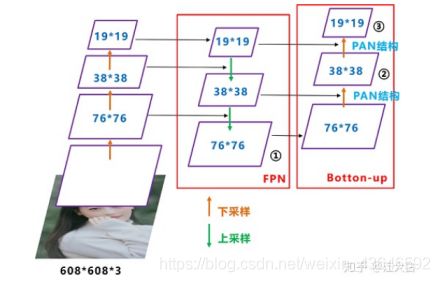
FPN层自顶向下传达强语义特征,而PAN则自底向上传达强定位特征(因为低级特征图还没有被下采样那么多,所以保留的定位信息肯定完整一点咯,而高层特征被下采样多次,更多地体现出的是较为高级抽象的语义信息咯),两两结合实属牛掰。
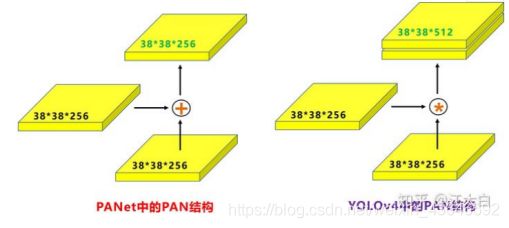
PAN这里还有一点需要注意:
原本的PANet网络的PAN结构中,两个特征图结合是采用shortcut操作(即add相加),而Yolov4中则采用concat(route)操作(即channels堆叠),特征图融合后的尺寸发生了变化。
CIOU_LOSS+DIOU_NMS(预测端部分):
一般来说,目标检测的LOSS = 分类LOSS + BBOX回归LOSS。
一个好的BBOX回归LOSS应该考虑三个重要几何因素:重叠面积、中心点距离,长宽比。
近年BBOX回归LOSS的发展
- Smooth L1 LOSS
- IOU LOSS(2016)
- GIOU LOSS(2019)
- DIOU LOSS(2020)
- CIOU LOSS(2020)
下面分别介绍这几种IOU LOSS:
1.IOU LOSS(2016)

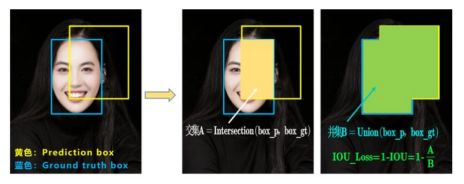
IOU很简单就是交并比而已。
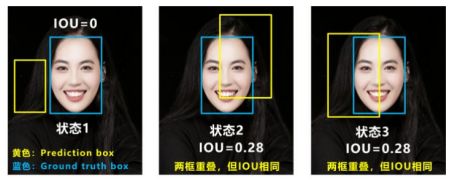
但存在如上图这两种情况的问题:
问题1:无法优化两个框不相交的情形,当IOU为0时无法衡量两框之间的相对距离,此时LOSS不可导。
问题2:如图状态2、3他们的IOU值是相同的,但IOU无法区分两者。
2.GIOU LOSS(2019)
![]()
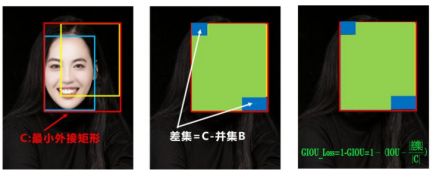
GIOU虽然增加了衡量相交情况的方式,但是还是存在不足。

如图这种情况,它们的GIOU都是相同的,这时不就跟IOU一个样,区分不了位置关系。
3.DIOU LOSS(2020)
针对IOU和GIOU的问题,DIOU综合考虑了重叠面积,中心点距离。当目标框包裹预测框的时候,直接度量2个框的距离,因此DIOU_Loss收敛的更快。


但问题是DIOU没有考虑到长宽比,如图:
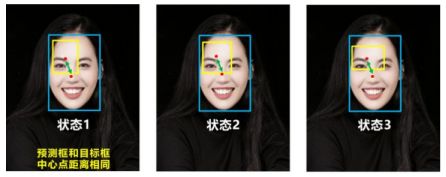
如图它们的中心点距离相同,所以DIOU也是相同的。
4.CIOU LOSS(2020)
DIOU LOSS在CIOU LOSS的基础上增加了一项,将预测框和目标框的长宽比都考虑了进去:

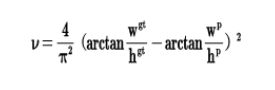
再来综合的看下各个Loss函数的不同点:
IOU_Loss:主要考虑检测框和目标框重叠面积。
GIOU_Loss:在IOU的基础上,解决边界框不重合时的问题。
DIOU_Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
CIOU_Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。
Yolov4中采用了CIOU_Loss的回归方式,使得预测框回归的速度和精度更高一些。
DIOU_NMS
为啥用CIOU LOSS 不用CIOU NMS呢?
因为前面讲到的CIOU_loss,是在DIOU_loss的基础上,添加的影响因子,包含目标框ground truth的信息,在训练时用于回归。但在测试阶段,我们是没有ground truth的,所以不用CIOU LOSS新增加的项,即直接用DIOU LOSS。
EndEndEndEndEndEndEndEndEndEndEndEndEndEndEndEndEndEndEndEnd
参考链接:
- 深入浅出Yolo系列之Yolov3&Yolov4&Yolov5核心基础知识完整讲解
- Yolov4技巧学习
- Yolov4论文翻译与解析(二)